







1.1简介
MobileNet V1是谷歌公司在2017年推出的一种轻量级卷积神经网络(CNN),专为移动端和嵌入式设备设计。它的核心创新在于使用了深度可分离卷积(depthwise separable convolutions),这是一种高效替代传统卷积运算的方法,能够显著减少模型的计算量和参数数量,从而在保持相对较高精度的同时,实现模型的小型化。
深度可分离卷积分为两步:首先是深度卷积(depthwise convolution),它针对输入的每个通道单独应用滤波器,用于捕捉空间特征;其次是点卷积(pointwise convolution,即1x1卷积),用于跨通道信息整合。通过这种分步骤的处理,MobileNet能够在较少的计算资源消耗下完成与传统卷积类似的功能。MobileNet V1还引入了两个全局超参数来进一步控制模型的大小和计算复杂度。
这些设计使得MobileNet V1成为了一种高度灵活的架构,可以根据不同的应用场景和硬件限制调整模型,以达到最佳的性能和效率平衡。尽管相比一些重型网络,MobileNet V1可能在最高精度上略有牺牲,但它在资源受限环境下的实时性、能效比方面表现优秀,非常适合于移动设备上的图像分类、物体检测等多种计算机视觉任务。
下面我们就来学习一下这篇论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
1.2 边缘计算
边缘计算是一种分布式计算架构,它将数据处理、存储、分析和应用程序的执行从集中式的云计算中心推向网络的边缘,也就是更接近数据生成源头的设备或本地网络。这样的设计旨在减少数据传输到云端处理的时间延迟,提高数据处理的效率和实时性,同时还能优化网络带宽使用,增强数据的安全性和隐私保护。边缘计算将深度学习模型的部署和执行从传统的集中式云平台扩展到了数据产生的源头——边缘设备上。
边缘计算的主要作用:
-
低延迟处理:边缘计算通过将模型推理任务放在靠近数据源的设备上执行,大大减少了数据传输到云端再返回的延迟,这对于实时性要求高的应用至关重要,如自动驾驶、工业自动化和远程医疗。
-
数据隐私保护:由于数据不需要上传到云端处理,边缘计算有助于保护用户隐私和敏感信息,符合数据保护法规,如GDPR。这对于涉及个人身份信息或健康记录的应用尤其重要。
-
带宽优化:通过在边缘处理数据,减少了对网络带宽的需求,降低了网络拥堵,对于带宽有限或成本敏感的场景非常有利。
-
资源优化与效率提升:将深度学习模型部署在边缘设备上,可以减轻云端服务器的压力,提高整体系统的效率和响应速度。这对于大规模部署的物联网设备尤其重要。
-
离线工作能力:边缘AI使设备能够在没有网络连接的情况下继续运行,提供基本的服务和决策,增强了系统的可靠性和自主性。
-
模型轻量化:为了适应边缘设备的计算和内存限制,深度学习模型往往需要进行裁剪、量化或采用其他优化技术,以生成轻量级模型,这促进了模型压缩和高效推理算法的发展。
-
云边协同:虽然计算任务在边缘执行,但边缘计算通常与云端相结合,形成“云边协同”的模式。复杂的学习和模型更新可以在云端进行,然后将优化后的模型推送到边缘设备,实现模型的持续迭代和优化。
1.3 轻量化卷积神经网络
轻量化卷积神经网络(Lightweight Convolutional Neural Networks)是针对资源受限环境(如移动设备、物联网设备)设计的一类卷积神经网络。它们的主要目的是在保持较高模型准确度的同时,显著减少模型的计算复杂度、内存占用和功耗,以适应有限的硬件资源和提升运行速度。
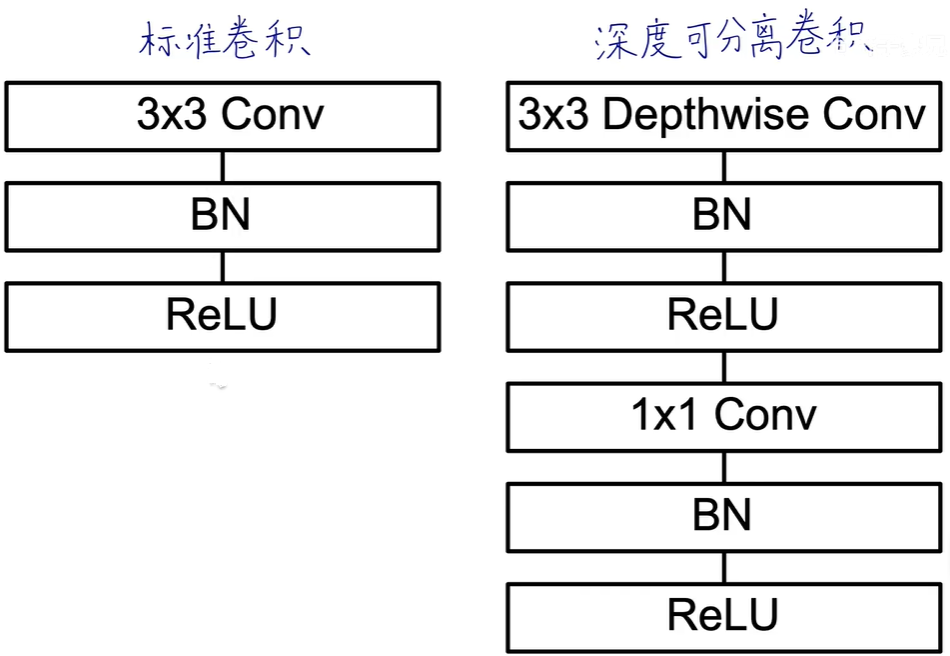
深度可分离卷积
1.深度卷积(Depthwise Convolution):这是深度可分离卷积的第一步,对输入的每个通道独立应用一个卷积核。这意味着,如果有N个输入通道,就会有N个不同的滤波器,每个滤波器只作用于对应的输入通道,从而捕获每个通道的特征。这个步骤能够有效地减少计算量,因为它避免了跨通道的信息混合,直到下一步骤。(每个通道单独卷积,不关心跨通道信息)
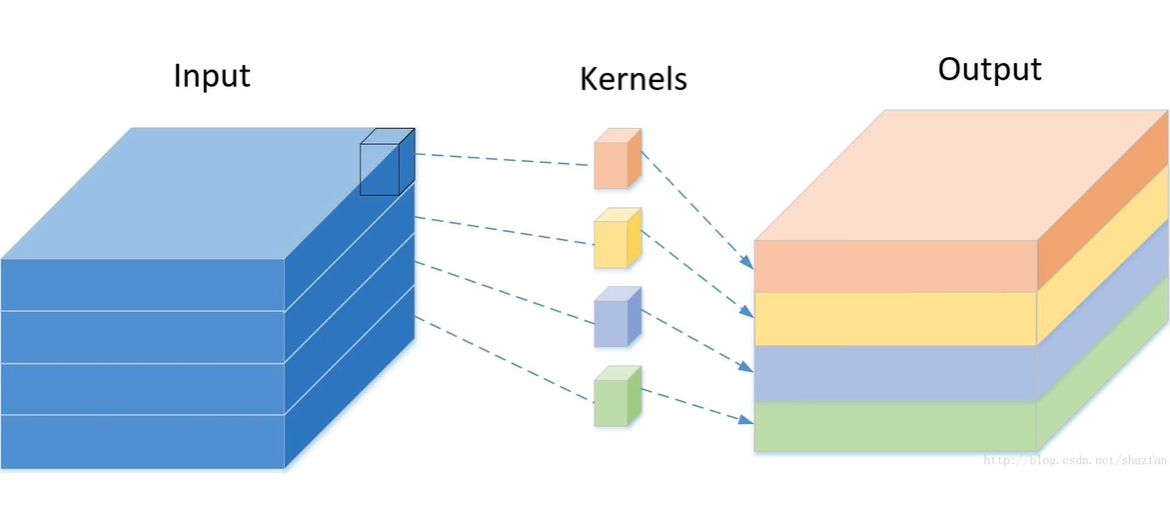
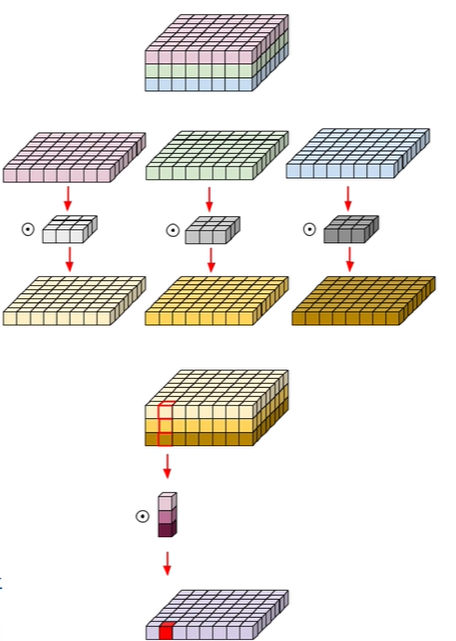
2.逐点卷积(Pointwise Convolution):在深度卷积之后,逐点卷积(也称为1x1卷积)被用来混合深度卷积后得到的特征图的不同通道。这个步骤实质上是一个标准的卷积操作,但使用的是1x1大小的滤波器,作用是减少或增加通道数,同时让不同通道之间的信息能够交互。相比于标准卷积,逐点卷积的计算成本较低。(获取跨通道信息)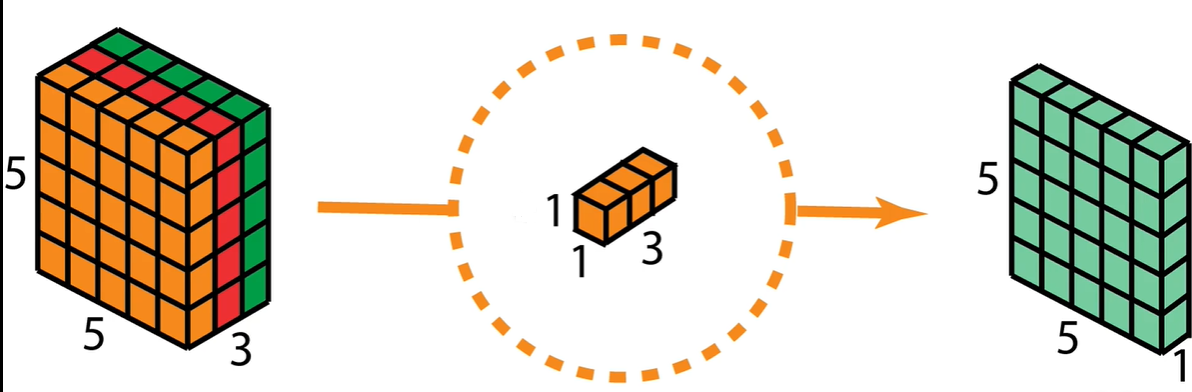
整个工作流程:(先depthwise在pointwise)
MobileNetV1结构特点
-
模型堆叠:MobileNetV1由多个深度可分离卷积层堆叠而成,每一层后面通常跟着Batch Normalization和ReLU激活函数,以保持模型的非线性表达能力。
-
超参数α:引入宽度乘数(width multiplier, α)的概念,允许通过简单地缩放网络的每个维度来调整模型的大小和计算成本,从而可以根据不同的应用场景和资源限制灵活调整模型。
-
全局平均池化和全连接层:网络的最后通常包括全局平均池化层来降低空间维度,接着是一个或多个全连接层来进行分类任务。
优势
- 轻量级:通过深度可分离卷积显著减少模型参数数量,使得模型非常适合在资源有限的设备上运行。
- 高效:减少了计算量,提升了推理速度,适合实时应用。
- 灵活性:通过调整宽度乘数和分辨率,可以在模型大小、计算成本和精度之间进行权衡。
1.4 参数量计算量分析
标准卷积

深度可分离卷积

二者比较

采用超参数α和ρ

1.5 模型结构
BN=batch normalization
一共28层。采用13组深度可分离卷积。
s1=步长为1。

1.6 模型性能分析
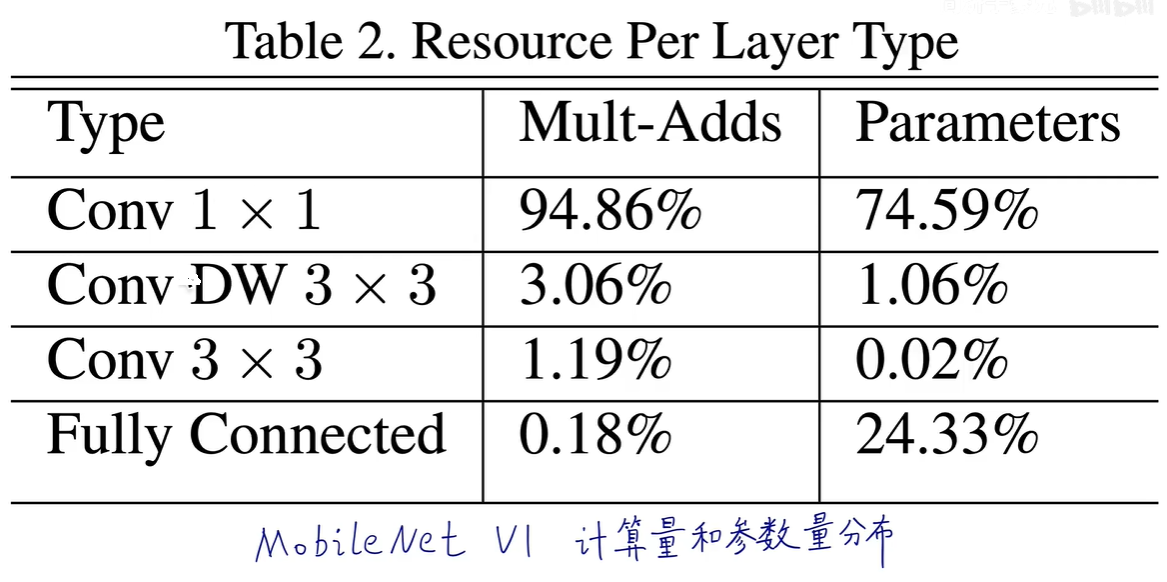
MobileNetV1中,1x1卷积之所以被认为是非常高效的,主要是基于以下几个原因:
-
参数量减少:1x1卷积核的大小仅为1x1,这意味着它不考虑像素与其周围像素的空间关系,而是对每个通道上的像素点进行线性组合。与较大的卷积核相比,它极大地减少了参数数量。在深度可分离卷积中,1x1卷积(也称为逐点卷积)紧随深度卷积之后,用于调整通道数,即使在增加或减少通道数时,其所需的参数也远少于常规卷积。
-
计算量降低:由于卷积核的尺寸小,1x1卷积的计算成本相比更大尺寸的卷积核要低得多。在每次卷积操作中,1x1卷积只需对输入特征图的每个通道执行一次乘加操作,而不需要像大尺寸卷积那样进行多次邻域内的乘加运算。这直接降低了模型的计算复杂度,提高了运行效率。
-
维度调整功能:1x1卷积能够有效地用于特征图的通道数降维或升维。在降维时,它可以减少计算负担并帮助防止过拟合;在升维时,它可以为模型提供更多的表达能力而不显著增加计算成本。这种灵活的维度调整机制对构建轻量级模型至关重要。
1.7 论文实验结果
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》展示了在多个计算机视觉任务上的实验结果,强调了其在保持较高精度的同时,显著减少了模型的参数量和计算量。具体实验结果包括但不限于以下几点:
-
模型效率:MobileNetV1通过使用深度可分离卷积替代传统的卷积层,显著降低了模型的复杂度。论文中提供了不同宽度乘子(α)配置下的模型大小和延迟时间,表明随着宽度乘子的减小,模型的参数量和计算量明显减少,同时仍然保持了较好的精度。
-
精度与速度权衡:论文展示了在ImageNet分类任务上的性能,比较了不同配置的MobileNetV1与当时其他流行模型(如VGG、Inception-v3)的精度与计算成本。MobileNetV1在大约减少10倍的参数量和减少约20倍的乘加运算(Multiply-Accumulate, MACs)的同时,达到了与VGG-16相近的分类准确率。
-
迁移学习能力:研究还评估了MobileNetV1作为特征提取器在其他任务上的表现,比如目标检测、细粒度分类和人脸属性识别等。结果显示,MobileNetV1的特征在这些任务上同样有效,表明其具有良好的泛化能力和迁移学习能力。
-
扩展性:论文探讨了通过调整宽度乘子和分辨率乘子来进一步优化模型性能的可能性,展示了如何根据具体应用场景的需求来平衡模型的大小、速度和精度。

2.模型代码复现
# Author:SiZhen
# Create: 2024/5/28
# Description:MobileNetV1网络模型
import torch.nn as nn
import torch
class MobileNetV1(nn.Module):
def __init__(self,ch_in,n_classes):
super(MobileNetV1,self).__init__()
#定义普通卷积,BN,激活模块
def conv_bn(inp,oup,stride):
return nn.Sequential(
nn.Conv2d(inp,oup,3,stride,1,bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
#定义DW,PW卷积模块
def conv_dw(inp,oup,stride):
return nn.Sequential(
#dw.关键是groups=inp时,就形成了深度卷积,即每个输入通道都有一个单独的卷积核(深度卷积核)与其匹配,且不共享卷积核。
nn.Conv2d(inp,inp,3,stride,1,groups=inp,bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
#pw
nn.Conv2d(inp,oup,1,1,0,bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn(ch_in,32,2),
conv_dw(32,64,1),
conv_dw(64,128,2),
conv_dw(128,128,1),
conv_dw(128,256,2),
conv_dw(256,256,1),
conv_dw(256,512,2),
conv_dw(512,512,1),
conv_dw(512,512,1),
conv_dw(512,512,1),
conv_dw(512,512,1),
conv_dw(512,512,1),
conv_dw(512,1024,2),
conv_dw(1024,1024,1),
nn.AdaptiveAvgPool2d(1)
)
self.fc = nn.Linear(1024,n_classes)
#定义前向传播
def forward(self,x):
x = self.model(x)
x = x.view(-1,1024)
x = self.fc(x)
return x
if __name__=="__main__":
#model check
model = MobileNetV1(ch_in=3,n_classes=5)
print(model)
random_data = torch.rand([1,3,224,224])
result = model(random_data)
print(result)

















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









