







 超级会员免费看
超级会员免费看
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第66天:序列建模与语言模型
欢迎来到Python星球日记系列的🪐的答疑篇!

一、Python安装与环境配置问题
1. Python安装问题:如何选择Python版本?
问题:我是初学者,应该安装Python 2还是Python 3?各个版本之间有什么区别?
回答:作为初学者,强烈推荐安装Python 3(最新的稳定版本,如Python 3.10或3.11)。Python 2已于2020年1月1日正式停止维护,不再接收安全更新。
Python 3相比Python 2有许多改进:
- 更一致的语法(如
print()函数而非print语句) - 更好的Unicode支持(字符串默认为Unicode)
- 更多的语言特性(如f-strings、类型注释、异步编程等)
- 所有主流库都已支持Python 3
安装时,访问Python官网下载最新的稳定版本安装包,并确保勾选"Add Python to PATH"选项,这样就可以在命令行中直接使用Python。
2. 如何验证Python安装成功?
问题:我已经安装了Python,但不确定是否安装成功,该怎么检查?
回答:验证Python安装成功的方法很简单:
在命令行(Windows上是CMD或PowerShell,MacOS/Linux上是Terminal)中输入:
python --version
或者:
python3 --version
如果安装成功,你会看到类似Python 3.11.0的输出,显示当前安装的Python版本。

如果出现"不是内部或外部命令"等错误,可能是Python没有被添加到系统PATH中。解决方法:
- 重新安装Python,确保勾选"Add Python to PATH"选项
- 或手动将Python安装目录添加到环境变量PATH中
3. pip安装包时出错怎么办?
问题:使用pip安装包时经常出错,如何解决?
回答:pip是Python的包管理工具,安装问题通常有几个常见原因:
-
网络问题:可以尝试使用国内镜像源加速下载:
pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple -
权限问题:
- Windows: 以管理员身份运行命令提示符
- Mac/Linux: 使用
sudo pip install 包名或设置虚拟环境
-
版本兼容性:指定版本安装:
pip install 包名==版本号 -
pip版本过旧:更新pip:
python -m pip install --upgrade pip -
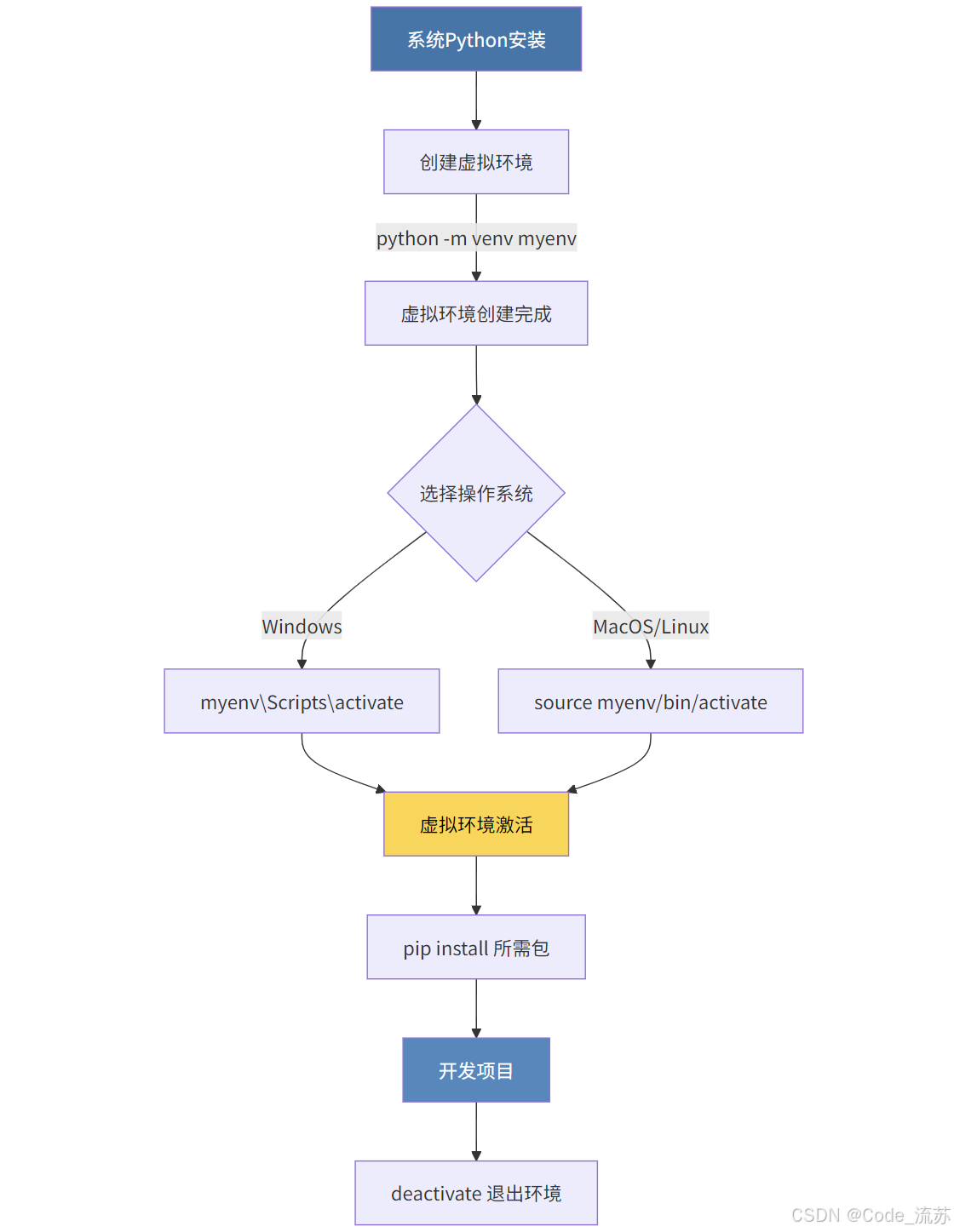
使用虚拟环境:避免包之间冲突:
# 创建虚拟环境 python -m venv myenv # 激活虚拟环境 # Windows: myenv\Scripts\activate # MacOS/Linux: source myenv/bin/activate
二、Python基础语法与概念疑惑
1. Python中的缩进问题
问题:为什么我的代码明明没错,但总是报"IndentationError"?Python对缩进有什么要求?
回答:在Python中,缩进不仅仅是代码风格问题,而是语法的一部分。Python使用缩进来表示代码块,而不是其他语言中常见的花括号{}。
缩进错误主要有以下几种情况:
-
混用Tab和空格:这是最常见的错误。Python要求统一使用Tab或空格(推荐使用4个空格)。
# 错误示例(混用Tab和空格) if True: print("这里用了4个空格") print("这里用了1个Tab") # 会导致IndentationError # 正确示例 if True: print("这里用了4个空格") print("这里也用了4个空格") # 正确 -
缩进层级不一致:同一代码块必须保持相同的缩进层级。
# 错误示例 if True: print("第一行") print("第二行缩进过多") # 会导致IndentationError # 正确示例 if True: print("第一行") print("第二行缩进相同") # 正确 -
遗漏冒号:在需要代码块的语句(如if、for、def等)后必须有冒号
:。
建议:使用专业的Python IDE如PyCharm、VSCode等,它们会自动处理缩进并给出提示,帮助避免这类错误。
2. 为什么Python中变量不需要声明类型?
问题:其他语言如C++、Java都需要声明变量类型,为什么Python不需要?这会不会带来问题?
回答:Python是动态类型语言,变量不需要预先声明类型,而是在赋值时自动确定类型。这是Python设计理念"简洁明了"的体现。
# Python动态类型示例
x = 10 # x是整型
x = "hello" # 现在x变成了字符串类型
x = [1, 2, 3] # 现在x变成了列表类型
这种特性带来了极大的灵活性和开发效率,但也有一些注意点:
- 类型错误可能在运行时才会被发现,而不是编译时
- 可能导致意外的类型转换问题
从Python 3.5开始,引入了类型提示(Type Hints)功能,允许开发者可选地标注变量类型:
def greeting(name: str) -> str:
return "Hello, " + name
这些类型提示不会强制执行,但可以:
- 提高代码可读性
- 帮助IDE提供更准确的代码补全
- 与类型检查工具(如mypy)配合使用,提前发现潜在的类型错误
3. Python中的"==" 和 “is” 有什么区别?
问题:我发现有时候==和is的结果不一样,它们有什么区别?
回答:这是Python初学者经常混淆的概念:
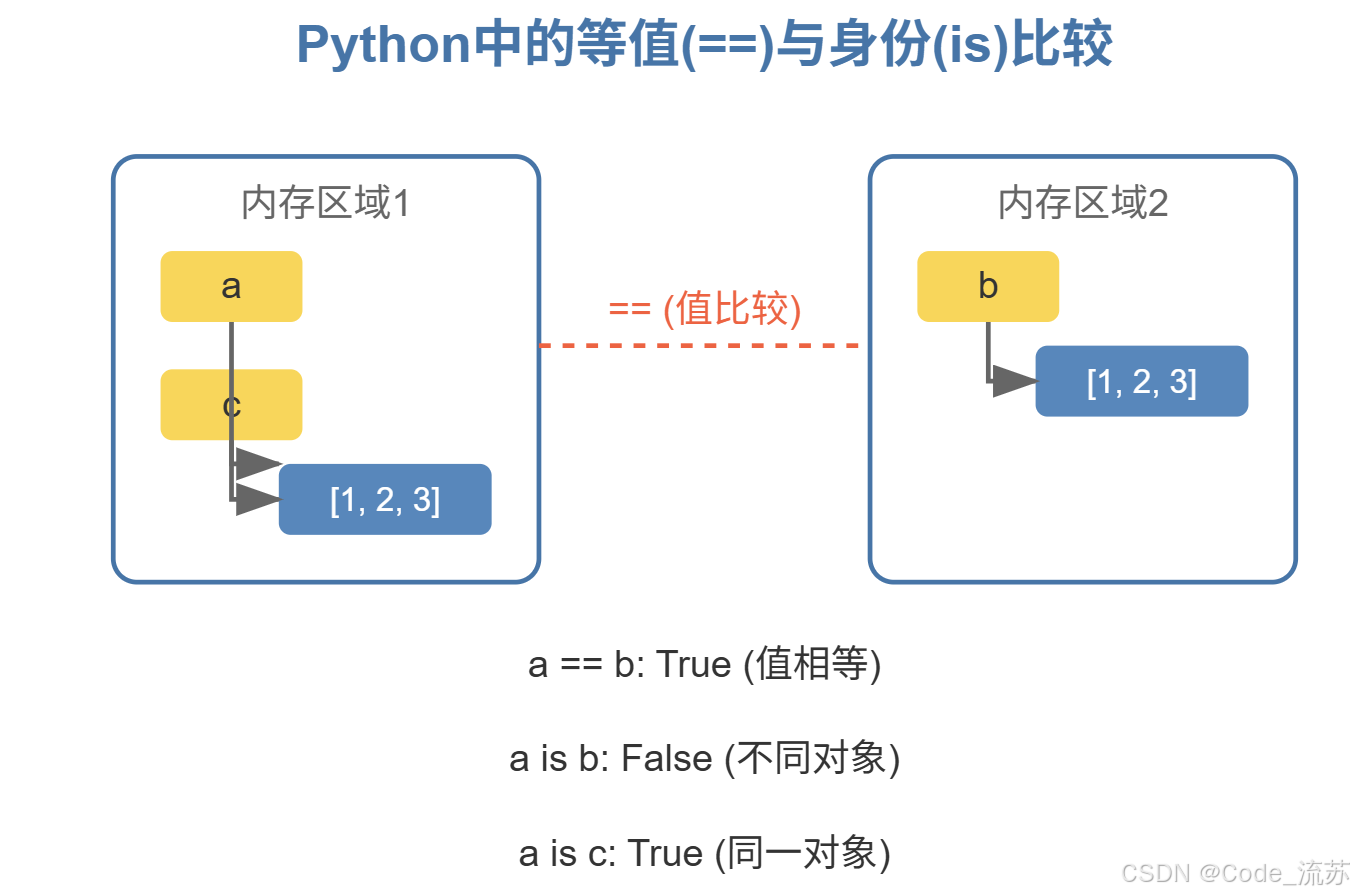
==比较的是对象的值是否相等is比较的是对象的身份(是否是同一个对象,即内存地址是否相同)
# 示例
a = [1, 2, 3]
b = [1, 2, 3]
c = a
print(a == b) # True(值相等)
print(a is b) # False(不是同一个对象)
print(a is c) # True(是同一个对象)
三、数据类型与变量常见困惑
1. 字符串、列表、元组的区别与选择
问题:Python中的字符串、列表和元组看起来很相似,我该如何选择使用哪一种?
回答:这三种数据类型确实有相似之处,但它们各有特点和适用场景:
字符串(str)是用于处理文本数据的序列类型。字符串是不可变的,这意味着一旦创建,就不能修改其内容。
text = "Hello World"
first_char = text[0] # 可以像数组一样访问: 'H'
# text[0] = 'J' # 错误!字符串不可修改
new_text = 'J' + text[1:] # 正确方式:创建新字符串
列表(list)是最灵活的序列类型,可以存储任意类型的数据,并且是可变的。
fruits = ["apple", "banana", "cherry"]
fruits.append("orange") # 添加元素
fruits[0] = "pear" # 修改元素
元组(tuple)与列表类似,但它是不可变的。一旦创建,就不能添加、删除或修改元素。
coordinates = (10.5, 20.8)
# coordinates[0] = 15 # 错误!元组不可修改
如何选择?
- 使用字符串处理文本数据
- 使用列表当你需要一个可以修改的序列,或者当数据项可能变化时
- 使用元组表示固定集合的数据,如坐标点、RGB颜色值,或作为字典的键
元组通常比列表更高效(因为不可变),也更安全(防止意外修改),所以当不需要修改数据时,优先考虑使用元组。
2. 可变与不可变类型有什么重要差异?
问题:我注意到有些操作在列表上可以,在字符串上却不行。什么是可变和不可变类型?
回答:在Python中,数据类型分为两大类:可变类型(mutable)和不可变类型(immutable),这是理解Python行为的关键概念。
不可变类型(immutable):
- 包括:整数(int)、浮点数(float)、字符串(str)、元组(tuple)、冻结集合(frozenset)
- 特点:创建后不能修改其内容,任何"修改"操作实际上是创建了一个新对象
可变类型(mutable):
- 包括:列表(list)、字典(dict)、集合(set)
- 特点:创建后可以修改其内容,而不需要创建新对象
这种区别在函数参数传递和作为字典键时尤为重要:
-
函数参数:传递可变对象时,函数内的修改会影响原对象
def modify_list(my_list): my_list.append(4) # 修改会影响原列表 numbers = [1, 2, 3] modify_list(numbers) print(numbers) # 输出 [1, 2, 3, 4] def modify_string(my_string): my_string += "!" # 不会影响原字符串,创建了新字符串 greeting = "Hello" modify_string(greeting) print(greeting) # 仍然输出 "Hello" -
字典键:只有不可变类型可以作为字典的键
# 正确:使用不可变类型作为键 dict_a = {1: "one", "two": 2, (3, 4): "tuple"} # 错误:使用可变类型作为键 # dict_b = {[1, 2]: "list"} # 会引发TypeError
理解可变性能帮助你避免许多常见的Python编程错误,尤其是在处理函数和复杂数据结构时。
3. 为什么我的代码有时会出现浅拷贝问题?
问题:我复制了一个列表,但修改复制后的列表时,原列表也被修改了。这是为什么?
回答:这是初学者常遇到的**浅拷贝(shallow copy)**问题,与Python的对象引用机制有关。
在Python中,简单的赋值操作(b = a)不会创建新对象,而只是创建了指向同一对象的新引用。要真正复制对象,需要使用特定的复制方法:
# 直接赋值 - 创建引用,而非复制
original = [1, 2, [3, 4]]
reference = original # reference和original指向同一个列表
# 浅拷贝 - 复制最外层对象,但内部对象仍然共享
import copy
shallow = copy.copy(original) # 或 shallow = original.copy() 或 shallow = original[:]
# 深拷贝 - 完全复制,创建独立的对象树
deep = copy.deepcopy(original)
# 修改测试
reference[0] = 99 # original也会变为 [99, 2, [3, 4]]
shallow[1] = 88 # original不变,但shallow变为 [1, 88, [3, 4]]
shallow[2][0] = 77 # original和shallow的内部列表都变为 [77, 4]
deep[2][1] = 66 # 只有deep变为 [1, 2, [3, 66]],original不受影响
四、控制流与逻辑结构问题
1. if-elif-else结构中容易犯的错误
问题:我的if-elif-else结构似乎不按我期望的方式工作,条件判断时有什么需要注意的吗?
回答:if-elif-else结构是Python中最基础的控制流语句,但即使是有经验的程序员也可能在使用时犯错。以下是几个常见的误区和解决方法:
- 忘记条件判断是按顺序执行的
Python会按照从上到下的顺序检查条件,一旦有一个条件满足,就会执行对应的代码块并跳过后面的所有条件。
# 错误示例
score = 85
if score >= 60: # 这个条件满足
grade = "及格" # 执行此语句后跳过剩余条件
elif score >= 80: # 虽然也满足,但永远不会被检查到
grade = "良好"
elif score >= 90:
grade = "优秀"
print(grade) # 输出"及格",而不是"良好"
解决方法是从最严格的条件开始判断:
# 正确示例
score = 85
if score >= 90:
grade = "优秀"
elif score >= 80: # 这个条件满足
grade = "良好" # 执行此语句
elif score >= 60:
grade = "及格"
print(grade) # 输出"良好"
- 使用单等号
=而不是双等号==进行比较
这是初学者最常见的错误之一,单等号是赋值,双等号才是比较。
# 错误示例
if x = 10: # 语法错误:试图赋值而不是比较
print("x等于10")
# 正确示例
if x == 10: # 使用双等号进行比较
print("x等于10")
- 混淆了逻辑运算符
and和or
and要求所有条件都为True,而or只需要任一条件为True。
# 常见误解
# 想要表达"x在1到10之间"
if x > 1 or x < 10: # 错误逻辑!几乎所有x值都满足此条件
print("x在范围内")
# 正确表达方式
if x > 1 and x < 10: # 正确:同时满足两个条件
print("x在范围内")
# 另一种正确表达方式
if 1 < x < 10: # Python支持链式比较
print("x在范围内")
2. 为什么我的循环不能正确遍历并修改列表?
问题:我尝试在遍历列表的同时修改它,但结果似乎不正确,甚至有时会出错。
回答:在遍历列表的同时修改它是一个常见的陷阱。当你在遍历过程中修改列表(添加或删除元素)时,列表的长度和元素位置都会改变,这会导致跳过某些元素或引发错误。
这个问题主要有三种情况:
- 在遍历时删除元素
# 错误方式:直接在for循环中删除
numbers = [1, 2, 3, 4, 5]
for num in numbers:
if num % 2 == 0: # 删除偶数
numbers.remove(num) # 这会改变列表结构!
print(numbers) # 可能输出[1, 3, 5]或[1, 3, 4, 5],取决于实现
这种情况下,当删除一个元素后,后面的元素会前移,导致某些元素被跳过。
解决方法有几种:
# 方法1:从后向前遍历(不会影响还未遍历的元素)
numbers = [1, 2, 3, 4, 5]
for i in range(len(numbers)-1, -1, -1):
if numbers[i] % 2 == 0:
del numbers[i]
# 方法2:创建新列表(最推荐的方式)
numbers = [1, 2, 3, 4, 5]
numbers = [num for num in numbers if num % 2 != 0] # 列表推导式
# 或者
numbers = list(filter(lambda x: x % 2 != 0, numbers))
- 在遍历时添加元素
这可能导致无限循环:
# 可能导致无限循环
numbers = [1, 2, 3]
for num in numbers:
numbers.append(num * 2) # 列表不断增长,循环不会结束
解决方法是在遍历前创建副本:
numbers = [1, 2, 3]
for num in numbers.copy(): # 或 numbers[:]
numbers.append(num * 2)
- 使用索引遍历并修改
# 这可能会导致索引错误
numbers = [1, 2, 3, 4, 5]
for i in range(len(numbers)):
if numbers[i] % 2 == 0:
numbers.pop(i) # 删除后,索引i可能超出范围
最佳实践:
- 在遍历列表时,尽量不要修改正在遍历的列表
- 如果必须修改,使用列表推导式创建新列表,或从后向前遍历
- 对于复杂的过滤和转换,考虑使用
filter()和map()函数
3. for循环与while循环如何选择?
问题:Python中有for循环和while循环,它们有什么区别?我该如何选择使用哪一种?
回答:for循环和while循环是两种常见的循环结构,它们各有特点和适用场景。
for循环是一种确定性循环,用于遍历一个可迭代对象(如列表、字符串、范围等)中的所有元素。它有明确的开始和结束点。
# for循环示例
for i in range(5):
print(i) # 输出0到4
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
while循环是一种条件性循环,只要指定的条件为True,就会一直执行。它的结束点取决于条件何时变为False。
# while循环示例
count = 0
while count < 5:
print(count)
count += 1 # 不要忘记更新条件,否则会造成无限循环
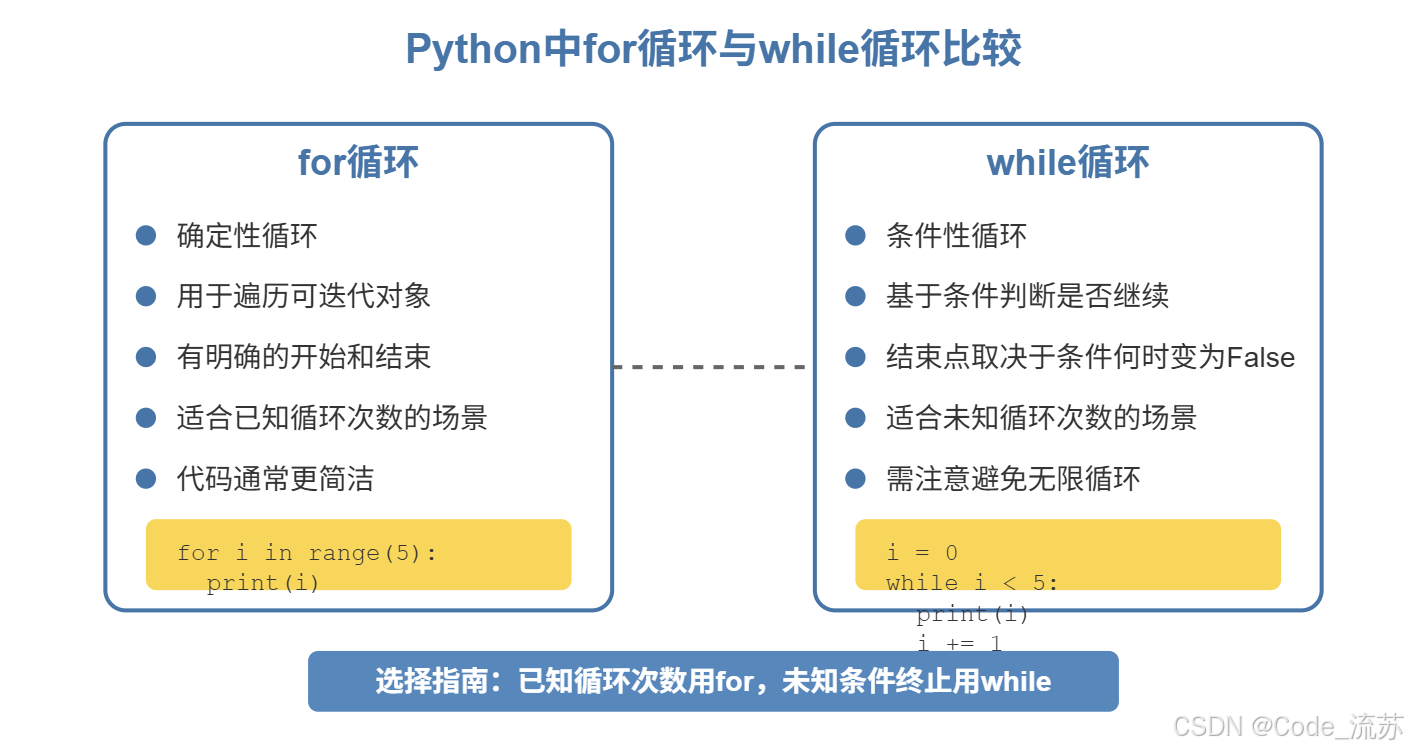
选择依据:
-
当你知道循环次数或需要遍历一个序列/集合中的元素时,使用for循环:
- 遍历列表、元组、字典等集合
- 需要执行确定次数的操作
- 需要同时获取索引和值(使用
enumerate())
-
当循环需要根据条件继续或停止,且不知道确切循环次数时,使用while循环:
- 需要直到满足某条件才结束的循环
- 用户输入验证(直到输入正确)
- 处理事件(如游戏循环)
在实际编程中,大约80%的循环场景适合使用for循环,因为大多数情况下我们是在处理集合或已知范围的数据。
五、函数与模块使用问题
1. 函数参数传递与返回值混淆
问题:我的函数为什么没有改变我传入的变量值?有时候会改变,有时候又不会,这让我很困惑。
回答:这个问题涉及到Python的参数传递机制,也是初学者常常感到困惑的地方。让我们一步步理解这个概念。
在Python中,函数参数传递遵循**“通过对象引用传递”**的方式,而不是纯粹的"传值"或"传引用"。这听起来可能有些复杂,但让我们通过例子来解释:
当你将一个变量传递给函数时,Python实际上是将这个变量所引用的对象传递给函数。这就引出了一个关键区别:函数能否修改原始对象,取决于对象是可变的还是不可变的。
对于不可变对象(如整数、字符串、元组),函数内的修改会创建一个新对象,而不会影响原始对象:
def modify_string(text):
text = text + " World" # 创建了新的字符串对象
print("Inside function:", text)
message = "Hello"
modify_string(message)
print("Outside function:", message) # 仍然是 "Hello"
对于可变对象(如列表、字典、集合),函数内的修改会直接影响原始对象:
def modify_list(items):
items.append(4) # 直接修改原列表
print("Inside function:", items)
numbers = [1, 2, 3]
modify_list(numbers)
print("Outside function:", numbers) # 变成了 [1, 2, 3, 4]
但是,如果你在函数内重新赋值整个变量,而不是修改其内容,那么就不会影响原始对象,即使它是可变的:
def replace_list(items):
items = [7, 8, 9] # 创建新列表并赋值给参数变量
print("Inside function:", items)
numbers = [1, 2, 3]
replace_list(numbers)
print("Outside function:", numbers) # 仍然是 [1, 2, 3]
如果你想让函数修改变量本身(而不仅是其内容),你需要使用返回值:
def double_value(x):
return x * 2 # 返回新值
num = 5
num = double_value(num) # 将返回值重新赋给原变量
print(num) # 现在是10
理解这个机制对于编写可预测的Python代码至关重要,尤其是在处理复杂数据结构时。
2. 理解函数默认参数的陷阱
问题:我创建了一个带默认列表参数的函数,但每次调用它时,默认列表似乎会保留之前的修改。这是怎么回事?
回答:这是Python中一个著名的"陷阱",与默认参数的评估时机有关。让我们深入了解原因和解决方法。
在Python中,默认参数值只在函数定义时计算一次,而不是在每次函数调用时重新计算。这对于像数字或字符串这样的不可变类型通常没有问题,但对于列表、字典等可变类型会导致意外行为。
看这个例子:
def add_item(item, item_list=[]): # 默认参数是空列表
item_list.append(item)
return item_list
print(add_item("apple")) # 输出: ['apple']
print(add_item("banana")) # 你可能期望 ['banana'],但实际输出: ['apple', 'banana']
print(add_item("cherry")) # 输出: ['apple', 'banana', 'cherry']
这发生是因为默认的空列表[]只在函数定义时创建了一次,所有后续调用都使用同一个列表对象。当你修改这个列表时,更改会持续存在。
这种行为对初学者来说很容易造成困惑,因为它看起来像是函数"记住"了之前的调用。
解决方案是使用None作为默认值,然后在函数内部检查并创建新列表:
def add_item(item, item_list=None):
if item_list is None:
item_list = [] # 每次调用都创建新列表
item_list.append(item)
return item_list
print(add_item("apple")) # 输出: ['apple']
print(add_item("banana")) # 现在输出: ['banana']
这种模式适用于任何需要在函数参数中使用可变默认值的情况,包括列表、字典、集合等。
记住这个规则:永远不要使用可变对象作为默认参数值。相反,使用None并在函数体内创建可变对象。
3. 模块导入与路径问题
问题:我在导入自己编写的模块时经常遇到ImportError或ModuleNotFoundError错误,如何解决Python模块导入问题?
回答:模块导入问题是Python开发中的一个常见障碍,尤其是当项目结构变得复杂时。让我们系统地了解Python如何查找模块,以及如何解决常见的导入问题。
Python模块搜索机制:当你执行import something时,Python会按照以下顺序查找模块:
- 当前目录
- PYTHONPATH环境变量中列出的目录
- 标准库目录
- 已安装的第三方包目录
可以通过查看sys.path列表来查看Python的搜索路径:
import sys
print(sys.path)
常见导入问题及解决方案:
-
找不到模块
如果你的模块不在Python的搜索路径中,可以通过以下几种方式解决:
# 方法1:将模块目录添加到sys.path(不推荐用于生产环境) import sys sys.path.append('/path/to/your/modules') import your_module # 方法2:创建合适的项目结构和__init__.py文件(推荐方式) # 在每个包目录中创建一个__init__.py文件(可以为空) -
相对导入与绝对导入
Python支持两种导入方式:
# 绝对导入(从项目根目录开始) from package import module from package.module import function # 相对导入(基于当前模块位置) from . import module # 从同级目录导入 from .. import module # 从父级目录导入 from ..sibling import module # 从父级的另一个子目录导入相对导入只能在包内使用,不能在直接运行的脚本中使用。
-
循环导入
当两个模块互相导入对方时,可能导致循环导入问题:
module_a.py 导入 module_b.py module_b.py 导入 module_a.py解决方法:
- 重构代码,消除循环依赖
- 将导入语句移到函数内部(延迟导入)
- 在模块底部导入而不是顶部
-
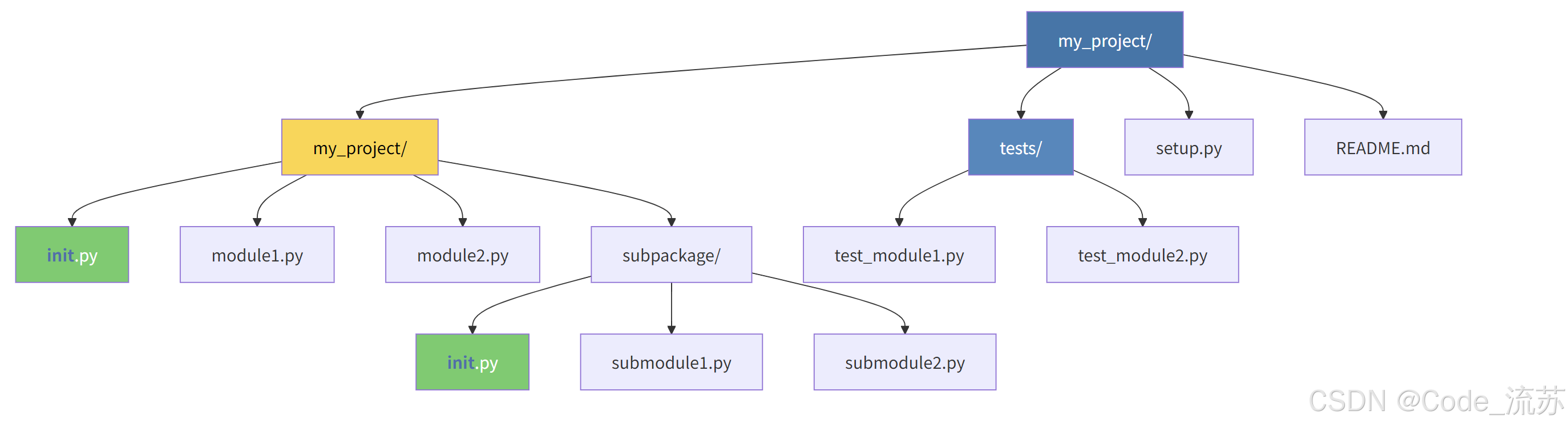
推荐的项目结构
对于较大的项目,推荐使用以下结构来避免导入问题:
六、异常处理与调试困难
1. 异常处理最佳实践
问题:我应该如何正确处理Python中的异常?捕获所有异常是好习惯吗?
回答:异常处理是编写健壮Python代码的关键部分,但它确实有一些最佳实践和常见陷阱需要了解。
首先,让我们明确一点:异常不是错误。它们是程序执行过程中发生的特殊事件,用于处理异常情况。Python的异常机制允许我们优雅地处理这些情况,而不是让程序崩溃。
然而,异常处理也需要谨慎使用。以下是一些关键的最佳实践:
- 永远不要捕获所有异常后静默处理
# 不推荐的做法
try:
# 一些代码
process_data(file_name)
except: # 捕获所有异常
pass # 不做任何处理
这种做法被称为"吞下异常",它会隐藏问题而不是解决问题,使调试变得极其困难。
- 只捕获预期的特定异常
# 推荐的做法
try:
with open(file_name, 'r') as file:
data = file.read()
except FileNotFoundError:
print(f"文件 {file_name} 不存在,请检查路径")
except PermissionError:
print(f"没有权限读取文件 {file_name}")
这样可以针对不同类型的异常采取不同的处理措施。
- 利用异常层级结构
Python的异常是有层级的。例如,IOError和OSError是基类,FileNotFoundError是它们的子类。你可以先捕获特定异常,再捕获更通用的异常:
try:
# 一些可能引发异常的代码
result = complex_operation()
except ValueError:
# 处理值错误
print("输入值无效")
except Exception as e:
# 处理其他所有异常,但要记录它们
print(f"发生未预期的错误: {type(e).__name__}: {e}")
logging.error(f"Unexpected error: {type(e).__name__}: {e}")
- 使用
finally子句确保资源释放
file = None
try:
file = open('data.txt', 'r')
# 处理文件
except FileNotFoundError:
print("文件不存在")
finally:
if file:
file.close() # 无论是否发生异常,都会执行
当然,更好的方法是使用with语句,它会自动处理资源的关闭:
try:
with open('data.txt', 'r') as file:
# 处理文件
except FileNotFoundError:
print("文件不存在")
- 自定义异常类
对于复杂应用,创建自己的异常类可以提高代码的可读性和可维护性:
class DataValidationError(Exception):
"""当数据验证失败时抛出"""
pass
def process_user_data(data):
if not valid_format(data):
raise DataValidationError("数据格式无效")
# 继续处理...
最后,记住异常处理的目的是让程序能够优雅地处理错误情况,而不是隐藏错误。好的异常处理应该提供清晰的错误信息,帮助用户或开发者理解和解决问题。
2. 调试技巧:找出错误根源
问题:当我的程序出错时,我经常很难找出问题在哪里。有什么有效的调试技巧吗?
回答:调试是编程中不可避免的一部分,掌握有效的调试技巧可以大大提高解决问题的效率。以下是一些适合Python初学者的实用调试方法:
- 使用
print()函数
这是最简单但也非常有效的调试方法。通过在关键位置添加print()语句,可以查看变量的值和程序的执行流程:
def calculate_total(items):
print(f"Starting calculation with items: {items}")
total = 0
for item in items:
print(f"Processing item: {item}")
total += item
print(f"Final total: {total}")
return total
虽然简单,但这种方法在复杂代码中可能会变得混乱。
- 使用Python内置的
pdb调试器
pdb是Python的内置调试器,提供了交互式调试环境:
import pdb
def complex_function(data):
result = process_step1(data)
pdb.set_trace() # 程序会在这里暂停,进入调试模式
result = process_step2(result)
return result
当程序执行到pdb.set_trace()时,会进入调试模式,你可以:
- 使用
n执行下一行 - 使用
s步入函数 - 使用
c继续执行直到下一个断点 - 使用
p 变量名打印变量值 - 使用
q退出调试器
在Python 3.7+中,你可以使用更简洁的breakpoint()函数代替pdb.set_trace()。
- 使用日志记录而不是打印
对于更大型的项目,使用Python的logging模块比print更合适:
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
def process_data(data):
logging.debug(f"Processing data: {data}")
try:
result = complex_calculation(data)
logging.info(f"Calculation successful: {result}")
return result
except Exception as e:
logging.error(f"Error in calculation: {e}")
raise
日志可以设置不同的级别(DEBUG, INFO, WARNING, ERROR, CRITICAL),并且可以输出到文件。
- 使用IDE的调试工具
现代的Python IDE(如PyCharm、VS Code)提供了强大的图形化调试工具,包括:
- 设置断点
- 单步执行
- 变量监视
- 条件断点
这些工具通常比使用pdb更加用户友好。
- 理解错误信息
Python的错误信息通常包含丰富的信息。以下是理解错误追踪信息的关键部分:
Traceback (most recent call last):
File "script.py", line 10, in <module>
result = process_data(input_data)
File "script.py", line 5, in process_data
return data[0] / divisor
ZeroDivisionError: division by zero
错误追踪从底部向上读:
- 最后一行告诉你错误类型(ZeroDivisionError)和错误消息(division by zero)
- 上面的行告诉你错误发生的位置,包括文件名、行号和上下文
- 追踪从调用栈的顶部(最近的调用)开始,到底部(最初的调用)结束
- 隔离和简化问题
当面对复杂错误时,尝试将问题隔离到最小可能的代码段:
- 注释掉代码部分,看问题是否仍然存在
- 创建一个简化版本的问题代码
- 一次只改变一个变量或参数,观察结果
这种"科学方法"可以帮助你找出真正的问题所在。
- 使用断言进行防御性编程
断言可以在开发阶段帮助捕获不符合预期的情况:
def calculate_average(numbers):
assert len(numbers) > 0, "Cannot calculate average of empty list"
return sum(numbers) / len(numbers)
记住,在生产环境中断言可能会被禁用,所以不要依赖它们来处理用户输入验证。
通过结合使用这些技巧,你可以更有效地定位和解决Python程序中的错误。
3. 代码性能优化与常见瓶颈
问题:我的Python程序运行很慢,有哪些常见的性能优化技巧?
回答:Python以其简洁易读的语法而闻名,但在某些情况下可能会遇到性能瓶颈。了解常见的性能优化技巧可以帮助你编写更高效的代码,而不必牺牲Python的简洁性。
让我们探讨一些实用的性能优化策略:
- 首先:确定真正的瓶颈
在开始优化之前,确定代码中的真正瓶颈是至关重要的。过早优化可能会浪费时间并使代码不必要地复杂化。
使用Python的性能分析工具:
import cProfile
cProfile.run('my_function()') # 显示函数各部分的执行时间
# 或者使用装饰器方式
import profile
@profile
def my_function():
# 代码
还可以使用第三方库如line_profiler或memory_profiler进行更详细的分析。
- 使用适当的数据结构
选择正确的数据结构对性能影响极大:
# 低效:在列表中查找元素 - O(n)
my_list = [1, 2, 3, 4, 5]
if 3 in my_list: # 线性搜索
print("Found")
# 高效:在集合中查找元素 - O(1)
my_set = {1, 2, 3, 4, 5}
if 3 in my_set: # 常量时间
print("Found")
常见的数据结构选择指南:
- 需要快速查找:使用字典或集合
- 需要有序元素:使用列表
- 需要不可变序列:使用元组
- 需要唯一元素:使用集合
- 减少循环中的不必要操作
# 低效
result = []
for i in range(1000):
result.append(i * i)
# 更高效 - 列表推导式
result = [i * i for i in range(1000)]
# 循环中减少函数调用
# 低效
for i in range(1000):
result = expensive_function(i)
process_result(result)
# 更高效
expensive_function_result = expensive_function # 保存函数引用
for i in range(1000):
result = expensive_function_result(i)
process_result(result)
- 使用生成器节省内存
当处理大量数据时,生成器可以节省大量内存:
# 内存密集型 - 一次创建所有平方数
squares = [x * x for x in range(1000000)]
# 内存友好型 - 按需生成平方数
squares_gen = (x * x for x in range(1000000))
生成器一次只生成一个值,而不是预先创建整个列表。
- 利用内置函数和标准库
Python的内置函数通常用C实现,比纯Python代码更快:
# 低效 - 自己实现求和
total = 0
for num in numbers:
total += num
# 高效 - 使用内置函数
total = sum(numbers)
类似地,map、filter和标准库中的函数通常比手写循环更高效。
- 使用局部变量而非全局变量
局部变量访问速度快于全局变量:
# 较慢
GLOBAL_VALUE = 5
def multiply():
result = []
for i in range(1000):
result.append(i * GLOBAL_VALUE)
return result
# 较快
def multiply():
local_value = 5 # 局部变量
result = []
for i in range(1000):
result.append(i * local_value)
return result
- 使用PyPy等替代解释器
对于计算密集型任务,考虑使用PyPy这样的JIT编译器,它可以提供接近C的性能:
# 安装PyPy
pip install pypy
# 使用PyPy运行脚本
pypy script.py
PyPy可以让某些Python代码运行速度提高3-10倍,而不需要修改代码。
- 使用适当的第三方库
对于数据科学和数值计算,使用经过优化的库:
- NumPy 用于数值计算
- Pandas 用于数据分析
- Numba 用于代码加速
- Cython 用于关键代码优化
- 优化字符串操作
# 低效 - 重复字符串连接
result = ""
for i in range(1000):
result += str(i)
# 高效 - 使用join
result = "".join(str(i) for i in range(1000))
字符串连接创建了多个临时字符串,而join只创建一个最终字符串。
- 缓存重复计算的结果
使用functools.lru_cache装饰器缓存函数结果:
from functools import lru_cache
@lru_cache(maxsize=None)
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-1) + fibonacci(n-2)
这对于经常使用相同参数调用的函数特别有用。
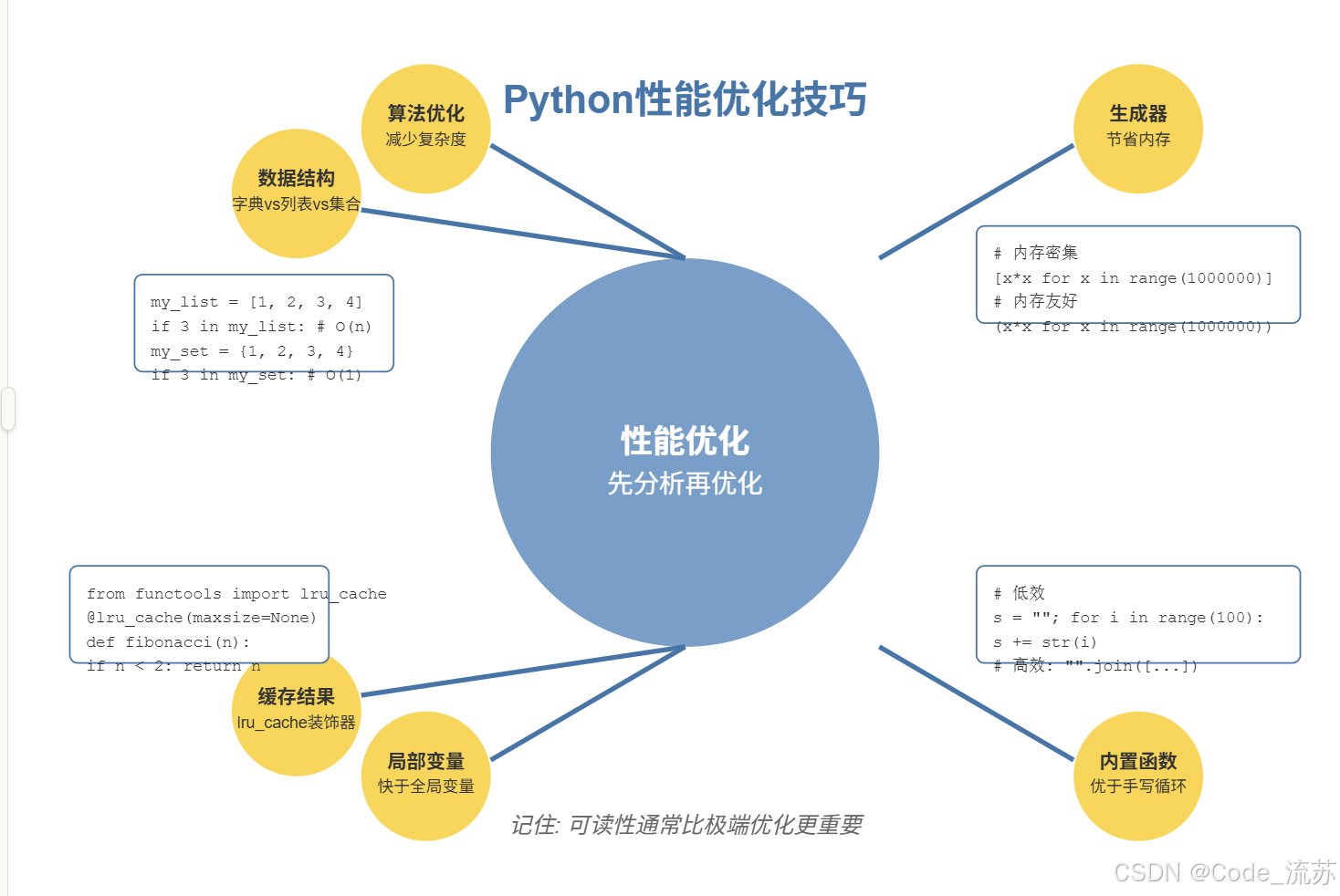
记住,代码可读性通常比极端的性能优化更重要。先写出正确、清晰的代码,然后只在需要时优化被证明是瓶颈的部分。
七、文件操作与数据处理常见问题
1. 文件路径与读写问题
问题:我在打开文件时经常遇到"找不到文件"或路径相关的错误,如何正确处理Python中的文件路径?
回答:文件操作是编程中的基础任务,但路径处理确实是初学者常见的绊脚石。让我深入解释Python中文件路径的处理方法和最佳实践。
首先,理解文件路径的两种基本类型非常重要:
- 绝对路径:从文件系统的根目录开始的完整路径
- 相对路径:相对于当前工作目录的路径
Python中处理文件路径的主要问题及解决方案:
- 路径分隔符不一致
不同操作系统使用不同的路径分隔符:Windows使用反斜杠\,而Unix/Linux/Mac使用正斜杠/。这导致跨平台时的路径问题。
# 错误:使用硬编码的Windows风格路径
file_path = "C:\Users\username\data.txt" # 在Windows中可能有效,但\U、\d等可能被解释为转义字符
# 正确:使用os.path模块处理路径
import os
file_path = os.path.join("C:", "Users", "username", "data.txt")
使用os.path.join()函数可以自动使用正确的分隔符,确保路径在所有操作系统上都有效。
- 相对路径与工作目录
Python中,相对路径是相对于当前工作目录的,而不是相对于脚本文件。
# 假设脚本在/home/user/scripts/,但工作目录是/home/user/
open("data.txt") # 尝试打开/home/user/data.txt,而非/home/user/scripts/data.txt
解决方法是使用__file__变量获取脚本的绝对路径,然后构建相对于脚本的路径:
import os
# 获取脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 构建相对于脚本的文件路径
file_path = os.path.join(script_dir, "data.txt")
# 现在可以安全地打开文件
with open(file_path, 'r') as file:
content = file.read()
- 路径中的特殊字符
文件名中的特殊字符或空格可能导致问题:
# 更安全的处理包含特殊字符的路径
from pathlib import Path
file_path = Path("folder with spaces") / "file with-特殊字符.txt"
with open(file_path, 'r') as file:
content = file.read()
- 使用
pathlib模块(Python 3.4+)
pathlib提供了一种更现代、更面向对象的路径处理方式:
from pathlib import Path
# 创建路径对象
data_file = Path("data") / "input" / "file.txt"
# 检查路径是否存在
if data_file.exists():
# 读取文件
content = data_file.read_text()
# 获取文件信息
print(f"文件大小: {data_file.stat().st_size} 字节")
print(f"修改时间: {data_file.stat().st_mtime}")
# 处理路径组件
print(f"文件名: {data_file.name}")
print(f"文件扩展名: {data_file.suffix}")
print(f"父目录: {data_file.parent}")
- 常见文件操作错误及解决方案
# 问题:文件未关闭
f = open("data.txt", "r")
content = f.read()
# 忘记关闭文件 → 可能导致资源泄漏
# 解决方案:使用with语句(上下文管理器)
with open("data.txt", "r") as f:
content = f.read()
# 文件自动关闭,即使发生异常也会关闭
# 问题:文件模式错误
with open("data.txt") as f: # 默认只读模式
f.write("新内容") # 错误!在只读模式下写入
# 解决方案:指定正确的模式
with open("data.txt", "w") as f: # 写入模式
f.write("新内容")
# 问题:编码错误
with open("chinese_text.txt") as f: # 默认使用系统编码
text = f.read() # 可能出现UnicodeDecodeError
# 解决方案:指定正确的编码
with open("chinese_text.txt", encoding="utf-8") as f:
text = f.read() # 正确处理UTF-8编码的文本
通过使用这些最佳实践,你可以避免大多数文件路径和文件操作中的常见错误,编写出更健壮、更跨平台的代码。
2. CSV和JSON数据处理中的常见问题
问题:在处理CSV和JSON数据时,我经常遇到格式错误或编码问题。有什么方法可以更可靠地处理这些数据格式?
回答:CSV和JSON是两种最常用的数据交换格式,但它们确实有一些常见的陷阱。让我详细探讨这些问题及其解决方案。
CSV文件处理
CSV(逗号分隔值)文件看似简单,但有很多细节需要注意:
- 使用csv模块而非手动分割
手动使用split(',')处理CSV是危险的,因为它无法正确处理引号内的逗号、换行符等特殊情况。
# 不推荐:手动分割
with open('data.csv', 'r') as file:
for line in file:
values = line.strip().split(',') # 无法处理引号内的逗号
# 推荐:使用csv模块
import csv
with open('data.csv', 'r', newline='') as file:
reader = csv.reader(file)
for row in reader:
# 现在row是一个包含每个字段的列表
print(row)
- 处理标题行和字典访问
使用DictReader可以通过列名而非索引访问数据:
import csv
with open('data.csv', 'r', newline='', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
# 通过列名访问数据
print(f"姓名: {row['name']}, 年龄: {row['age']}")
- 编码问题
CSV文件可能使用各种编码,尤其是包含非ASCII字符时:
# 处理包含中文等非ASCII字符的CSV
import csv
with open('chinese_data.csv', 'r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)
- 不同分隔符和方言
并非所有CSV文件都使用逗号作为分隔符。有些使用制表符(TSV)或其他字符:
import csv
with open('data.tsv', 'r', newline='') as file:
reader = csv.reader(file, delimiter='\t')
for row in reader:
print(row)
# 或者定义自定义方言
csv.register_dialect('pipes', delimiter='|', quoting=csv.QUOTE_NONE)
with open('data.txt', 'r', newline='') as file:
reader = csv.reader(file, dialect='pipes')
for row in reader:
print(row)
- 类型转换
CSV中的所有数据都以字符串形式读取,需要手动转换类型:
import csv
with open('data.csv', 'r', newline='') as file:
reader = csv.reader(file)
next(reader) # 跳过标题行
for row in reader:
name = row[0]
age = int(row[1]) # 转换为整数
height = float(row[2]) # 转换为浮点数
- 写入CSV文件
写入CSV也需要注意类似的问题:
import csv
data = [
['姓名', '年龄', '城市'],
['张三', 25, '北京'],
['李四', 30, '上海']
]
with open('output.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(data) # 一次写入多行
JSON数据处理
JSON(JavaScript对象表示法)是一种更结构化的数据格式,但也有自己的注意事项:
- 基本读写操作
import json
# 读取JSON文件
with open('data.json', 'r', encoding='utf-8') as file:
data = json.load(file) # 将JSON转换为Python对象
# 写入JSON文件
with open('output.json', 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=4)
# ensure_ascii=False允许保存非ASCII字符
# indent=4使输出格式美观
- 处理格式错误
JSON格式的严格要求可能导致解析错误:
try:
data = json.loads(json_string)
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
print(f"错误位置: 行 {e.lineno}, 列 {e.colno}")
print(f"出错文档片段: {e.doc[e.pos-20:e.pos+20]}")
- 日期和复杂对象的序列化
JSON不直接支持日期、时间或自定义Python对象:
import json
from datetime import datetime
# 自定义JSON编码器
class DateTimeEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat()
return super().default(obj)
data = {'timestamp': datetime.now(), 'value': 42}
# 使用自定义编码器
json_string = json.dumps(data, cls=DateTimeEncoder)
- 大型JSON文件处理
对于大型JSON文件,一次加载到内存可能会有问题:
# 使用ijson库进行流式处理
import ijson
with open('large.json', 'rb') as file:
# 逐项解析
for item in ijson.items(file, 'items.item'):
process_item(item)
- 保持对象顺序
在Python 3.7之前,JSON解析不保证保留字典的键顺序:
# Python 3.7+默认保留顺序
# 对于早期版本,使用collections.OrderedDict
import json
from collections import OrderedDict
with open('data.json', 'r') as file:
data = json.load(file, object_pairs_hook=OrderedDict)
Pandas:处理结构化数据的高级选择
对于更复杂的CSV和JSON处理,pandas库提供了强大的功能:
import pandas as pd
# 读取CSV
df = pd.read_csv('data.csv', encoding='utf-8')
# 读取JSON
df = pd.read_json('data.json')
# 数据操作
filtered_data = df[df['age'] > 25]
average_age = df['age'].mean()
# 写回文件
filtered_data.to_csv('filtered.csv', index=False)
filtered_data.to_json('filtered.json', orient='records')
通过遵循这些最佳实践,你可以避免大多数CSV和JSON处理中的常见陷阱,提高数据处理的可靠性和效率。
3. 数据清洗与预处理常见挑战
问题:在数据分析之前,我经常需要清理数据,但总是觉得很繁琐,有什么高效的数据清洗与预处理技巧吗?
回答:数据清洗和预处理通常占据了数据分析项目的60-80%的时间,这是因为真实数据往往"杂乱无章"。掌握高效的数据清洗技巧可以大大提高你的工作效率。
让我深入探讨数据清洗与预处理中的常见挑战及其解决方案:
1. 处理缺失值
缺失值是数据清洗中最常见的问题之一:
import pandas as pd
import numpy as np
# 加载数据
df = pd.read_csv('data.csv')
# 检测缺失值
print(df.isnull().sum()) # 每列缺失值数量
# 处理缺失值的策略
# 策略1: 删除包含缺失值的行
df_dropped = df.dropna()
# 策略2: 使用平均值、中位数或众数填充
df['age'].fillna(df['age'].mean(), inplace=True) # 均值填充
df['income'].fillna(df['income'].median(), inplace=True) # 中位数填充
df['category'].fillna(df['category'].mode()[0], inplace=True) # 众数填充
# 策略3: 使用前向或后向填充(适用于时间序列)
df['value'].fillna(method='ffill', inplace=True) # 前向填充
df['value'].fillna(method='bfill', inplace=True) # 后向填充
# 策略4: 使用预测模型填充缺失值(高级方法)
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
选择填充策略应基于数据的性质和缺失值的模式。删除数据可能导致样本偏差,而简单填充可能引入噪声。
2. 异常值检测与处理
异常值会严重影响统计分析和模型训练:
# 使用箱线图可视化异常值
import matplotlib.pyplot as plt
plt.boxplot(df['salary'])
plt.title('Salary Distribution with Outliers')
plt.show()
# 使用Z分数检测异常值
from scipy import stats
z_scores = stats.zscore(df['salary'])
outliers = df[abs(z_scores) > 3] # Z分数大于3的通常被视为异常值
# 使用IQR(四分位距)方法检测异常值
Q1 = df['salary'].quantile(0.25)
Q3 = df['salary'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['salary'] < lower_bound) | (df['salary'] > upper_bound)]
# 处理异常值
# 方法1: 删除
df = df[(df['salary'] >= lower_bound) & (df['salary'] <= upper_bound)]
# 方法2: 截断 - 将异常值设置为边界值
df['salary'] = df['salary'].clip(lower_bound, upper_bound)
# 方法3: 替换为NaN然后使用填充方法
df.loc[(df['salary'] < lower_bound) | (df['salary'] > upper_bound), 'salary'] = np.nan
df['salary'].fillna(df['salary'].median(), inplace=True)
不同领域对异常值的定义和处理方式可能不同。例如,在医学研究中,极端值可能表示重要的病例,而不应简单删除。
3. 数据类型转换与格式规范化
不正确的数据类型会导致分析错误:
# 检查数据类型
print(df.dtypes)
# 将字符串转换为数值类型
df['income'] = pd.to_numeric(df['income'], errors='coerce') # 'coerce'将无效值转换为NaN
# 日期时间转换
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# 提取日期特征
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day_of_week'] = df['date'].dt.dayofweek
# 处理分类数据
df['category'] = df['category'].astype('category')
# 规范化文本格式
df['name'] = df['name'].str.strip().str.lower()
确保数据类型正确不仅可以防止错误,还可以提高处理效率,因为某些类型(如category)比通用类型(如object)更节省内存。
4. 文本数据清洗
文本数据通常需要特殊处理:
# 移除特殊字符和标点
import re
df['text'] = df['text'].apply(lambda x: re.sub(r'[^\w\s]', '', str(x)))
# 大小写标准化
df['text'] = df['text'].str.lower()
# 移除停用词
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stop = set(stopwords.words('english'))
df['text'] = df['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop]))
# 词干化或词形还原
from nltk.stem import PorterStemmer, WordNetLemmatizer
nltk.download('wordnet')
stemmer = PorterStemmer()
df['text_stemmed'] = df['text'].apply(lambda x: ' '.join([stemmer.stem(word) for word in x.split()]))
lemmatizer = WordNetLemmatizer()
df['text_lemmatized'] = df['text'].apply(lambda x: ' '.join([lemmatizer.lemmatize(word) for word in x.split()]))
文本清洗是自然语言处理(NLP)的基础步骤,对于后续的文本分析至关重要。
5. 重复数据处理
重复数据会影响分析结果和模型性能:
# 检测重复行
duplicates = df.duplicated()
print(f"发现 {duplicates.sum()} 个重复行")
# 删除完全重复的行
df_no_dupes = df.drop_duplicates()
# 基于特定列删除重复
df_no_dupes = df.drop_duplicates(subset=['name', 'address'], keep='first')
有时,重复可能是部分的或近似的,这需要更复杂的检测方法,如模糊匹配。
6. 数据标准化和规范化
不同尺度的特征会导致某些算法表现不佳:
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
# 标准化(均值为0,方差为1)
scaler = StandardScaler()
df[['height', 'weight', 'income']] = scaler.fit_transform(df[['height', 'weight', 'income']])
# 最小-最大缩放(范围0-1)
min_max_scaler = MinMaxScaler()
df[['height', 'weight', 'income']] = min_max_scaler.fit_transform(df[['height', 'weight', 'income']])
# 鲁棒缩放(对异常值不敏感)
robust_scaler = RobustScaler()
df[['height', 'weight', 'income']] = robust_scaler.fit_transform(df[['height', 'weight', 'income']])
不同的机器学习算法对特征缩放有不同的敏感度。例如,基于距离的算法(如KNN、SVM)对缩放非常敏感,而基于树的算法(如决策树、随机森林)则不太敏感。
7. 特征工程
虽然不严格属于清洗,但特征工程通常与预处理同时进行:
# 创建交互特征
df['bmi'] = df['weight'] / ((df['height']/100) ** 2)
# 多项式特征
df['age_squared'] = df['age'] ** 2
# 二值化
df['is_adult'] = (df['age'] >= 18).astype(int)
# 分箱(将连续变量转换为分类变量)
df['age_group'] = pd.cut(df['age'], bins=[0, 18, 35, 50, 65, 100], labels=['Child', 'Young Adult', 'Adult', 'Middle Aged', 'Senior'])
# 独热编码
df_encoded = pd.get_dummies(df, columns=['category', 'age_group'], drop_first=True)
有效的特征工程可以显著提高模型性能,它通常需要领域知识和创造性思维相结合。
8. 使用数据验证
确保数据符合预期的格式和范围:
# 使用断言进行简单验证
assert df['age'].min() >= 0, "年龄不应为负数"
assert (df['gender'].isin(['M', 'F', 'Other'])).all(), "性别只能是M、F或Other"
# 使用pandera进行更复杂的验证
import pandera as pa
schema = pa.DataFrameSchema({
"age": pa.Column(int, pa.Check.greater_than_or_equal_to(0)),
"income": pa.Column(float, pa.Check.greater_than_or_equal_to(0)),
"gender": pa.Column(str, pa.Check.isin(['M', 'F', 'Other'])),
"email": pa.Column(str, pa.Check.str_matches(r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'))
})
validated_df = schema.validate(df)
数据验证可以帮助你在早期发现数据问题,避免在分析或建模过程中出现意外错误。
9. 自动化数据清洗流程
对于重复的数据清洗任务,可以创建自动化流程:
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# 定义数值和分类特征
numeric_features = ['age', 'income', 'height', 'weight']
categorical_features = ['gender', 'occupation', 'education']
# 创建数值特征转换管道
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# 创建分类特征转换管道
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 组合转换器
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 创建完整管道(包括模型)
from sklearn.ensemble import RandomForestClassifier
full_pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier())
])
# 使用管道处理数据并训练模型
X = df.drop('target', axis=1)
y = df['target']
full_pipeline.fit(X, y)
# 保存管道以便将来使用
from joblib import dump
dump(full_pipeline, 'preprocessing_model_pipeline.joblib')
使用管道可以确保预处理步骤在训练和预测时一致,并简化工作流程。
掌握这些数据清洗和预处理技巧,可以帮助你更有效地处理各种数据挑战,为后续的分析和建模奠定坚实基础。
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!


















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











