






参考笔记:https://github.com/dxc19951001/Study_TF2.0/blob/master/tensorflow2.md
在神经网络中,如果不对上一层结点的输出做非线性转换的话,再深的网络也是线性模型,只能把输入线性组合再输出,不能学习到复杂的映射关系,因此需要使用激活函数这个非线性函数做转换。引入非线性转换后,神经网络的表达能力大大提升,使其能够逼近任何复杂的函数关系,这是基于万维空间中任何函数都可以由足够深的神经网络逼近的通用逼近定理的思想。
激活函数:
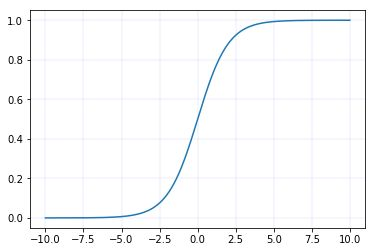
1,tf.nn.sigmoid(x)
sigmoid函数图像
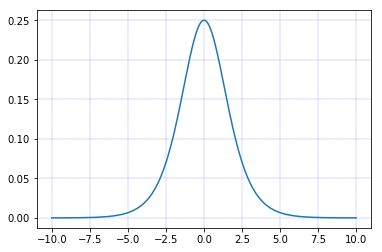
sigmoid导数图像
目前使用sigmoid函数为激活函数的神经网络已经很少了
特点
(1)易造成梯度消失
深层神经网络更新参数时,需要从输入层到输出层,逐层进行链式求导,而sigmoid函数的导数输出为[0,0.25]间的小数,链式求导需要多层导数连续相乘,这样会出现多个[0,0.25]间的小数连续相乘,从而造成结果趋于0,产生梯度消失,使得参数无法继续更新。
(2)输出非0均值,收敛慢
希望输入每层神经网络的特征是以0为均值的小数值,但sigmoid函数激活后的数据都时整数,使得收敛变慢。
(3)幂运算复杂,训练时间长
sigmoid函数存在幂运算,计算复杂度大。
2,tf.math.tanh(x)
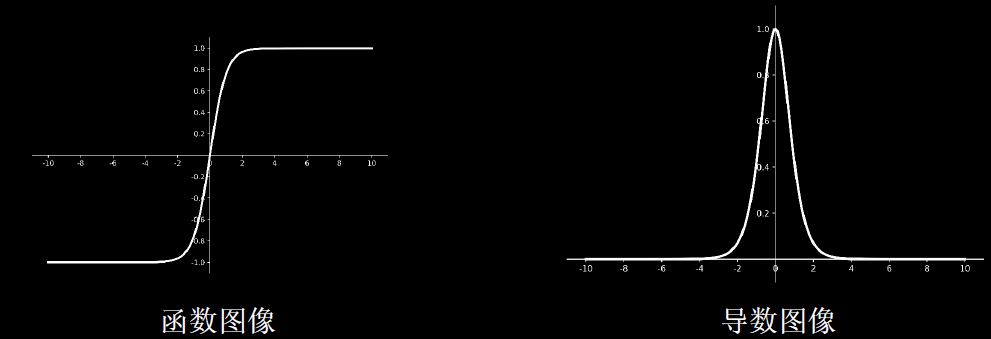
特点
(1)输出是0均值
(2)易造成梯度消失
(3)幂运算复杂,训练时间长
3,tf.nn.relu(x)
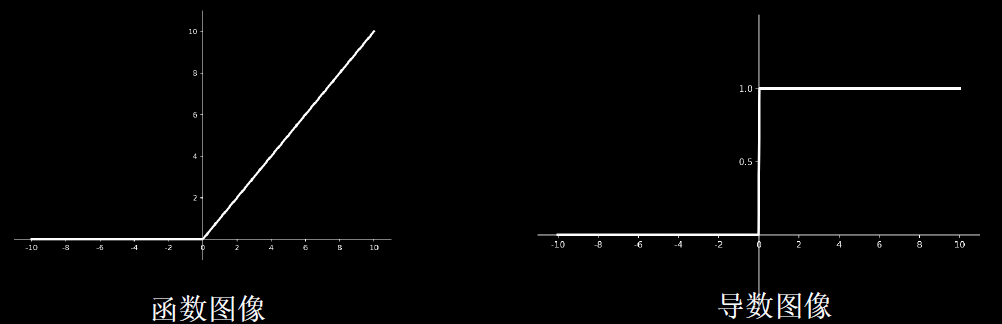
优点:
- 解决了梯度消失问题(在正区间)
- 只 需判断输入是否大于0,计算速度快
- 收敛速度远快于sigmoid和tanh
缺点:
- 输出非0均值,收敛慢
- Dead ReIU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
4,tf.nn.leaky_relu(x)
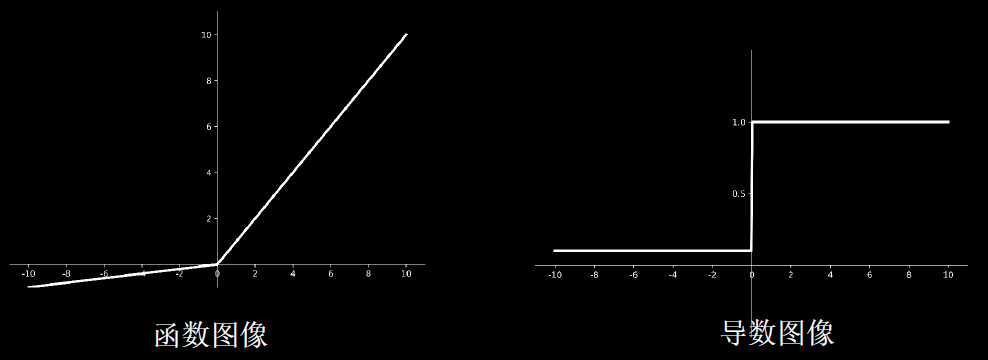
理论上来讲,Leaky Relu有Relu的所有优点,外加不会有Dead Relu问题,但是在实际操作当中,并没有完全证明Leaky Relu总是好于Relu。
总结
- 首选relu激活函数;
- 学习率设置较小值;
- 输入特征标准化,即让输入特征满足以0为均值,1为标准差的正态分布;
- 初始参数中心化,即让随机生成的参数满足以0为均值,
 为标准差的正态分布。
为标准差的正态分布。















 1584
1584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









