







文章目录
一、文献简明(zero)
领域:NLP、预训练语言模型
标题:[2019] Language Models are Unsupervised Multitask Learners (GPT-2)(语言模型是无监督多任务学习器)
作者:OpenAI贡献:提出了GPT-2模型,展示了大规模预训练语言模型在零样本和少样本任务中的强大能力。
链接:https://storage.prod.researchhub.com/uploads/papers/2020/06/01/language-models.pdf
二、快速预览(first)
1、标题分析
《语言模型是无监督多任务学习器》
(一)背景
- GPT - 2(Generative Pre - trained Transformer - 2)是 OpenAI 开发的一种基于 Transformer 架构的大型语言模型。它在自然语言处理领域具有重要意义,是深度学习在语言生成方面的一个里程碑式的成果。
- 这个标题体现了 GPT - 2 的核心特性,即它是一种语言模型,同时具备无监督学习和多任务学习的能力。
(二)无监督学习
- 无监督学习是指模型在没有明确标注的训练数据的情况下进行学习。对于 GPT - 2 来说,它主要通过大量的文本数据(如书籍、网页等)进行训练,这些数据没有像监督学习那样有明确的标签(例如分类任务中的类别标签)。
- 它通过预测文本序列中的下一个单词来学习语言的模式和结构。例如,给定句子 “The cat sat on the”,模型会尝试预测下一个单词,通过这种方式逐渐理解语言的语法、语义等规则。
(三)多任务学习
- GPT - 2 可以在多种自然语言处理任务上表现出色,而不需要针对每个任务进行单独的训练。这些任务包括但不限于文本生成、机器翻译、问答系统、文本分类等。
- 它能够利用在预训练阶段学到的语言知识,通过微调(在特定任务上进行少量的训练)或者直接使用(零样本学习)的方式,适应不同的任务场景。例如,在问答任务中,它可以理解问题的语义并生成相关的答案;在文本生成任务中,它可以生成连贯、符合语法的文本内容。
2、作者介绍

……
3、引用数
……
4、摘要分析

(1)翻译
自然语言处理任务,例如问答、机器翻译、阅读理解和文本摘要,通常采用在特定任务数据集上进行监督学习的方法。我们展示了当语言模型在一个新的包含数百万网页的WebText数据集上进行训练时,无需任何明确的监督,语言模型就能开始学习这些任务。当模型在给定文档和问题的情况下进行条件化,生成的答案在CoQA数据集上达到了55的F1分数,匹配或超过了4个基线系统中3个的性能,而没有使用127,000多个训练样本。语言模型的能力对于零样本任务迁移的成功至关重要,并且增加其能力可以在任务间以对数线性的方式提高性能。我们最大的模型GPT-2是一个具有15亿参数的Transformer,在8个测试的语言建模数据集中7个上实现了最先进的结果,即使在零样本设置中仍然优于WebText。模型的样本反映了这些改进,并包含连贯的文本段落。这些发现表明,构建能够从自然发生的示例中学习执行任务的语言处理系统是一个有前景的方向。
(2)分析
-
研究背景:文章开头提到自然语言处理任务通常需要在特定任务的数据集上进行监督学习。这表明传统的NLP任务训练方法依赖于大量标注数据。
-
研究方法:作者展示了一种新的方法,即在没有明确监督的情况下,通过在WebText数据集上训练语言模型,模型能够学习执行多种NLP任务。这种方法减少了对标注数据的依赖。
-
实验结果:在CoQA数据集上的实验结果显示,模型在没有使用大量训练样本的情况下,达到了与基线系统相匹配或更好的性能。这表明模型具有强大的零样本学习能力。
-
模型能力:文章强调了语言模型的能力对于零样本任务迁移的重要性,并指出增加模型能力可以显著提高任务间迁移的性能。
-
模型介绍:GPT-2是一个具有15亿参数的Transformer模型,在多个语言建模数据集上实现了最先进的结果,即使在零样本设置中也表现出色。
-
研究意义:文章最后指出,这些发现表明,构建能够从自然发生的示例中学习执行任务的语言处理系统是一个有前景的方向。这为未来的研究提供了新的思路和方法。
总的来说,这篇文章展示了通过在大规模无标注数据集上训练语言模型,可以在没有明确监督的情况下学习执行多种NLP任务,这对于减少对标注数据的依赖和提高模型的泛化能力具有重要意义。
5、总结分析

(1)翻译
当一个大型语言模型在一个足够大且多样化的数据集上进行训练时,它能够在许多领域和数据集上表现良好。GPT-2在8个测试的语言建模数据集中的7个上实现了零样本学习(zero-shot learning)的最先进的性能。模型能够在零样本设置中执行的任务的多样性表明,为了最大化足够多样化文本语料库的可能性而训练的高容量模型开始学习如何在不需要明确监督的情况下执行大量任务。
(2)分析
-
模型性能:结论部分强调了大型语言模型在多样化数据集上训练后的性能。这表明通过在大规模和多样化的数据集上进行训练,模型能够适应并执行多种不同的任务。
-
GPT-2的表现:特别提到了GPT-2模型在8个测试数据集中的7个上实现了最先进的零样本学习性能。这说明GPT-2在没有特定任务训练的情况下,仍然能够在多个任务上表现出色。
-
任务多样性:文章指出模型能够执行的任务多样性,这表明模型不仅在特定任务上表现良好,而且在多种不同的任务上都能达到较高的性能。
-
高容量模型的优势:结论中提到高容量模型(即参数众多的模型)在多样化文本语料库上训练的优势。这些模型能够学习到更广泛的语言模式和结构,从而在没有明确监督的情况下执行多种任务。
-
零样本学习的重要性:文章强调了零样本学习的重要性,即模型能够在没有特定任务训练样本的情况下执行任务。这对于减少对大量标注数据的依赖和提高模型的泛化能力具有重要意义。
-
未来研究方向:结论部分暗示了未来研究的方向,即继续探索和开发能够在多样化数据集上训练并执行多种任务的高容量模型。
总的来说,这段结论强调了大型语言模型在多样化数据集上训练后的强大性能,特别是在零样本学习场景下的能力,为未来的研究和应用提供了新的思路和方向。
6、部分图表
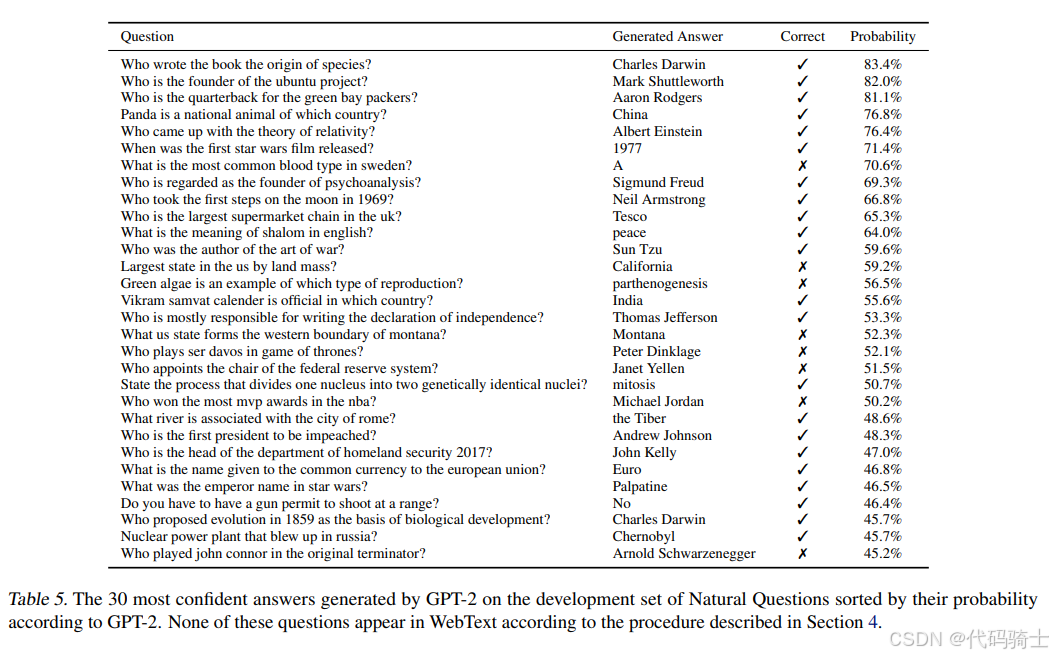
该图表展示了GPT-2在Natural Questions数据集上生成的30个最自信的答案,这些答案按照GPT-2给出的概率排序。图表中包含以下几个关键部分:
-
问题(Question):列出了30个不同的问题,这些问题覆盖了广泛的主题,如科学、历史、地理等。
-
生成的答案(Generated Answer):GPT-2为每个问题生成的答案。
-
正确性(Correct):标记了GPT-2生成的答案是否正确。图表中使用了对勾(✓)和叉号(✗)来表示答案的正确与否。
-
概率(Probability):表示GPT-2对其生成答案的自信程度,以百分比形式表示。
主要观察:
- 高正确率:在30个问题中,GPT-2正确回答了22个,正确率为73.3%。这表明GPT-2在处理多样化问题时具有较高的准确性。
- 自信但错误:有些问题的答案虽然GPT-2给出了较高的自信度,但答案是错误的。例如,关于“谁被认为是精神分析学的创始人?”的问题,GPT-2给出了69.3%的自信度,但答案是错误的(正确答案应为Sigmund Freud)。
- 低自信度的正确答案:有些问题的答案虽然正确,但GPT-2的自信度相对较低。例如,关于“谁提出了1859年的进化论作为生物发展的基础?”的问题,GPT-2给出了45.7%的自信度,但答案是正确的(Charles Darwin)。
- 常见错误类型:错误答案通常涉及对特定事实的误解或混淆。例如,关于“谁在1969年首次登上月球?”的问题,GPT-2错误地回答了Neil Armstrong,而正确答案应为Buzz Aldrin(第一个踏上月球表面的人)。
结论:
图表显示GPT-2在处理多样化问题时具有较高的正确率,但也存在一些自信但错误的答案。这表明尽管GPT-2在许多情况下能够提供准确的答案,但在某些情况下仍可能产生误导性的信息。因此,在使用这类模型时,需要谨慎对待其输出,并在必要时进行验证。此外,这些结果也表明,尽管GPT-2在处理多样化问题时表现出色,但仍有改进的空间,特别是在提高对特定事实的准确性方面。
7、引言分析
(1)翻译
机器学习系统现在在它们被训练的任务上表现出色(期望中),这是通过结合大型数据集、高容量模型和监督学习实现的(Krizhevsky 等人,2012)(Sutskever 等人,2014)(Amodei 等人,2016)。然而,这些系统是脆弱的,对数据分布的轻微变化和任务规范都很敏感(Recht 等人,2018)和(Kirkpatrick 等人,2017)。当前的系统更好地被描述为狭窄的专家,而不是有能力的通才。我们希望转向更通用的系统,这些系统可以执行许多任务——最终无需为每个任务手动创建和标记训练数据集。
创建机器学习系统的主导方法是收集一个期望任务的正确行为的训练示例数据集,训练一个系统来模仿这些行为,然后在独立同分布(IID)保留示例上测试其性能。这在使狭窄专家取得进展方面做得很好。但是,标题模型(Lake 等人,2017)、阅读理解系统(Jia & Liang,2017)和图像分类器(Alcorn 等人,2018)在可能的输入的多样性和变化性上经常表现出不稳定的行为,这突出了这种方法的一些缺点。
我们的怀疑是,单一任务训练在单一领域数据集上的普遍性是当前系统中观察到的泛化能力缺乏的一个主要原因。使用当前架构朝着具有鲁棒性的系统取得进展可能需要在广泛的领域和任务上进行训练和衡量性能。最近,已经提出了几个基准,如GLUE(Wang 等人,2018)和decanLP(McCann 等人,2018),开始研究这个问题。
多任务学习(Caruana,1997)是一个有希望的框架,用于提高一般性能。然而,NLP中的多任务训练仍然处于起步阶段。最近的工作报告了适度的性能提升(Yogatama 等人,2019),迄今为止最有雄心的两个努力分别在总共10和17(数据集,目标)对上进行了训练(McCann 等人,2018)(Bowman 等人,2018)。从元学习的角度来看,每对(数据集,目标)都是从数据集和目标的分布中采样的单个训练示例。当前的机器学习系统需要数以百计到数千计的示例来推导出泛化良好的函数。这表明多任务训练可能只需要与当前方法一样多的有效训练对就能实现其承诺。很难继续按当前技术所需的程度扩展数据集的创建和目标的设计。这促使我们探索执行多任务学习的其他设置。
当前在语言任务上表现最好的系统利用了预训练和监督微调的组合。这种方法有着悠久的历史,并趋向于更灵活的迁移形式。首先,学习了词向量并用作任务特定架构的输入(Mikolov 等人,2013)(Collobert 等人,2011),然后将递归网络的上下文表示转移(Dai & Le,2015)(Peters 等人,2018),最近的工作表明不再需要任务特定的架构,转移许多自注意力块就足够了(Radford 等人,2018)(Devlin 等人,2018)。
这些方法仍然需要监督训练才能执行任务。当只有最小或没有监督数据可用时,另一条研究线展示了语言模型执行特定任务的前景,如常识推理(Schwartz 等人,2017)和情感分析(Radford 等人,2017)。
在本文中,我们将这两条研究线联系起来,并继续更通用的迁移方法的趋势。我们证明了语言模型可以在零样本设置中执行下游任务——无需任何参数或架构修改。我们通过强调语言模型在零样本设置中执行广泛任务的能力来证明这种方法显示出潜力。我们根据任务的不同,取得了有希望的、有竞争力的和最先进的结果。
(2)分析
-
机器学习系统的局限性:
- 尽管机器学习系统在特定任务上表现出色,但它们对数据分布的轻微变化和任务规范非常敏感。
- 当前的系统更像是狭窄的专家,而不是通用的通才。
-
多任务学习的潜力:
- 多任务学习被认为是提高系统泛化能力的一个有希望的框架。
- 然而,NLP中的多任务训练仍处于起步阶段,且需要大量的训练示例来实现良好的泛化。
-
预训练和监督微调的组合:
- 当前在语言任务上表现最好的系统利用了预训练和监督微调的组合。
- 这种方法有着悠久的历史,并趋向于更灵活的迁移形式。
-
零样本学习:
- 文章提出了一种新的方法,即在零样本设置中执行任务,无需任何参数或架构修改。
- 这种方法展示了语言模型在执行广泛任务方面的潜力,并取得了有希望的结果。
-
未来研究方向:
- 需要探索更多的设置和方法来实现多任务学习和零样本学习,以提高系统的泛化能力和鲁棒性。
8、全部标题
以下是文档中所有标题及其中文翻译:
-
Abstract
摘要 -
1. Introduction
- 引言
-
2. Approach
2. 方法 -
2.1. Training Dataset
2.1. 训练数据集 -
2.2. Input Representation
2.2. 输入表示 -
2.3. Model
2.3. 模型 -
3. Experiments
3. 实验 -
3.1. Language Modeling
3.1. 语言建模 -
3.2. Children’s Book Test
3.2. 儿童图书测试 -
3.3. LAMBADA
3.3. LAMBADA -
3.4. Winograd Schema Challenge
3.4. 温格拉德模式挑战 -
3.5. Reading Comprehension
3.5. 阅读理解 -
3.6. Summarization
3.6. 摘要 -
3.7. Translation
3.7. 翻译 -
3.8. Question Answering
3.8. 问答 -
4. Generalization vs Memorization
4. 泛化与记忆 -
5. Related Work
5. 相关工作 -
6. Discussion
6. 讨论 -
7. Conclusion
7. 结论 -
Acknowledgements
致谢 -
References
参考文献 -
Appendix A: Samples
附录A:样本 -
8.1. Model capacity
8.1. 模型容量 -
8.2. Text Memorization
8.2. 文本记忆 -
8.3. Diversity
8.3. 多样性 -
8.4. Robustness
8.4. 鲁棒性
9、参考文献
以下是文档中前十条参考文献及其中文翻译:
-
Al-Rfou, R., Choe, D., Constant, N., Guo, M., and Jones, L. Character-level language modeling with deeper self-attention. arXiv preprint arXiv:1808.04444, 2018.
阿尔-鲁福,R.,乔,D.,康斯坦特,N.,郭,M.,琼斯,L. 具有更深层次自注意力的字符级语言建模。arXiv预印本arXiv:1808.04444,2018。 -
Alberti, C., Lee, K., and Collins, M. A bert baseline for the natural questions. arXiv preprint arXiv:1901.08634, 2019.
阿尔贝蒂,C.,李,K.,柯林斯,M. 自然问题的BERT基线。arXiv预印本arXiv:1901.08634,2019。 -
Alcorn, M. A., Li, Q., Gong, Z., Wang, C., Mai, L., Ku, W.-S., and Nguyen, A. Strike (with) a pose: Neural networks are easily fooled by strange poses of familiar objects. arXiv preprint arXiv:1811.11553, 2018.
阿尔康,M. A.,李,Q.,龚,Z.,王,C.,迈,L.,古,W.-S.,阮,A. 摆个姿势(with):神经网络很容易被熟悉物体的奇怪姿势愚弄。arXiv预印本arXiv:1811.11553,2018。 -
Amodei, D., Ananthanarayanan, S., Anubhai, R., Bai, J., Battenberg, E., Case, C., Casper, J., Catanzaro, B., Cheng, Q., Chen, G., et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In International Conference on Machine Learning, pp. 173–182, 2016.
阿莫代伊,D.,阿南塔纳拉亚南,S.,阿努拜,R.,白,J.,巴滕贝格,E.,凯斯,C.,卡斯珀,J.,卡坦扎罗,B.,程,Q.,陈,G.,等。深度语音2:英语和普通话的端到端语音识别。在国际机器学习会议上,页码173-182,2016。 -
Artetxe, M., Labaka, G., Agirre, E., and Cho, K. Unsupervised neural machine translation. arXiv preprint arXiv:1710.11041, 2017.
阿尔特谢,M.,拉巴卡,G.,阿吉雷,E.,赵,K. 无监督神经机器翻译。arXiv预印本arXiv:1710.11041,2017。 -
Artetxe, M., Labaka, G., and Agirre, E. An effective approach to unsupervised machine translation. arXiv preprint arXiv:1902.01313, 2019.
阿尔特谢,M.,拉巴卡,G.,阿吉雷,E. 一种有效的无监督机器翻译方法。arXiv预印本arXiv:1902.01313,2019。 -
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
巴,J. L.,基罗斯,J. R.,欣顿,G. E. 层归一化。arXiv预印本arXiv:1607.06450,2016。 -
Bajgar, O., Kadlec, R., and Kleindienst, J. Embracing data abundance: Booktest dataset for reading comprehension. arXiv preprint arXiv:1610.00956, 2016.
巴吉尔,O.,卡德尔克,R.,克莱因迪恩斯特,J. 拥抱数据丰富:阅读理解的Booktest数据集。arXiv预印本arXiv:1610.00956,2016。 -
Barz, B. and Denzler, J. Do we train on test data? purging cifar of near-duplicates. arXiv preprint arXiv:1902.00423, 2019.
巴尔兹,B. 和登兹勒,J. 我们在测试数据上训练吗?清除CIFAR中的近重复项。arXiv预印本arXiv:1902.00423,2019。 -
Bengio, Y., Ducharme, R., Vincent, P., and Jauvin, C. A neural probabilistic language model. Journal of machine learning research, 3(Feb):1137–1155, 2003.
本吉奥,Y.,杜夏尔姆,R.,文森特,P.,和若万,C. 一种神经概率语言模型。机器学习研究杂志,3(二月):1137-1155,2003。


















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











