







利用激光雷达扫描的时空信息和不同的表示方式来提高激光雷达的 MOS 性能.
与LMNet相比,提出了一种新的双分支结构,首先 分别处理空间和时间信息,然后使用 运动引导注意力模块将它们融合在一起.
待解决的问题
- 纯点云的规模一大计算速度和精度跟不上
- 稀疏体素卷积可以减轻点云的计算负担,但体素化会引入信息丢失
- 基于投影的range图像被用作相对轻量级的中间表示。但是在反投影回 3D 的过程中会导致边界模糊
因此,本文建议不使用单一表示,而是首先使用基于RV图像的主干来获得粗略分割,然后使用轻量级的3D体素稀疏卷积模块来细化分割结果
具体工作
RV图略
残差图略
Meta-Kernel Convolution—最早在RangeDet中提出
由于球面投影的降维,在距离图像上使用二维卷积不能充分利用三维几何信息。这是由于与 RGB 图像相比, RV 图是有深度和反射强度信息的,这使其更类似一个笛卡尔坐标系统。然而标准卷积是为常规像素坐标的 2D 图像设计的。对于卷积核内的每个像素,权重只取决于像素坐标,这不能完全利用笛卡尔坐标的几何信息。(就是说,在 RV图 上看上去距离很近的两个点可能在实际点云中深度差距非常大)

如图箭头指的两个点虽然 2D 图上离得很近但是在点云里一个是车一个是路
因此 Meta-Kernel Convolution 针对传统 Convolution 进行修改。我们首先将标准卷积分解为四个部分:采样、权重获取、乘法和聚合

可以看出,传统 kernel 在卷积计算中起到权重 wj 的作用
而 Meta-Kernel Convolution 在乘法和聚合阶段都没有变化,而是对 kernel 作出修改:
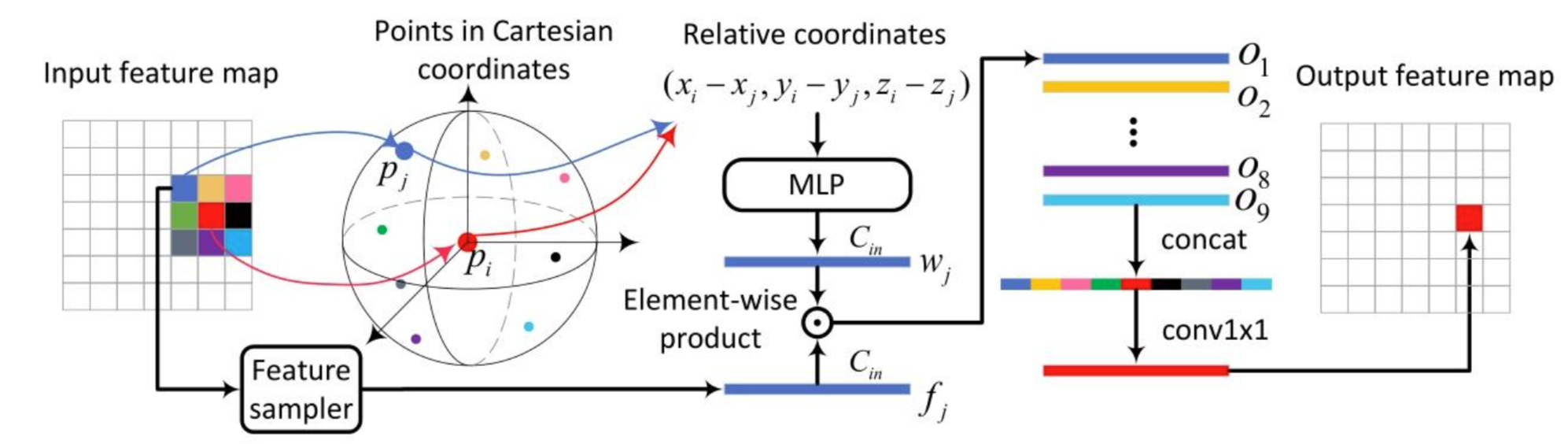
解释上图就是,首先把输入的 kernel 特征图中 3x3 的区域对应到笛卡尔坐标系,比如中心点为 Pi,边缘点为 Pj,之后计算边缘点相对于中心点的相对坐标。将该相对坐标输入到具有两个全连接层的 MLP 中,得到 Pj 的权重 Wj 。之后将9个点在原始 kernel 图上的特征 fj 与 Wj 进行逐元素乘积,得到9个输出向量 Oj ,将9个向量进行拼接,最终通过一个 1x1 卷积变换通道得到最终的结果
网络结构
网络架构基于 SalsaNext(单个编码器和解码器网络)。我们将其扩展并修改为双分支和双头网络。
RV 图像分支(Enc-a)用于对外观特征进行编码,残差图像分支(Enc-M)用于对时间运动信息的进行编码,一个用于对 Enc-a 和 Enc-M 的特征进行解码的具有 Skip Connection 的 ImageHead,以及用于进一步细化分割结果的 PointHead

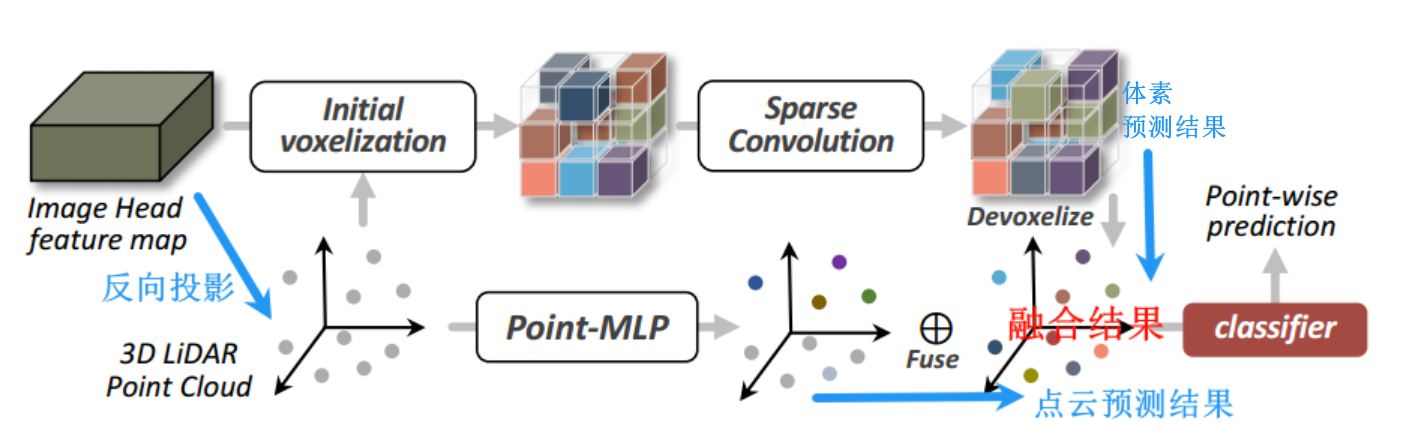
具体而言,在特征编码阶段,我们首先使用 Meta-Kernel 算子来更好地捕捉 3D 空间信息,然后使用运动注意力模块来更有效地融合从残差图像中提取的运动信息。在解码的最后阶段,除了由 ImageHead 处理的 RV 图像上的损失之外,我们还将 2D 特征反向投影到 3D 点云,并使用轻量级稀疏卷积模块 PointHead 来细化分割结果。(像素筛选也叫像素拖拽)
网络结构----运动引导注意力模块
(LMNet直接将距离图像和残差图像连接在一起作为原始SalsaNext的输入,我们使用两个特定分支分别从距离图像中提取外观特征和从残差图像中提取运动特征)
该算法添加了空间通道注意力模块,以从残差图像中提取运动信息。这样的运动信息加强外观特征中某些重点区域的响应,并通过下列公式(3)(4)计算,最终生成一个时空融合特征:
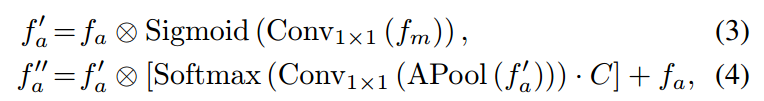
首先通过运动特征fm使用空间注意力来强调当前外观特征fa上的空间位置,并生成运动显著特征f’a。其次,我们采用通道注意力来增强基本属性的响应,并生成最终的时空融合特征f’'a
整体结构如下图: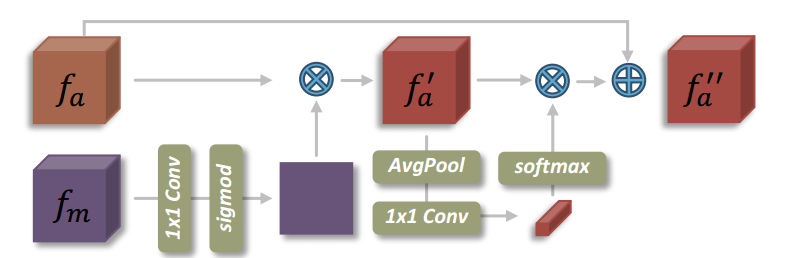
网络结构----PointHead,细化分割结果
将最后一层的输出的 2D 特征图反向投影到原始点云位置,然后对其进行体素化+稀疏卷积,得到一支的分割误差;之后将其与另一支轻量级的直接点云卷积所得到的预测误差结合,作为最终误差
损失函数
总损失函数结合了加权交叉熵 (weighted cross-entropy) 和 Lovász Softmax 损失,L=Lwce+Lls
训练细节:
- 上一节的 PointHead 中,体素预测和点云预测都使用这种融合损失函数 L
- 在训练 PointHead 时,固定大网络,在输出 RV 分割图不变的情况下训练 PointHead 网络
实验结果
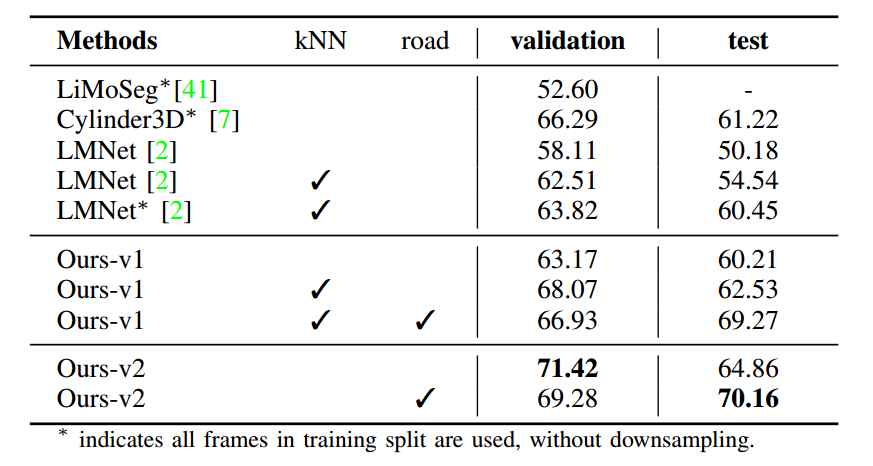
表格中 kNN 代表 kNN 后处理方法,在 RangeNet++ 中被提出
Ours-v1 代表不使用 PointHead 后处理,Ours-v2 代表使用
road 代表使用了改进过的 KITTI-road 标记数据集
分析可得,该方法在不使用后处理的情况下已经得到了较高的交并比,且如果使用 PointHead 后处理,准确率也高于使用 kNN 后处理方法。















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









