







用RV的
算法优点
- 准确地对 LiDAR only 点云进行语义分割
- 可以推断完整原始点的语义标签。即使在 3D转2D 和 CNN 过程中忽略了很多点云点,也能避免在语义分割后的图像点还原点云时被丢弃或错分
- 计算速度快,超过了 Velodyne 扫描仪的帧工作速率(10Hz)
RangeNet++做的事情:
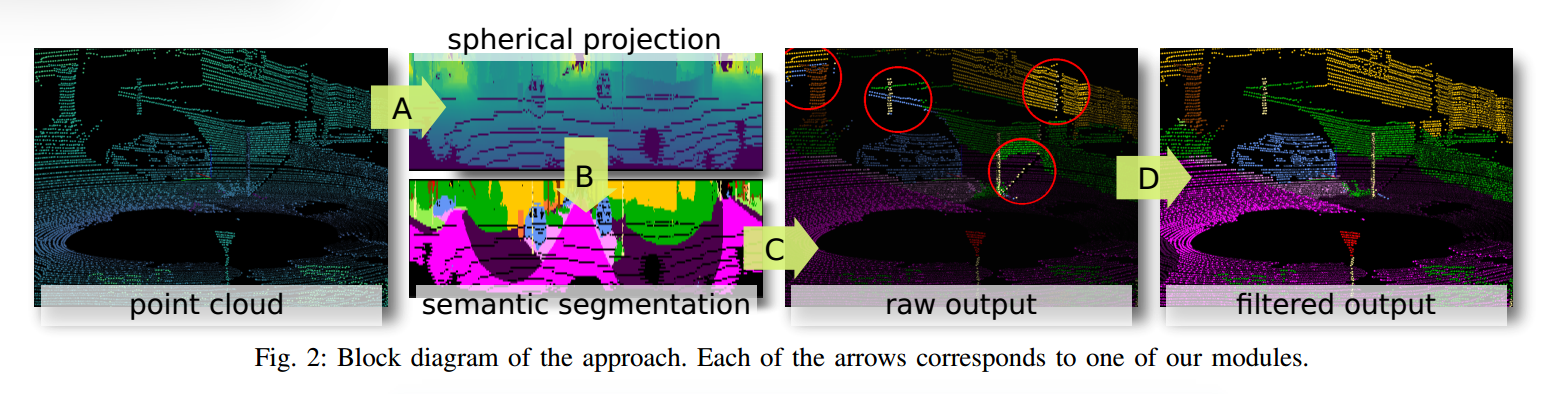
A:将输入点云转换为RV图像表示
B:2D全卷积语义分割
C:将分割好的 2D 图语义转移到 3D 点云,在原始点云中恢复所有点
D:基于有效距离图像的 3D 点云图像后处理,使用对所有点进行操作的新开发的 3D-kNN 搜索来清除点云中不需要的错误和伪影
A
一般的RV变化,见这里
B
RangeNet++使用的 2D图像语义分割 CNN 网络:
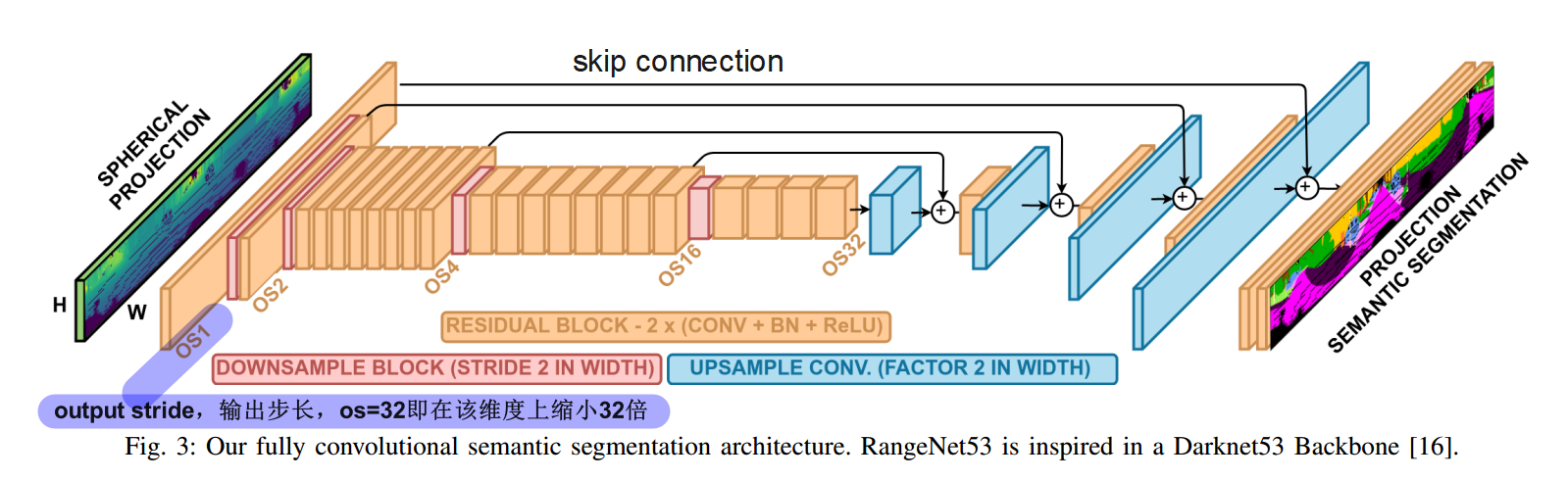
为了在垂直方向上保留信息,我们只在水平方向上进行SubSampling。
损失函数:加权交叉熵: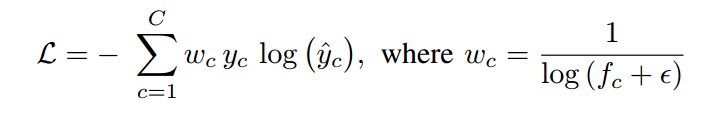 ,可以看出类别的权重与其出现的频率成反比,对于数量小但很重要的点(“行人”比之于“道路”)有更多关注
,可以看出类别的权重与其出现的频率成反比,对于数量小但很重要的点(“行人”比之于“道路”)有更多关注
C
主要要克服 2D 点对点云点的缺失问题
由于最初是从点云生成RV图像,这意味着可能从原始点云表示中删除大量点。尤其是为了使CNN的计算速度更快,对点的省略尤其突出。例如,将130000个点投影到[64 × 512]范围的图像上的扫描,将仅剩余32768个点。
因此,为了给原始点云表示中的所有点都赋予一个语义,我们使用初始渲染过程中获得的所有 pi 的所有 (u; v) 对,并用每个点对应的图像坐标对范围图像进行索引。
D
点云后处理问题
一旦标签被投影到原始点云中,存储在同一个像素中的两个或多个点将获得相同的语义标签,(其实就是遮挡,比如路中间的栅栏挡住了后面的点云)如果我们希望使用更小范围的图像表示来推断语义,这个问题就会变得更强
具体如下图
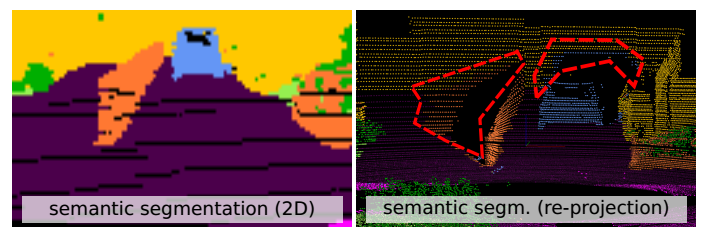
RV图像(左)中的栅栏和汽车都被赋予了适当的语义标签,但在将语义发送回原始点云(右)的过程中,标签也被投影为“阴影”
为了解决这个问题,我们提出了一个快速的、支持gpu的k近邻(kNN)搜索,直接在输入点云中操作

通过上图实验结果可以看出经过后处理的 IoU 和 bIoU 得分都有提升















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









