







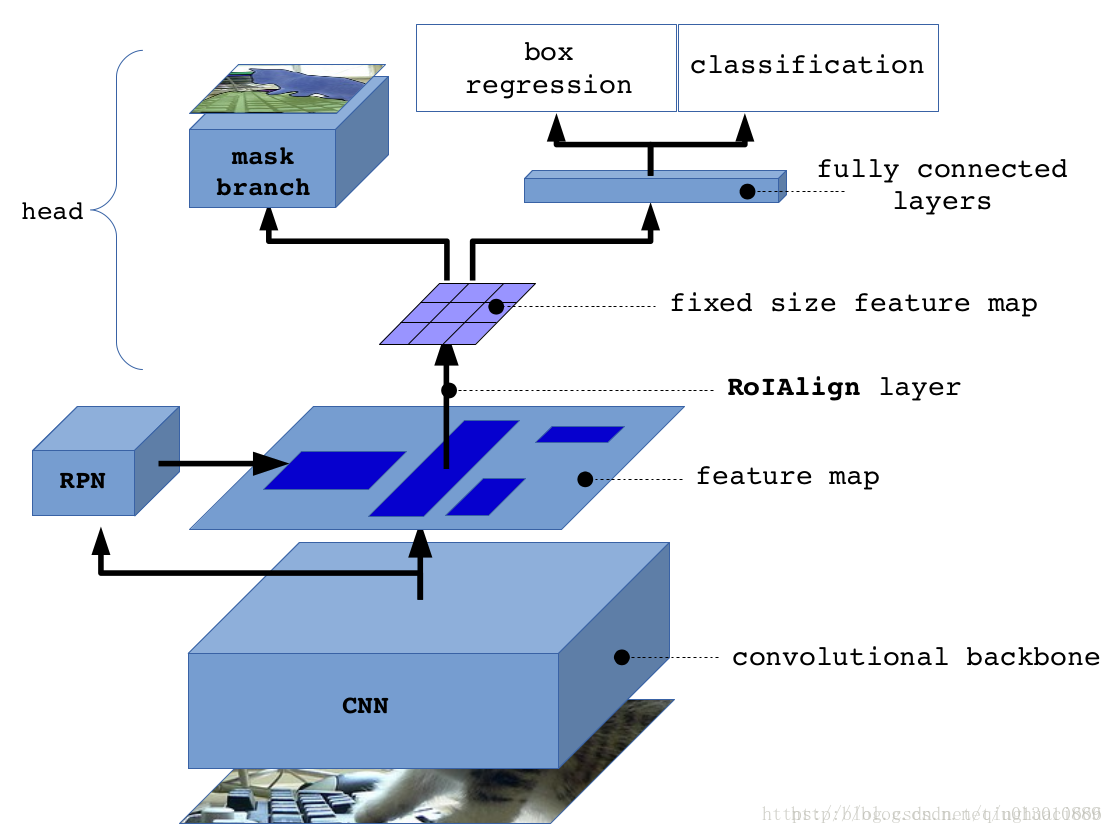
Mask R-CNN
提出目的
基于全景分割,精细分割效果貌似不如UNet
实现目标实例语义分割(object instance segmentation).
改进点(Faster RCNN)
- ROI Pooling->ROIAlign
- 在原来的faste rcnn 部分并联一个mask分支(FCN实现)
- 解耦分类和语义分割mask,mask分支负责生成mask,class分支就负责判断类别
- Mask R-CNN is based on an instance-first strategy

比较
- mask rcnn是一个小的应用在每个RoI上的FCN,生成分割蒙版(segmentation mask),独立分割,不再预测类别。
- 经典语义分割目标是将每个像素分类到一个固定的类别集合中,而不区分对象实例,先分割出来再预测类别。
- 经典目标检测目标是分类并用bounding box定位。
GAP 和FCN
- 两个作用差不多,减少参数,起到FC作用。FCNpadding可调。
- FCN做语义分割会在最后加上一层转置卷积,上采样变成原图大小。
- FCN卷积操作和全连接相乘再相加操作一样,可以把FC里每一个节点的权重reshape后当作conv的一个卷积核的参数。
- 现在在代替FC方面GAP用来替代FCN,因为FCN参数过大。
优点
- 并联结构独立预测更快
- 用了RoIAlign更准
RoIAlign
注意:RoI在原图上
roi pooling过程:
- 原图的候选框映射到feature map上,例如665* 665 映射到feature map25* 25上为665/32=20.78,取整为20,这是第一次量化
- 如果pooling输出为7*7,那么会把上面映射的feature划分成49个同等大小的bin,每个bin大小为20/7=2.86,取整后为2,这是第二次量化
- 每个bin里取最大,max poolng,得到7*7大小的feature map
roialign过程:
由于上述roi pooling过程的两次量化(取整操作)会造成misalignment,为了做精细的语义分割,roialign实现了pixel-to-pixel alignment,没有取整操作。

下图align输出为2* 2,和我解释的7*7不一样:

- 原图的RoI映射到feature map上不取整(Figure 3中align输出为2* 2),假设还是665/32=20.78,保留浮点数
- 直接将映射的feature map分割为7* 7大小(align输出大小)的feature map,划分成几个同等大小的区域
- 文章中采样点数为4,表示对每个bin,平分四份,取中心点位置(红叉),中心点的像素采用双线性插值法计算(中心和其所在的feature方格的四个顶点,左上角顶点才是方格的值对应的点),一个bin得到四个值(左上角)
- 每个bin分别取max作为其值,得到最终输出。
对于有较多小物体的图片使用RoIAlign会更加精确。
关于最终的采样结果对采样点的位置,以及采样点的个数并不敏感。
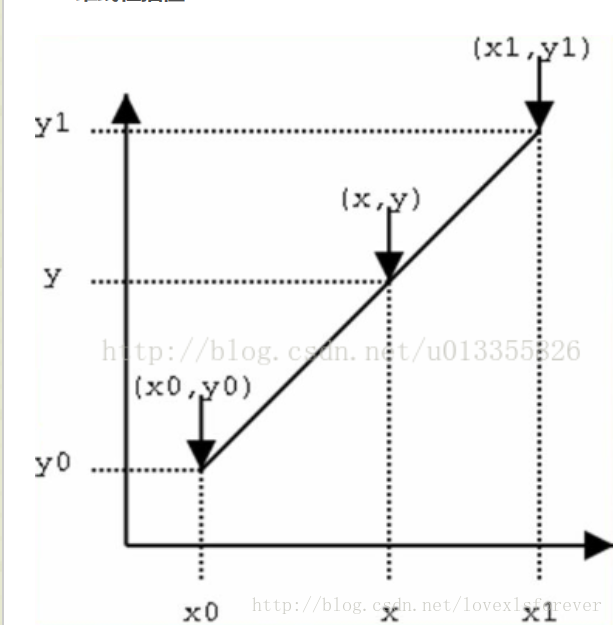
单线性插值
已知数据 (x0, y0) 与 (x1, y1),要计算 [x0, x1] 区间内某一位置 x 在直线上的y值。
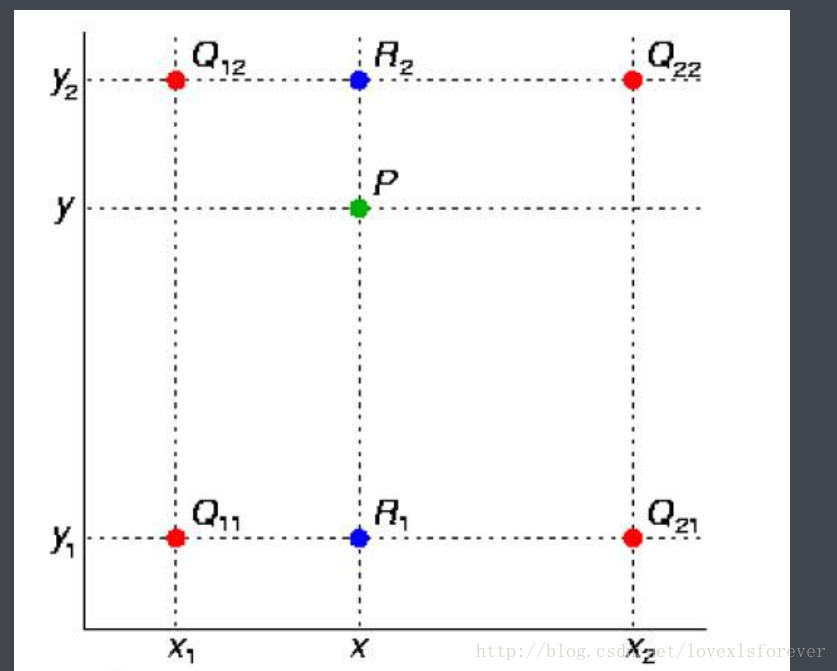
双线性插值
有两个方向和对应的值
在两个方向分别进行一次单线性插值
我们想得到未知函数 f 在点 P = (x, y) 的值
已知函数 f 在 Q11 = (x1, y1)、Q12 = (x1, y2), Q21 = (x2, y1) 以及 Q22 = (x2, y2) 四个点的值
首先在 x 方向进行线性插值
然后在 y 方向进行线性插值
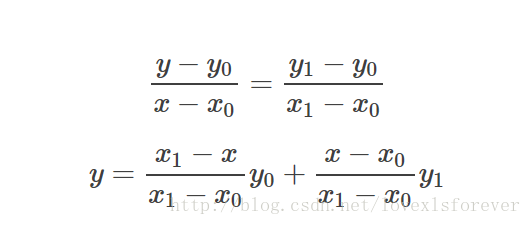
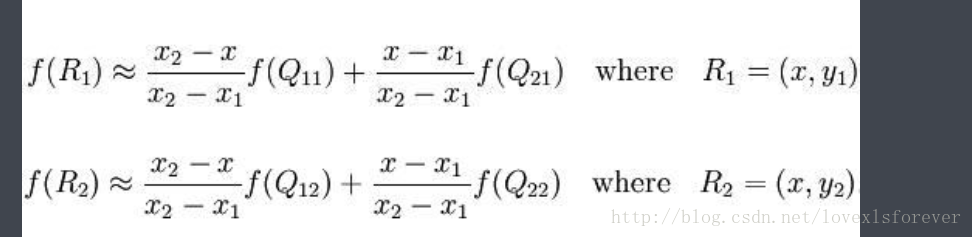
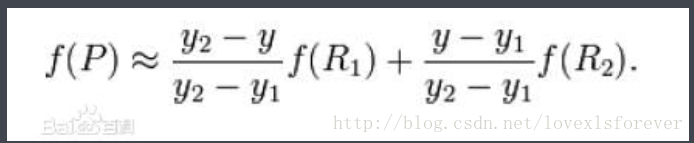
mask分支

上图是针对不同backbone mask分支的结构。右边灰色部分忽略了几个卷积层。和class的RoIAlign输出大小不一样。

X4:3*3,s1,p1
输入:
Roi在Feature map上的映射图
实现:
FCN(?),最后做转置卷积上采样,最后对256个通道做一次1* 1卷积得到28* 28*numcls大小的masks,最后根据fast rcnn分支给出的类别拿出对应的mask。
原本是class
输出:
mask
LOSS:L = Lcls + Lbox + Lmask
Lmask is only defined on the k-th mask (other mask outputs do not contribute to the loss).
Mask RCNN总体架构
消融实验
Backbone Architecture:resnet 50、101、resnet 50-fpn、resnet 101-fpn、resnext-101-fpn最终resnext-101-fpn效果最好,AP均高于其他几个backbone6-1个点。
多任务/独立mask:独立的强。
RoIAlign(ResNet-50-C4),RoIAlign (ResNet-50-C5, stride 32) 都优于于roipooling 。
Mask Branch (ResNet-50-FPN) FCNs improve results as they take advantage of explicitly encoding spatial layout.MLP稍微落后AP1-2个点。
后面还做了迁移,用于人体姿态检测。














 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









