







课程名称:物联网智能信息处理
实验项目:数据预处理,C4.5分类器,关联规则,员工离职数据
实验一
-
在data文件夹中找到玻璃数据集g1ass.arff,将其导入到Explorer界面,在预处理面板中查看RI属性直方图。
- 首先安装weka
weka,Rstudio,R软件,员工数据集网盘资源提取码:bngo






- 安装完成后,可生成如上文件
- 查看data文件夹,里面是weka自带的数据集

- 完成后打开weka,进入探索者页面


- Openfile打开文件,选怎data文件夹,选择玻璃数据集

- 加载数据后如下


-
将无监督离散化过凌器应用到等宽和等频两种离散化方法,即首先保持weka. fi1ters.unsupervised attribute.Discretize的全部默认选型默认值不变,然后将useEqualFrequency选项值更改为True 。

图2.1 过滤器
图2.2 等宽离散化方法 
图2.3 等频离散化设置 
图2.4 等频离散化 -
比较得到的直方图,你观察到什么

图2.5 等宽离散化直方图 
图2.6 等频离散化直方图 - 答:等宽离散化(或称为等宽分箱)经常造成实例分布不均匀,有的间隔区域内(箱内)包含很多个实例,但有的却很少甚至没有。这样会降低属性辅助构建较好决策结果的能力。通常也允许不同大小的间隔区域存在,从而使每个区间内的训练实例数量相等,这样的效果会好一些,该方法称为等频离散化(或称为等频分箱),其方法是:根据数轴上实例样木的分布将属性区间分隔为预先设定数量的区间。如果观察结果区间的直方图,会发现其形状平直。等频分箱与朴素贝叶斯学习方案一起应用时效果较好。但是,等频分箱也没有注意实例的类别属性,仍有可能导致不好的区间划分。例如,如果一个区域内的全部实例都属于—个类别,而下一个区域内除了第一个实例外都属于前一个类别,其余的实例都属于另一 个类别,那么,显然将第一个实例包含到前一个区域更为合理。
等宽离散化数值属性从最小值到最大值之间平均分为十份,因此每一份所包含的实例数量就各不相等;而等频离散化按数值属性的大小顺序将全部实例平均分为十份,每份所包含是实例数量为21~22
- 答:等宽离散化(或称为等宽分箱)经常造成实例分布不均匀,有的间隔区域内(箱内)包含很多个实例,但有的却很少甚至没有。这样会降低属性辅助构建较好决策结果的能力。通常也允许不同大小的间隔区域存在,从而使每个区间内的训练实例数量相等,这样的效果会好一些,该方法称为等频离散化(或称为等频分箱),其方法是:根据数轴上实例样木的分布将属性区间分隔为预先设定数量的区间。如果观察结果区间的直方图,会发现其形状平直。等频分箱与朴素贝叶斯学习方案一起应用时效果较好。但是,等频分箱也没有注意实例的类别属性,仍有可能导致不好的区间划分。例如,如果一个区域内的全部实例都属于—个类别,而下一个区域内除了第一个实例外都属于前一个类别,其余的实例都属于另一 个类别,那么,显然将第一个实例包含到前一个区域更为合理。
-
在预处理面板中查看Ba属性直方图,等频离散化Ba属性,再检查结果,发现直方图严重偏向一端,也就是根本不等频,这是为什么
- 仔细观察第一个直方图的标签,其值为(-inf-0.03】,即区间大于负无穷且小于等于0.03。使用数据集编辑器打开离散化前的原始数据集,单击第八列表头,使数据集按照Ba属性进行排序,可以看到,有176个实例的Ba属性值都等于0.0。由于这些值都完全相同,没有办法将它们分开。这就是为什么,上图严重地偏向一端的根本原因。

-
找到鸢尾花数据集iris. arff,施加有监督的高散化方法wek a.flters. supervised attrlute.Discretize,观察得到的直方图,你认为最有预测的属性是哪个属性?
图4.1 导入鸢尾花数据集iris. arff 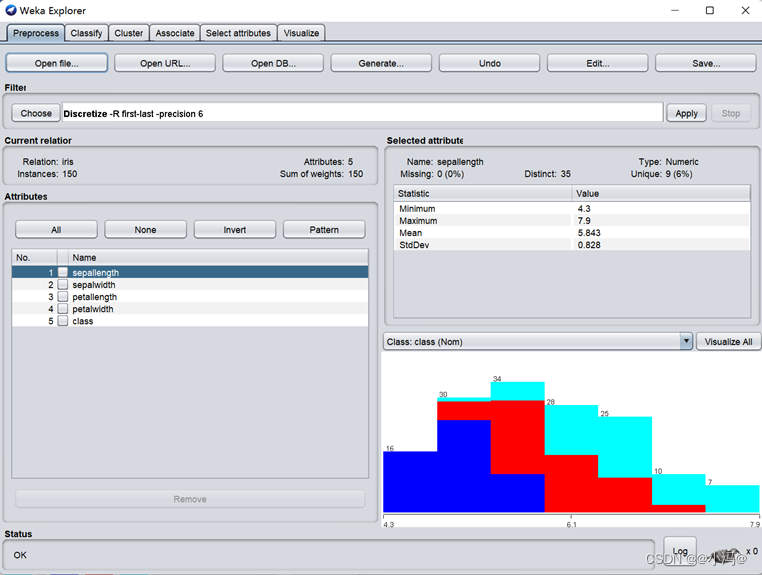
图4.2 导入后的主界面 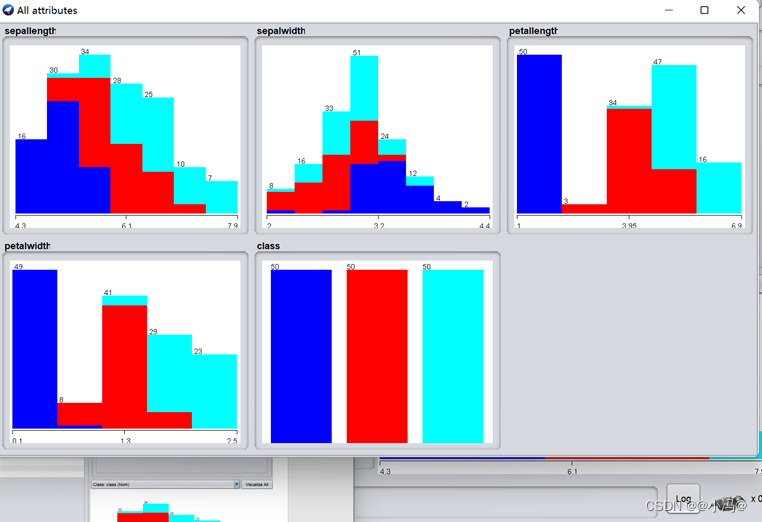
图4.3 导入后的直方图 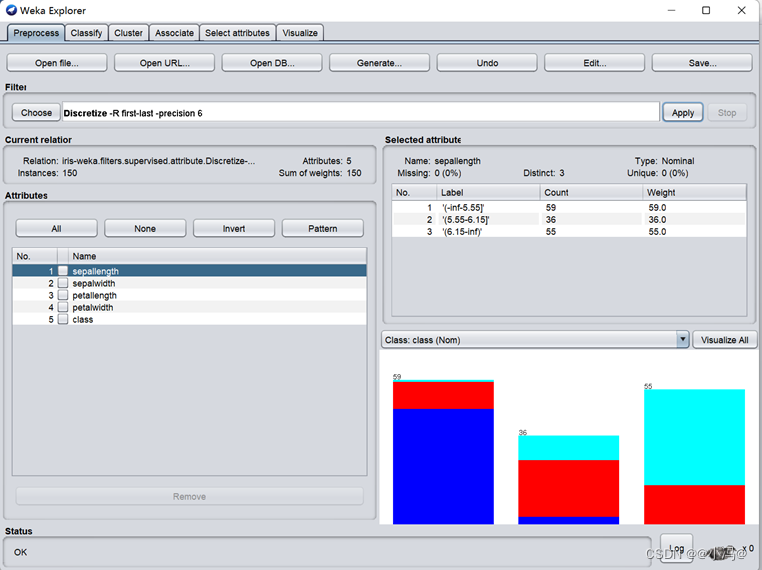
图4.4 有监督的高散化方法 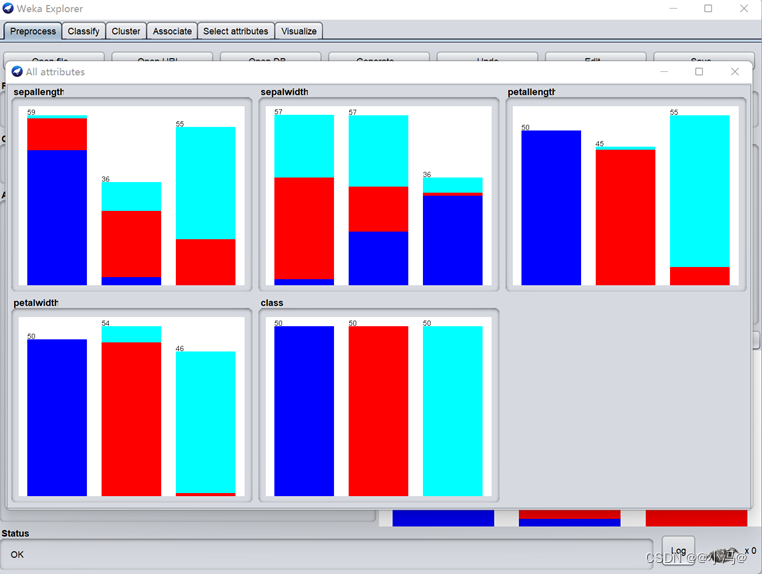
图4.5 有监督的高散化方法直方图 - 结论:显然,只有petallength(花瓣长)和petalwidth(花瓣宽)最具竞争力,因为它们的每种分类都已经接近为同一种颜色。再经仔细对比发现在前者中,有1个virginica实例错分到versicolor中,有6个实例versicolor错分到virginica中,因此共有7个错分的实例;而后者,只有5个virginica实例错分到versicolor中,有1个versicolor实例错分到virginica 中,因此共有6个错分的实例从而得出结论:离散化后的petalwidth属性最具有预测能力。
实验二
-
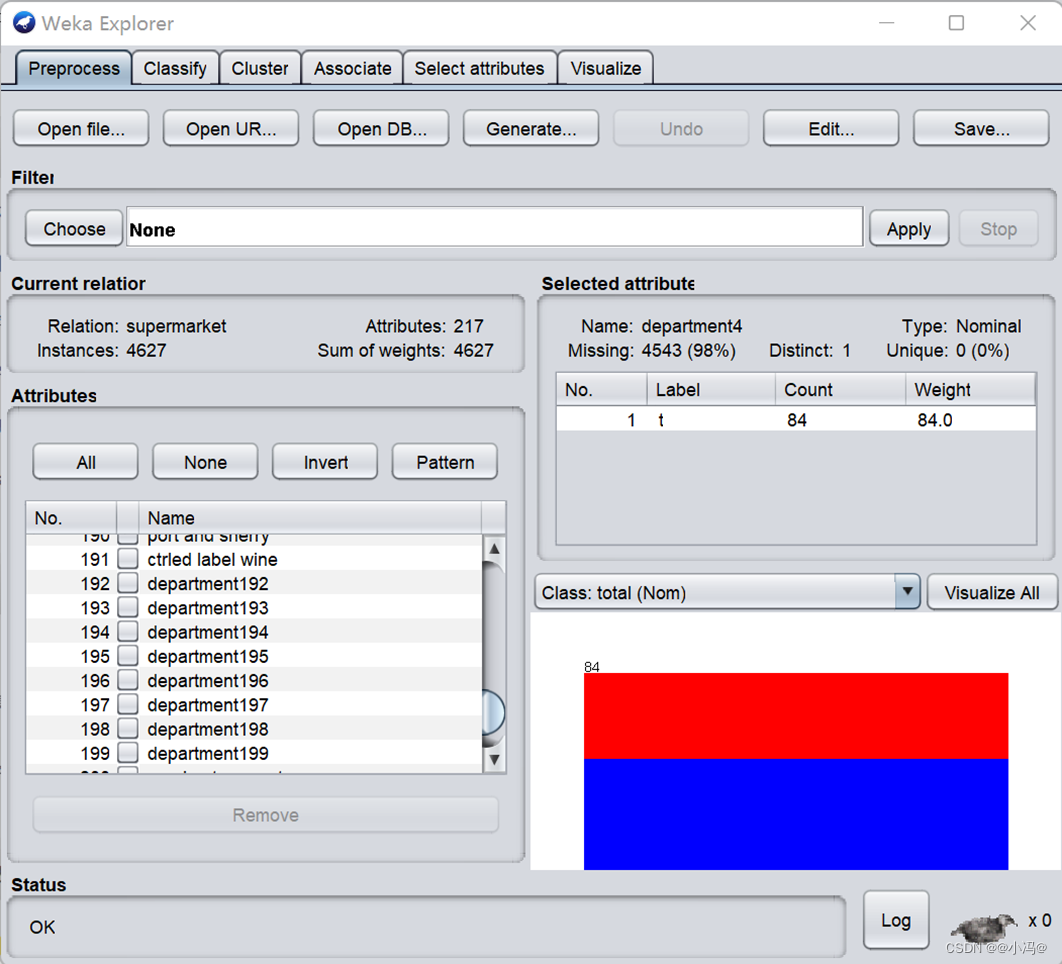
对超市收银台进行关联数据挖掘,加载data目录下的supermarket.arff文件,在Current relation子面板中,观察属性和实例的数量。
-
查看数据文件supermarket.arff,描述每个实例和属性表示什么?每个属性有几个值?如果顾客没有买这个商品如何表示?
如图可以看出属性有217个,实例有4627个
-
规则采用“前件num.1=->结论num.2”的形式表示,前件后面的数字表示有多少个实例满足前件,结论后的数字表示有多少个实例满足整个规则。从你得到的规则得出什么结论,比如:购买biscuits饼干和frozen foods冷冻食品以及fruit水果的顾客,往往total总金额较高还会顺便买些bread和cake蛋糕。
- 2、购买baking needs烘焙用品和biscuits饼干以及fruit水果的顾客,往往total总金额较高(760),还会顺便买一些bread面包和cake蛋糕
- 3、购买baking needs烘焙用品和frozen foods冷冻食品以及fruit水果的顾客,往往total总金额较高(770),还会顺便买一些bread面包和cake蛋糕
- 4、购买party snack foods派对休闲食品和fruit水果以及vegetables蔬菜的顾客,往往total总金额较高(815),还会顺便买一些bread面包和cake蛋糕
- 5、购买baknig needs烘焙用品和fruit水果的顾客,往往total总金额较高(854),还会顺便买一些bread面包和cake蛋糕
- 6、购买biscuits饼干和frozen foods冷冻食品以及vegetables蔬菜的顾客,往往total总金额较高(797),还会顺便买一些bread面包和cake蛋糕
- 7、购买baking needs烘焙用品和biscuits饼干以及vegetables蔬菜的顾客,往往total总金额较高(772),还会顺便买一些bread面包和cake蛋糕
- 8、购买biscuits饼干和fruit水果的顾客,往往total总金额较高(886),还会顺便买一些bread面包和cake蛋糕
- 9、购买frozen foods冷冻食品和fruit水果以及vegetables蔬菜的顾客,往往total总金额较高(834),还会顺便买一些bread面包和cake蛋糕
- 10、购买frozen foods冷冻食品和fruit水果的顾客,往往total总金额较高(969),还会顺便买一些bread面包和cake蛋糕
实验三
-
首先,打开天气数据集weather.nominal.arff
-
找到构建决策树的C4.5算法:weka.classifiers.trees.J48
- 用训练集Use training set,右击结果列表中的trees.J48条目,选择Visualize tree,构建可视化的决策树
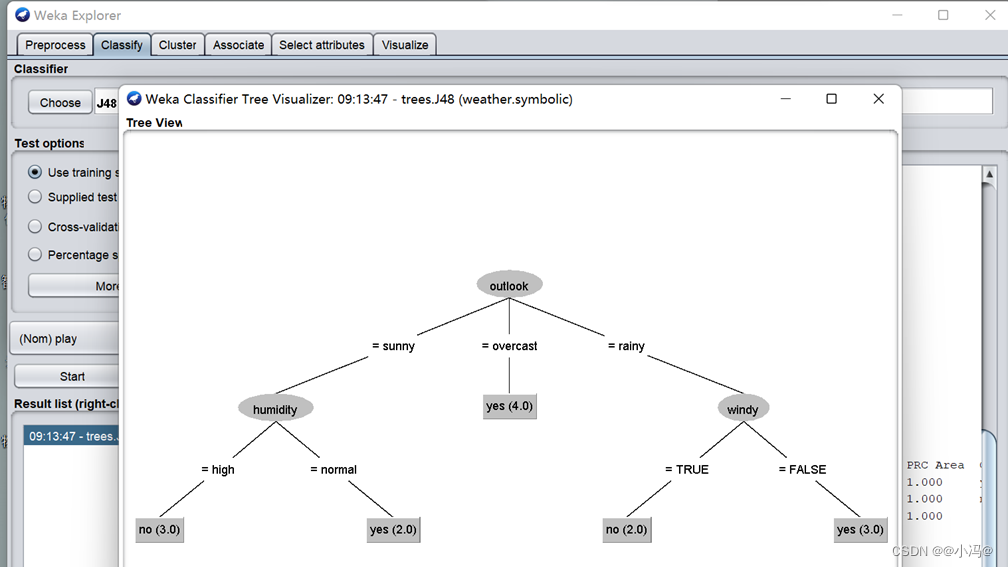
-
加载鸢尾花lris数据
-
分别用训练集Use training set和十折交叉验证Crs-valdation Folds 10两种方案在数据上评估C4.5,包括正确分类的测试实例和正确分类的比例。\
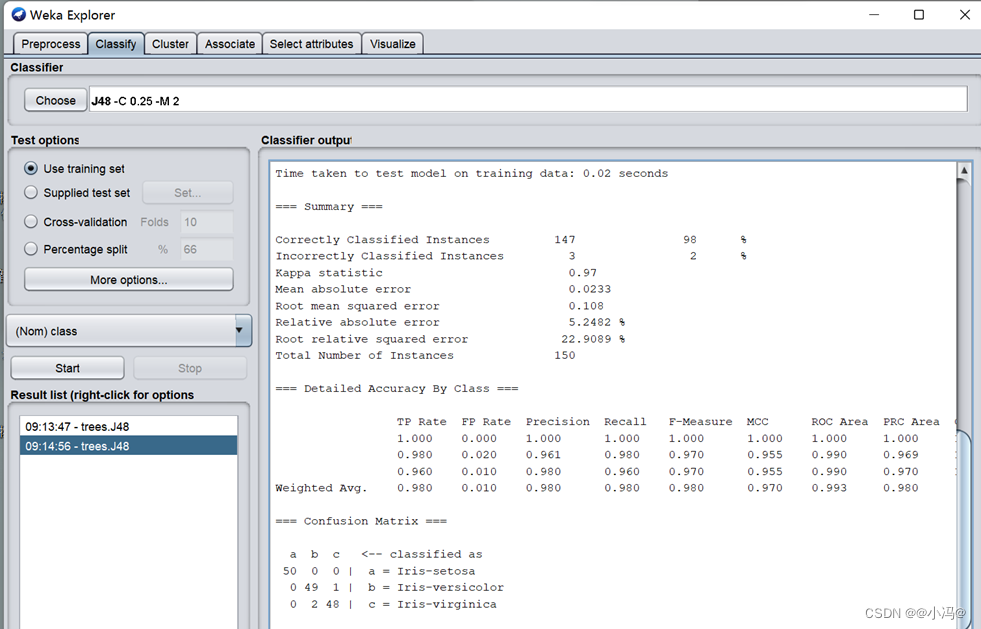

测试选项 释义 正确分类的测试实例 正确分类比例 Use training set 使用训练集 147 98% Crs-valdation Folds 10 交叉验证(十折) 144 96% - 从上表的数据可以看到,使用训练集的正确分类所占的比例较高,达到98%。但由于是直接将训练集用于测试,因此结论并不可靠。相反,十折交叉验证将数据集分为10 等份,将其中的1份用于测试,另外9份用于训练,如此依次进行10次训练和评估,显然得到的结论要可靠一些。
-
右击结果列表中的交叉验证方案trees.48条目,选择Visualize classifier errors,横坐标为真实类别,纵坐标为预测类别,双击散点图中的叉和方形,观察他们所代表的标记。
- 弹出一个散点图窗口,正确分类的实例标记为小十字,不正确的分类实例标记为小空心方块,如下图所示。

-
拉动Jitter滑条,观察错分类实例的位置有什么收获

- 一个小十字并不一定只代表一个实例,一个小空心方块有时也并不仅仅代表一个 错分的实例。如果想看到底有几个实例错分,可以拉动Jitter滑条,会错开一些相互叠加 的实例,便于看清楚到底有多少个错分的实例。另一种办法是单击小空心方块,就会弹出 如下图所示的实例信息,显示每个实例的各属性值以及预测类别和真实类别。
实验四
- 本次综合实验为员工离职预测分析,可参考附件用R软件分析,首先加载R包,查看员工离职数据的基本数据结构。
- 加载Rmisc关联包
library(plyr)
library(dplyr)
library(ggplot2)
library(DT)
library(lattice)
library(caret)
library(rpart)
library(e1071)
library(randomForest)
library(pROC)
library(Rmisc)
hr<- read.csv("D:\\chapter11\\HR_comma_sep.csv")
str(hr)

导入员工数据,并进行描述性分析

- 探索员工对公司满意度、绩效评估和月均工作时长与是否离职的关系,绘制对公司满意度与是否离职的箱型图。
- 观察图上中各个变量的主要描述统计量可知,离职率left接近15%,对公司的满意度在62%左右,绩效评估在72%左右,月均工作时长在200h左右
hr$left<- factor(hr$left,levels=c('0','1'))
box_sat<- ggplot(hr,aes(x=left,y=satisfaction_level,fill=left))+geom_boxplot(varwidth=T)+theme_bw()+stat_summary(fun.y='mean',geom='point',shape=23,size=3,fill='white')+labs(x='left',y='satisfaction_level')+theme(axis.text.x=element_text(size=rel(1.3)),axis.text.y=element_text(size=rel(1.3)),axis.title.x=element_text(size=rel(1.3)),axis.title.y=element_text(size=rel(1.3)))
box_eva<- ggplot(hr,aes(x=left,y=last_evaluation,fill=left))+geom_boxplot(varwidth=T)+theme_bw()+stat_summary( fun.y='mean',geom='point', shape=23,size=3,fill='white')+ labs( x='left',y='last_evaluation' )+theme(axis.text.x=element_text(size=rel(1.3)),axis.text.y=element_text(size=rel(1.3)),axis.title.x=element_text(size=rel(1.3)),axis.title.y=element_text(size=rel(1.3)))
box_mon<- ggplot(hr,aes(x=left,y=average_montly_hours,fill=left))+geom_boxplot(varwidth=T)+theme_bw()+stat_summary(fun.y='mean',geom='point',shape=23,size=3,fill='white')+labs(x='left',y='average_montly_hours')+theme(axis.text.x=element_text(size=rel(1.3)),axis.text.y=element_text(size=rel(1.3)),axis.title.x=element_text(size=rel(1.3)),axis.title.y=element_text(size=rel(1.3)))
multiplot(box_sat,box_eva,box_mon,cols=3)
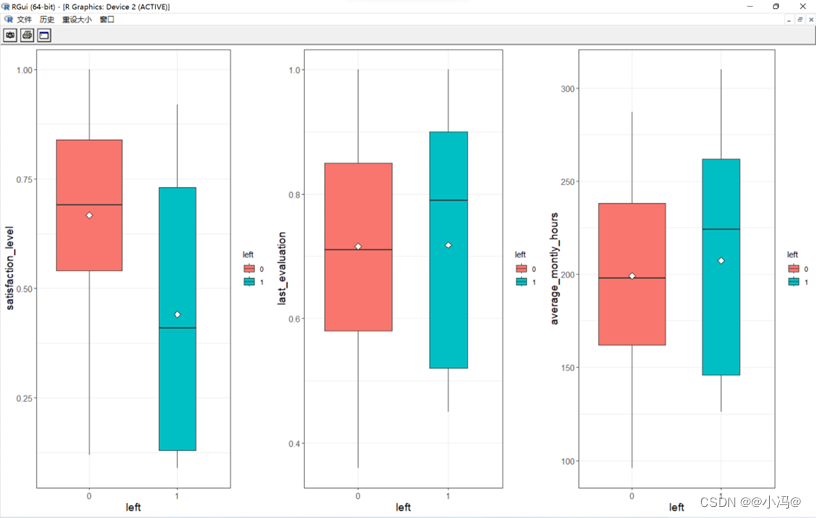
通过上图可知,离职员工的特点为对公司满意度较低,大多数集中在0.4左右,绩效评估较高,在0.8以上的较为集中,平均月工作时长较高,超过了平均的200h
#通过各特征之间的关系来探索离职率情况
#绘制参与项目个数条形图时需要把此变量转换为因子型
hr$number_project<- factor(hr$number_project,levels=c('2','3','4','5','6','7'))
# position='fill'#绘制百分比堆积条形图(图11-3)
bar_pro<-ggplot(hr,aes(x=number_project,fill=left))+geom_bar(position='fill')+theme_bw()+labs(x='left',y='number_project')+theme(axis.text.x=element_text(size=rel(1.3)),axis.text.y=element_text(size=rel(1.3)),axis.title.x=element_text(size=rel(1.3)),axis.title.y=element_text(size=rel(1.3)))
#绘制5年内是否升职与是否离职的百分比堆积条形图
bar_5years<- ggplot(hr,aes(x=as.factor(promotion_last_5years),fill=left))+geom_bar(position='fill')+theme_bw()+labs(x='left',y='promotion_last_5years')+theme(axis.text.x=element_text(size=rel(1.3)),axis.text.y=element_text(size=rel(1.3)),axis.title.x=element_text(size=rel(1.3)),axis.title.y=element_text(size=rel(1.3)))
#绘制薪资与是否离职的百分比堆积条形图(图11-3)
bar_salary<- ggplot(hr,aes(x=salary,fill=left))+geom_bar(position='fill')+theme_bw()+labs(x='left',y='salary')+theme(axis.text.x=element_text(size=rel(1.3)),axis.text.y=element_text(size=rel(1.3)),axis.title.x=element_text(size=rel(1.3)),axis.title.y=element_text(size=rel(1.3)))
#合并这些图在一个绘图区域,cols=3的意思就是排版为一行三列
multiplot(bar_pro,bar_5years,bar_salary,cols=3)
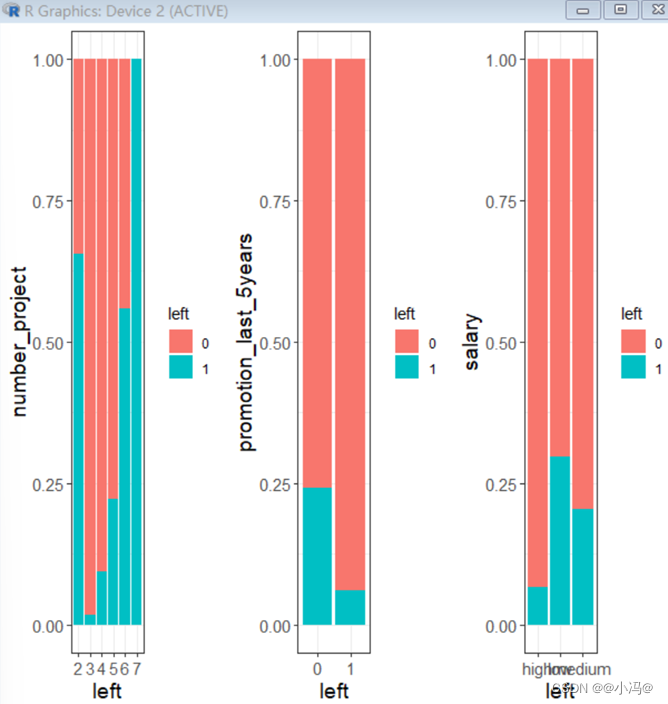
通过探索参与项目个数,五年内有没有升职以及薪资与离职的关系可知,参加项目数越多的员工离职率越大(去除项目数为2的样本),五年内没有升职的员工离职率比较大,薪资越高离职率越低。
- 用五折交叉验建立回归树并分析混淆矩阵结果。
hr_model<- filter(hr,last_evaluation>=0.70 | time_spend_company>=4 | number_project>5)
train_control<- trainControl(method='cv',number=5)
set.seed(1234)
index<- createDataPartition(hr_model$left,p=0.7,list=F)
traindata<- hr_model[index, ]
testdata<- hr_model[-index, ]
rpartmodel<- train(left ~.,data=traindata,trControl=train_control,method='rpart')
pred_rpart<- predict(rpartmodel,testdata[-7])
con_rpart<- confusionMatrix(testdata$left,pred_rpart,positive='1')
con_rpart


| 预测值 | ||
|---|---|---|
| 实际值 | 0 | 1 |
| 0 | 2246 | 51 |
| 1 | 72 | 528 |
回归树建模的混绢矩阵结果如表11-2所示,真正例数为528,预测正例数为实际正例预测正例和实际负例预测正例数之和,实际正例数为预测正例实际正例和预测负例实际正例之和,根据查全率和查准率概念,计算得查准率为92.15%,查全率为85.85%。
- 选择特征后,用五折交叉验建立随机森林模型并分析混淆矩阵结果。
特征选择(随机森林)。随机森林就是用随机的方式建立一个森林,森林里面有很多的决策树,并且每棵树之间是没有关联的。得到一个森林后,当有一个新的样本输入,森林中的每一棵决策树会分别进行一次判断,进行类别归类(针对分类算法),最后判定类别最多的那一类,就是最后的预测结果。
set.seed(1234)
fs_rf <- rfe(x=traindata[,-7], y=traindata[,7], sizes=seq(3,8,1), rfeControl=rfeControls_rf)
fs_rf
new_vars<- fs_rf$optVariables[1:6]
mydata<- hr_model[c(new_vars,'left')]
traindata2<- mydata[index,]
testdata2<- mydata[-index,]
rfmodel<- train(left~.,data=traindata2,trControl=train_control,method='rf')
pred_rf<- predict(rfmodel,testdata2[-7])
con_rf<- confusionMatrix(pred_rf,testdata2$left,positive='1')
con_rf


| 预测值 | ||
|---|---|---|
| 实际值 | 0 | 1 |
| 0 | 2292 | 23 |
| 1 | 5 | 577 |
随机森林特征选择运行结果如表11-3所示,计算得查准率为96.17%,查全率为99.14%,比回归树建模有所提高。
- 建立朴素贝叶斯模型并分析混淆矩阵结果。
e1071model<- train(left ~ .,data=traindata,trControl=train_control,method='nb')
pred_nb<- predict(e1071model,testdata[-7])
con_nb<- confusionMatrix(pred_nb,testdata$left,positive='1')
con_nb

| 预测值 | ||
|---|---|---|
| 实际值 | 0 | 1 |
| 0 | 2248 | 146 |
| 1 | 49 | 454 |
朴素贝叶斯建模的混绢矩阵如表11-4所示,计算得查准率为75.67%,查全率为90.25%。
- 选择特征后,用五折交叉验建立朴素贝叶斯模型并分析混淆矩阵结果。
- 特征选择(朴素贝叶斯)。
- 朴素贝叶斯分类器(Naive Bayes Classifier,NBC)基于古典数学理论,具有稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。朴素贝叶斯分析如下:
rfeControls_nb<- rfeControl(functions=nbFuncs,method='cv',number=5)
fs_nb <- rfe(x=traindata[,-7], y=traindata[,7], sizes=seq(3,8,1), rfeControl=rfeControls_nb)
报错如下(并未解决,以至于影响了后面的实验结果,请谨慎参考)

- 建立Logistic回归模型并分析混淆矩阵结果。
gmlmodel<- train(left~.,data=traindata,trControl=train_control,method='LogitBoost')
pred_log<- predict(gmlmodel,testdata[-7])
con_log<- confusionMatrix(pred_log,testdata$left,positive='1')
con_log

表11-6为逻辑斯蒂回归建模后预测的结果,通过计算得查准率为88.83%,查全率为89.73%。
| 预测值 | ||
|---|---|---|
| 实际值 | 0 | 1 |
| 0 | 2236 | 67 |
| 1 | 61 | 533 |
- 绘制各模型的ROC曲线
| 模型 | 查全率 | 查准率 |
|---|---|---|
| 朴素贝叶斯 | 90.25% | 75.67% |
| 特征选择+朴素贝叶斯 | ||
| 逻辑斯蒂回归 | 89.73% | 88.83% |
| 回归树 | 85.85% | 92.15% |
| 特征选择+随机森林 | 99.14% | 96.17% |
通过模型对比可以发现经过特征选择过的随机森林为最佳模型
pred_rpar<- as.numeric(pred_rpart)
pred_rf<- as.numeric(pred_rf)
pred_nb<- as.numeric(pred_nb)
pred_nb2<- as.numeric(pred_nb2)
pred_log<- as.numeric(pred_log)
roc_rpar<- as.numeric(testdata$left,pred_rpart)
Specificity<- roc_rpart$specificities
Sensitivity<- roc_rpart$sensitivities
p_rpart<- ggplot(data=NULL,aes(x=1-Specificity,y=Sensivity))+geom_line(color=’red’)+geom_abline()+annotate(
报错:
- 选取最优的模型,预测员工离职与不离职的概率。
- 图11-6是本实验最后的预测数据表:“pred.0”是预测为0(不离职)的概率,相反“pred.1”是预测为1(离职)的概率,最后一列“pred”即是否离职
pred_end<- predict(rfmodel,testdata2[-7],ytpe='prob')
data_end<- cbind(pred_end,pred_rf)
names(data_end)<- c('pred.0','pred.1','pred')
datatable(data_end)

















 7133
7133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











