







提出背景
R-CNN的特征提取网络要求输入图像为固定尺寸,和人的视觉系统相比,这一约束其实非常不自然。R-CNN对输入图像尺寸的这一约束,使得图像在进入网络之前,必须进行截取或拉伸,改变了图像原本的形态,直接影响了算法的性能。另外,R-CNN在对各个候选框进行特征提取的过程中,也进行了非常多重复的卷积计算,导致算法耗时很长,很难在实时系统中使用。针对上述两个问题,何恺明等人提出了一种新的池化方法,即空间金字塔采样,而基于这种方法构建的卷积神经网络,称为SPP-Net。下面将对空间金字塔采样和SPP-Net进行详细介绍。
空间金字塔采样
R-CNN的出现,使得检测算法的性能有了显著提升,其中一个最为核心的思想是通过卷积神经网络进行特征提取。常规的卷积神经网络包含卷积层、池化层以及全连接层,虽然卷积层和池化层对输入尺寸(特征图的宽和高)没有限制,但是全连接层的输入和输出都是固定维度的特征,这就要求整个神经网络的输入图像需要具有固定的尺寸(例如AlexNet就要求输入图像的尺寸为224像素×224像素)。把任意尺寸的图像变为固定尺寸,如图8.3所示,要么需要对原图进行截取(crop),要么需要对原图进行拉伸(warp),实际上都改变了图像原来的形态,会对识别效果产生影响。
基于上述原因,为了进一步提升算法的性能,一个直接的力法就是去掉对输入图像尺寸的限制。因为全连接层严格要求输入的特征维数,所以我们可以在全连接层之前,插入一个采样层,把之前经过一系列卷积层生成的特征图采样成规定尺寸,这 个采样层称为空间金字塔采样层, 图1 将图像截取、拉伸成固定尺寸(Spatial Pyramid Pooling layer, SPP layer)。图2显示了基于常规图像变换和基于SPP变换方法在网络计算过程中的区别,可以看出,SPP的本质是将图像的特征,在更深的网络层次中进行汇聚。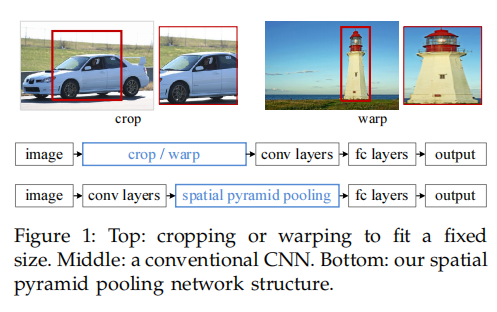
SPP的具体实现方法可以参考图8-5,在最后一个卷积层之后插入一个SPP层(或替换原卷积层之后的池化层),在最后一个卷积层之后的特征图上,划分粗细尺度不同的几级均匀网格(特征图的各通道切片上,网格划分的方式一致)。各级网格对特征图进行了不同尺度的划分,构成了特征图的金字塔结构。对每级网格中的每个单元,使用最大值池化或平均值池化,池化之后的结果融合在一起,构成长度固定的特征向量。在SPP的过程中,对于不同大小的图像,同一层级网格单元格的数量是相同的,每个单元格的尺寸和整个图像的尺寸成正比,这样就保证了无论输入图像的尺寸如何,经过SPP层之后,都能变成同样维度的特征向量。向量的总维数为kxM,其中k表示SPP输入特征图的通道数(即最后一个卷积层卷积核的个数),M表示在每个切片上,各级网格单元格数量之和。图8-5中使用了3个均匀网格,网格的尺寸分别是4×4、2×2和1×1,图中特征图的通道数为256,经过SPP层之后,图像的特征向量变换成(4×4+2×2+1×1)×256维,维度和输入图像的分辨率及宽高比都无关,从而消除了之前R-CNN算法中对输入图像尺寸的约束。
多尺度方法在图像分类和目标检测算法中有着非常重要的作用,在不同尺寸的图像(图像金字塔)上提取SIFT、HOG等特征进行融合使用,能够明显提升算法的尺度鲁棒性。其实,对于神经网络提取的特征也一样,因为使用了SPP层,特征向量的维数和输入图像的尺寸无关,所以保证了我们在模型训练的时候能够对原图进行多尺寸缩放,大大增强了网络模型的尺寸鲁棒性。
网络训练
原则上来说,SPP对输入图像的尺寸没有要求,但在实现训练算法的时候,为了保证训练流水线计算的高效性,类似caffe这样的训练框架都约束了输入图像的尺寸。SPP-Net的训练方法,对于单尺度训练和多尺度训练两种训练模式,将给出SPP的具体实现方案。
1.单尺度训练
假设固定输入图像尺寸,比如224像素×224像素,对于其他尺寸的输入图像,常规的做法是先缩放到比224像素×224像素略大一些的尺寸,然后通过224×224的窗口进行滑窗截取,生成一系列224像素×224像素的训练图像样本 这此固尺寸的样本经过一系列卷积计算后到达SPP层,通过SPP层的池化计算,生成圆定尺寸的特征向量并传到网络后段。整个过程中,网络的各级特征图的尺寸在每次开算的时候不发生变化,因而无须动态分配存储空间,提升了整个计算流水线的效率。
2.多尺度训练
多尺度训练和单尺度训练的区别是多尺度训练指定了输入图像的多个尺度,比如224像素×224像素和180像素×180像素,先通过截取获得的一系列224像素×224像素的样本,再通过缩放生成对应的一系列180像素×180像素的样本。在训练迭代过程中,先对所有224像素×224像素的样本进行一次完整迭代,然后对所有180像素×180像素的样本进行下一次完整迭代,再使用224像素×224像素的样本进行完整迭代。如此往复交替进行训练过程。在整个过程中,模型权重参数的维数是一致的,每一次迭代的模型参数都是下一次迭代模型参数的初值。对于不同的输入图像尺寸,特征图的维度是变化的,需要分配不同大小的存储空间,但在同一尺寸的完整迭代过程中,特征图的维度是不变的,可以共享相同的存储空间。存储空间的切换,仅仅发生在不同尺寸迭代之间切换的时候,因此也可以保证整个训练过程的高效进行。指定多个输入图像尺寸的目的和图像金字塔的思想一致,就是使得算法模型具有更好的尺寸鲁棒性。
测试过程
与R-CNN算法类似,对于检测问题,在SPP-Net算法中,首先需要通过类似Selective Search方法生成一系列候选框。但在提取特征的过程中,SPP-Net与R-CNN不同,其仅需要对全图进行一次卷积计算。对于每个候选框,根据候选框角点坐标和特征图上对应点坐标的映射关系,可以在特征图上找到对应的区域,无论特征图上的这个区域尺度如何,SPP层都会将其变换成固定维度的特征向量传递到后段进行计算,最终得到对应候选框的特征。这之后的处理过程与R-CNN的流程相同,都是使用特征进行分类和位置修正,然后通过非极大值抑制(NMS)算法合并重复的结果,最后根据每个类的检出國值输出最终的结果。整个测试过程的一个最大的改进,就是不再需要使用神经网络单独对每个候选框提取特征,只需进行一次卷积计算,仅仅在最后一个卷积层之后的特征图上使用SPP即可。这一改进,使得测试时的速度有了几十乃至上百倍的显著提升。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











