







 超级会员免费看
超级会员免费看
数据及源码链接见文末
视听事件定位,即以视频信息和音频信息作为输入,模型确定事件的存在和可见事件,并将其定位在时间维度上的边界。其主要的挑战有:
- i).在合并互补的音频和视觉特征时,同时保留特定于模态的信息并不是简单的。
- ii).无约束视频中存在的突发噪声和复杂背景会阻碍对事件类别的预测。
- iii).视听信息不同步的问题会误导事件边界预测。
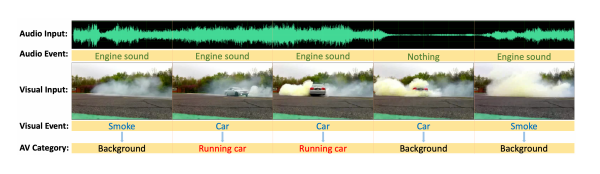
早期的研究主要集中于解决第一个挑战,在独立处理每种模态的信息后,简单地融合每个或对齐视听信息,然后通过交叉注意融合它们。然而,噪声问题和视听事件不同步的问题依旧是一个很大问题。这篇研究主要致力于解决这两个问题。
而在AVE任务中,不同于单模态任务,AVE任务可能出现在一种模态下将视频片段视为前景,但实际上它可能是背景片段,因为在另一种模态中缺少相关信息。此外,噪声存在于多个模态,这也给任务带来了挑战。
因此,首先从两个方面来定义“背景”类别: 1)如果小视频片段中的视听信息不代表同一事件,则该视频片段将被标记为背景。2)如果一个事件只在一种模式中发生,但在另一种模式中概率较低,那么这个事件类别将被标记为本视频的背景,即屏幕外的声音。
因此,这项研究提出了一种新的跨模态背景抑制方法,

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 2367
2367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











