







问题:
随机生成了两个簇,随机选取两个中心点,然后通过k-means算法不断地聚类,等到两个中心的距离小于0.001收敛时,停止聚类。import matplotlib.pyplot as plt
import numpy as np
# 欧式距离
def oj(x,y):
return np.sqrt(np.sum((x-y)**2))
# kmeans算法
def kmeans(data, k):
# 随机初始化聚类中心
centers = data[np.random.choice(data.shape[0], k)]
for _ in range(100):
# 初始化距离矩阵
distances = np.zeros((data.shape[0], centers.shape[0]))
# 矩阵行为各个元素,列为两个中心点
for i, one_data in enumerate(data):
for j, center in enumerate(centers):
# 计算欧式距离
distances[i, j] = oj(one_data,center)
# 分配每个样本到最近的聚类中心
labels = np.argmin(distances, axis=1)
# 计算新的聚类中心
# 对于每一个聚类 j,计算属于该聚类的数据点的均值,得到新的聚类中心
new_centers = []
for j in range(k):
# 通过布尔索引选择属于第 j 个聚类的所有数据点
data_in_cluster = data[labels == j]
# 计算每个特征的均值,即计算新的聚类中心
center_of_cluster = np.mean(data_in_cluster, axis=0)
# 将计算得到的新聚类中心添加到列表中
new_centers.append(center_of_cluster)
# 将列表转换为 NumPy 数组,得到新的聚类中心
new_centers = np.array(new_centers)
# 检查是否收敛,欧氏距离小于0.001
if oj(centers,new_centers) < 0.001:
break
centers = new_centers
return labels, centers
# 生成两个簇的数据
np.random.seed(42)
cluster1 = np.random.normal(loc=10, scale=2, size=(50, 2))
cluster2 = np.random.normal(loc=20, scale=4, size=(50, 2))
# 合并簇
data = np.concatenate((cluster1, cluster2), axis=0)
# 使用K-means进行聚类
k = 2
labels, centers = kmeans(data, k)
# 打印聚类中心和标签
print("聚类中心:", centers)
print("标签:", labels)
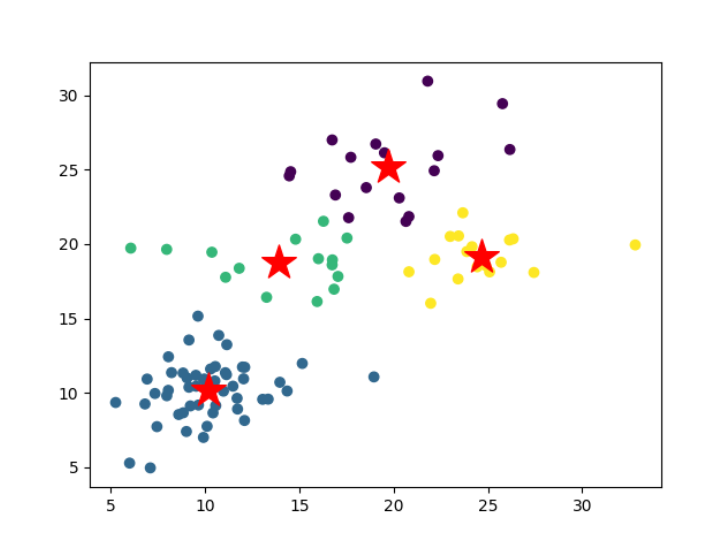
plt.scatter(data[:,0],data[:,1],c=labels)
plt.scatter(centers[:,0],centers[:,1],s=500,c='red',marker='*')
plt.show()
结果:
每次的族类中心 [[20.15008182 22.46043598]
[10.3317368 10.44410348]
[11.38009434 20.58788711]
[25.81966102 18.62536652]]
每次的族类中心 [[19.63900317 23.17421187]
[10.16446758 10.21524289]
[12.38563165 19.66159937]
[24.98966135 19.03900242]]
每次的族类中心 [[19.68869988 24.73898943]
[10.16446758 10.21524289]
[13.50481581 18.8392834 ]
[24.66587777 19.16574853]]
每次的族类中心 [[19.70951928 25.17353345]
[10.16446758 10.21524289]
[13.89347944 18.74011391]
[24.66587777 19.16574853]]
最后的聚类中心:-------》 [[19.70951928 25.17353345]
[10.16446758 10.21524289]
[13.89347944 18.74011391]
[24.66587777 19.16574853]]
标签: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 3 2 3 0 3 0 2 2 2 3 3 3 2 3 0 3 0 2 2 0 0 1 0 3
0 3 3 3 2 2 0 0 0 0 3 3 2 2 0 3 2 0 0 3 2 2 0 2 3 0]
知识点:
enumerate将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
第一行 0 第一个数据 1 第二个数据
第二行 0 第一个数据 2 第二个数据
d[0][0]= 距离1 d[0][1]=距离2
d[1][0]= 距离1 d[1][1]=距离2
argmin 在数组中沿指定轴找到最小值的索引 距离1>距离2 labels=1
else labels=0
当labels==k(0,1)
计算离第一个中心点近的 data[0]的平均值
计算离第二个中心点近的 data[1]的平均值
用array数组保存
loc:分布的均值(mean)
scale:分布的标准差(standard deviation)
size:生成的随机数的形状
size=(50, 2) 表示生成一个形状为 (50, 2) 的二维数组,其中包含50个样本,每个样本有2个特征
[行,列:行,列] [起始:终止:步长]
调用方法:plt.scatter(x, y, s, c, marker, cmap, norm, alpha, linewidths, edgecolorsl)
参数说明:
x: x轴数据
y: y轴数据
s: 散点大小
c: 散点颜色
marker: 散点形状
cmap: 指定特定颜色图,该参数一般不用,有默认值
alpha: 散点的透明度
linewidths: 散点边框的宽度
edgecolors: 设置散点边框的颜色
















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











