










Transformer是现代深度学习的核心架构之一,广泛应用于自然语言处理、计算机视觉等领域。本文将从Attention原理讲起,逐步拆解Transformer架构,结合BERT、GPT等主流模型,通过实战示例讲透大模型训练的完整流程。
目录
1.2 Transformer提出:Attention Is All You Need
1.4.1 多头注意力机制(Multi-Head Attention)
1.4.2 位置编码(Positional Encoding)
1.4.3 前馈网络(Feed Forward Network)
2.2 Scaled Dot-Product Attention公式推导
2.4 多头注意力(Multi-Head Attention)
3.3.1 Masked Multi-Head Self-Attention
3.3.2 编码器-解码器注意力(Encoder-Decoder Attention)
3.5 位置编码(Positional Encoding)机制回顾
四、主流Transformer模型剖析:BERT、GPT、T5对比实战
训练目标:Masked Language Modeling (MLM)
训练目标:自回归语言模型(Autoregressive LM)
核心理念:Text-to-Text Transfer Transformer
5.2.1 使用HuggingFace Trainer快速训练
一、Transformer诞生背景与架构概览
1.1 背景:NLP的演进与Transformer的出现
在Transformer问世之前,自然语言处理(NLP)主要依赖于循环神经网络(RNN)和其变体(如LSTM、GRU)。这些模型的核心优势在于它们可以处理变长序列,保留前文的上下文信息,因而广泛应用于语言模型、机器翻译、文本分类等任务。然而,RNN 系列模型存在三个显著的瓶颈:
-
序列计算限制并行性:由于RNN在时间步上是串行计算,无法充分利用现代GPU的并行能力。
-
长距离依赖难以捕捉:虽然LSTM/GRU试图缓解这个问题,但仍难以捕捉远距离词汇间的依赖关系。
-
梯度消失与爆炸问题:当序列变长时,反向传播中的梯度容易变得非常小或非常大,导致模型训练不稳定。
为了解决这些问题,研究者们引入了注意力机制(Attention)。Attention的核心思想是:在处理某个词时,可以自由地关注输入序列中的任何其他词,而不受距离限制。Transformer模型将这一机制提升到了新高度。
1.2 Transformer提出:Attention Is All You Need
2017年,Google Brain团队在论文《Attention Is All You Need》中首次提出Transformer模型。该模型完全摒弃了RNN和CNN结构,仅依靠注意力机制和前馈神经网络实现序列到序列的建模。论文标题中的“All You Need”是对注意力机制强大能力的自信宣言。
Transformer的关键创新点包括:
-
自注意力机制(Self-Attention):每个词可以与句中所有其他词建立动态的关系。
-
位置编码(Positional Encoding):引入位置感知,使模型能识别词在句中的顺序。
-
完全并行计算:所有词可以同时处理,大大提升训练效率。
-
深层堆叠结构:通过堆叠多层编码器和解码器模块,模型具备更强的表达能力。
1.3 Transformer架构总览
Transformer模型由两个主要部分组成:编码器(Encoder) 和 解码器(Decoder)。每部分由多个结构相同的子层(Layer)堆叠而成。
-
编码器部分:主要处理输入序列,输出一个上下文相关的表示矩阵。
-
解码器部分:在预测目标序列的过程中,结合编码器输出与已生成的目标词序列逐步生成新的词。
以下是一个标准Transformer的结构图:
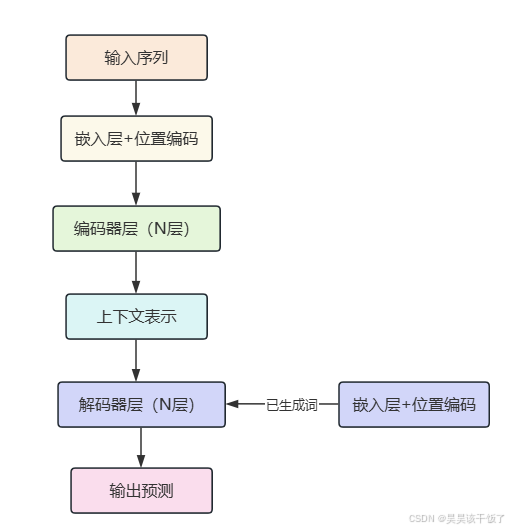
每个编码器层包括两个子层:
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈全连接网络(Feed-Forward Network)
每个解码器层包括三个子层:
-
多头自注意力机制(Masked Self-Attention)
-
编码器-解码器注意力机制(Encoder-Decoder Attention)
-
前馈全连接网络
所有子层都使用残差连接(Residual Connection)与Layer Normalization来加快训练收敛。
1.4 核心模块简介
1.4.1 多头注意力机制(Multi-Head Attention)
它将输入序列投影到多个子空间上进行注意力计算,最后将结果拼接合并,从而学习到更多样化的语义关系。
1.4.2 位置编码(Positional Encoding)
由于Transformer模型没有内建顺序信息,位置编码用于向输入中注入词位置信息。可以是基于三角函数的固定编码,也可以是可学习的向量。
1.4.3 前馈网络(Feed Forward Network)
每个位置上独立应用两个线性变换和一个激活函数(如ReLU),提升模型的非线性表达能力。
1.5 与传统模型对比分析
| 模型类型 | 是否并行 | 是否处理长依赖 | 表达能力 | 训练效率 |
|---|---|---|---|---|
| RNN/LSTM | 否 | 弱 | 中 | 慢 |
| CNN | 部分并行 | 局部有效 | 中 | 中 |
| Transformer | 是 | 强 | 强 | 快 |
Transformer的出现打破了序列建模的传统思维,其强大的表示能力和高效的训练方式,迅速成为NLP领域的主流选择。
二、Attention机制详解:从单头到多头注意力
在上一部分中我们提到,Transformer的核心驱动力在于“注意力机制”,尤其是自注意力(Self-Attention)。本节将从数学角度详细推导Attention机制的计算过程,并结合代码示例说明其实现方式。同时,我们也会深入分析为什么引入多头注意力机制(Multi-Head Attention),以及它在建模语言时起到的关键作用。
2.1 什么是注意力机制?
注意力机制的灵感来源于人类的视觉聚焦行为。当我们阅读一句话时,不是每个词都平均关注,而是会对某些关键词聚焦更多注意力。在神经网络中引入类似机制,有助于模型更有效地提取关键特征。
简单来说,注意力机制就是:
给定一个查询(Query)向量,计算它与一组键(Key)向量的相关性分数,然后将所有值(Value)向量按照这个相关性加权求和,作为最终输出。
2.2 Scaled Dot-Product Attention公式推导
我们首先来看Transformer使用的注意力形式——Scaled Dot-Product Attention。

2.3 自注意力(Self-Attention)原理
在Transformer中,每个位置的词向量同时充当Q、K、V,因此称为自注意力。模型可以在同一序列中捕捉不同位置词之间的关系。
例如:在句子“The cat sat on the mat.”中,模型处理“cat”时可以聚焦“sat”、“mat”等位置,从而学习到语法和语义依赖。
特点:
-
所有词彼此建立联系,不受距离影响。
-
权重是动态学习的,适应不同上下文。
2.4 多头注意力(Multi-Head Attention)
为什么需要多个头?
单个注意力头容易学习到局部或单一类型的关系,为了解决这个问题,Transformer使用了多头注意力机制:
-
将输入向量线性映射为 个子空间。
-
在每个子空间中独立执行注意力计算(即 )。
-
将所有头的输出拼接,并通过一个线性层整合。
多头注意力公式:

具体流程:

2.5 PyTorch实现示例
import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k):
super().__init__()
self.scale = d_k ** 0.5
def forward(self, Q, K, V, mask=None):
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = torch.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output, weightsclass MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
def transform(x, linear):
x = linear(x)
x = x.view(batch_size, -1, self.num_heads, self.d_k)
return x.transpose(1, 2)
Q, K, V = transform(Q, self.W_q), transform(K, self.W_k), transform(V, self.W_v)
scores, attn = ScaledDotProductAttention(self.d_k)(Q, K, V, mask)
concat = scores.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
return self.fc(concat)2.6 可视化:注意力矩阵长什么样?
我们可以将某一层某一头的注意力权重矩阵可视化,来看模型如何在不同词之间分配注意力:
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(attn[0][0].detach().cpu(), cmap='viridis')
plt.title("Attention Weights - Head 1")
plt.show()这种热力图可以直观展示模型在不同层和头上学习到的模式。
2.7 总结:Attention为什么强大?
-
可并行:不同位置的词可同时处理
-
捕捉长依赖:不受序列长度限制
-
结构灵活:可用于编码、解码、跨模态
-
自适应:不同上下文学习不同的注意模式
下一部分我们将进入Transformer的模块级解析,详解编码器与解码器的完整结构、子层连接逻辑和如何通过残差与归一化提升训练效果。
三、Transformer编码器与解码器模块解析
通过前两部分我们已经掌握了Transformer的整体结构和核心注意力机制。接下来我们将聚焦于模型的两个关键组成:编码器(Encoder)与解码器(Decoder)。本节将深入剖析它们的内部结构、子层细节、连接方式以及它们之间的交互原理。
3.1 编码器与解码器:整体架构回顾
Transformer的架构是对称的:
-
编码器由N个结构相同的层堆叠(通常为6层)。
-
解码器也由N个结构相同的层堆叠。
每一层都包含多个子模块,通过**残差连接(Residual Connection)和层归一化(LayerNorm)**进行连接。
编码器结构:
输入嵌入 + 位置编码
↓
[多头自注意力 → 残差 → LayerNorm]
↓
[前馈网络 → 残差 → LayerNorm]
↓
输出表示(供解码器使用)解码器结构:
目标嵌入 + 位置编码
↓
[Masked 自注意力 → 残差 → LayerNorm]
↓
[编码器-解码器注意力 → 残差 → LayerNorm]
↓
[前馈网络 → 残差 → LayerNorm]
↓
输出预测3.2 编码器层结构详解
每个编码器层由两个子层组成:
3.2.1 多头自注意力子层
-
输入为序列中所有词的表示(嵌入+位置编码)。
-
每个位置的词可“看到”整个序列中的其他位置,形成上下文感知表示。
-
通过多头机制获取多种语义维度的注意特征。
3.2.2 前馈神经网络子层(FFN)
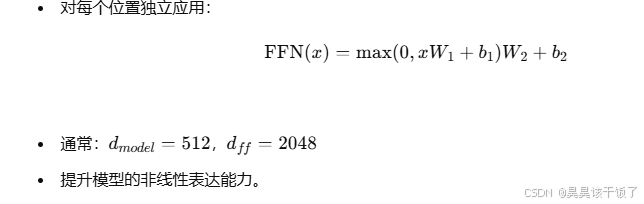
3.3 解码器层结构详解
解码器在结构上比编码器多了一个子层,其三大组件如下:
3.3.1 Masked Multi-Head Self-Attention
-
类似于编码器中的自注意力,但加入了掩码机制(Masking),禁止模型看到未来位置的词。
-
保证在训练阶段每个位置只能依赖前面已生成的词。
3.3.2 编码器-解码器注意力(Encoder-Decoder Attention)
-
Query来自解码器的前一层,Key和Value来自编码器输出。
-
实现解码器对编码结果的条件依赖,即“读懂”源语言的上下文。
3.3.3 前馈神经网络
-
与编码器相同,结构也一致。
3.4 残差连接与归一化策略
Transformer结构中的每个子层都使用Add & Norm:
x = x + Sublayer(x)
output = LayerNorm(x)为什么这么做?
-
残差连接有助于梯度传播,避免梯度消失。
-
LayerNorm消除不同特征维度的分布偏移,使训练更稳定。
相比BatchNorm,LayerNorm对序列长度不敏感,更适合处理变长输入。
3.5 位置编码(Positional Encoding)机制回顾
由于Transformer架构本身不具备位置信息,因此需要加入位置编码。Transformer原始论文中使用的是固定的三角函数编码:
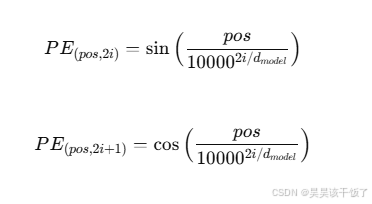
-
可学习的位置编码是后续改进方法之一,增加了适应性。
-
位置编码在嵌入之后、进入编码器/解码器之前加到输入上。
3.6 PyTorch简化实现(Encoder层)
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, heads, d_ff):
super().__init__()
self.attn = MultiHeadAttention(d_model, heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
x2 = self.attn(x, x, x, mask)
x = self.norm1(x + x2)
x2 = self.ffn(x)
x = self.norm2(x + x2)
return x3.7 编码器与解码器的协同工作流程
-
输入经过嵌入和位置编码处理后,进入编码器模块,输出序列表示。
-
解码器接收目标序列输入,通过Masked Attention生成当前步预测。
-
解码器每层会用Encoder输出进行交叉注意力,形成源-目标之间的对齐机制。
-
最终解码器输出通过线性变换 + Softmax 得到词汇预测。
3.8 图示对比:编码器 vs 解码器
| 模块 | 编码器 | 解码器 |
|---|---|---|
| 自注意力 | 是(可见全序列) | 是(加入掩码,只能看前面) |
| 编码器-解码器注意力 | 否 | 是(对编码器输出做注意力) |
| 前馈网络 | 是 | 是 |
| 残差 & LayerNorm | 是(两个) | 是(三个) |
通过对Transformer内部模块的细致分析,我们已经理解了模型中信息如何流动、子层如何协同工作、注意力如何有效建立全局依赖。下一部分,我们将进入主流Transformer模型(如BERT、GPT、T5)的结构与训练策略对比实战,进一步探索这些变体如何在实际任务中表现出强大能力。
四、主流Transformer模型剖析:BERT、GPT、T5对比实战
在理解了Transformer的基础架构和模块细节之后,深入剖析其主流变体将有助于大家在实际应用中做出合理选型。Transformer并非一成不变,而是被不断演化,形成了如 BERT、GPT、T5 等广泛应用于自然语言处理任务的代表性模型。
本节将系统分析三者在结构、训练目标、应用场景等方面的核心差异,并辅以实战案例来帮助理解它们在真实业务中的使用方式。
4.1 模型概览:三大代表架构
| 模型 | 架构类型 | 训练方式 | 应用类型 | 是否可生成文本 |
|---|---|---|---|---|
| BERT | 双向编码器 | Masked Language Model | 分类、问答、抽取等 | 否 |
| GPT | 单向解码器 | 自回归语言模型 | 文本生成、摘要、对话等 | 是 |
| T5 | 编码器-解码器 | Text-to-Text | 万能(分类+生成) | 是 |
4.2 BERT模型详解:双向理解的典范
结构特点:
-
仅使用Transformer的编码器部分。
-
所有注意力是双向的,即上下文中每个词都可以看到左右两边的信息。
训练目标:Masked Language Modeling (MLM)
-
随机遮蔽输入中的一部分词,让模型预测这些被遮蔽的词。
-
增强了对词语上下文语义的理解。
常见下游任务:
-
文本分类(情感分析、主题识别)
-
文本匹配(如自然语言推理NLI)
-
问答系统(SQuAD)
示例代码:文本分类
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
inputs = tokenizer("I love Transformer models!", return_tensors="pt")
outputs = model(**inputs)局限性:
-
不能用于生成任务(没有解码器结构)
-
输入长度有限(最多512个token)
4.3 GPT系列:生成任务的王者
结构特点:
-
仅使用Transformer的解码器部分。
-
使用掩码的自注意力,确保生成时不会看到未来词。
训练目标:自回归语言模型(Autoregressive LM)
-
输入为原始语句,模型学习根据上下文预测下一个词。
应用场景:
-
对话生成(ChatGPT)
-
自动写作、摘要、翻译
-
编码辅助(如Copilot)
示例代码:文本生成
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
inputs = tokenizer("Once upon a time", return_tensors="pt")
outputs = model.generate(**inputs, max_length=50, do_sample=True)
print(tokenizer.decode(outputs[0]))GPT进化:
-
GPT-2:较大,支持生成长文本。
-
GPT-3:参数达175B,支持few-shot、zero-shot任务。
-
GPT-4:多模态支持,逻辑推理能力增强。
4.4 T5模型:统一视角的文本转文本架构
核心理念:Text-to-Text Transfer Transformer
-
所有任务统一转换为“输入文本 → 输出文本”的格式
-
例如:
-
翻译:"translate English to German: How are you?"
-
分类:"cola sentence: The cat sat on the mat."
-
结构特点:
-
完整的编码器-解码器结构(类似Transformer原始架构)
-
可处理输入与输出不同长度的序列
训练方式:使用大规模多任务数据集(C4)进行监督学习
优势:
-
统一架构下易于微调多个任务
-
既能分类又能生成,适配范围广
示例代码:翻译任务
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5ForConditionalGeneration.from_pretrained('t5-small')
input_text = "translate English to French: The book is on the table."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
output_ids = model.generate(input_ids)
print(tokenizer.decode(output_ids[0]))4.5 模型对比分析
| 对比维度 | BERT | GPT | T5 |
| 架构 | 编码器 | 解码器 | 编码器+解码器 |
| 注意力类型 | 双向 | 单向(前向) | 编码双向,解码单向 |
| 输入输出 | 输入→标签 | 输入→预测下一个词 | 输入文本→输出文本 |
| 是否可生成 | 否 | 是 | 是 |
| 适合任务 | 分类、抽取 | 生成、续写 | 多任务通用 |
| 参数规模 | 110M(BERT base) | 124M(GPT-2) | 60M(T5 small)起 |
4.6 应用场景选择建议
| 场景 | 推荐模型 | 理由 |
| 文本分类、情感分析 | BERT | 精度高,训练稳定 |
| 对话生成、写作 | GPT系列 | 自回归能力强,支持长文本输出 |
| 翻译、多任务训练 | T5 | 输入输出可灵活控制,多任务预训练 |
通过对BERT、GPT和T5的结构解析与实际应用展示,大家可以更清晰地选择适合的模型用于自己的项目中。
五、大模型训练工程实战:从数据到部署
上一部分我们对主流Transformer模型的结构和应用场景进行了对比分析,但要将这些模型真正应用到生产环境中,还需掌握从数据准备、模型训练、优化、微调到部署的完整流程。
本节将以工程视角,深入讲解如何构建一个完整的大模型训练管线,并提供实战经验与代码示例,帮助大家应对大模型带来的训练挑战和部署复杂性。
5.1 数据准备:Tokenizer与Dataset构建
Transformer训练的第一步就是将原始文本转化为模型可接受的张量格式。
5.1.1 Tokenizer选择
-
BERT/GPT使用的是WordPiece或Byte-Pair Encoding(BPE)
-
推荐使用HuggingFace中的Tokenizer类
from transformers import AutoTokenizer
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokens = tokenizer("Transformers are powerful models!", padding=True, truncation=True, return_tensors="pt")5.1.2 自定义数据集(Dataset)类
from torch.utils.data import Dataset
class TextDataset(Dataset):
def __init__(self, texts, tokenizer, max_len=128):
self.encodings = tokenizer(texts, truncation=True, padding=True, max_length=max_len)
def __len__(self):
return len(self.encodings['input_ids'])
def __getitem__(self, idx):
return {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}5.2 模型训练:从单机到分布式
5.2.1 使用HuggingFace Trainer快速训练
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="./checkpoints",
evaluation_strategy="epoch",
per_device_train_batch_size=8,
num_train_epochs=3,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
trainer.train()5.2.2 分布式训练策略
| 策略 | 特点 | 场景 |
|---|---|---|
| DDP(DataParallel) | 数据级并行 | 中等规模GPU集群 |
| FSDP(Fully Sharded) | 权重+梯度切分,显存更节省 | 超大模型训练 |
| ZeRO(DeepSpeed) | 三阶段优化显存利用 | 超大语言模型(>10B) |
torchrun --nproc_per_node=4 train.py可使用Accelerate简化多卡训练:
accelerate config && accelerate launch train.py5.3 模型微调与压缩
大模型预训练成本高昂,因此实际应用中往往基于已有模型进行微调(Fine-tuning)或参数高效微调(PEFT)。
5.3.1 微调策略
-
全参数微调:更新全部权重,效果好但开销大
-
冻结部分层:只更新后几层或分类头
5.3.2 参数高效微调技术(PEFT)
| 技术 | 原理 | 特点 |
| Adapter | 插入小模块,仅训练Adapter层 | 简单稳定 |
| LoRA(Low-Rank Adaptation) | 将权重矩阵低秩分解,仅训练可学习矩阵 | 性能优异 |
| Prefix Tuning | 添加可学习前缀向量 | 高效灵活 |
from peft import get_peft_model, LoraConfig
peft_model = get_peft_model(model, LoraConfig(r=4, lora_alpha=16, target_modules=["query", "value"]))5.4 模型压缩与部署
5.4.1 模型压缩
-
量化(Quantization):将模型从FP32转换为INT8
-
剪枝(Pruning):移除低重要性参数
-
蒸馏(Distillation):训练小模型模仿大模型
from optimum.intel import IncQuantizer
quantizer = IncQuantizer(model, tokenizer)
quant_model = quantizer.quantize("dynamic")5.4.2 推理优化
-
使用ONNX/TensorRT加速推理
-
使用TorchScript导出模型
traced = torch.jit.trace(model, example_input)
torch.jit.save(traced, "model.pt")5.4.3 API部署
-
Flask / FastAPI / Gradio / Streamlit
from fastapi import FastAPI
app = FastAPI()
@app.post("/predict")
def predict(text: str):
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs)
return {"result": tokenizer.decode(outputs[0])}运行:
uvicorn app:app --reload5.5 工程实践建议
| 问题 | 建议 |
| 显存爆炸 | 使用FSDP / 混合精度训练 / LoRA |
| 模型过拟合 | 增加正则,使用EarlyStopping或Dropout |
| 部署慢 | ONNX导出 + INT8量化 + 异步推理服务 |
5.6 开源工具链推荐
| 工具 | 功能 |
| HuggingFace Transformers | 模型加载与训练接口 |
| Accelerate | 多卡训练管理 |
| PEFT / LoRA | 高效微调框架 |
| Optimum / Intel Neural Compressor | 推理优化与压缩 |
| FastAPI / Gradio | 模型部署接口 |
至此,我们完成了从数据准备到部署的大模型训练全流程解析。
六、Transformer架构的演化与趋势
前几部分我们系统讲解了Transformer的原理、模块、变体和训练落地过程。作为一项具有深远影响的架构,Transformer并未停留在最初提出的形式,而是持续进化,适应多个任务、场景和硬件环境的需求。
本节将全面总结Transformer的发展趋势,涵盖效率优化、多模态融合、长序列建模、跨领域应用等多个方向,帮助大家了解当前研究前沿与工业界动态。
6.1 计算效率优化:从稠密到稀疏
Transformer原始结构的最大问题之一是计算复杂度为O(n^2) ,尤其在处理长文本或大图像时成本极高。为此,研究者提出了一系列高效变体,其目标是降低注意力机制中的计算和内存开销。
代表性模型与机制:
| 模型 | 技术手段 | 特点 |
|---|---|---|
| Linformer | 低秩近似 | 将注意力矩阵压缩为固定维度 |
| Performer | 核技巧(FAVOR+) | 精确近似点积注意力 |
| Longformer | 局部+全局注意力 | 适合超长文本,支持段落级分析 |
| Reformer | 局部敏感哈希 | 节省内存,提升效率 |
示例:Longformer的稀疏注意力图解
-
局部窗口:每个token只与附近token交互
-
全局token:可与全序列交互(如[CLS])
工程建议:
-
对于输入长度超过1024的任务(如文档分类、代码分析),优先选择高效注意力变体
-
使用
transformers库中的LongformerModel或BigBirdModel
6.2 多模态融合:文字、图像、音频统一建模
Transformer原生就具备统一处理序列的能力,因此天然适合扩展至多模态场景。近年来,多模态Transformer模型如雨后春笋般出现,广泛应用于图文理解、视频问答、跨模态检索等领域。
代表模型:
| 模型 | 输入模态 | 应用 |
| ViT(Vision Transformer) | 图像 | 图像分类、检测 |
| CLIP(OpenAI) | 图像 + 文本 | 图文匹配、图像生成控制 |
| BLIP / Flamingo | 图像 + 文本 | 图文问答、图文生成 |
| Whisper(OpenAI) | 音频 + 文本 | 语音识别、翻译 |
ViT简析:
-
将图像切分为固定大小patch
-
每个patch嵌入为向量,送入Transformer编码器
-
类似文本序列建模过程
多模态挑战:
-
如何统一不同模态的表征方式?
-
不同模态序列长度差异巨大,如何建模对齐关系?
-
模态不完整时如何做鲁棒预测?
6.3 长序列建模:超越512 token限制
传统Transformer模型最大输入长度为512或1024,这在法律文书、代码理解、金融分析等任务中远远不够。
新趋势:
-
结构优化:Sparse Attention、Memory Cache
-
分层建模:Segment级别建模、滑动窗口机制
-
压缩表示:Summarize历史上下文、Cache状态向量(如Transformer-XL)
推荐模型:
-
Longformer、BigBird(Google)
-
Memorizing Transformer(2022 NeurIPS):引入显式记忆模块
-
RWKV:结合RNN的线性推理能力与Transformer的并行优势
6.4 模型规模趋势:从BERT到千亿参数
Transformer模型参数规模不断突破:
| 模型 | 参数规模 | 机构 |
| BERT base | 110M | |
| GPT-3 | 175B | OpenAI |
| PaLM | 540B | |
| GPT-4(估计) | >1T | OpenAI |
趋势:
-
模型越大,通用能力越强(few-shot、zero-shot)
-
大模型+少量样本微调(Instruct tuning)成为主流范式
工程挑战:
-
模型训练资源需求指数级增长
-
参数冗余 vs 表达能力的博弈
6.5 应用边界扩展:从NLP走向跨领域
Transformer已渗透进除NLP外的多个领域:
| 领域 | 应用示例 |
| 计算机视觉 | ViT, DETR, SAM(分割) |
| 语音处理 | Whisper, Wav2Vec 2.0 |
| 蛋白质结构预测 | AlphaFold2(基于Attention) |
| 推荐系统 | DeepCTR + Transformer结构改造 |
| 代码理解/生成 | CodeBERT, Codex, StarCoder |
值得关注的研究方向:
-
通用大模型(Foundation Model)如何跨模态适配?
-
跨任务预训练与解耦策略设计
6.6 小结:Transformer的未来展望
Transformer已从一个“序列建模工具”演变为AI系统的“基础骨架”。其演化趋势体现为:
-
结构轻量化:提升效率以适应边缘部署
-
范式统一化:Text-to-Text / Prompt-based 模型统一任务表达
-
能力多样化:多模态、多任务、多语言支撑
-
训练稳定化:探索更稳健的优化器与范式(如RLHF)


















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











