







Contextual Transformer Networks for Visual Recognition
paper: Contextual Transformer Networks for Visual Recognition
code: https://github.com/JDAI-CV/CoTNet
一、引言
最近研究领域激发了Transformer风格的架构设计的出现,并在众多计算机视觉任务中取得了竞争性的结果。然而,大多数现有设计直接在2D特征图上使用自注意力,以基于每个空间位置处的孤立查询和键对来获得关注矩阵,但未充分利用相邻键之间的丰富上下文。本文设计了一个新颖的Transformer风格模块,即上下文Transformer(CoT)块,用于视觉识别。这种设计充分利用了输入键之间的上下文信息来指导动态注意力矩阵的学习,从而增强了视觉表示的能力。从技术上讲,CoT块首先通过3×3卷积对输入键进行上下文编码,使输入的静态上下文表示。我进一步将编码密钥与输入查询连接起来,通过两个连续的1×1卷积来学习动态多头注意力矩阵。学习的注意力矩阵乘以输入值,以实现输入的动态上下文表示。最终将静态和动态上下文表示的融合作为输出。
(一)、Our Approach
在本文中,提出一个简单的问题——有没有一种优雅的方法通过利用2D特征图上输入键之间的丰富上下文来增强Transformer风格的架构?本文提供了一个独特的Transformer样式块设计,名为Contextual Transformer(CoT),如下图(b)所示。这样的设计在单个架构中统一了键之间的上下文挖掘和2D特征图上的自注意力学习,从而避免了为上下文挖掘引入额外的分支。从技术上讲,在CoT块中,首先通过对3×3网格内的所有相邻密钥执行3×3卷积来上下文化密钥的表示。上下文化的关键特征可以被视为输入的静态表示,它反映了局部邻域之间的静态上下文。之后,将上下文化的关键特征和输入查询的级联输入到两个连续的1×1卷积中,以产生注意力矩阵。这个过程自然地利用了每个查询之间的相互关系以及在静态上下文的指导下进行自注意力学习所有键。学习的注意力矩阵被进一步用于聚集所有输入值,并因此实现输入的动态上下文表示以描绘动态上下文。将静态和动态上下文表示的组合作为CoT块的最终输出。总之,本文的出发点是同时捕获输入键之间的上述两种空间上下文,即通过3×3卷积的静态上下文和基于上下文化的自注意力的动态上下文,以促进视觉表示学习。

(二)、Multi-head Self-attention in Vision Backbones
本文总结了视觉主干中可缩放的局部多头自注意力的一般公式,如下图(a)所示。形式上,给定大小为H×W×C(H:高度,W:宽度,C:通道数)的输入2D特征图X,分别通过嵌入矩阵
(
W
q
,
W
k
,
W
v
)
(W_q,W_k,W_v)
(Wq,Wk,Wv)将X转换为查询
Q
=
X
W
q
Q=XW_q
Q=XWq,键
K
=
X
W
k
K=XW_k
K=XWk,和值
V
=
X
W
v
V=XW_v
V=XWv。值得注意的是,每个嵌入矩阵在空间中用1×1卷积实现。然后,得到局部关系矩阵
R
∈
R
H
×
W
×
(
k
×
k
×
C
h
)
R∈R^{H×W×(k×k×C_h)}
R∈RH×W×(k×k×Ch) 键k和查询Q之间的为:

C
h
C_h
Ch是注意力头的数量,*表示局部矩阵乘法运算,该运算测量每个查询与空间中局部k×k网格内的对应键之间的成对关系。因此,R的第i个空间位置处的每个特征
R
(
i
)
R^{(i)}
R(i)是
k
×
k
×
C
h
k×k×C_h
k×k×Ch维向量,其由所有头部的
C
h
C_h
Ch局部查询关键字关系图(大小:k×k)组成。局部关系矩阵R进一步丰富了每个k×k网格的位置信息:

其中
P
∈
R
k
×
k
×
C
k
P∈ R^{k×k×C_k}
P∈Rk×k×Ck表示每个k×k网格内的2D相对位置嵌入,并在所有
C
h
C_h
Ch头上共享。接下来,通过沿着每个头部的通道维度使用Softmax操作对增强的空间感知局部关系矩阵进行归一化来实现关注矩阵A:
A
=
S
o
f
t
m
a
x
(
R
^
)
A=Softmax(\hat{R})
A=Softmax(R^)。在将A的每个空间位置处的特征向量重塑为
C
h
C_h
Ch个局部关注矩阵(大小:k×k)之后,最终输出特征图被计算为每个k×k网格内的所有值与学习的局部关注矩阵的集合:

每个头部的局部注意力矩阵仅用于聚集沿通道维度均匀划分的V的特征图,并且最终输出Y是所有头部的聚集特征图的级联。

二、Contextual Transformer Block
传统的自注意力很好地触发了不同空间位置的特征交互,这取决于输入本身。然而,在传统的自注意力机制中,所有成对的查询关键字关系都是在孤立的查询关键字对上独立学习的,而不需要探索其间的丰富上下文。这严重限制了用于视觉表示学习的2D特征图上的自注意力学习的能力。为了缓解这个问题,本文构建了一个新的Transformer风格的构建块,即上图(b)中的Contextual Transformer(CoT)块,它将上下文信息挖掘和自注意力学习集成到一个统一的架构中。它可以是充分利用相邻键之间的上下文信息,以有效的方式促进自注意力学习,并增强输出聚合特征图的代表能力。
假设有相同的输入2D特征图
X
∈
R
H
×
W
×
C
X∈ R^{H×W×C}
X∈RH×W×C。键、查询和值分别定义为K=X、Q=X和
V
=
X
W
v
V=XW_v
V=XWv。CoT块首先对k×k网格内的所有相邻密钥进行k×k组卷积,以在空间上对每个密钥表示进行上下文信息挖掘,而不是像典型的自注意力那样通过1×1卷积对每个密钥进行编码。学习的上下文键
K
1
∈
R
H
×
W
×
C
K^1∈ R^{H×W×C}
K1∈RH×W×C自然地反映了本地相邻密钥之间的静态上下文信息,将
K
1
K^1
K1作为输入X的静态上下文表示。之后,在上下文化密钥
K
1
K^1
K1和查询Q的级联的条件下,通过两个连续的1×1卷积(
W
θ
W_θ
Wθ具有ReLU激活函数,
W
δ
W_δ
Wδ不具有激活函数)来实现注意力矩阵:

对于每个注意力头,基于查询特征和上下信息的关键特征而不是孤立的查询关键字来学习A的每个空间位置处的局部注意力矩阵。这种方式通过挖掘的静态上下文
K
1
K^1
K1的额外指导来增强自注意力学习。接下来,根据上下文注意力矩阵A,通过聚合所有值V来计算注意力特征图
K
2
K^2
K2,如典型的自注意力:

鉴于注意力特征图
K
2
K^2
K2捕捉了输入之间的动态特征交互,将
K
2
K^2
K2命名为输入的动态上下文表示。因此,CoT块(Y)的输出通过注意力机制为静态上下文
K
1
K^1
K1和动态上下文
K
2
K^2
K2的融合。
(一)、Contextual Transformer Networks
CoT的设计是一个统一的c构建块,作为ConvNet中标准卷积的替代方案。因此,用CoT代替卷积加强视觉主干是可行的。这里,介绍了如何将CoT块集成到现有的最先进的ResNet架构(例如,ResNet和ResNeXt)中,而不显著增加参数预算。下表显示了基于ResNet-50/ResNeXt-50主干的上下文变压器网络(CoTNet)的两种不同结构,分别称为CoTNet-50和CoTNeXt-50。CoTNet可以灵活地推广到更深层次的网络(例如ResNet-101)。

CoTNet-50:CoTNet50是通过用CoT块直接替换ResNet-50中的所有3×3卷积(在res2、res3、res4和res5阶段)。由于CoT块在计算上与典型卷积相似,CoTNet-50具有相似(甚至稍小)的参数数量和与ResNet-50的FLOP。

CoTNeXt-50:首先用CoT块替换ResNeXt-50的分组卷积中的所有3×3卷积核。与典型的卷积相比,当组的数量(即表2中的C)增加时,分组卷积内的内核深度显著降低。在ResNeXt-50中,分组卷积的计算成本因此降低了C倍。因此,为了实现与ResNeXt-50相似的参数数量和FLOP,将CoTNeXt-50的输入特征图的比例从32×4d减少到2×48d。最后,CoTNeXt-50只需要比ResNeXt-50多1.2倍的参数和1.01倍的FLOP。
(二)、Connections with Previous Vision Backbones
Blueprint Separable Convolution:用1×1点卷积加上k×k深度卷积逼近传统卷积,旨在减少沿深度轴的冗余。这种设计与Transformer模块有一些共同之处(例如,典型的Transformer和CoT模块)。这是因为Transformer样式的块还利用1×1逐点卷积将输入转换为值,并且以类似的深度方式使用k×k局部注意力矩阵执行随后的聚合计算。此外,对于每个头部,Transformer块中的聚合计算采用通道共享策略,以有效实现,而没有任何显著的精度下降。这里,所利用的通道共享策略也可以解释为绑定块卷积,其在相等的通道块上共享相同的滤波器。
Dynamic Region-Aware Convolution :介绍了一个滤波器生成器模块(由两个连续的1×1组成),用于学习针对不同空间位置的区域特征的专用滤波器。因此,它与CoT块中的注意力矩阵生成器具有相似的作用,该生成器实现了每个空间位置的动态局部注意力矩阵。然而,这种滤波器生成器模块基于主要输入特征图生成专用滤波器。相比之下,本文的注意力矩阵生成器充分利用了上下文化键和查询之间的复杂特征交互,用于自注意力学习。
Bottleneck Transformer:还旨在通过用Transformer样式的模块替换3×3卷积来增强具有自注意力机制的ConvNet。它采用了全局多头自注意力层,这在计算上比CoT块中的局部自关注更多。因此,对于相同的ResNet主干,BoT50仅用瓶颈转换器块替换了最后三个3×3卷积,而CoT块可以在整个深度架构中完全替换3×3的卷积。此外,CoT块超越了典型局部自注意力,通过利用输入键之间的丰富上下文来加强自注意力的学习。
三、实验实现
(一)对比实验
默认的训练设置是经典视觉主干中广泛采用的设置(例如,ResNet、ResNeXt和SENet),该设置通过标准预处理训练网络约100个轮次。每个输入图像被裁剪成224×224,并且仅执行标准数据增强(即,随机裁剪和50%概率的水平翻转)。所有超参数都按照官方实现设置,无需任何额外调整。类似地,CoTNet是以端到端的方式进行训练的,通过使用动量为0.9的SGD和签平滑0.1的反向传播。将批大小设置为B=512,在8-GPU机器上实现适用的实现。对于前五个轮次,学习率从0线性缩放到
0.1
B
256
\frac{0.1B}{256}
2560.1B,通过余弦退火进一步衰减。在训练期间采用了权重为0.9999的指数移动平均值。
为了与最先进的主干网(例如,ResNeSt、EfficientNet和LambdaNetworks)进行公平比较,还采用了具有更长训练周期和改进的数据扩充和正则化的高级训练设置。在这一设置中,使用350个时期训练CoTNet,再加上RandAugment和mixed的额外数据扩充,以及dropout和DropConnect的正则化。

上图为与ImageNet上最先进的图像识别视觉主干的性能比较(默认训练设置)。将具有相同深度(50层/101层)的模型分组以进行效率比较 *表示在训练期间使用指数移动平均值。

上图为与ImageNet(高级训练设置)上最先进的图像识别视觉骨干的性能比较。

上图为ImageNet上的推理时间与精度曲线(默认训练设置)。

上图为 ImageNet上的推理时间与精度曲线(高级训练设置)。
(二)、消融实验
在CoT块,首先通过3×3卷积来挖掘密钥之间的静态上下文。基于查询和上下文化键的连接,还可以通过自注意力获得动态上下文。CoT块动态地融合静态和动态上下文作为最终输出。在这里,通过直接对两种上下文求和来组成CoT块的一个变体,称为线性融合。可以解释为一种没有自我关注的ConvNet。接下来,通过通过自注意力直接利用动态上下文,动态上下文表现出更好的性能。静态和动态上下文的线性融合有了78.7%的提升,这基本上验证了两种上下文的互补性。CoT块通过注意力进一步受益于动态融合,CoT的前1精度最终达到79.2%


(三)、目标检测

在目标检测的下游任务(基础检测器:Faster-RCNN和Cascade-RCNN)上与最先进的视觉骨干进行性能比较。平均精度(AP)是在不同的IoU阈值和三种不同的对象大小下报告的:小、中、大(s/m/l)。
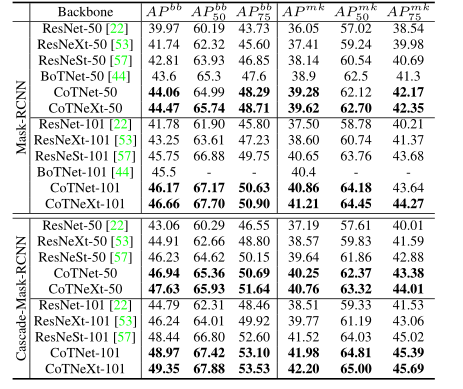
在实例分割的下游任务(基础模型:Faster-RCNN和Cascade-RCNN)上与最先进的视觉骨干进行性能比较。在不同的IoU阈值下报告边界框和掩码平均精度(
A
P
b
b
AP^{bb}
APbb、
A
P
m
k
AP^{mk}
APmk)。请注意,BoTNet-50/101使用更大的输入大小1024×1024和更长的训练周期(36)进行了微调。















 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









