







发表时间:2021
论文地址:https://arxiv.org/abs/2107.12292
文章目录
摘要
带有自注意力的Transformer导致了 nlp 领域的革命,也启发了在计算机视觉任务上。大多数存在的设计直接使用2D特征图来获得注意力矩阵,基于每个位置独立的queries和keys,使得相邻keys之间丰富的上下文信息利用不足。
在这项工作中,我们设计了一个新颖的Transformer风格的模块,即Contextual Transformer (CoT) block,用于视觉检测。这样的设计充分利用了输入keys之间的上下文信息来指导动态注意力矩阵的学习和增强视觉表现能力。在技术上,CoT块通过一个3×3卷积进行上下文编码,得到了输入图像的静态上下文表示。进一步连接编码后的keys和输入的queries来学习动态的多头注意力矩阵。学到的注意力针具乘以输入values来实现输入的动态上下文表示。静态和动态上下文表示的融合作为输出。
我们的CoT块可以替代ResNet结构中的每个3×3卷积,得到一个名为Contextual Transformer Networks (CoT-Net) 的网络
3 方法
首先提供了一个传统自注意力的回顾。接下来是contextual transformer(CoT)。
将整个深度结构中的3×3卷积替换成CoT块,CoTNet和CoTNeXt来源于ResNet和ResNeXt。
3.1. Multi-head Self-attention in Vision Backbones
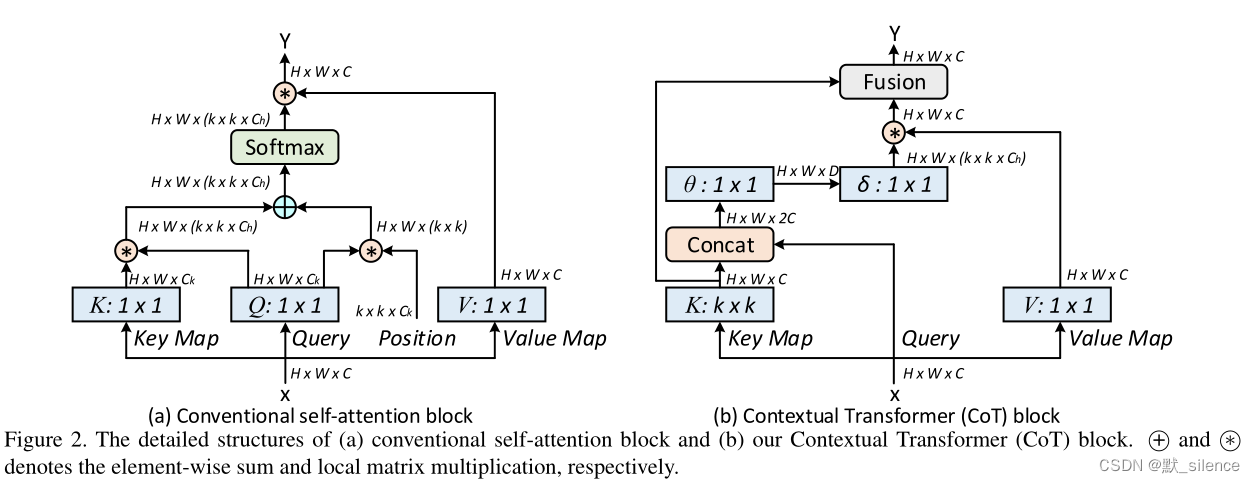
一般的多头自注意力公式,给定一个2D的特征图X,大小为H×W×C,通过嵌入矩阵( W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv)将X转换为querirs,keys,values:
Q = X W q , K = X W k , V = X W v Q=XW_q,K=XW_k,V=XW_v Q=XWq,K=XW
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









