







YOLO目标检测创新改进与实战案例专栏
专栏目录: YOLO有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLO目标检测创新改进与实战案例
介绍

摘要
Transformer自注意力机制已经引领了自然语言处理领域的革命,并且最近激发了Transformer风格架构设计在众多计算机视觉任务中取得竞争性结果。然而,大多数现有设计直接在二维特征图上使用自注意力机制,以基于每个空间位置的孤立查询和键对来获取注意力矩阵,但没有充分利用邻近键之间的丰富上下文信息。在这项工作中,我们设计了一种新颖的Transformer风格模块,即Contextual Transformer(CoT)块,用于视觉识别。该设计充分利用了输入键之间的上下文信息,以引导动态注意力矩阵的学习,从而增强视觉表示的能力。
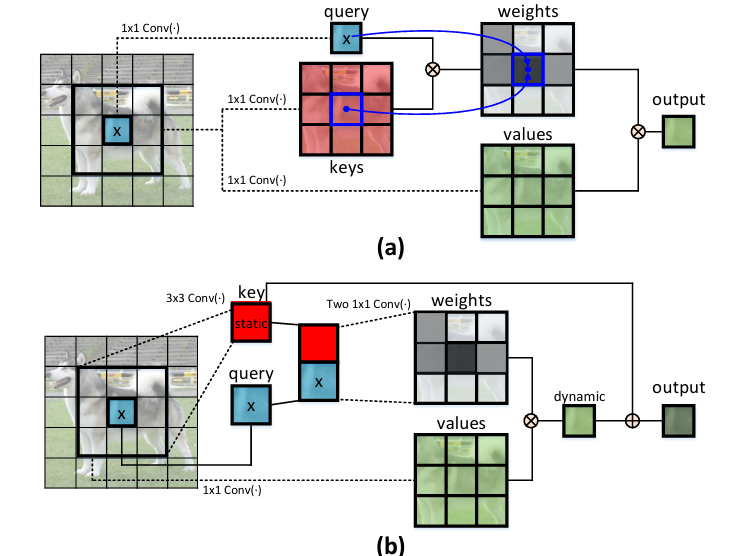
在技术上,CoT块首先通过一个3×3卷积对输入键进行上下文编码,导致输入的静态上下文表示。我们进一步将编码后的键与输入查询连接起来,通过两个连续的1×1卷积来学习动态多头注意力矩阵。学习到的注意力矩阵与输入值相乘,以实现输入的动态上下文表示。静态和动态上下文表示的融合最终作为输出。我们提出的CoT块非常有吸引力,因为它可以轻松替换ResNet架构中的每一个3×3卷积,从而生成一种名为Contextual Transformer Networks(CoTNet)的Transformer风格骨干网络。通过在广泛应用(例如图像识别、目标检测和实例分割)中的大量实验,我们验证了CoTNet作为更强骨干网络的优越性。源码可在https://github.com/JDAI-CV/CoTNet获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
CoTNet是一种基于Contextual Transformer(CoT)模块的网络结构,其原理如下:
-
CoTNet原理:
- CoTNet采用Contextual Transformer(CoT)模块作为构建块,用于替代传统的卷积操作。
- CoT模块利用3×3卷积来对输入键之间的上下文信息进行编码,生成静态上下文表示。
- 将编码后的键与输入查询连接,通过两个连续的1×1卷积来学习动态多头注意力矩阵。
- 学习到的注意力矩阵用于聚合所有输入数值,生成动态上下文表示。
- 最终将静态和动态上下文表示融合作为输出。
-
Contextual Transformer Attention在CoTNet中的作用和原理:
Contextual Transformer Attention是Contextual Transformer(CoT)模块中的关键组成部分,用于引导动态学习注意力矩阵,从而增强视觉表示并提高计算机视觉任务的性能
- Contextual Transformer Attention是CoT模块中的注意力机制,用于引导动态学习注意力矩阵。
- 通过Contextual Transformer Attention,模型能够充分利用输入键之间的上下文信息,从而更好地捕捉动态关系。
- 这种注意力机制有助于增强视觉表示,并提高计算机视觉任务的性能。
- CoTNet通过整合Contextual Transformer Attention,实现了同时进行上下文挖掘和自注意力学习的优势,从而提升了深度网络的表征能力。

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 4546
4546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











