







一.介绍
对YOLO做了一些改进。但也只是一些小的改变,最终使得网络表现更好。针对v1、v2的原理和技巧,v3变动不多。YOLO3主要的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
二.细节
2.1 边界框预测
(1)与YOLOv2相同:使用dimension clusters来找到先验anchor boxes,然后通过anchor boxes来预测边界框。
网络预测边界框的4个坐标,分别是tx、ty、tw、th。如果网格单元从图像左上角偏移(cx, cy),先验anchor box有宽度和高度pw, ph,则网络预测的边界框为(bx,by,bw,bh):
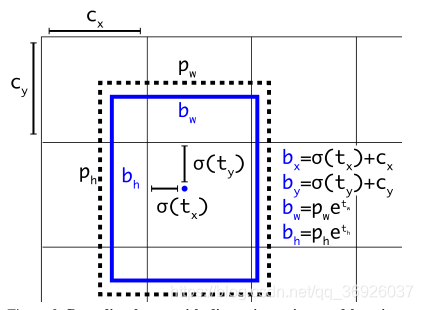
(2)YOLO用逻辑回归预测每个边界框的objectness score。如果当前预测的边界框与ground truth重合最好,那它的分数就是1。如果当前的预测不是最好的,但它和ground truth对象重合到了一定阈值以上,网络会忽视这个预测。
系统只为每个ground truth对象分配一个边界框,如果边界框并未分配给相应对象,那它不会导致坐标或类预测的损,只会导致目标损失。
在训练期间,使用平方误差损失之和
2.2 类预测
边界框使用多标签分类来预测边界框可能包含的类。
不使用softmax:
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
1.softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,比如一个人有Woman 和 Person两个标签。使用softmax,它会强加一个假设,使得每个框只包含一个类别,.因此Softmax不适用于多标签分类。
2.Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
分类损失采用binary cross-entropy loss.
使用独立的logistic逻辑分类器,进行预测。
在训练过程中,使用二元交叉熵损失进行类预测。
2.3 跨尺度预测
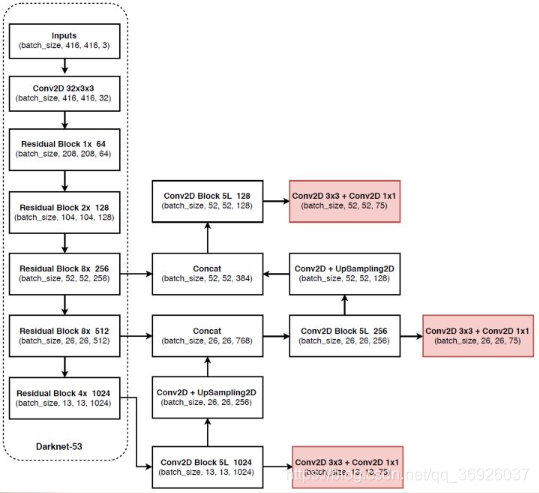
思想:
(1)YOLOv3采用了3个不同尺度的特征图(三个不同卷积层提取的特征)
详解:YOLOv3采用了3个尺度的特征图(当输入为416 x 416时,)这些特征图是通过对输入下采样32x,16x,8x得到,特征图为(13 x 13), (26 x 26),(52 x 52) 。VOC数据集上的YOLOv3网络结构如上图所示,其中红色部分为各个尺度特征图的检测结果。
(2)YOLOv3每个尺度的特征图上使用3个先验anchor box。
详解:使用dimension clusters得到9个聚类中心(先验anchor boxes),并将这些anchor boxes划分到3个尺度特征图上,尺度更大的特征图使用更小的先验框。
(3)YOLOv3对每个尺度下的特征图都进行边界框的预测。
详解:每种尺度的特征图上可以得到 N × N × [3 ∗ (4 + 1 + 80)] 的结果,分别是N x N个 gird cell ,3种尺度的anchors,4个边界框偏移值、1个目标预测置信度以及80种类别的预测概率。
该方法允许从上采样的特征中获取更有意义的语义信息,从早期的特征图中获取更细粒度的信息。
不同尺度下的预测方法:
(1)第一种尺度:
特征图:对原图下采样32x得到(13 x 13)特征图
预测:在上述特征图后添加几个卷积层,最后输出一个 N × N × [3 ∗ (4 + 1 + 80)] 的张量表示预测。----图中第3个红色部分
(2)第二种尺度:
特征图:来源于两种计算
1.对原图下采样16x得到 (26 x 26)特征图
2.对第一种尺度得到的(13 x 13)特征图进行上采样,得到(26 x 26)特征图。
两种计算得到的(26 x 26)特征图通过连接合并在一起。
预测:在合并后的特征图后添加几个卷积层,最后输出一个 N × N × [3 ∗ (4 + 1 + 80)] 的张量表示预测。这个张量的大小是尺度一输出张量大小的两倍----图中第2个红色部分
(3)第三种尺度:
特征图:来源于两种计算
1.对原图下采样8x得到 (52 x 52)特征图
2.对第二种尺度得到的(26 x 26)特征图进行上采样,得到(52 x 52)特征图。
两种方式得到的(52 x 52)的特征图通过连接合并在一起。
预测:在合并后的特征图后添加几个卷积层,最后输出一个 N × N × [3 ∗ (4 + 1 + 80)] 的张量表示预测。这个张量的大小是尺度二输出的两倍----图中第1个红色部分.
对第三尺度的预测受益于所有的先验计算以及网络早期的细粒度特性。
2.4 特征提取
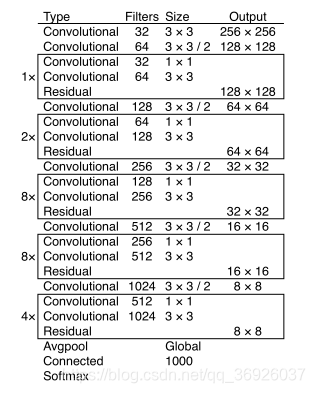
使用一个新的网络来进行特征提取。新网络相比YOLOv2的Darknet-19,使用了残差结构,使用了ResNet中的残差结构可以更大,它有53个卷积层,称之为Darknet-53
新网络比Darknet19强大得多,并且比ResNet-101或ResNet-152有效率。相同设置下的实验结果:
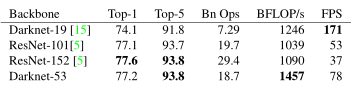
(Top1和Top5:模型在ImageNet数据集上进行推理,按照置信度排序总共生成5个标签。按照第一个标签预测计算正确率,即为Top1正确率;前五个标签中只要有一个是正确的标签,则视为正确预测,称为Top5正确率)
2.5 训练
训练完整的图像,没有硬负面挖掘。使用多尺度的训练,大量的数据扩充,批量标准化。使用Darknet神经网络框架来训练和测试。
3.结果
COCO数据集上的实验结果,它与SSD变体mAP相当,但是快了3倍。但是它仍然落后于其他RetinaNet模型。
但是,当查看IOU= 0.5(图中的AP50,旧”检测度量时)处的mAP,YOLOv3是非常强大的。它几乎与RetinaNet持平,远远高于SSD变体。但是随着IOU阈值的增加,性能会显著下降,这表明YOLOv3很难使边界框与目标完全对齐。
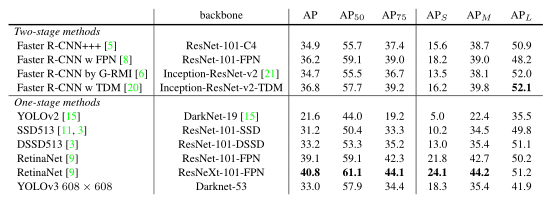
在过去,YOLO很难检测小目标。然而现在这一趋势发生逆转。通过新的多尺度预测,YOLOv3具有较高的应用性能。
4.尝试
(1)尝试使用普通的anchor预测机制,其中使用线性激活预测x, y偏移为的anchor box的宽度或高度的倍数。这种方法降低了模型的稳定性,效果不是很好
(2)尝试使用线性激活来直接预测x, y偏移量,而不是逻辑逻辑激活。这导致了一些mAP的下降。
(3)尝试过focal损失。mAPx下降2个点。YOLOv3可能已经对focal loss试图解决的问题很健壮,因为它有独立的目标预测和条件类预测。
(4)Faster RCNN在训练中使用两个IOU阈值。如果预测框与真值d IOU大于0.7的,则边界框作为正样本。如果IOU在0.3-0.7之间它被忽略,小于0.3阈值时,它是一个负样本。我们尝试了类似的策略,但没有得到好的结果。

















 3834
3834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









