







fastchat
来看看fastchat是怎么部署成api的呀
参考教程:
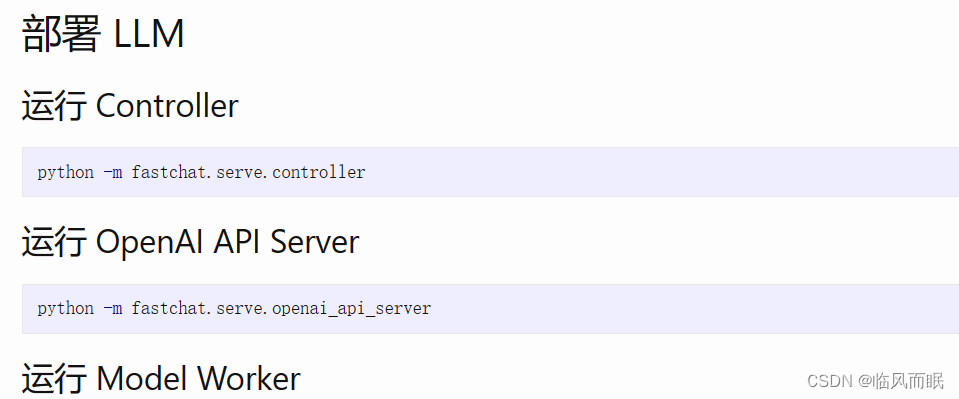
我按照第二个教程链接,一次运行controller,openai api server,还有model worker,然后报错了
[Errno 99] error while attempting to bind on address ('::1', 21001, 0, 0)
按照这篇说的解决了
我给三个命令都加上了host 0.0.0.0
python3 -m fastchat.serve.controller --host 0.0.0.0
python -m fastchat.serve.openai_api_server --host 0.0.0.0
python -m fastchat.serve.model_worker \
--model-path /root/model/chatglm3-6b --port 21003 \
--worker-address http://localhost:21003 \
--host 0.0.0.0
我是分别在三个终端运行的
然后就可以调用端口啦(参考)
下面注释掉的也能用
# import requests
# import json
# response = requests.get('http://localhost:8000/v1/models')
# data = response.json()
# # 使用json.dumps函数美化JSON数据
# pretty_data = json.dumps(data, indent=4)
# print(pretty_data)
import requests
import json
url = "http://localhost:8000/v1/chat/completions"
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
}
data = {
"model": "chatglm3-6b",
"max_tokens": 2048,
# "prompt": "写一篇1000字的作文:《2024回家过年》"
"messages": [
{ "role": "system", "content": "你是一名二次元助手,回答要精简。" },
{ "role": "user", "content": "最近有什么好看的番剧?" }
]
}
response = requests.post(url, headers=headers, data=json.dumps(data))
# 打印响应内容
print(response.json())
或者用curl
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "chatglm3-6b",
"messages": [{"role": "user", "content": "北京景点"}],
"temperature": 0.7
}'
去看看源代码
可以看到是使用了fastapi
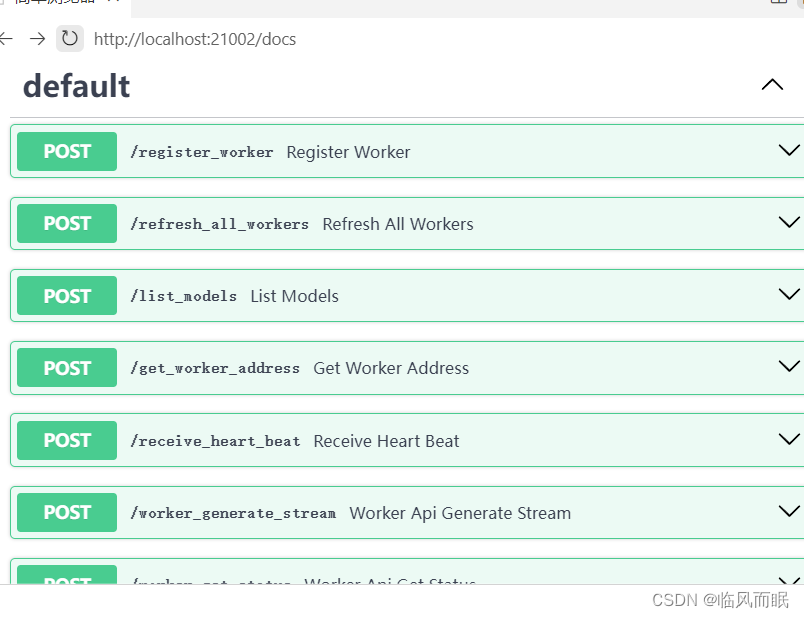
可以看看对应的接口文档,
http://localhost:21002/docs
可以去这些url后面加个/docs
然后try it out
就都能测试,这些接口
和那些代码里面@的地方是相对应的
如何终止服务
fastchat的封装解析
这篇写的挺好:FastChat工作原理解析
vllm
没写完,遇到bug没解决
- 参考:
python -m vllm.entrypoints.api_server --trust-remote-code --model /root/model/chatglm3-6b
INFO 05-18 15:38:07 llm_engine.py:70] Initializing an LLM engine with config: model='/root/model/chatglm3-6b', tokenizer='/root/model/chatglm3-6b', tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=8192, download_dir=None, load_format=auto, tensor_parallel_size=1, quantization=None, enforce_eager=False, seed=0)
WARNING 05-18 15:38:07 tokenizer.py:62] Using a slow tokenizer. This might cause a significant slowdown. Consider using a fast tokenizer instead.
INFO 05-18 15:38:19 llm_engine.py:275] # GPU blocks: 18773, # CPU blocks: 9362
INFO 05-18 15:38:22 model_runner.py:501] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 05-18 15:38:22 model_runner.py:505] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode.
INFO 05-18 15:38:26 model_runner.py:547] Graph capturing finished in 4 secs.
INFO: Started server process [99226]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
INFO: 127.0.0.1:40436 - "GET / HTTP/1.1" 404 Not Found
INFO: 127.0.0.1:40436 - "GET /favicon.ico HTTP/1.1" 404 Not Found















 1144
1144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









