






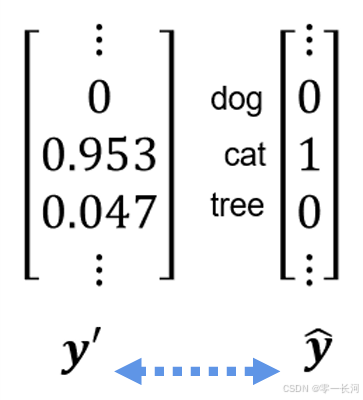
1,做分类的输出和输入
输出采用的独热编码(one-hot),用向量形式表示,预测值采用的概率形式表示,最大的概率作为分类的判断结果.判断真实结果和预测的概率的差值求loss采用交叉熵。
所以求两个预测概率之间的loss函数选择交叉熵损失函数而不是mse损失函数
预测值y’真实值y^
输入的图片一般可以采用3×224×224的大小,3表示通道数,正常一张图片是有RGB三个通道,宽度和高度都是224.每一个像素点都可以用一个数值表示,因此可以将一个图片看作3×224×224张量。
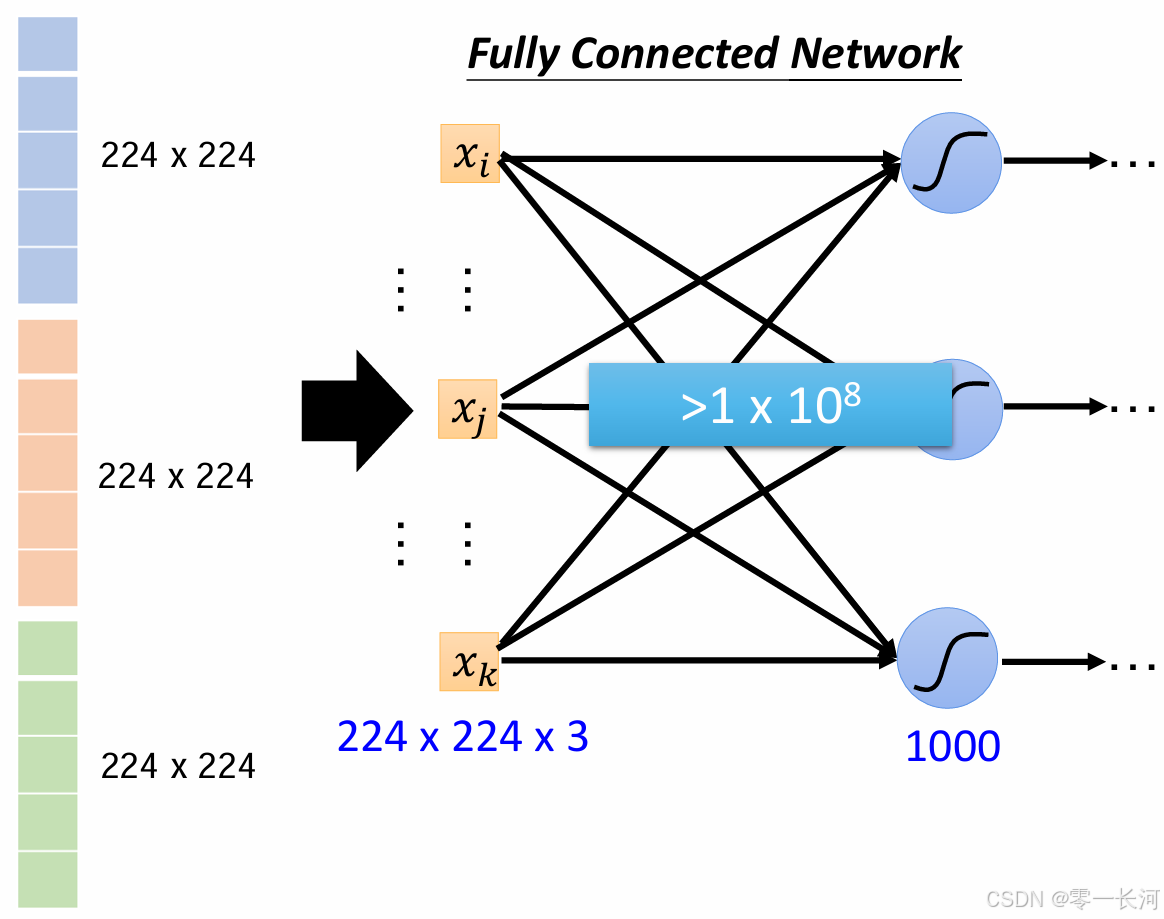
如果采用正常的全连接,那么要把一张图片每个通道展开成一条直线,将三个通道拼在一起,形成一个超大的向量作为输入,每个像素点作为一个特征输入,先不说能不能出结果,这样做参数会过多,出结果很大可能也会导致过拟合的现象。除非是很小的灰度图文字数字识别可以。
所以要通过卷积神经网络减少参数
2,卷积
2.1基本解释
因此要采用卷积这样一个工具来帮助我们做模型的训练。
要处理的图片被称为特征图,处理过得到的“图片”也被称为特征图。处理图片的工具是一个特别小的张量,每层大小一般取3×3,5×5,7×7…这样的,通道数要和要处理的特征图保持一致,称为卷积核。卷积核的大小叫做感受野,就是卷积核每次能“看到”的范围。
例如对3×224×224的图片,可以用3×3×3这样的卷积核。
卷积的最基本过程是用卷积核和特征图,在每个位置对应元素相乘再相加,得到每个数组合成一个新的张量,作为一个新的特征图。动图上面深色的遮罩表示卷积核,遮罩和蓝色矩阵的对应位置每个元素都相乘,求和,得到结果放在绿色矩阵的对应位置上。
还有就是这个蓝色图周围有一圈虚线方格,这个是zero-padding,就是在周围补一圈0,为了可以让卷积核对原特征图处理以后得到的新特征图能和原特征图的大小保持不变。

2.2图片识别
那么卷积是如何识别出来相同或者类似的图案呢?


看这两个图,这个大的图案中是否有右侧这个小的图案或者类似的图案呢?
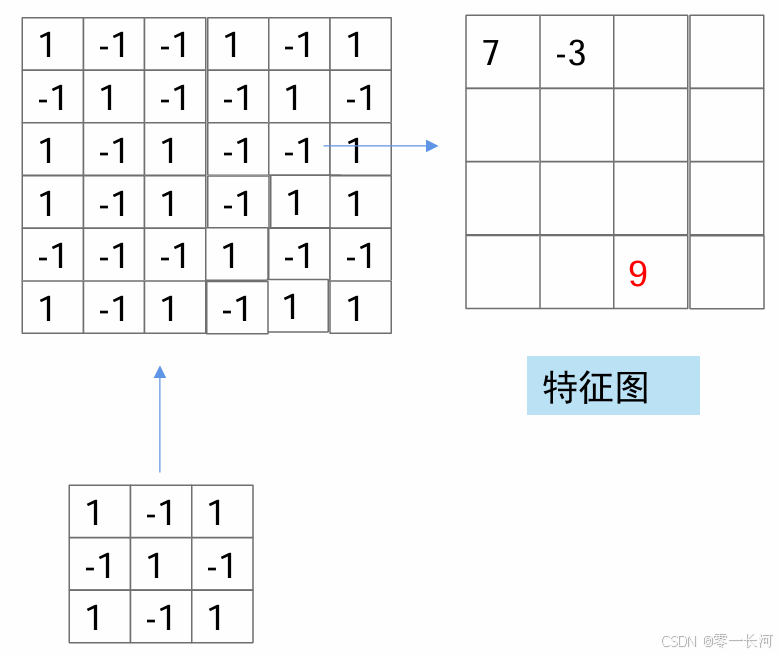
将其转为数值来看就是这样,用1表示红色,-1表示黑色,小矩阵作为卷积核,用卷积核对大的特征图处理了以后可以得到后面的4×4的特征图,其中只标出了几个点位的数据,可以对比带颜色的那个图来看,可以发现,得到数值越高的地方和和卷积核的相似度越高,比如7那个位置,在原图上只差了右上角的红色方块,而9那个位置和卷积核一摸一样,-3那个位置和卷积核差别很大,因此数值也小。
所以就可以用要找的图片的其中一些特征作为卷积核来处理图片,可以用鸟嘴也可以用鸟爪子那样的作为卷积核对特征图进行处理。所以我们的参数w就变成了这些卷积核。而不是之前普通的全连接那样巨多的参数。此外每个卷积核还有一个偏执值b。 卷积核就是卷积神经网络中的神经元
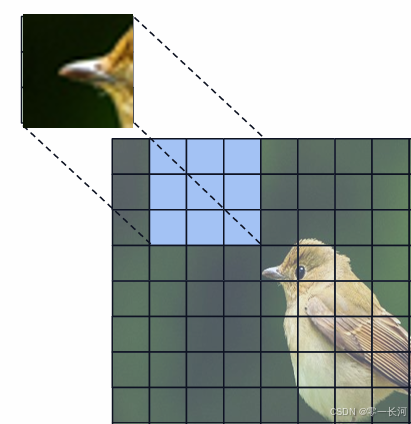
这样卷完以后得到鸟的特征数值最大就可以判断是一个鸟。
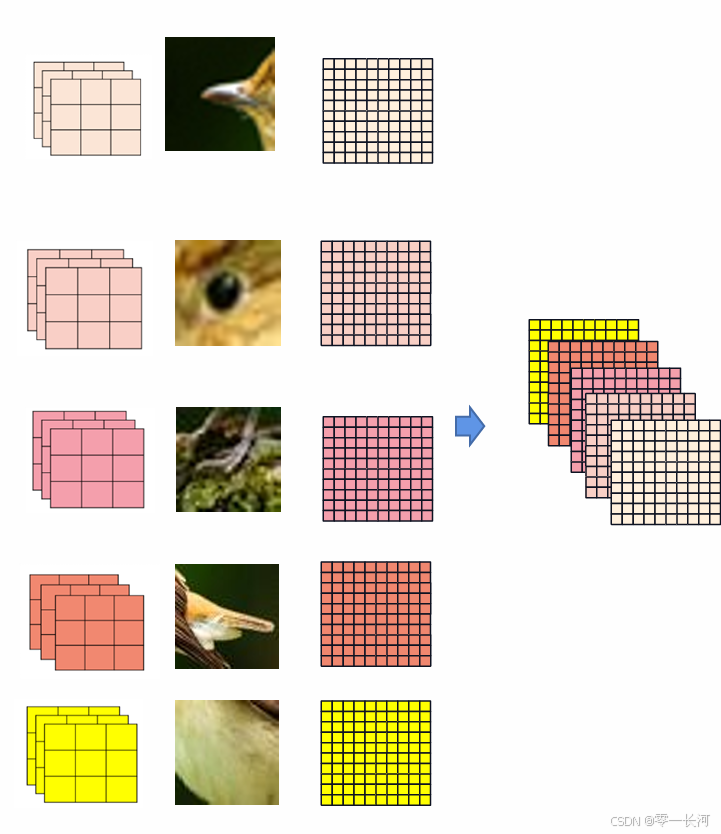
因为可以用很多卷积核去卷积,会得到多个结果,将这些结果组合以后会得到一个新的特征图,这个特征图有很多通道数,这样多次卷积的特征图,已经不是人能看得懂的图片了。得到的这样一个特征图要怎么继续处理呢,我们首先要增加卷积核通道数或者叫通道维度,原来是3通道的,现在就变成5通道的,也可以增大感受野,可以观察更大的特征。 卷积核的通道数也随着新特征图的数量而相应增多
通过卷积可以得知,特征图越卷越小,若要卷完的的特征图大小不变,可以在卷之前通过zeropadding补一圈0保持不变
计算参数量,得到特征图大小,这里用I表示原特征图的长/宽,O表示得到的特征图的长/宽,P表示几层padding,K表示卷积核的长/宽,我们有这样的一个公式:I-K+1+2P=O
该公式可以用于计算卷积后的特征图大小,若有m个卷积核进行卷积,则最后的特征图大小为MxOxO eg特征图大小3 * 4 * 4,padding1,卷积核大小3* 3* 3,七个卷积核,卷后的新特征图大小为7* 4* 4

卷积操作具有局部链接和权值共享

不管目标特征在图像上什么位置,用同一个卷积核去卷,得到的结果是一样的,这就叫平移不变性。权重共享便是同一个卷积核在图片上滑动卷积时共享其参数。

局部连接就是指每个神经元只连接输入数据的局部区域,而非全部输入。当前卷积核只和当前所卷的局部小区域连接,而非连接整个特征图。
2.3缩小特征图
但特征图如果一直依赖padding保持大小不变,无论怎么卷最后展平后都需要大量参数,所以要缩小特征图。
现在知道了怎么进行基本的卷积,那怎么由一张图片转化成它要输出的类别呢,这首先需要能够有效的缩小特征图的大小。
缩小特征图的大小一般叫做降采样,主要有两种方法:
1是扩大步长,就是每次不论是卷积核横着移动还是从一行到下一行都跳一格进行。
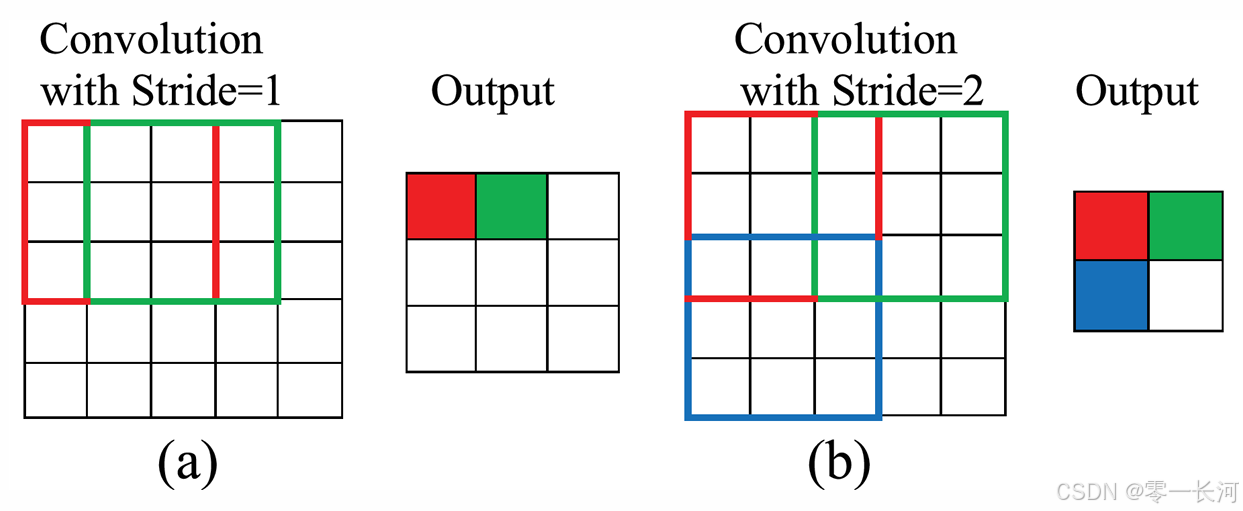
a图是步长为1,b是步长为2。S表示步长,这样的公式就变成了
不过直接只使用这种方法难以提取到图片准确的特征,可能会丢失掉一些重要的信息,因此一般不用。
2是池化(pooling)
池化分为最大池化(Max Pooling)和平均池化(Average Pooling)
最大池化,比如下图
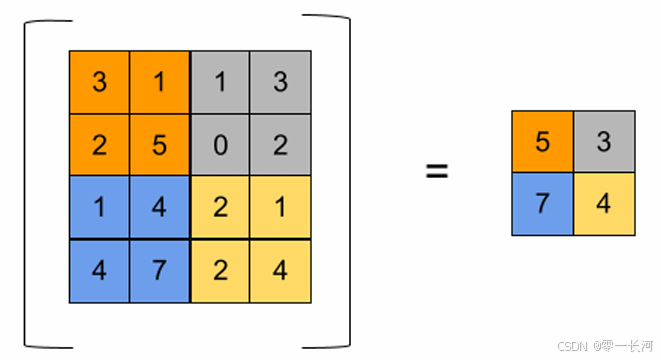
可以用nn.MaxPool2d(2, stride=2)表示,2表示对每个2×2的区域(池化窗口)进行池化操作stride表示步长,就是下次进行池化就走两格再进行**。可以看出来这个池化操作就是对每一个区域取其最大的数字,就是最显著的特征。**
降采样后的特征图大小计算:(I-K+2P)/S=O,S为步长
平均池化,如下图
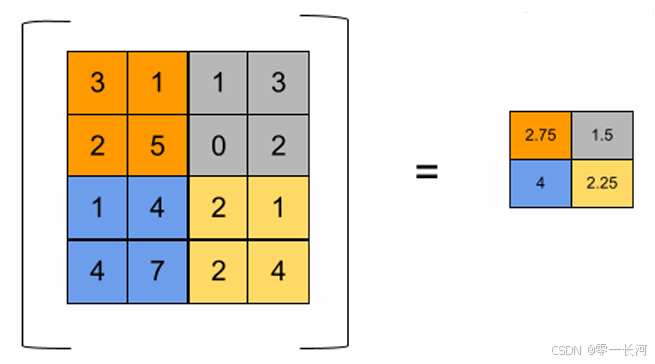
平均就是取每一块平均值,但平均池化计算麻烦,还可能不能提取最关键的特征。
因此我们一般选用最大池化。池化的作用就是缩小特征图,减少参数量,提取主要特征,增加卷积核的感受野。
2.4类别划分
前面一直在卷积,那么怎么才能分出来几个类别呢?
在不断的卷积和池化后,特征图的维度在增加,但大小会变得比较小了,于是我们就可以把整个特征图展开拉直变成一条向量,然后进行一个标准的全连接网络,经过多个隐藏层以后,最后要输出几个类别,就把最后一层的神经元结点个数设置成多少。
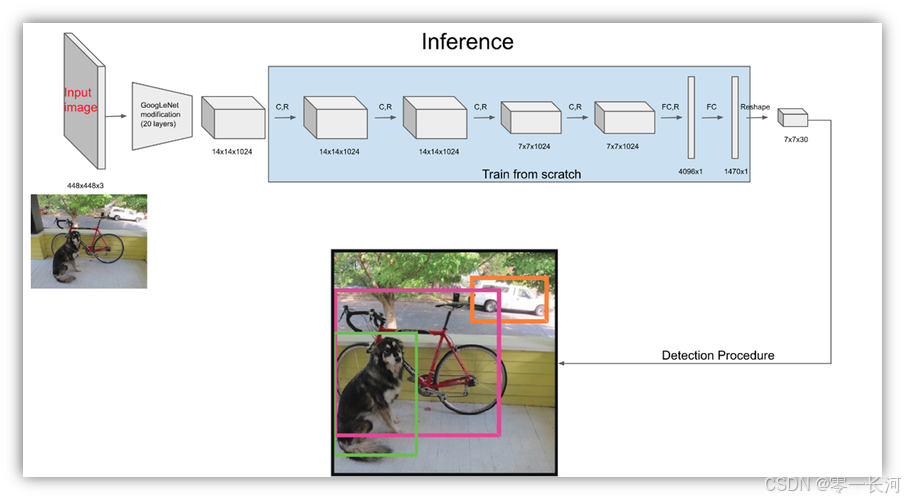
这就是一个卷积到全连接网络的过程,如果大致了解过YOLO的话,YOLOv1也是类似的结构
2.5其他内容
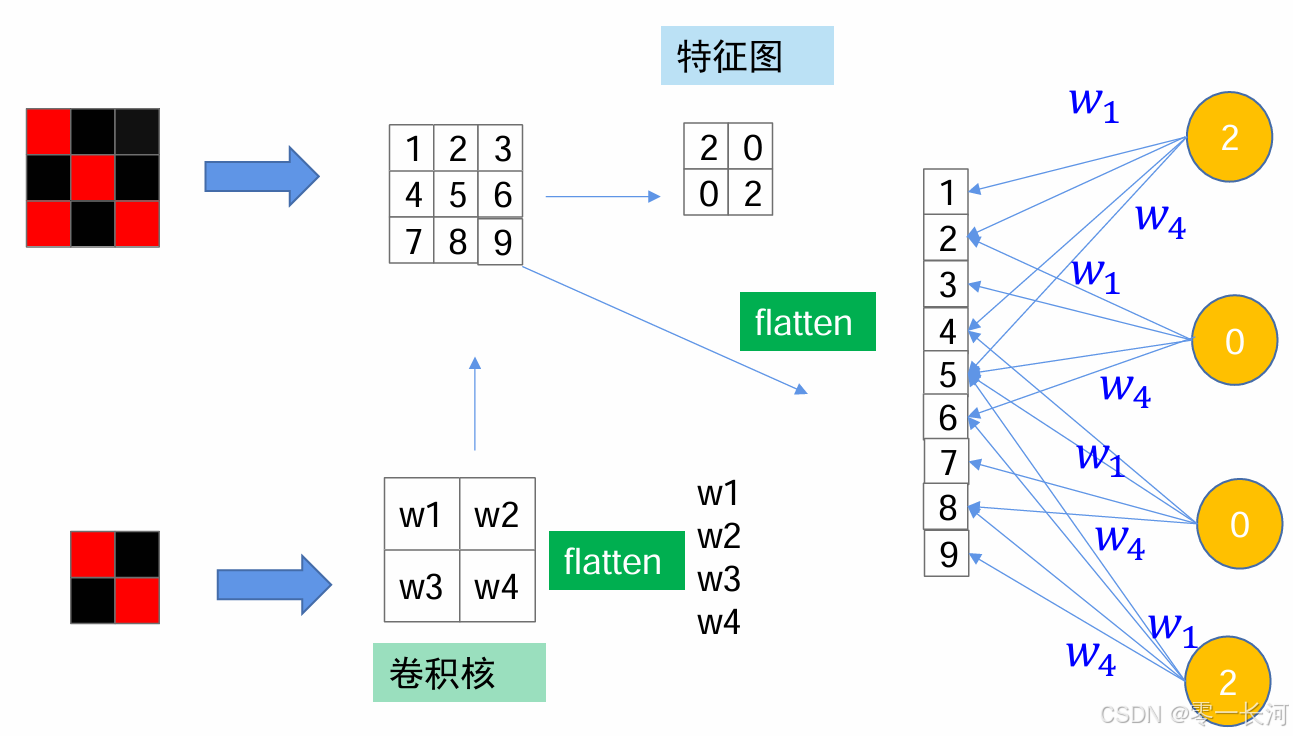
还可以这样来理解卷积,卷积核是要训练得到的参数,特征图是数值是确定的,那么可以将它们都展开,这样卷积前后的两个特征图就是靠卷积核的参数相关联,这些关联参数都是共用卷积核的,所以也可以理解为这样一种参数共享的不全连接。
3,损失计算
softmax的作用,以及交叉熵损失函数的意义
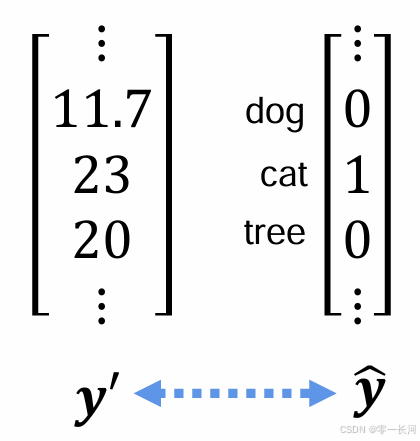
最后FC输出的可能是这样一个结果y’,而真值是一个独热编码,cat1可以理解为猫的概率为1 ,因此我们要把y’转化为一个概率的形式,就要用到一个叫做softmax的函数
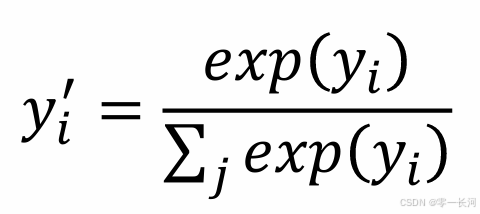
yi’是求得的其中一个类型的概率,这个函数就是对于y’的每一个值,分子上求指数,分母是对y’所有的元素分别求指数,然后对它们求和,这样的结果是当y’某个元素值特别小时,由于经过指数以后会将差距放大很多倍(这就是softmax取指数的意义),于是那个元素基本就可以趋近为0,越大的元素会越趋近为1.
softmax负责将预测出的多个实数转换为概率分布后才能求loss。且该概率应为(0,1)间的数值。
这样就可以和真值进行比较了。比较我们需要使用交叉熵,这个涉及信息熵的相关知识可以看
在代码可以直接调用 nn.CrossEntropyLoss().需要提供给交叉熵损失函数的参数是预测的分布,以及真实值的下标
这个上面是一个基本的loss计算公式
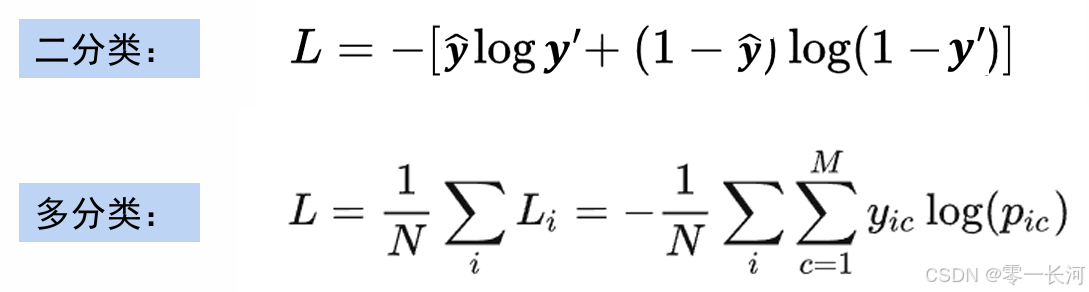

这个是一个简单的例子,对于一个三分类的任务,预测正确和预测错误的loss是什么样,以及它们的总loss,这里求完loss以后就可以反向的对全连接的参数以及进一步对卷积核的参数进行反向链式求导得到梯度,并对参数进行更新。
交叉熵是信息论中的一个概念,原本用于衡量两个概率分布之间的差异。在机器学习的分类任务里,交叉熵损失函数用于衡量模型预测的概率分布与真实标签的概率分布之间的差异程度。模型训练的目标就是最小化这个差异,使得模型的预测结果尽可能接近真实标签。
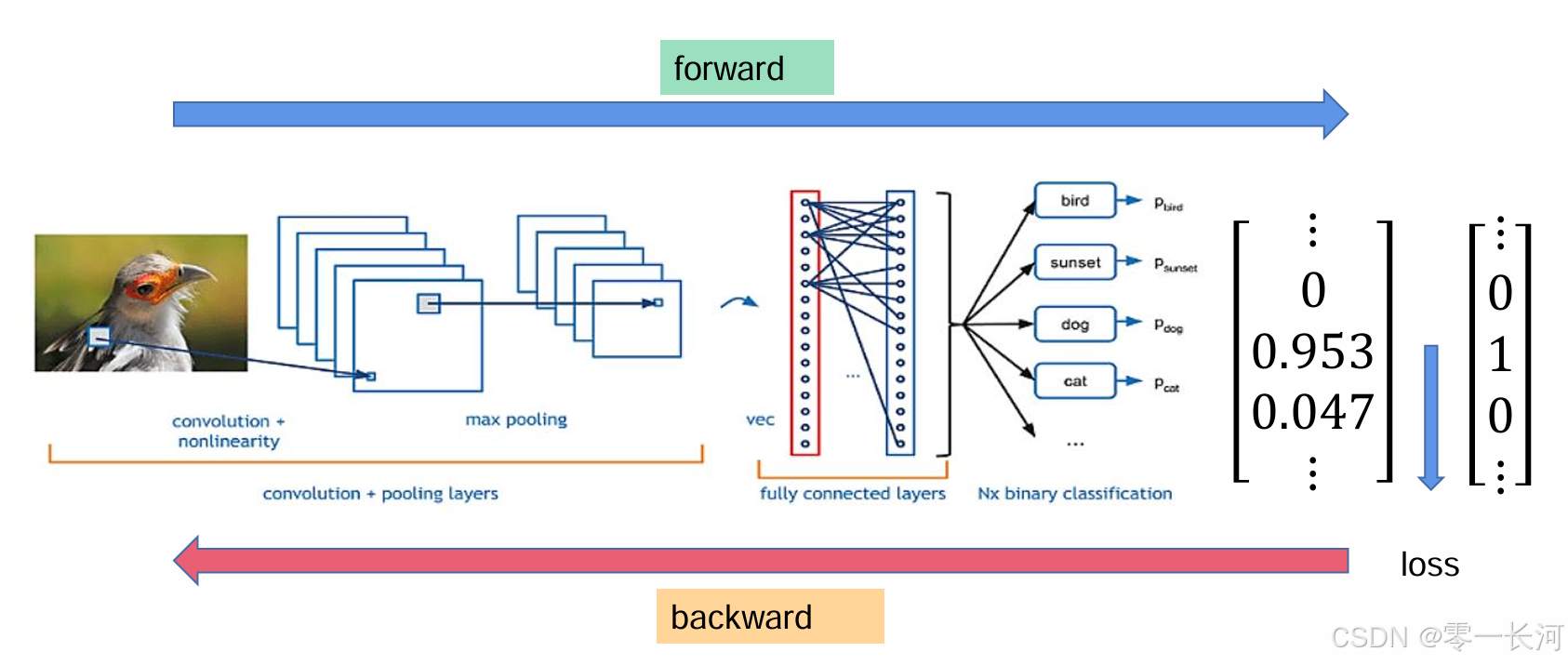
输入一张图片,用卷积核卷卷卷,卷的同时还要pooling 缩小特征图,卷到一定程度,拉直全连接进行预测分类,经过softmax后得到概率分布,然后计算交叉熵损失,梯度回传进行更新卷积核(因为卷积核就是参数)
这就是一个最基本的图片分类训练网络了
4,经典神经网络
当前的图像识别网络发展还是很迅速的,以至于有的研究者说他们的模型准确率已经超越人类,而实际上,很多机构使用的是Top5准确率,也就是为每张图像预测选取前5个最可能的类别。接下来,我们检查这前5个类别中是否包含了每张图像的真实类别。如果包含了,我们就认为这次预测是成功的。最后,我们计算成功的预测次数占总预测次数的比例,这个比例就是Top5准确率。而很多实际应用中,比如智能驾驶中,top5明显是不足的,这时候可能就需要top1的判断,对就是对错就是错。
当然不否认很多网络对于特征的提取很好,能有效识别物体的特征,在图片状态不好甚至被遮挡的情况下也能识别正确。
4.1AlexNet
它使用了relu,drop out, pooling和归一化等技术。drop out可以缓解过拟合,就是在一个全连接的网络中,每次训练不使用所有的神经元,只使用一部分,避免了网络过于依赖某些特定的神经元结点。归一化可以让模型关注数据的分布,而不受数据量纲的影响。 归一化可以保持学习有效性, 缓解梯度消失和梯度爆炸。
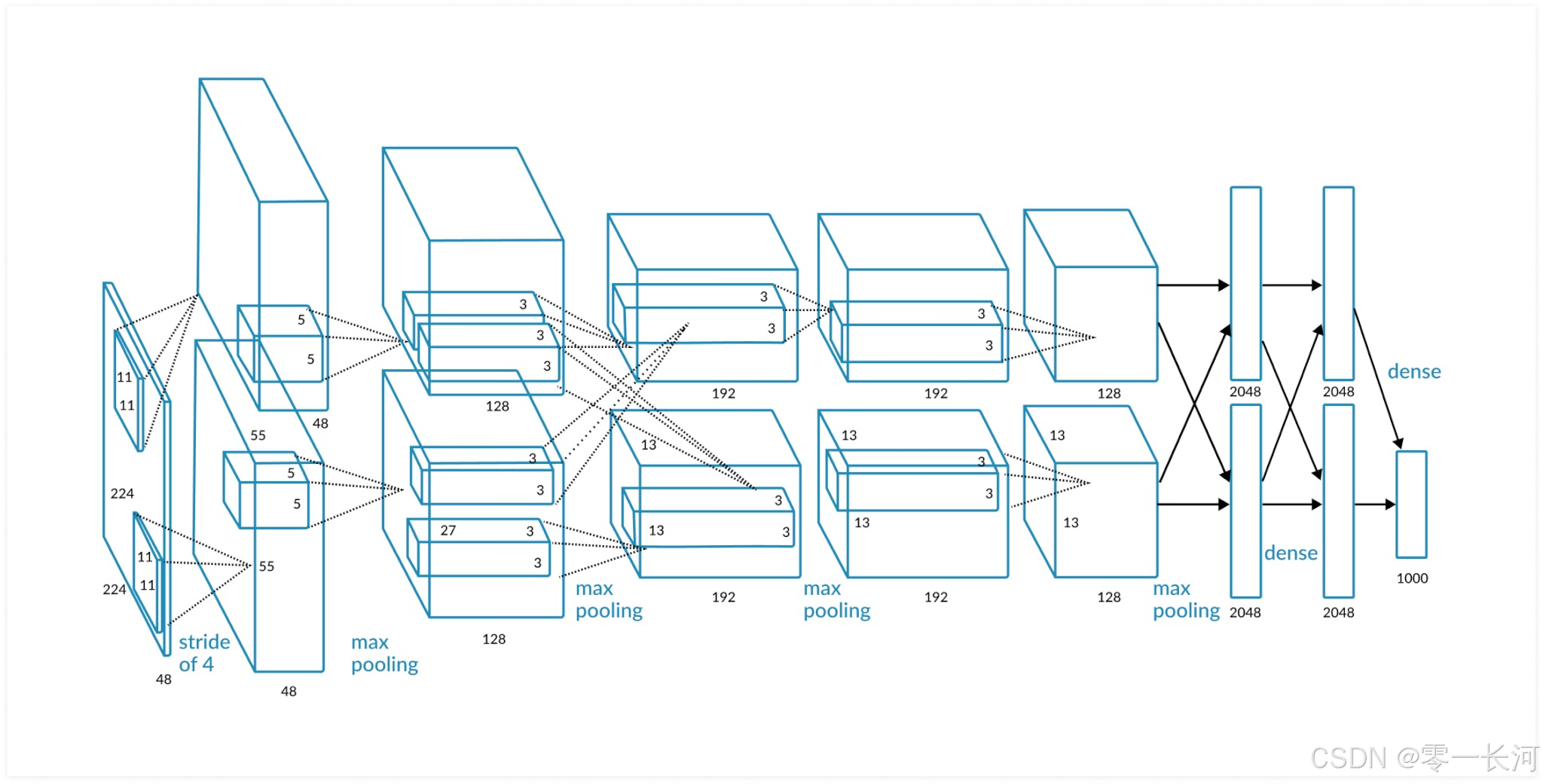
上图是AlexNet的网络架构
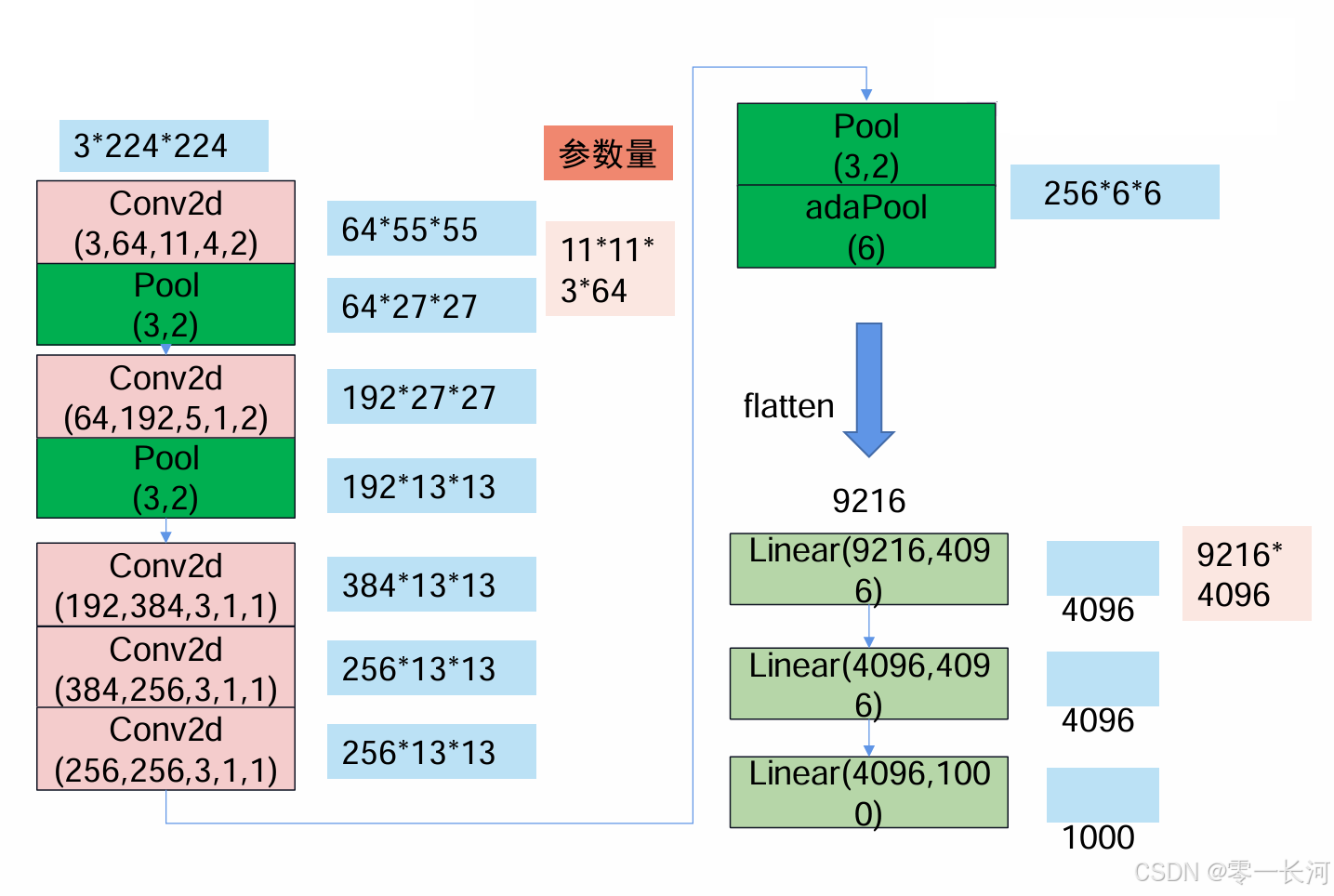
来计算一下这个张量大小变换
首先输入特征图大小是3×224×224,经过第一层conv2d表示一个二维卷积,
其中的3表示通道数,我们输入图片是RGB3通道的,卷积核也要3通道
64表示有64个卷积核,生成的特征图有64个通道,
11表示卷积核的大小,卷积核每个通道都是11×11的,
4表示步长,每次移动四个进行一次卷积,
2表示padding,表示加两圈0.
由计算(224-11+4)/4+1=55.25舍去小数,就是55,通道数是64.
就得到了一个64×55×55的特征图
然后是pooling池化,3表示池化窗口为3×3,2表示步长,每次移动两个格,55/2=27.5,就是27,0.5是不够3×3不能做池化。
后面的卷积和池化也一样,大家可以自己算一下。
adapool是二维自适应平均池化(Adaptive Average Pooling),参数6表示输出特征图的目标大小,这里是6x6。无论输入特征图的大小如何,自适应平均池化层都会将其下采样到6x6的大小。
flatten就是将特征图扁平化拉直,然后经过全连接输出1000个类别。
import torchvision.models as models
model = models.alexnet()
print(model)
我们可以使用这几句代码打印一下alexnet的网络架构
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
就是这样,和上面说的内容差不多。
import torch.nn as nn
class MyAlexNet(nn.Module):
def __init__(self, outdim=1000):
super(MyAlexNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 11, 4, 2)
self.pool1 = nn.MaxPool2d(3, 2)
self.conv2 = nn.Conv2d(64, 192, 5, 1, 2)
self.pool2 = nn.MaxPool2d(3, 2)
self.conv3 = nn.Conv2d(192, 384, 3, 1, 1)
self.conv4 = nn.Conv2d(384, 256, 3, 1, 1)
self.conv5 = nn.Conv2d(256, 256, 3, 1, 1)
self.pool3 = nn.MaxPool2d(3, 2)
self.adaPool = nn.AdaptiveAvgPool2d(6)
self.fc1 = nn.Linear(9216, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, outdim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.relu(x)
x = self.conv5(x)
x = self.relu(x)
x = self.pool3(x)
x = self.adaPool(x) # batch*256*6*6 维度
x = x.view(x.size()[0], -1) # x.size表示维度,[0]取batch,保持batch这维不变的,-1表示256*6*6全放在第二维上
# 变成16×9216,如果batch=16
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
这里手动写一下AlexNet的基本结构,和原版那个有点差别,只是一个框架,init方法里面定义网络每层结构,forward里面传入数据执行
model = MyAlexNet(1000)
data = torch.ones((4, 3, 224, 224)) # 四个样本,每个样本3*224*224
pred = model(data)
实例化,随便定义一个数据,调试跑一下可以看数据在每一层之间怎么变换的。
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
这个函数可以看整个网络多少参数
print(get_parameter_number(model))
print(get_parameter_number(model.conv1)) # 3*11*11*64+64=23296
打印整个模型参数,还可以打印一层的看,对于第一层来说,卷积核是3×11×11,共64个,每个有一个偏执值就得到这一层的参数量。
4.2VGGNet
2014年,VGG网络被提出,其在AlexNet的基础上,运用了更小的卷积核,并且加深了网络, 达到了更好的效果。VGG的网络更深更复杂,并使用了小的卷积核代替了大的卷积核。相比Alexnet减少了参数量
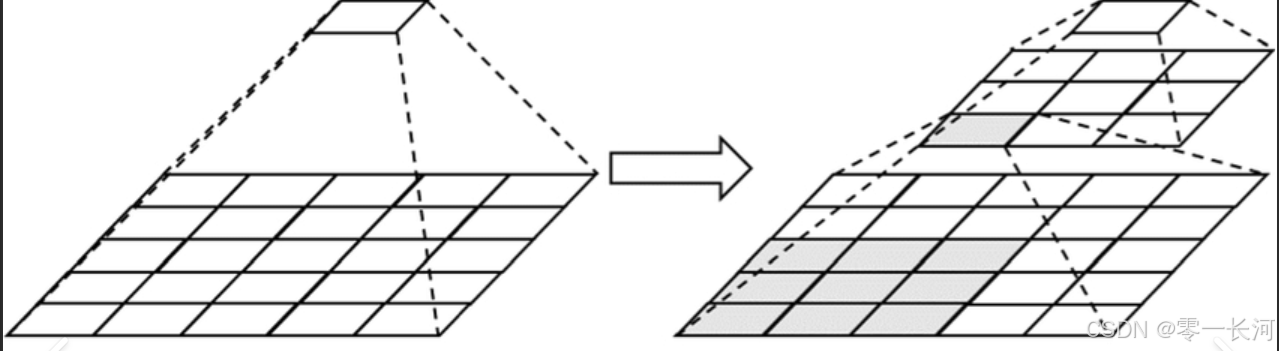
由图可见,用两个3×3的卷积核就可以代替5×5的卷积核,感受野也一样,但是参数由25个变成了18个,减少了参数,降低了过拟合的风险。
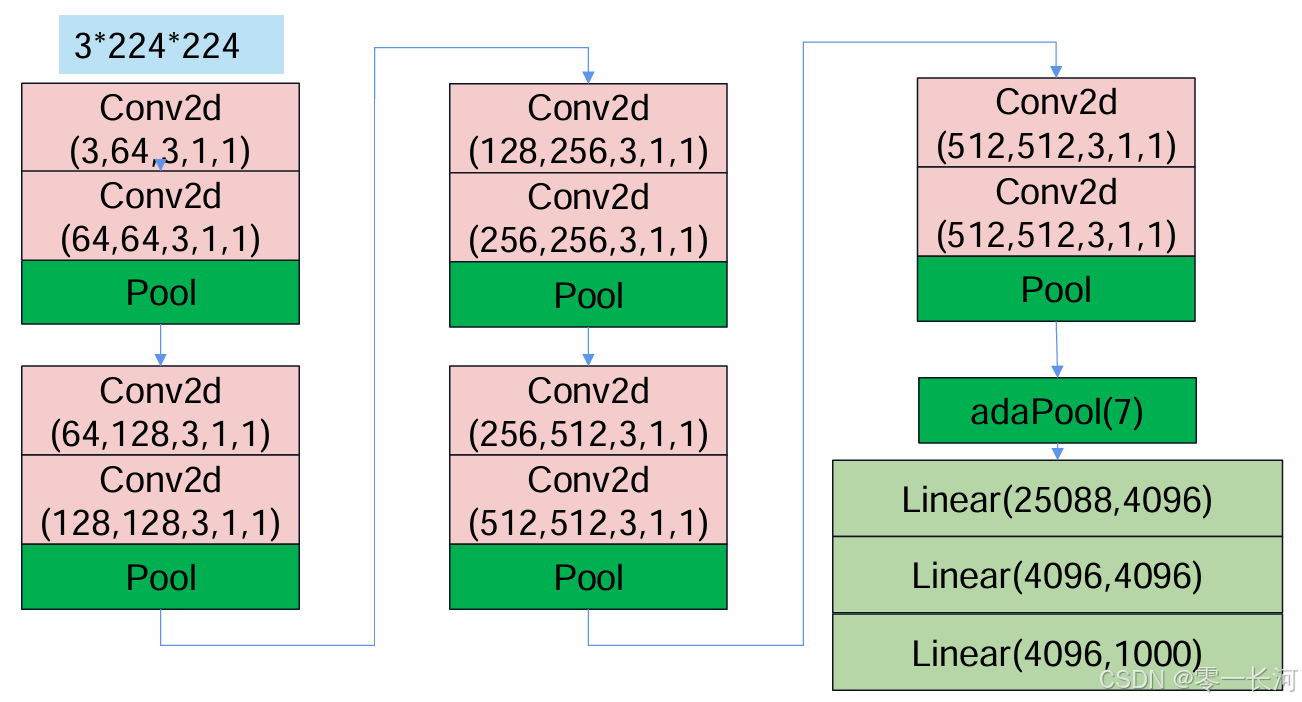
这是VGGNet的基本框架,下面简单计算一下每一层张量变化和参数量等。
输入3224224,第一层Conv得到特征图64224224,参数量为1792
第二层Conv得到特征图64224224,参数量为36,928
pool(2),步长默认为kernel_size,得到特征图64112112
conv得到特征图128112112,参数量为73,856
conv得到特征图128112112,参数量为147,584
pool得到特征图1285656
conv得到特征图2565656,参数量为295,168
conv得到特征图2565656,参数量为590,080
pool得到特征图2562828
conv得到特征图5122828,参数量为1,180,160
conv得到特征图5122828,参数量为2,359,808
pool得到特征图5121414
conv得到特征图5121414,参数量为2,359,808
conv得到特征图5121414,参数量为2,359,808
pool得到特征图51277
adapool得到51277
展开得到25088个值经过全连接最后得到1000个类别
import torch
import torch.nn as nn
class vgg_layer(nn.Module):
def __init__(self, in_dim, out_dim):
super(vgg_layer, self).__init__()
self.conv1 = nn.Conv2d(in_dim, out_dim, 3, 1, 1)
self.conv2 = nn.Conv2d(out_dim, out_dim, 3, 1, 1)
self.pool = nn.MaxPool2d(2)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
return x
class my_vgg_net(nn.Module):
def __init__(self):
super(my_vgg_net, self).__init__()
self.layer1 = vgg_layer(3, 64) # 调用这个就是直接调用init
self.layer2 = vgg_layer(64, 128)
self.layer3 = vgg_layer(128, 256)
self.layer4 = vgg_layer(256, 512)
self.layer5 = vgg_layer(512, 512)
self.ada_pool = nn.AdaptiveAvgPool2d(7)
self.linear1 = nn.Linear(25088, 4096)
self.linear2 = nn.Linear(4096, 4096)
self.linear3 = nn.Linear(4096, 1000)
self.relu = nn.ReLU()
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.ada_pool(x)
x = x.view(x.size()[0], -1)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.relu(x)
x = self.linear3(x)
x = self.relu(x)
return x
model = my_vgg_net()
data = torch.ones((1, 3, 224, 224))
pred = model(data)
print(pred.size())
调试此代码,就可以看特征图大小怎么变化的.
网络这样写是因为VGG那些卷积层都是类似的结构,因此先定义一个vgg层的类,然后在定义网络的类上传入参数调用vgg层的类,可以避免写的很繁琐。执行myvggnet这个类的前向forward时,就会在vgglayer这个类上调用前向forward方法。
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
# print(get_parameter_number(model))
for i in range(1, 6):
layer_name = f"layer{i}"
layer = getattr(model, layer_name)
print(layer_name)
print(get_parameter_number(layer.conv1))
print(get_parameter_number(layer.conv2))
再加上这个代码,可以打印每层的卷积层参数,和上面计算结果对比一样。
4.3ResNet
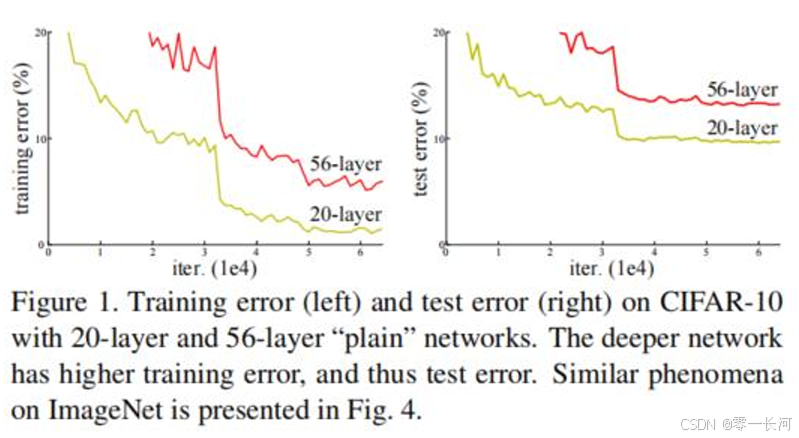
这个残差网络主要是想改变这样一个问题,就是网络层数越多,训练和测试的错误越多。
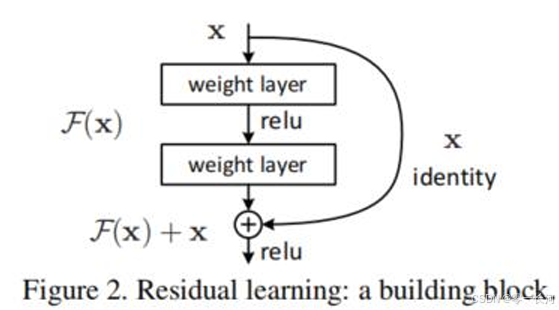
残差网络将输入特征图数据x加到了输出的F(x)上,可以一定程度上解决梯度消失的问题,
在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫做消失的梯度问题。(百度百科)
梯度消失的原因主要有以下几点:(AI)
激活函数的选择:某些激活函数(如sigmoid、tanh)在输入较大或较小的情况下,梯度会非常接近于零,从而导致梯度消失。这是因为这些激活函数的导数在输入值远离零时趋近于零。
权重初始化:如果网络的权重初始化过大或过小,也可能导致梯度消失问题。权重初始化不当会影响前向传播过程中信号的传递,进而影响梯度在反向传播过程中的计算。
深层网络结构:深层网络中,梯度需要通过多个层传播,每一层都会引入一定的误差。这些误差会累积并导致梯度消失。特别是当网络层数非常多时,梯度消失的风险会大大增加。
基本上就是当求梯度求导数的链式求导连乘在一起时,每一部分如果数值都比较小,乘一起就更小,越往前的层得到的梯度数值越小,就会导致模型的越前面的参数越难以得到有效的更新。
而残差网络引入x以后,x的梯度是1,可以将梯度传入前面的层更新参数。另外relu函数也会比sigmoid函数更容易更新梯度,sigmoid的自变量数值越大梯度越小,也会导致梯度消失等问题。
还有的解释是残差网络通过搭建这样的桥梁,跳过那些训练效果不好的层,让网络基本只走那些训练比较好的层。
如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
- 全0填充;
- 采用1*1卷积。
维度相同才能相加,实现残差链接
1 * 1卷积核可以在输入和输出特征图大小不变的情况下,改变其通道数。最终特征图的通道数是增加还是减少取决于1 * 1卷积核的数量。比如3 * 9 * 9的特征图经过一个1 * 1 的卷积核得到一个1 * 9 * 9的特征图,如果是两个卷积核则得到2 * 9 * 9的特征图,以此类推。
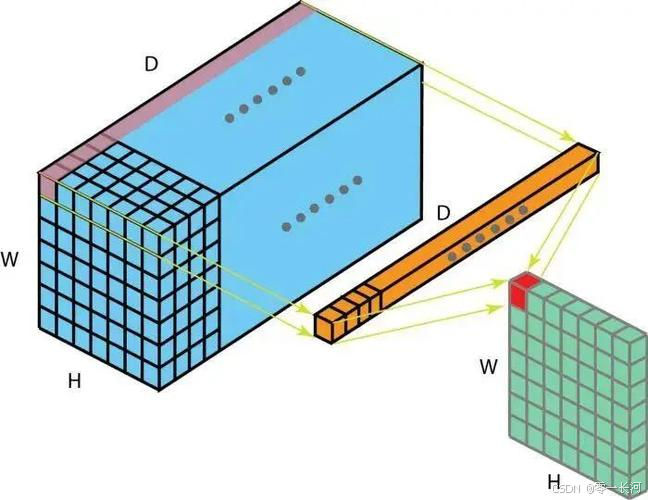
ResNet还使用了1 * 1的卷积,1 * 1的卷积可以减少参数,还可以在残差模块输入不等于输出的时候用1 * 1卷积让它们强行匹配。(用128个卷积核,每走两步去卷一次)
1*1卷积的作用:



Resnet18:
18主要指的是带有权重的,包括卷积层和全连接层,不包括池化层和BN层。(BN层是有参数的)
ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
(注意每个残差块的使用,第一次是通道数的变化,所以加入一层卷积层,第二次通道数不变化,所以不要用到卷积层,直接将输入加到输出)
所以resnet的残差块有两部分组成,一部分卷积层,另一部分不参与卷积而是实现残差链接
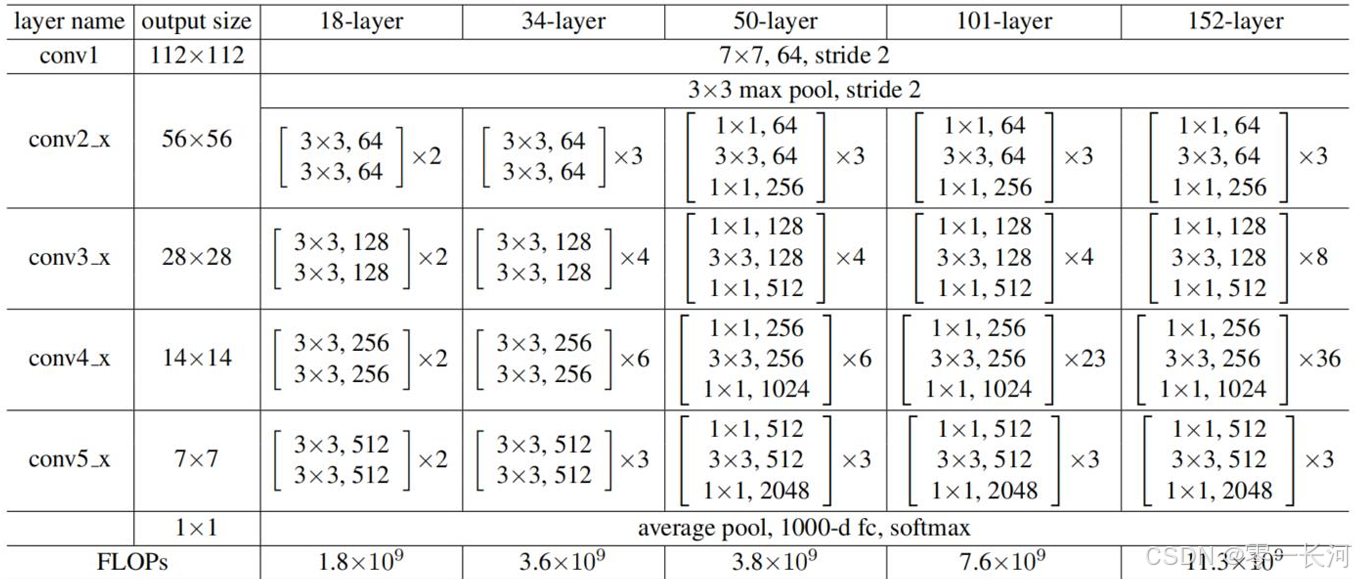
ResNet的有好几个不同层数的版本,下面写一下最简单的18层代码
class Res_block(nn.Module):
def __init__(self, in_dim, out_dim, strides):
super(Res_block, self).__init__()
self.conv1 = nn.Conv2d(in_dim, out_dim, 3, stride=strides, padding=1)
self.conv2 = nn.Conv2d(out_dim, out_dim, 3, stride=1, padding=1)
self.relu = nn.ReLU()
self.batchNorm = nn.BatchNorm2d(out_dim)
if in_dim != out_dim:
self.conv = nn.Conv2d(in_dim, out_dim, 1, stride=strides)
else:
self.conv = None
def forward(self, x):
out = self.relu(self.batchNorm(self.conv1(x)))
out = self.batchNorm(self.conv2(out))
if self.conv:
x = self.conv(x)
out += x
return out
先定义残差模块,可以打印models.resnet18()来看网络结构,每个模块需要定义两个卷积层,relu和批归一化,如果输入层不等于输出的维度,需要添加一个1*1的卷积层
forward方法就按照官方给的结构来写就行,最后让输入层加到输出层上
class My_Res_Net(nn.Module):
def __init__(self):
super(My_Res_Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(3)
self.ada_pool = nn.AdaptiveAvgPool2d(1)
self.layer1 = nn.Sequential(
Res_block(64, 64, 1),
Res_block(64, 64, 1)
)
self.layer2 = nn.Sequential(
Res_block(64, 128, 2),
Res_block(128, 128, 1)
)
self.layer3 = nn.Sequential(
Res_block(128, 256, 2),
Res_block(256, 256, 1)
)
self.layer4 = nn.Sequential(
Res_block(256, 512, 2),
Res_block(512, 512, 1)
)
self.flatten = nn.Flatten()
self.linear = nn.Linear(512, 1000)
按照官方的给的层描述定义需要的结构,开始的几个层,中间的4个layer和结尾的一些内容
Sequential是一个容器,里面的内容可以顺序执行,写这样一个容器可以在写forward方法时简便一些,直接调用layer即可。
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.ada_pool(x)
x = self.flatten(x)
x = self.linear(x)
return x
forward层正常写就行。结构参考官方给的网络。
x = torch.rand((1, 3, 224, 224))
model_of = models.resnet18()
out_of = model_of(x)
# print(model_of)
print(out_of.shape)
model_my = My_Res_Net()
out_my = model_my(x)
print(out_my.shape)
传入x,调试看网络的数据变换。
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
print(get_parameter_number(model_my.conv1))
print(get_parameter_number(model_my.bn1))
for i in range(1, 5):
layer_name = f"layer{i}"
layer = getattr(model_my, layer_name)
print(layer_name)
for j in range(2):
print("Res_block.conv1", get_parameter_number(layer[j].conv1))
print("Res_block.conv2", get_parameter_number(layer[j].conv2))
打印参数量

















 3541
3541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









