






监督学习,无监督学习:
监督学习是机器学习的类型,其中机器使用“标记好”的训练数据进行训练,并基于该数据,机器预测输出。标记的数据意味着一些输入数据已经用正确的输出标记。
在监督学习中,提供给机器的训练数据充当监督者,教导机器正确预测输出。它应用了与学生在老师的监督下学习相同的概念。
监督学习是向机器学习模型提供输入数据和正确输出数据的过程。监督学习算法的目的是找到一个映射函数来映射输入变量(x)和输出变量(y)。
在现实世界中,监督学习可用于风险评估、图像分类、欺诈检测、垃圾邮件过滤等。
缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习
分类和回归
不管是分类,还是回归,其本质是一样的,都是对输入做出预测,并且都是监督学习。说白了,就是根据特征,分析输入的内容,判断它的类别,或者预测其值。
a.分类问题输出的是物体所属的类别,回归问题输出的是物体的值
b.分类问题输出的值是离散的,回归问题输出的值是连续的
c.分类问题输出的值是定性的,回归问题输出的值是定量的
3.聚类和降维
聚类是按照某个特定标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。简言之,聚类是根据研究对象的特征值差异,将研究对象划分为多个不同的类别,从而实现将研究对象分层/分簇的目的。聚类方法可以分为划分聚类、层次聚类和密度聚类。
假设样本资料矩阵为n×k的矩阵(n个研究对象,k个特征),当k远大于n时,直接拟合模型会导致维度灾难、过拟合的问题,因此需要通过一定的方法减少特征数量,以克服维数灾难,获取本质特征,去除无用的噪声,减少冗余信息所造成的误差,提高识别的精度。降维方法可以分为线性降维方法和非线性降维方法,最常见的方法比如PCA、LDA等。
降维和聚类表面上而言都可以减少数量,但是减少对象不同。对于聚类而言,是依据不同样本特征值的差异,对样本进行聚类,将总体分为k组,实现总体分层,进而方便分层分析;而对于降维而言,降维是降低数据维度,即减少特征数量,以避免特征数量大于样本量而导致的高维灾难问题。所以我们可以理解为降维是降低特征数,聚类是将样本分为不同的类。
4.损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parametric estimation),在宏观经济学中被用于风险管理(risk management)和决策 ,在控制理论中被应用于最优控制理论(optimal control theory)
5.我们通常把训练的数据分为三个文件夹:训练集、测试集和验证集。
下面这个比喻非常恰当:模型的训练与学习,类似于老师教学生学知识的过程。
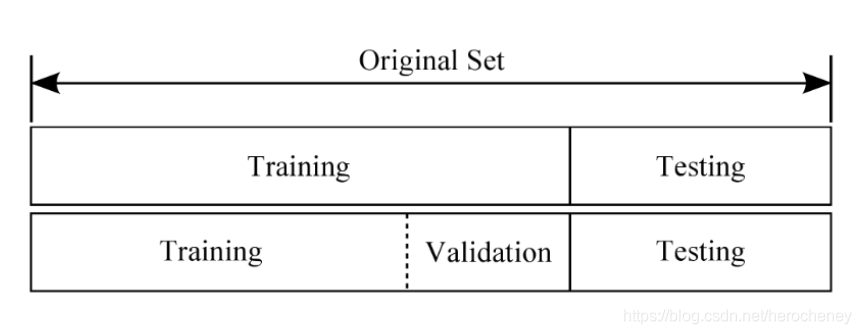
1、训练集(train set):用于训练模型以及确定参数。相当于老师教学生知识的过程。
2、验证集(validation set):用于确定网络结构以及调整模型的超参数。相当于月考等小测验,用于学生对学习的查漏补缺。
3、测试集(test set):用于检验模型的泛化能力。相当于大考,上战场一样,真正的去检验学生的学习效果。
参数(parameters)是指由模型通过学习得到的变量,如权重和偏置。
超参数(hyperparameters)是指根据经验进行设定的参数,如迭代次数,隐层的层数,每层神经元的个数,学习率等。
6.过拟合:是指我们在训练集上的误差较小,但在测试集上的误差较大;
欠拟合:在训练集上的效果就很差。
一、欠拟合
首先来说欠拟合,欠拟合主要是由于学习不足造成的,那么我们可以通过以下方法解决此问题
1、增加特征
增加新的特征,或者衍生特征(对特征进行变换,特征组合)
使用较复杂的模型,或者减少正则项
二、过拟合
1、样本问题
1)样本量太少:
样本量太少可能会使得我们选取的样本不具有代表性,从而将这些样本独有的性质当作一般性质来建模,就会导致模型在测试集上效果很差;
2)训练集、测试集分布不一致:
对于数据集的划分没有考虑业务场景,有可能造成我们的训练、测试样本的分布不同,就会出现在训练集上效果好,在测试集上效果差的现象;
3)样本噪声干扰大:
如果数据的声音较大,就会导致模型拟合这些噪声,增加了模型复杂度;
7.
经验风险与期望风险
经验风险来源于训练数据集,训练数据集的平均损失也称为经验风险。⽽期望风险则针对的是全体数据。也就是已有的数据,未有的数据都包括在内。我们往往希望的得到的模型不仅要对已有的数据有较好的预测效果,还更要对未知的的数据的预测有好的效果。
经验风险与期望风险有什么关系呢?我们往往希望得到的模型期望风险能够越⼩越好,也就是泛化能⼒越强越好。但是,期望风险我们不能直接得到。且我们可知当训练数据集很多,接近⽆穷时,经验风险就会⾮常接近期望风险。所以很多时候,我们希望如果能有⼤量的训练数据来训练模型,那么就可以得到泛化能⼒较好的模型。但有时训练数据不多,我们则会⽤别的⽅法尽量通过使经验误差较⼩的同时,也能有较好的泛化能⼒。⽐如,正则化、交叉验证等。














 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









