






Attention 机制
心理学角度看注意力机制
动物需要在复杂环境下有效关注值得关注的地方。
心理学框架:人类根据随着意识线索和不随意线索选择注意点。人们会有意识的关注想要的东西。有个例子:
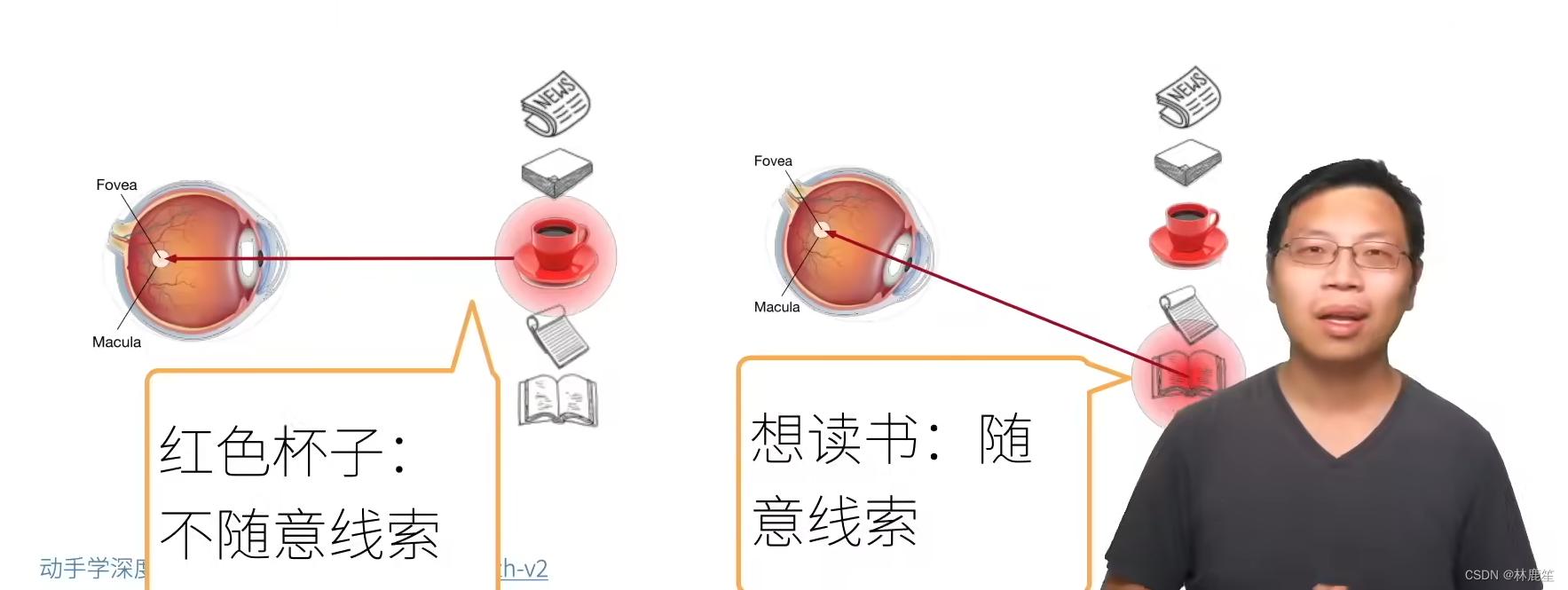
红色杯子就是不随意线索,书籍就是随意线索;随意线索和不随意线索中的随意指的就是随着自己的主观。 可以将随意理解为有目的的,不随意反之
注意力机制
键/值/查询的概念类似于检索系统。例如,搜索视频时,搜索引擎会将查询(搜索栏中的文本)映射到数据库中与候选视频相关的一组键(视频标题、描述等),然后向您显示最佳匹配的视频(值)。
卷积、全连接、池化层都只考虑随意线索。
卷积、全连接、池化是让数据原有的特点更加突出,能让这些特点被注意到,就说是不随意。
注意力机制则显式的考虑随意线索。
心理学的内容可以对应到注意力机制中来。
①随意线索被称之为查询query,每一个输入都是一个值value和不随意线索key的对。
随意线索被称为query,就是想要干嘛;环境就认为是key-value pair,key对应的就是值value,key和value可以一样也可以不一样
②通过注意力池化层来有偏向性的选择某些输入。
根据query,有根据的偏向选择某一些东西,也就是选择key-value pair
根普通的池化层不同的就是多了一个query查询。
什么是查询query、键key和值value
在注意力机制当中,将不随意线索称为非自主性提示,随意线索被称为自主性提示。
"是否包含自主性提示"将注意力机制与全连接层或汇聚层区别开来。 在注意力机制的背景下,自主性提示被称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。在注意力机制中,这些感官输入被称为值(value)。
非自主性提示被称为键(key)。更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。
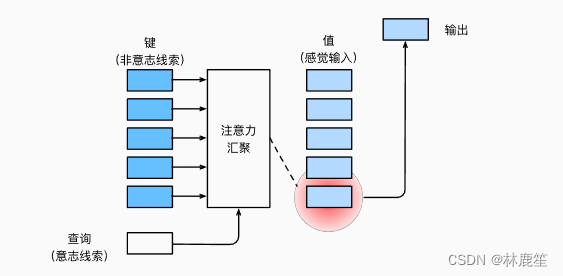
注意力机制通过注意力汇聚将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向
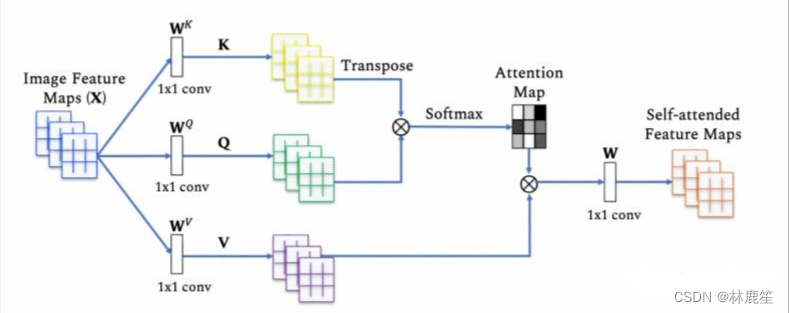
自注意力机制(Self-Attention)
自注意力机制又称内部注意力机制,前面提到的注意力机制可以知道,Attention机制与自身还有关注对象都有关系;而Self-Attention,指的是输入的source和输出的target之间发生的Attention机制,也可以理解为source=target这种特殊情况下的注意力计算机制。Self-Attention只关注输入本身或只关注对象本身。
Attention机制和Self-Attention的区别
注意力机制的查询Query和键Key是不同来源的,比如翻译模型,查询Q是输入内容,键K是翻译后的输出内容。而自注意力机制的查询和键都是来自于同一组的元素,比如编码器-译码器模型(Encoder-Decoder)查询和键都是Encoder中的元素,即查询和键都是中文特征,可以理解为同一句话中的词语或者同一张图像中不同的补丁,这都是一组元素内部相互做注意力机制。
总结:
①如果查询和键是同一组内的特征,并且相互做注意力机制,则称为自注意力机制或内部注意力机制。
②多头注意力机制的多头表示对每个Query和所有的Key-Value做多次注意力机制。做两次,就是两头,做三次,就是三头。这样做的意义在于获取每个Query和所有的Key-Value的不同的依赖关系。
Self-Attention-文字处理中单词向量编码的方式
①one-hot独热编码
②词向量编码:将词语映射/嵌入到另一个数值向量空间,可以通过距离来表征不同词语之间的相 关性。
拿词性标注举例,对一个句子来说每一个词向量对应一个标签;还考虑在句子不同位置,单词可能表示不同含义的问题。
The animal didn't cross the street because it was too tired .
这句话中的单词"it"指的是什么呢?它是指“street”还是“animal”呢?对于我们人来说,对一个算法来说,这并不简单。当模型正在处理单词“it”的时候,自注意力机制允许单词“it”结合单词“animal”一起处理。也就是说,在注意力机制中,模型可以结合上下文的单词来处理当前单词。从其它单词中找寻“线索”,可以帮助模型更好的编码当前单词。
Self-Attention如何实现
Self-Attention结构:
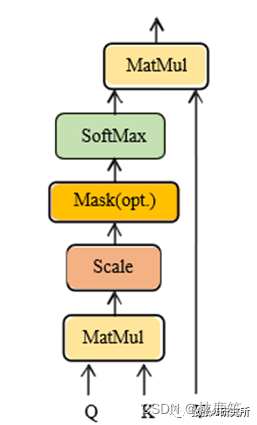
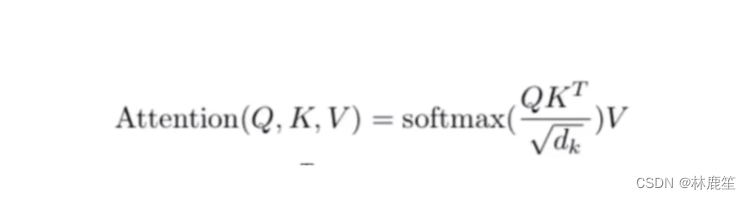 Q和K^T是矩阵的点乘运算,点乘的意义:点乘的结果是一个向量在另一个向量上投影的长度,它可以反映两个向量之间的相似度,也就是说,两个向量越相似,它的点乘结果也就越大。dk指的是每个头的维度,防止梯度消失。
Q和K^T是矩阵的点乘运算,点乘的意义:点乘的结果是一个向量在另一个向量上投影的长度,它可以反映两个向量之间的相似度,也就是说,两个向量越相似,它的点乘结果也就越大。dk指的是每个头的维度,防止梯度消失。
自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性,它的实现方法如下:
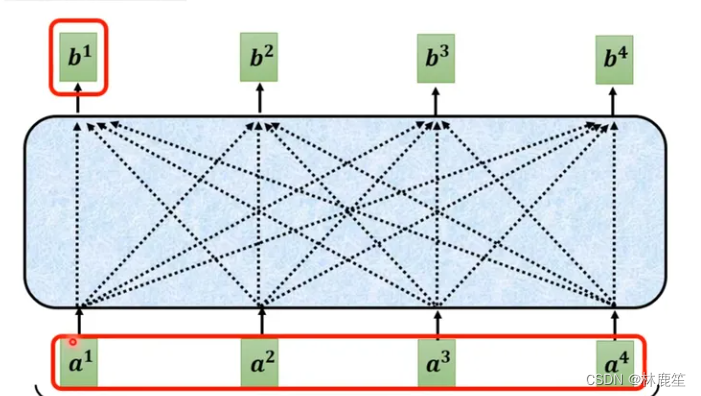
对于每一个输入向量a,在本例中也就是每一个词向量,经过self-attention之后都输出一个向量b,这个向量b是考虑了所有的输入向量才得到的,这里有四个词向量a对应就会输出四个向量b。
step1:
对于每一个向量a,分别乘上三个系数 𝑤𝑞, 𝑤𝑘,𝑤𝑣得到q,k,v三个值:得到的Q,K,V分别表示query,key和value。𝑤𝑞, 𝑤𝑘,𝑤𝑣是需要学习的参数。
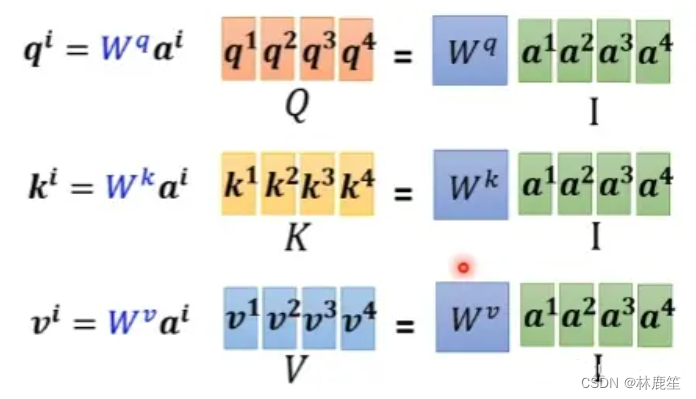
step2:
利用得到的Q和K计算每两个输入向量之间的相关性,也就是计算attention的值α,α的计算方法有多种,通常采用点乘的方式。
𝛼𝑖,𝑗=𝑞𝑖⋅𝑘𝑗 写成向量形式: 𝐴=𝐾𝑇⋅𝑄 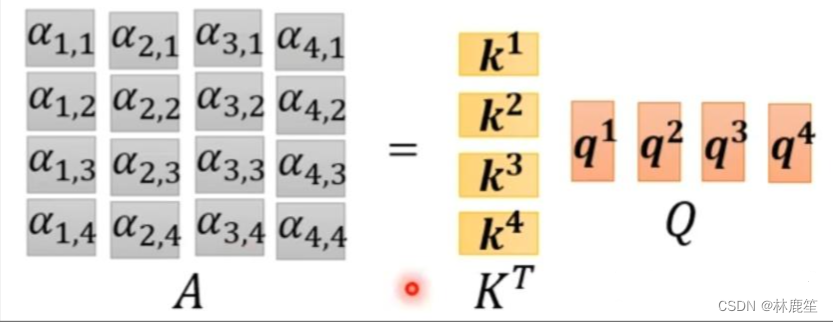
step3:对A矩阵进行softmax操作或者relu操作得到A'
step4:利用得到的A'和V计算每个输入向量a对应的self-attention层的输出向量b 𝑏𝑖=∑𝑗=1𝑛𝑣𝑖⋅𝛼𝑖,𝑗′,写成向量形式 𝑂=𝑉⋅𝐴′
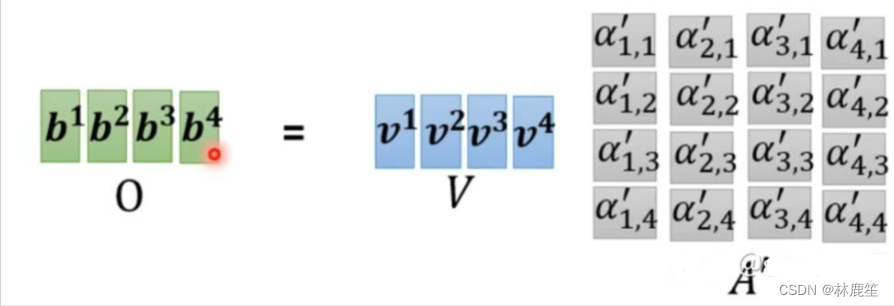
Self-Attention工作流程:
注意力汇聚
查询query(自主提示)和键key(非自主提示)之间的交互形成的注意力汇聚;注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出。
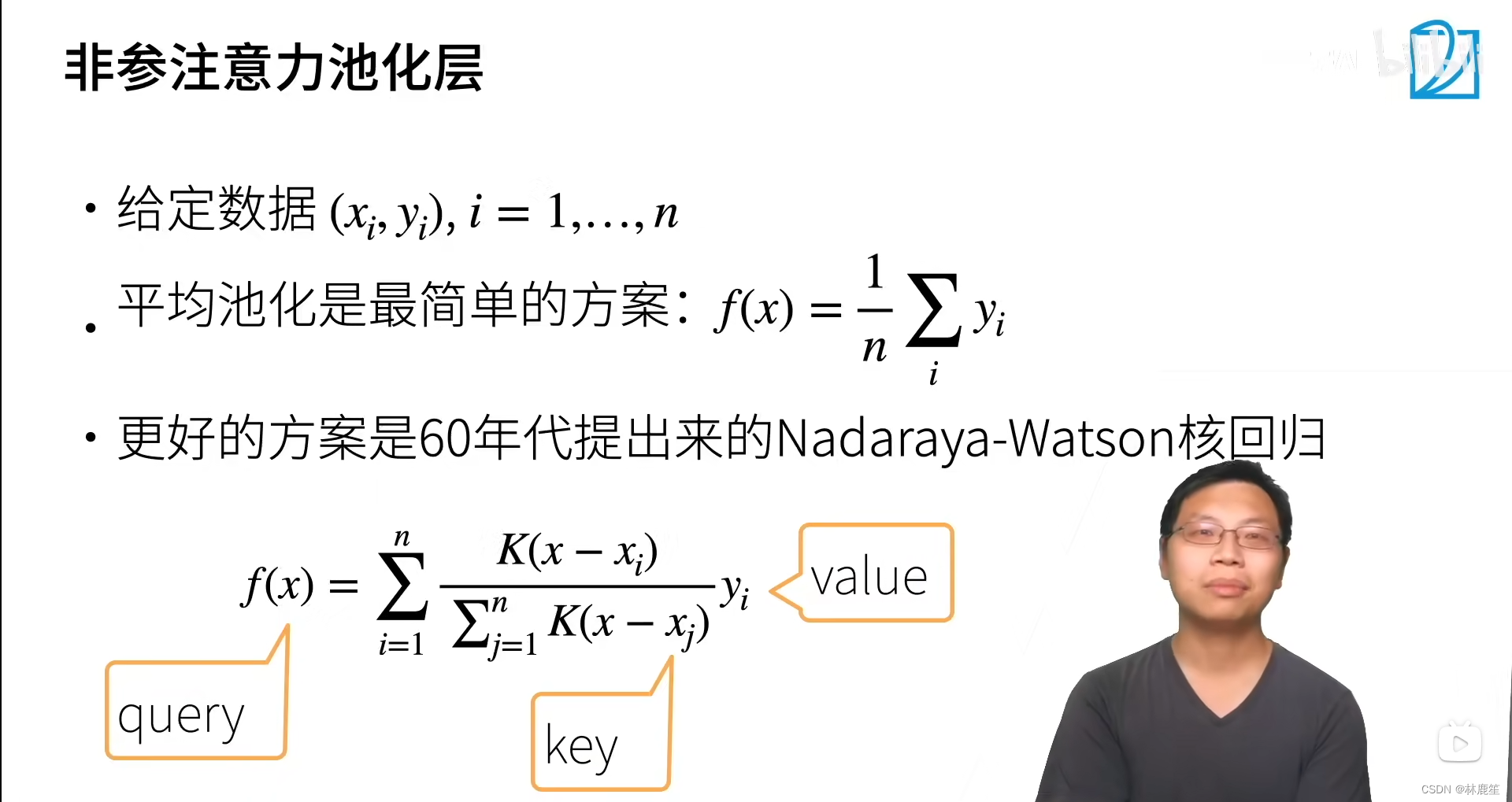
非参就是不需要学任何东西,(x_i,y_i)是key-value pair,f(x)中的x时query,是要查询的东西,其实query和key是一样的,K是一个衡量x到x_i距离的函数,再除以分母,就得到了每一个key的相对的重要性;这项加权对y_i求和,意思是将和x相近的x_i,y_i选出来,找出和query相近的key-value pair

这就是对K的选择了,u就是前面说的距离,带进去相当于做了一个softmax

w本质上是正态分布的标准差参数。


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









