






一、摘要
Differential Transformer(Diff Transformer)是由微软与清华大学联合提出,旨在通过差分注意力机制(Differential Attention)解决传统Transformer中存在的注意力噪声(Attention Noise)、长上下文建模困难及幻觉(Hallucination)问题。其核心思想是通过两组注意力权重的差值抵消共模噪声,从而提升模型对关键信息的捕捉能力。实验表明,Diff Transformer在语言建模、长文本理解、幻觉缓解等任务中显著优于传统Transformer,同时具备更高的参数效率和训练稳定性。
论文地址:https://arxiv.org/abs/2410.05258
(ps:**幻觉问题(Hallucination)**指的是模型生成的文本包含与输入无关(如自行添加原文中没有的信息)、不符合事实(如爱因斯坦发明了电话)或逻辑上自相矛盾的内容(如会议在周一举行后又改成在周三举行),尽管这些内容可能在语法和表面语义上是通顺的。这种现象在生成式任务(如文本生成、问答、摘要)中尤为突出。)
二、背景与动机
1、传统Transformer的局限性
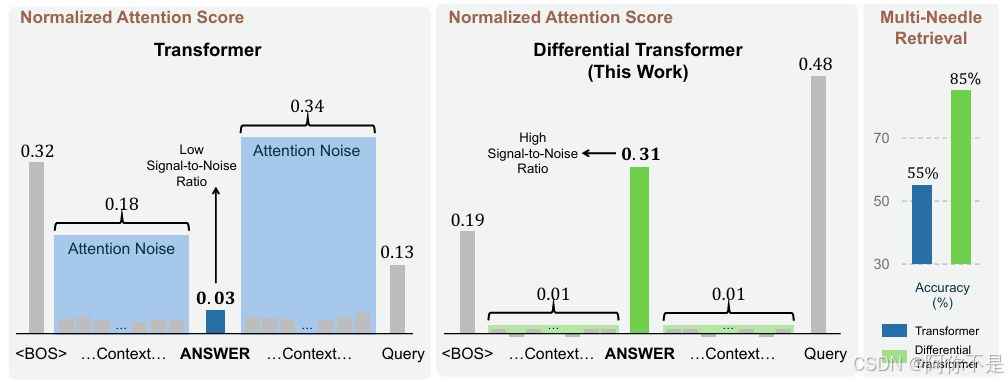
1)注意力噪声:Softmax注意力倾向于过度关注无关上下文(如高频但无意义的短语),导致关键信息被淹没,如图1左模型分配给正确答案的注意力分数很低,同时不成比例地关注不相关的上下文,这意味着信噪比很低,最终淹没了正确答案。
2)长上下文建模失效:在超长文本(如64k token)中,注意力稀释(Attention Dilution)问题显著,模型难以有效利用远端信息。
3)幻觉问题:生成内容中常包含与输入无关或逻辑矛盾的信息,尤其在问答和摘要任务中表现突出。
2、Diff Transformer的创新点
1)差分注意力:通过两组注意力权重的差值消除共模噪声,保留差异化信号。
2)动态参数调节:引入可学习标量,平衡噪声抑制与信号保留。
3)高效训练设计:通过参数共享与归一化策略(如RMSNorm),确保梯度稳定性。
三、实现方法
1、差分注意力机制(Differential Attention)
1.1 数学原理
输入矩阵通过投影矩阵生成两组查询(
)、键(
)和值(
):
,
,
其中,为动态学习的标量参数,通过以下方式初始化:
随层数递增(如
),深层网络更强调噪声控制。
2.2 噪声消除原理
1)共模噪声:两组注意力均包含相同噪声(如高频冗余模式),通过差值操作抵消。
(
ps:为什么两组注意力权重的差值可以消除共模噪声?
假设两组注意力权重 和
均包含相同的噪声成分
和不同的信号成分
:
通过计算差值 :
若 ,则共模噪声
被完全抵消,仅保留信号差异
。
实际中, 是动态学习的参数,通过调整
,模型可权衡噪声消除与信号保留:
-
当
:最大限度消除共模噪声,但可能削弱部分有用信号。
-
当
:保留更多原始信号,但噪声抑制效果减弱。
)
2)差异化信号:两组投影捕捉不同子空间信息(如局部依赖与全局结构),差值保留有用信号。
2、多头差分注意力(Multi-Head Differential Attention)
1)独立投影矩阵:每组头使用不同的,但共享同一层的
。
2)归一化与梯度对齐:输出经RMSNorm后乘以固定缩放因子,确保梯度流与传统Transformer一致。
3)参数效率:头数,总参数量与传统模型对齐。
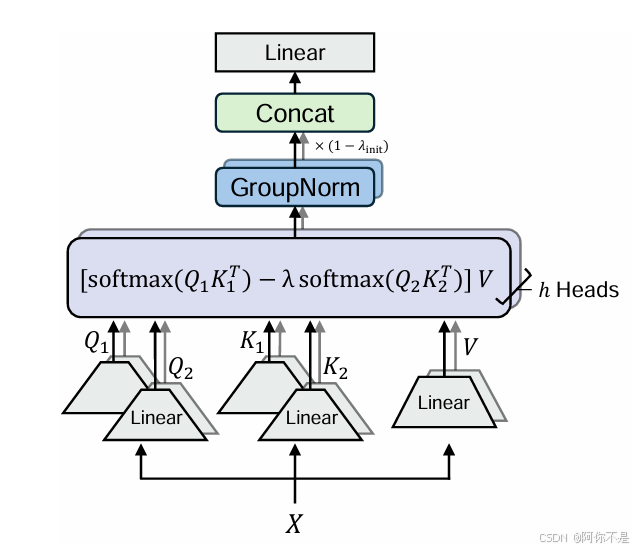
(
ps:多头差分注意力的设计有几个关键点:首先,每个头独立计算差分注意力,从而在不同子空间中捕捉不同的噪声和信号;其次,共享λ参数确保层内的一致性,避免不同头之间的噪声抑制策略冲突;最后,通过归一化和缩放因子,保持梯度流与传统Transformer一致,确保训练稳定性。
在多头差分注意力中,同一层内的所有头共享标量参数λ,这是为了保持层内注意力模式的一致性。如果不共享λ,或者如果每个头有自己的λ,是否会导致层内注意力模式不一致,进而带来什么问题?
在标准Transformer中,每个多头注意力层包含多个独立的注意力头,每个头都有自己的查询、键、值的投影矩阵。每个头可以关注输入的不同部分,从而捕捉不同的语义信息。例如,一个头可能关注句子的语法结构,另一个头可能关注实体的共现关系。因此,不同的头自然会有不同的注意力模式,这就是多头机制的优势所在。
在Differential Transformer中,每个头的注意力计算都涉及两组投影(Q₁/Q₂和K₁/K₂),并通过差值运算消除共模噪声。标量参数λ用于调整第二组注意力权重的抑制强度。如果每个头都有自己的λ,那么不同头可能会有不同的噪声抑制强度,导致同一层内的头在捕捉信息时关注不同的噪声和信号组合。这种不一致性可能会使得模型难以协调不同头的信息,影响最终输出的稳定性和一致性。
此外,共享λ可能有助于减少模型的参数数量,避免过拟合,同时保持训练过程的稳定性。如果每个头都有独立的λ,会增加模型的复杂度,可能需要在更多数据上进行训练才能有效学习这些参数,而这在实际应用中可能不切实际。
层内注意力模式的一致性是Differential Transformer高效运作的关键。通过共享噪声抑制参数λλ、统一梯度对齐策略和参数效率设计,模型能够在不同头之间协调噪声过滤与信号保留,确保长文本建模的鲁棒性和生成内容的逻辑一致性。这一设计平衡了灵活性与稳定性,为复杂场景下的注意力机制优化提供了重要参考。
)
四、实验验证
1、语言建模能力
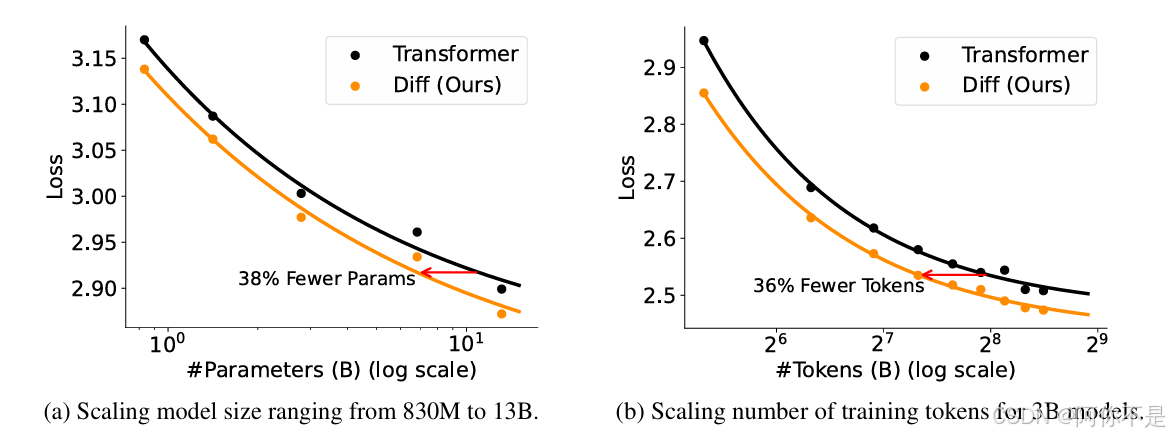
基准测试:在LM Eval Harness中,Diff-3B模型(1T tokens训练)平均准确率达60.6%,显著高于OpenLLaMA-3B(57.5%)和StableLM-3B(56.8%)。
参数效率:6.8B Diff Transformer的验证损失与11B传统Transformer相当,参数量减少37.8%。
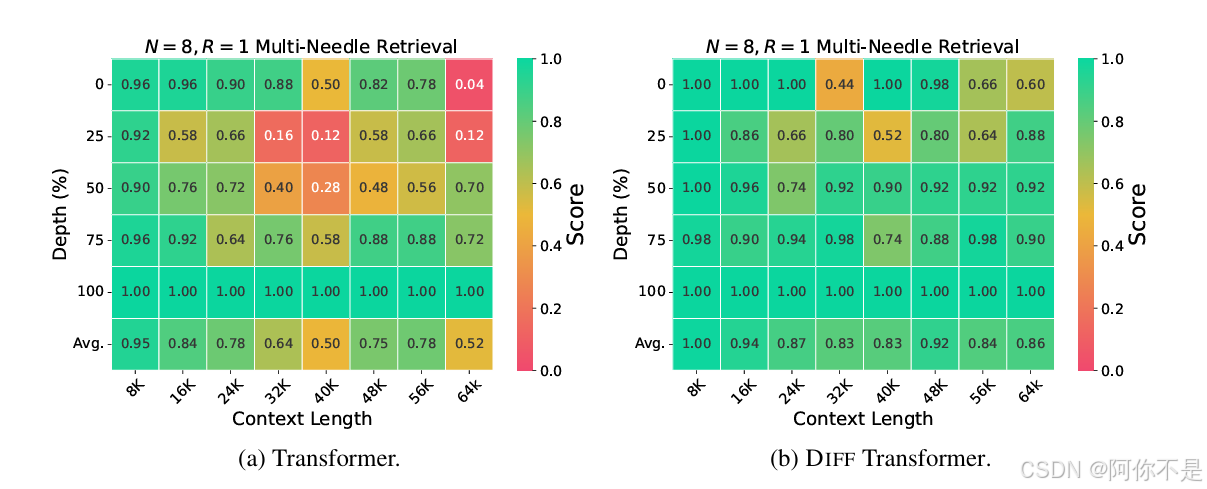
2、长上下文建模(大海捞针测试)
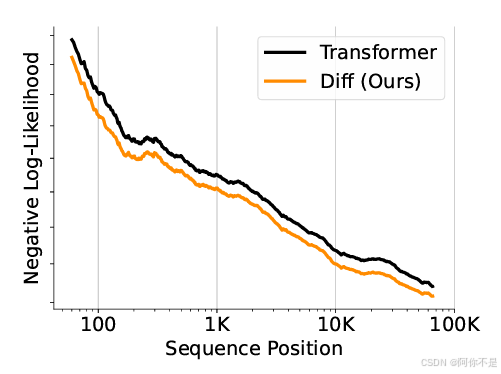
本文的实验遵循LWM和Gemini 1.5的「多针」评估方案,在不同长度的上下文中,N根针被插入不同的深度。每根「针」都由一个简洁的句子组成,为特定城市分配一个独特的魔法数字。答案针被放置在上下文中的5个不同深度:0%、25%、50%、75%和100%,同时随机放置其他分散注意力的针。待测LLM的目标,就是是检索与查询城市相对应的数字。
64k上下文测试:Diff Transformer的负对数似然(NLL)持续低于传统模型,表明其能有效利用长文本信息。
关键信息检索(Needle-in-a-Haystack):在64k上下文中,Diff Transformer检索精度提升76%(25%深度位置),且对输入顺序扰动更鲁棒。
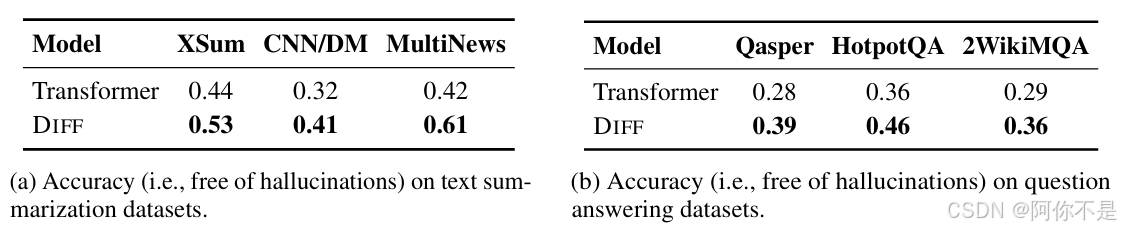
3、幻觉缓解
文章幻觉检测实验关注的是输入上下文包含正确事实的情况下,模型仍然未能生成准确输出的情况。将模型输出与地面真实响应一起输入到GPT-4o。然后要求GPT-4o对模型输出是否准确且没有幻觉做出二元判断。先前的研究已经表明,以上的幻觉评估协议在GPT-4o判断与人工标注之间具有较高的一致性。该自动化指标是可靠的,并且与人工评估相吻合。对于每个数据集,准确度是基于100个样本的平均值。
文本摘要与问答:Diff Transformer在XSum、CNN/DM等数据集上的幻觉率降低9-19%。
注意力分数分析:Diff Transformer对答案片段的注意力分配提升至0.27-0.40(传统模型仅0.03-0.09),噪声注意力降低至0.01-0.02(传统模型0.49-0.54)。
4、激活异常值抑制
量化性能:Diff Transformer在6-bit量化下保持高准确率(HellaSwag任务中仅下降2%),而传统模型下降15%。
异常值统计:注意力Logit的Top-1值从318.0(传统模型)降至38.8,更适合低比特部署。
五、讨论与未来方向
1、优势总结
1)噪声抑制能力:差分注意力显著减少无关上下文的干扰。
2)长文本建模:支持64k及以上上下文窗口,关键信息检索精度高。
3)训练效率:参数与数据需求减少约35-40%,适合边缘设备部署。
2、潜在挑战
1)计算开销:差分注意力引入额外投影,训练吞吐量降低5-12%。
2)动态参数优化:的初始化策略需进一步探索,以适配不同任务需求。
3、未来工作
1)多模态扩展:结合图像/音频模态,探索跨模态噪声抑制。
2)低比特优化:利用激活异常值减少特性,开发高效FlashAttention内核。
3)符号知识融合:集成知识图谱,增强生成内容的事实一致性。
六、结论
Diff Transformer通过差分注意力机制,在保持传统Transformer架构简洁性的同时,显著提升了模型对关键信息的捕捉能力与生成内容的可靠性。其在长文本建模、幻觉缓解、量化友好性等方面的优势,为大规模语言模型的实用化提供了新的技术路径。未来研究可进一步探索其在多模态、低资源场景下的潜力。

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









