











当物理学遇上AI,一场精准捕捉的变革悄然上演
想象一下,在信息的汪洋大海中,寻找一根至关重要的“针”,难度无异于“大海捞针”。然而,随着诺贝尔物理学奖的光芒照耀到“机器学习之父”

Geoffrey Hinton的肩头,另一场跨界融合也在悄然进行——微软与清华大学的科研团队携手,将物理学的智慧融入AI,推出Differential Transformer(DIFF Transformer),
让Transformer的“眼睛”更加雪亮,精准捕捉关键信息的能力暴增30%!这一突破性成果,是否意味着AI在信息筛选上的“慧眼”将开启全新篇章?
Transformer的困境:注意力迷雾中的“幻觉”
Transformer,这一自然语言处理(NLP)领域的明星架构,其核心在于注意力机制,仿佛一双洞察文本脉络的眼睛。

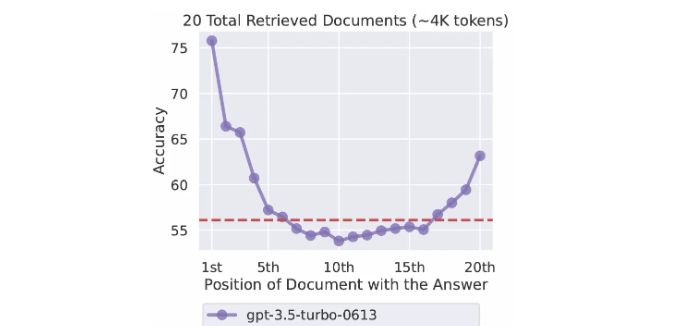
然而,这双眼睛却时常陷入“迷雾”——难以准确检索和利用长上下文中的关键信息。就像斯坦福Percy Liang团队的研究揭示的那样,
尽管语言模型能接收长篇输入,但往往无法稳健地利用这些信息。改变关键信息的位置,就能让GPT-3.5 Turbo的检索性能如过山车般起伏。更令人头疼的是,

Transformer常常过度关注不相关的上下文,产生“注意力噪声”,仿佛在一场嘈杂的派对中,难以捕捉到清晰的声音。
差分注意力:降噪“慧眼”,精准捕捉
面对这一困境,DIFF Transformer应运而生,它携带着“差分注意力”机制,如同一台精密的差分放大器,消除注意力噪声,让模型更加聚焦于上下文中的关键信息。
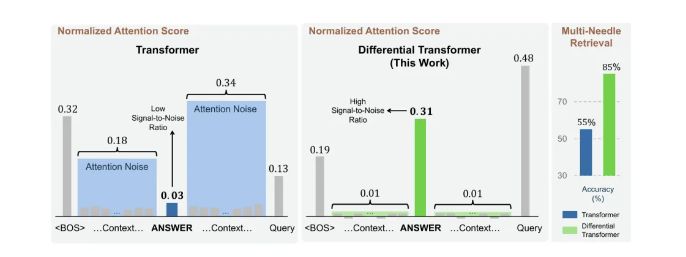
不同于传统Transformer,DIFF Transformer在softmax过程中引入了差分算子,通过计算两个softmax函数间的差异,有效降低了不相关信息的干扰,提升了信噪比。
正如降噪耳机在嘈杂环境中捕捉清晰人声,DIFF Transformer也在信息的洪流中,精准锁定那根至关重要的“针”。
模型架构:物理灵感,重塑经典
DIFF Transformer不仅保留了Transformer的可扩展性,更在细节上进行了精妙改进。它可用于纯Encoder或Encoder-Decoder模型,以纯Decoder模型为例,
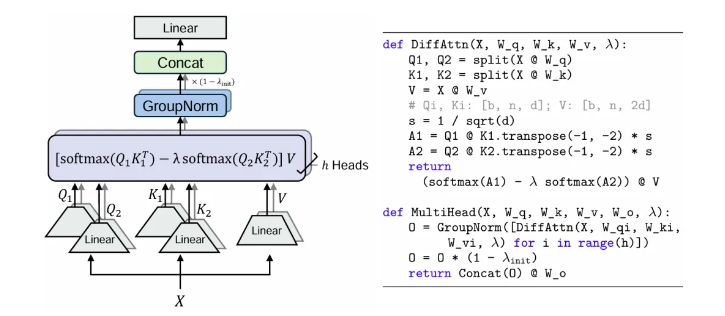
整个架构由多个DIFF Transformer层堆叠而成,每层包含一个差分注意力模块和一个前馈网络模块。差分注意力模块中,加入了可学习标量λ,
通过公式计算,实现注意力的差分放大。这种设计,不仅提升了模型对关键信息的敏感度,还增强了其处理长上下文的能力。
实验:从“大海捞针”到精准定位
实验证明,DIFF Transformer的表现令人瞩目。在1T token上训练的3B大小模型,在各种下游任务上均取得了优异成绩。特别是在长上下文任务中,
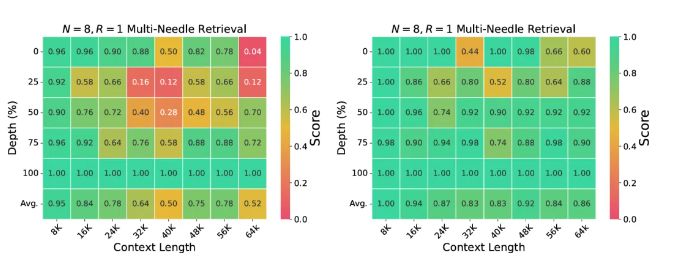
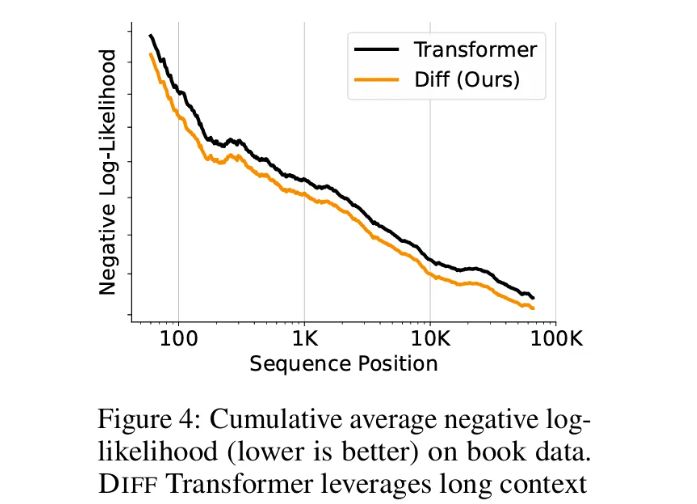
随着上下文长度的增加,DIFF Transformer的累计平均负对数似然值(NLL)持续降低,显示出其在处理长序列上的强大能力。在“大海捞针”测试中,DIFF Transformer更是大放异彩,
相比传统Transformer,在关键信息位于前半部分时,实现了高达76%的精度提升。此外,DIFF Transformer还有效缓解了幻觉现象,让模型在总结和问答任务上更加准确可靠。
物理与AI的交响曲,奏响未来
DIFF Transformer的诞生,不仅是AI技术的一次革新,更是物理学与AI跨界融合的典范。它让我们看到,

当传统学科的智慧与现代科技的力量相遇,将碰撞出怎样的火花。未来,随着更多跨学科研究的深入,AI将拥有更加敏锐的“慧眼”,在信息的海洋中,
精准捕捉每一份价值,为人类社会的发展贡献更大的力量。这场物理与AI的交响曲,正奏响着未来的乐章。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









