







一、概论
机器学习其复杂之处便是如何进行特征工程来提取特征,但是对于深度学习而言,其优势便是解决了特征工程复杂的问题,从而可以让计算机可以自己提取特征,拥有学习的能力
常用于自然语言处理和计算机视觉,人脸识别
但是其不太适用于移动端,因为其内部参数实在是太多了,速度可能比较慢,但是对于准确率比传统机器学 习模型高
深度学习支持的数据集比较大的时候效果较传统的人工智能算法要好,图像数据集可以通过旋转,映像等方式扩充。
二、计算机视觉基础知识
1.二值图像
二值图像是指仅仅包含黑色和白色两种颜色的图像,在计算机中以二维矩阵表示,其中白色为1,黑色为0,例如96*96的二值图像即可表示为矩阵为96*96的二维矩阵
2.灰度图像
同样,灰度图像仍为二维矩阵表示,但其值不再是0,1。通常,计算机会将灰度处理为 256 个灰度级,用数值区间[0,255] 来表示。其中,数值"255"表示纯白色,数值“0”表示纯黑色,其余的数值表示从纯白到纯黑之间不同级别的灰度 用于表示 256 个灰度级的数值 0-255,正好可以用一个字节(8 位二进制值)来表示。
3.彩色图像
神经生理学实验发现,在视网膜上存在三种不同的颜色感受器,能够感受三种不同的颜色红色、绿色和蓝色,即三基色。自然界中常见的各种色光都可以通过将三基色按照一定的比例混合构成。除此以外,从光学角度出发,可以将颜色解析为主波长,纯度,明度等,从心理学和视觉角度出发,可以将颜色解析为色调、饱和度、亮度等,通常,我们将上述采用不同的方式表述颜色的模式称为色彩空间,或者颜色空间、颜色模式等。
虽然不同的色彩空间具有不同的表示方式,但是各种色彩空间之间可以根据需要按照公式进行转换。这里仅仅介绍较为常用的 RGB 色彩空间
在 RGB 色彩空间中,存在 R(red,红色)通道,G(gren,绿色)通道和 B(bhue,踅色)通道,共三个通道。每个色彩通道值的范围都在 [0-255] 之间,我们用这三个色彩通道的组合表示颜色。
以比较通俗的方式来解释就是,有三个油漆桶,分别装了红色、绿色、蓝色的油漆,我们分别从每个油漆桶中取容呈为 0-255 个单位的不等量的油漆,将三种油漆混合就可以调出一种新的色,三种油漆经过不同的组合,共可以词配出所有常见的 256×256×256=16777216种颜色
因此我们可以用三维矩阵来表示彩色图像,一般清况下,在 RGB 色彩空间中,图像道的顺序是 R→G→B,即第1 个通道是R通道,第2 个通道是G通道,第3 个道是B 通道: 需要特别注意的是,在 Opencv中,通道的顺序是 B→G→R。
三、初识神经网络
组件①:线性(得分)函数
形如 :![]()
例如所要处理的是十分类图片分类任务,对应每张图片像素为10*10*3,那么W就应该是10*300的矩阵,其中300表示像素点个数,即特征个数,b为调制的一个参数,值为10*1的矩阵,x为一张图片对应像素值矩阵即为300*1
线性函数w矩阵中,值大小表示相关程度,正负表示促进或者抑制,初始值可以为随机生成,之后不断迭代进行改进
组件②:损失函数
神经网络可做分类可做回归,其主要区别就是损失函数如何定义
例如: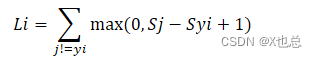
Syi为本类别 Sj为其他类别 1即∆(就是一个容忍值)
做的好损失值为0,做的不是特别好损失值>0,因此常用来衡量模型怎么样
Update:
损失函数=数据损失+正则化惩罚项(就是以防模型过拟合,和那个w矩阵有关)
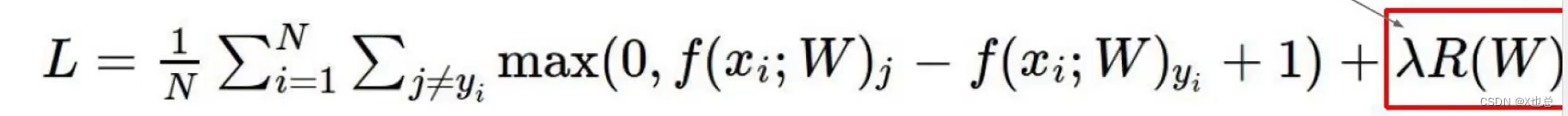
![]()
组件③:Softmax分类器
即将对应类别得分值转换为概率

![]()
计算损失值的时候仅看对应正确类别,随后进行 Li=-log(P)变换即得出对应损失值,根据图像更加容易理解
前向传播:(即得出损失值,根据这个损失值不断来进行反向传播(梯度下降),更新W矩阵)
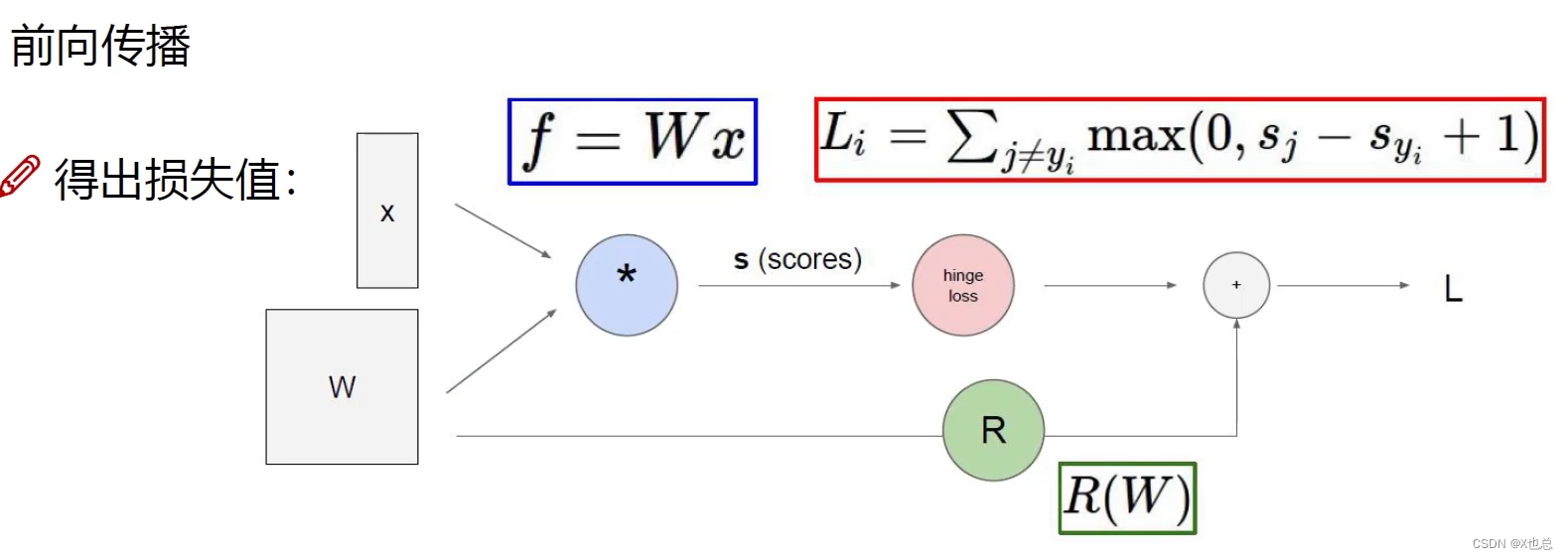
回归任务:根据得分值计算损失
分类任务:根据概率值计算损失
反向传播:(计算方法)
应用链时法则求导,即从损失值入手,逐步从后向前求偏导
即梯度是一步一步传过去的
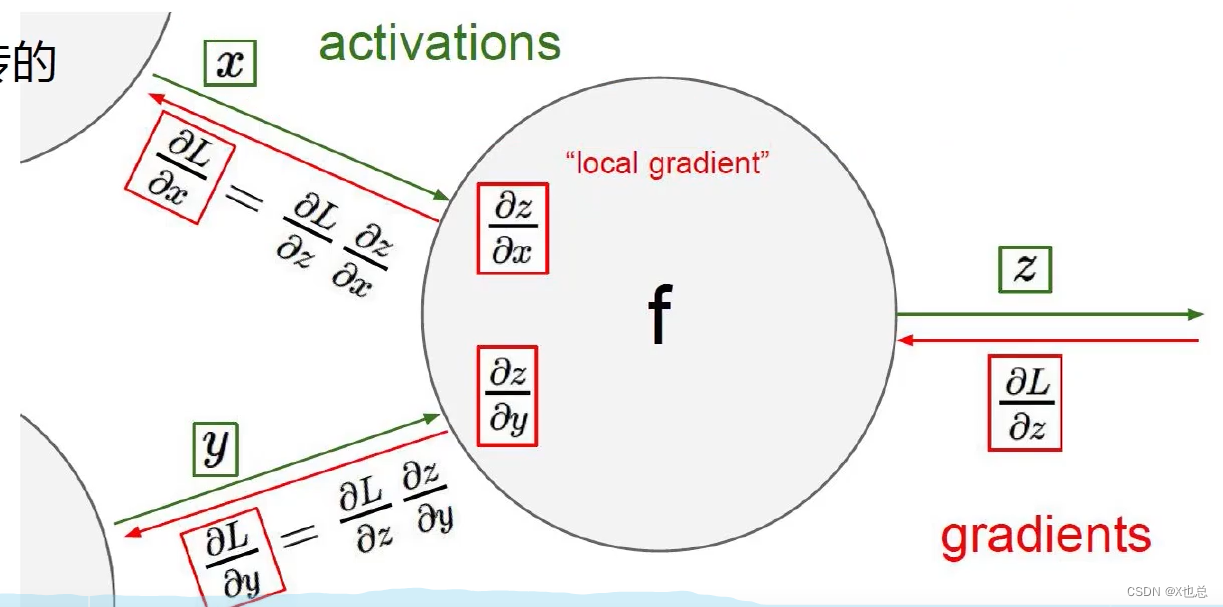
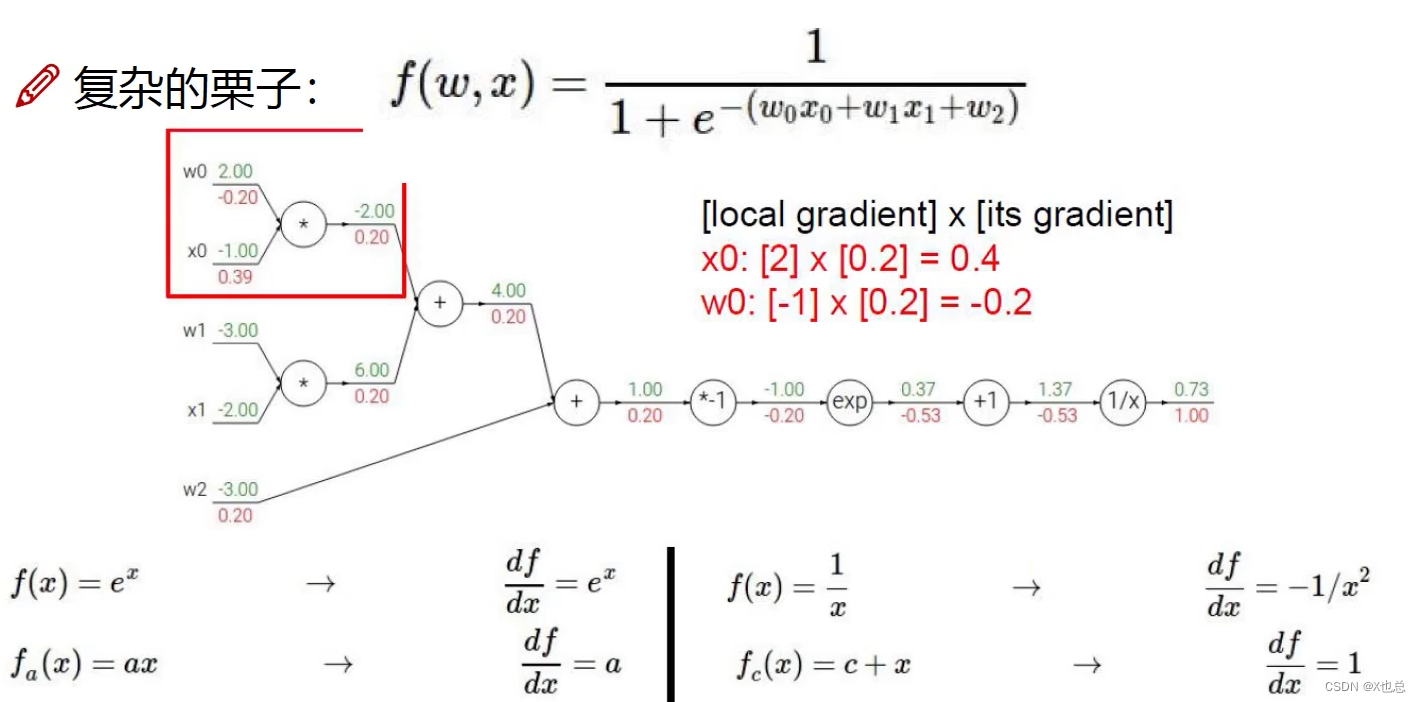
其中在计算的时候也可以采用成块来进行求偏导

不过计算过程固然麻烦,但是又工具包就会好很多
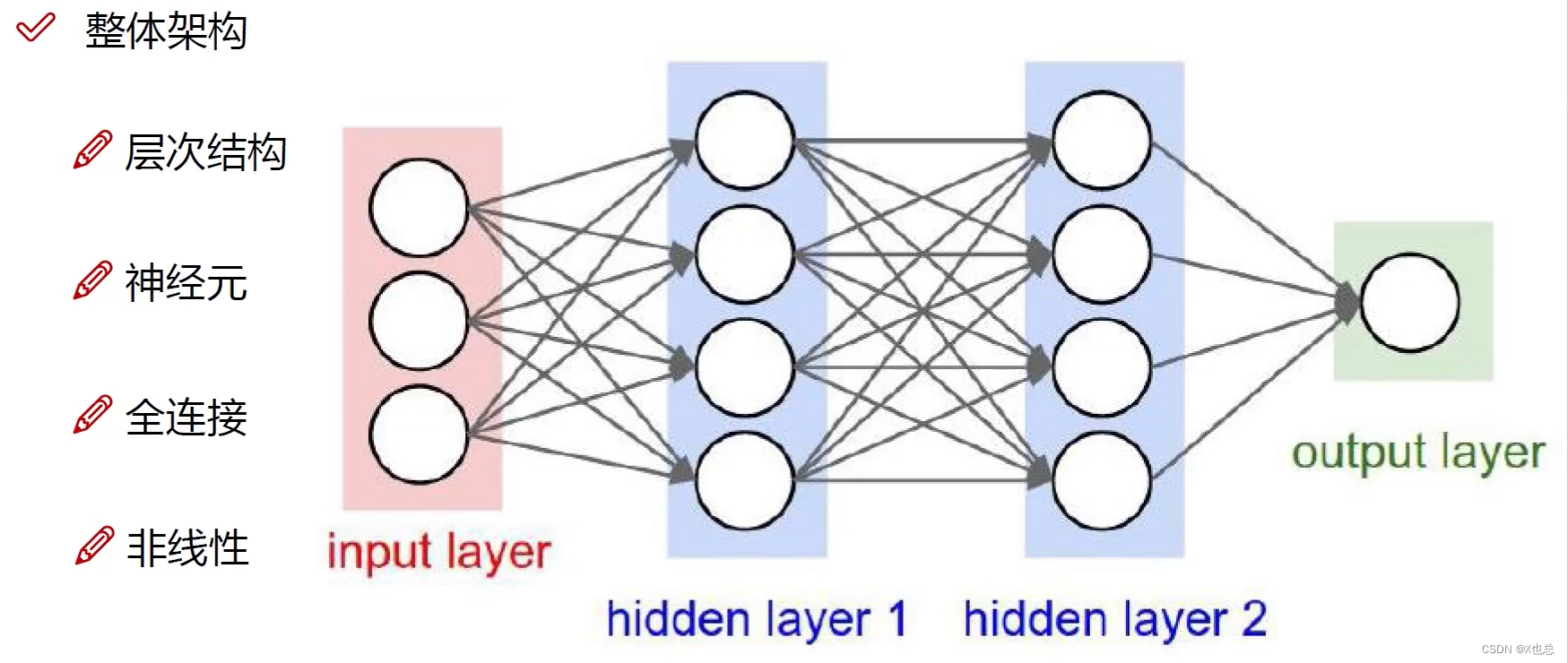
四、神经网络整体架构
神经元:输入数据的列数、即特征数
全连接:图中的线就是那个意思
隐层1:特征数变多,第一个神经元可以是 0.2*A+0.2*B+0.4*C,后面三个就是这个意思
线层:(乱起的名字)即权重参数矩阵W1、W2、w3[需要注意的是其中不同参数矩阵大小可能不一致,这取决于前后神经元个数]
非线性:即在经过权重参数矩阵变换后就会进行非线性变换,而不是直接进行W2变换
其中数学表示便是:(也因此我们可以发现其过程中参数很多)
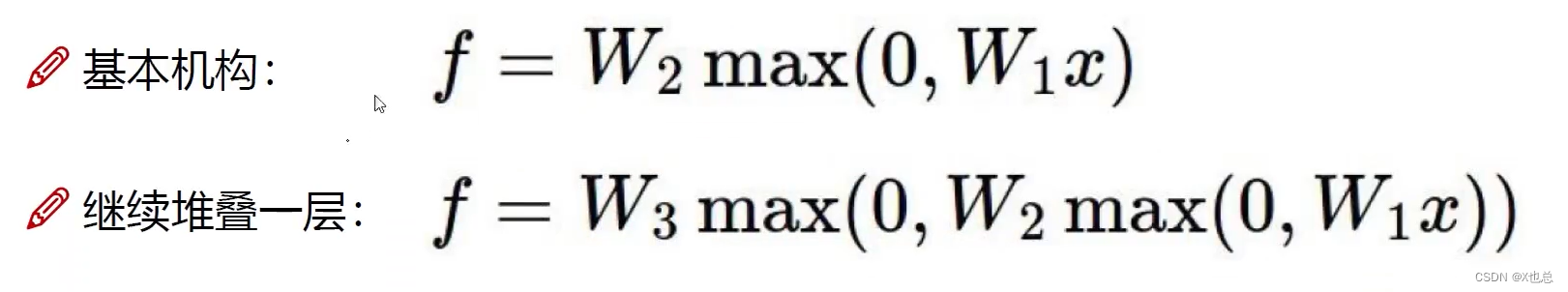
神经元数量的影响: 64,128,256,512(常见)
数量太小:拟合效果不好
数量太大:容易产生过拟合
正则化惩罚力度的影响:
惩罚力度太大:消除过拟合现象 0.1
惩罚力度太小:过拟合现象拟合消除不明显 0.001
激活函数(非线性变换):
sigmoid函数:(易出现梯度消失现象,已淘汰)
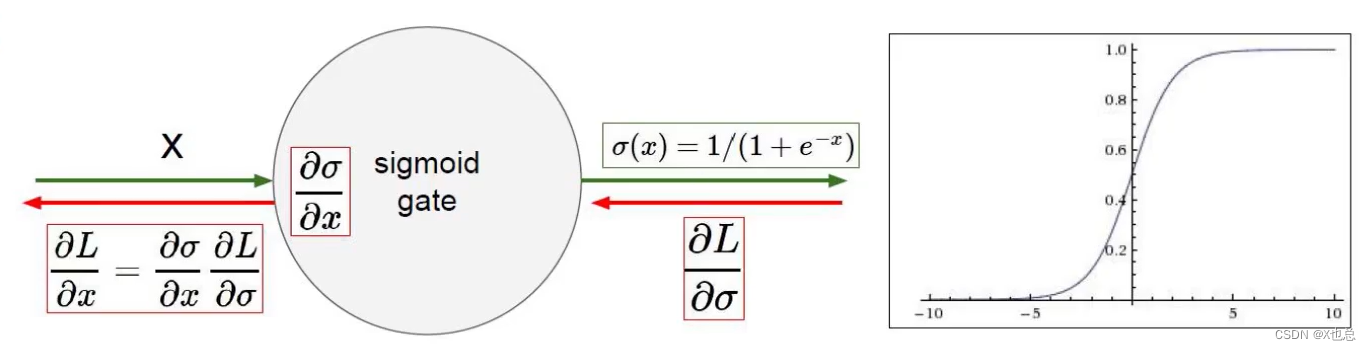
relu函数:(较为常用)
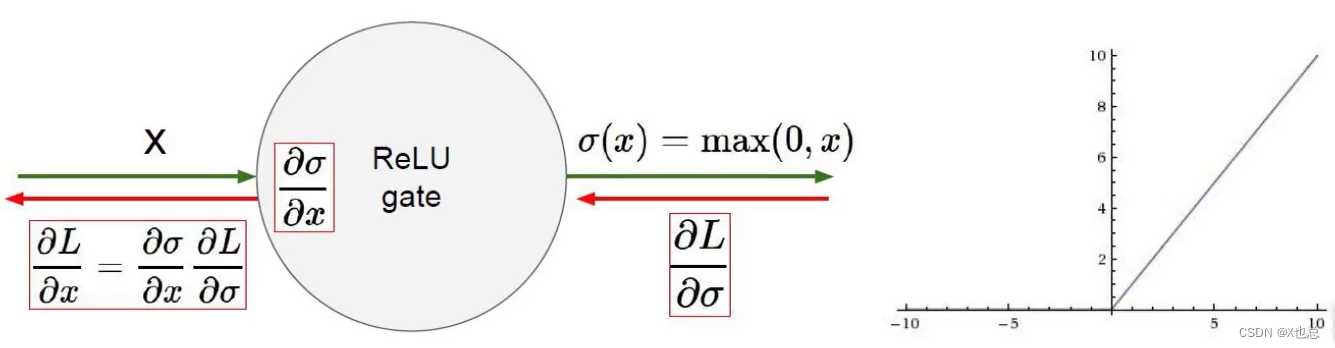
五、神经网络过拟合解决方法:
Ⅰ:数据预处理(不同预处理方式会产生不同的结果)
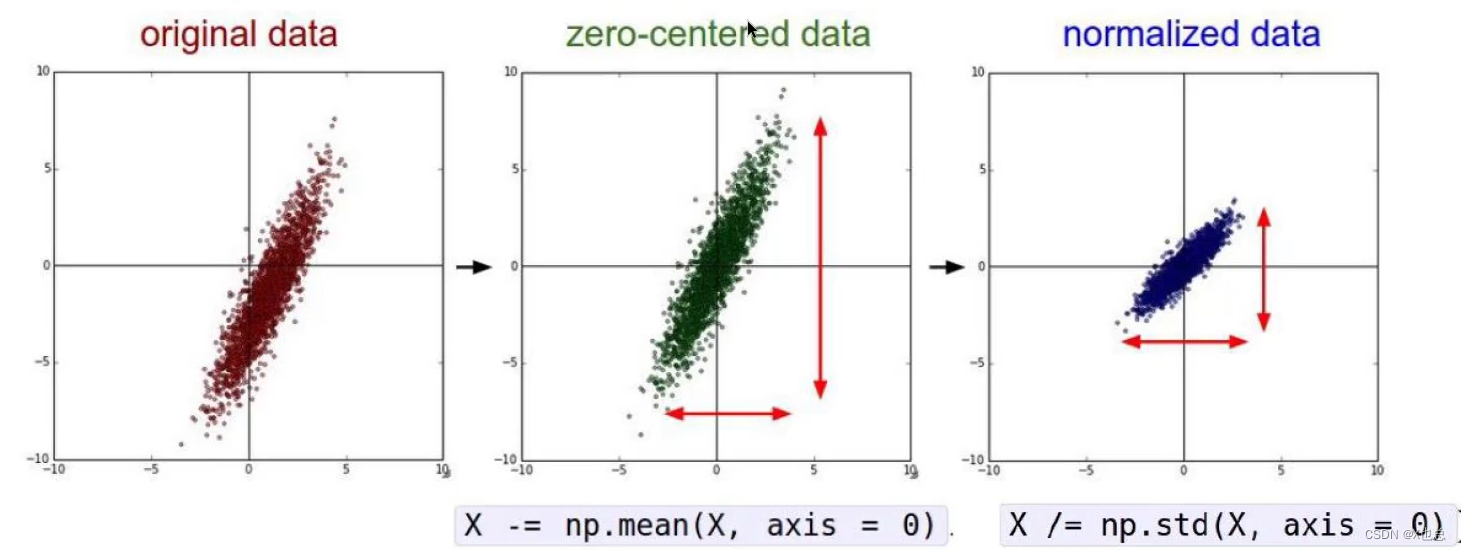
Ⅱ:参数初始化(随机策略)

其中0.01是为了防止值波动太大,初始权值系数矩阵是随机产生的
Ⅲ:DROP-OUT(传说中的七杀拳)
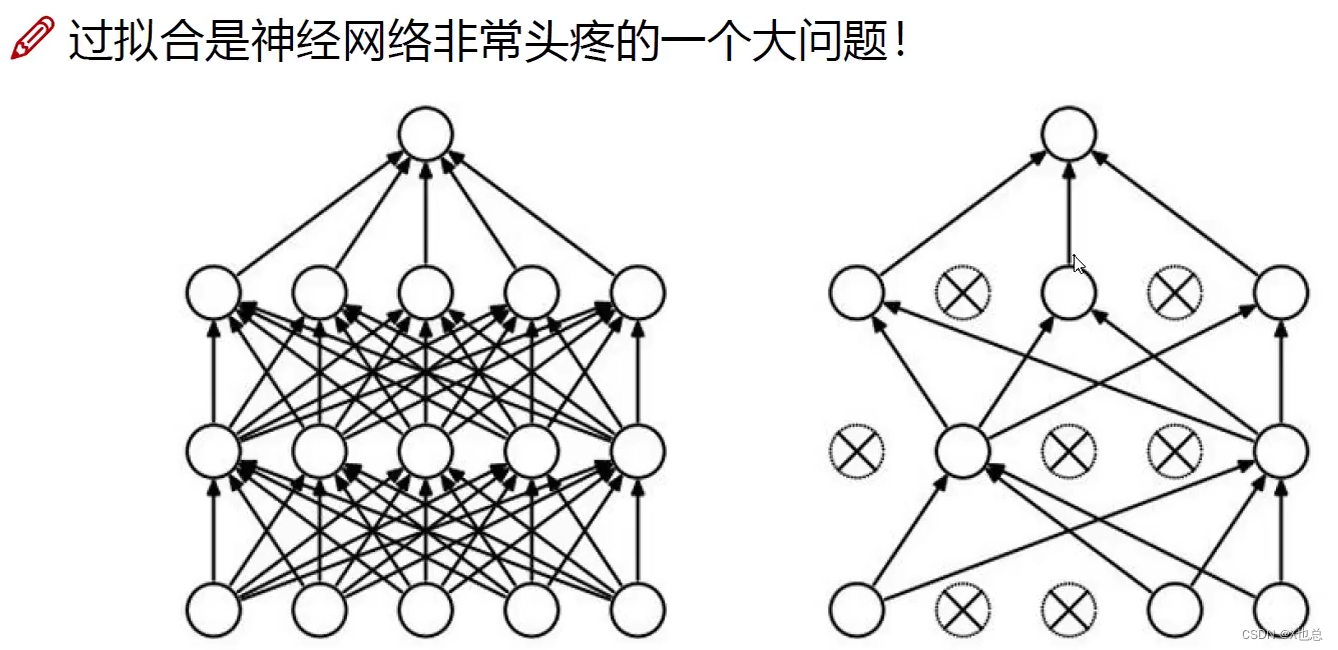
在训练阶段中:在每轮迭代过程中选择性忽略掉某些神经元,更新也会忽略掉, 在每一轮当中忽略掉的神经元未必一致。
在测试阶段则没有必要这样进行。















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









