






目录
摘要
VIBE是一种基于视频的3D人体姿态和形状估计方法,改进了先前工作 HMR 中存在的时序不一致性和动态运动捕捉不足等问题。通过引入时序编码器(如:GRU、Transformer)和对抗性训练,VIBE能够从视频序列中生成平滑且逼真的3D人体网格。其模型结构包括特征提取器、时序编码器、人体网格回归器和对抗性判别器,利用AMASS数据集进行预训练,显著提升了性能。VIBE在3DPW、Human3.6M等数据集上达到了当时的最先进水平,并且在长视频序列中表现出色。
Abstract
VIBE is a video-based 3D human pose and shape estimation method that addresses issues such as temporal inconsistency and insufficient dynamic motion capture in previous work like HMR. By introducing temporal encoders (e.g., GRU, Transformer) and adversarial training, VIBE can generate smooth and realistic 3D human meshes from video sequences. Its model architecture includes a feature extractor, a temporal encoder, a human mesh regressor, and an adversarial discriminator, and it leverages the AMASS dataset for pre-training, significantly improving performance. VIBE achieves state-of-the-art results on datasets such as 3DPW and Human3.6M, demonstrating exceptional performance in long video sequences.
VIBE

论文链接:[1912.05656] VIBE: Video Inference for Human Body Pose and Shape Estimation
项目地址:VIBE

VIBE主要由上图的特征提取器CNN、时序编码器GRU、人体网格回归器、对抗性判别器 4 个模块组成,下文将主要按照这4个模块进行介绍。
特征提取器
VIBE使用预训练的卷积神经网络,如:ResNet,作为特征提取器的骨干网络。将视频的每一帧图像输入到CNN中。CNN的中间层或最后一层的特征图被提取出来,作为每一帧的视觉特征表示。这些特征一般是2D关键点热图或高维特征向量。
时序编码器
时序编码器主要功能是捕捉视频帧之间的时序信息,生成连贯的3D姿态序列,解决单帧估计方法中存在的时序不一致性问题。时序编码器通常采用GRU或Transformer。特征提取器输出的特征序列,即每一帧的特征向量作为时序编码器的输入。输出则是一个时序上下文特征,包含当前帧及其前后帧的运动信息。
GRU
传统的RNN在处理长序列数据时,容易出现梯度消失或梯度爆炸的问题,导致模型难以学习到序列中的长期依赖关系。GRU通过引入门控机制,有效缓解了这一问题,同时简化了LSTM的结构,提高了计算效率。GRU的核心在于其两个门控机制:更新门和重置门,以及隐藏状态的更新方式。如下图所示:
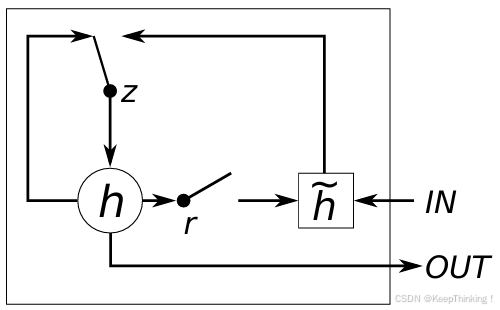
- 更新门
更新门的作用是决定当前隐藏状态中保留多少过去的信息,以及从当前输入中引入多少新信息。其计算公式为:
是更新门的输出,当
- 重置门
重置门的作用是决定如何将新信息与之前的记忆结合起来,类似于LSTM中的遗忘门。其计算公式为:
重置门的输出值也在0到1之间,用于控制前一时刻隐藏状态对当前候选隐藏状态的影响程度。
- 隐藏状态的更新
基于更新门和重置门,GRU的隐藏状态更新公式如下:
,计算候选隐藏状态
, 将候选隐藏状态与前一时刻的隐藏状态进行加权组合
PyTorch实现GRU模型示例如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 构造简单的示例数据集
X = [[1, 2, 3, 4], [5, 6, 7, 8], [1, 9, 10, 11], [12, 13, 14, 15]]
y = [0, 0, 1, 1]
X = torch.tensor(X, dtype=torch.long)
y = torch.tensor(y, dtype=torch.long)
# 定义数据集和数据加载器
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 定义GRU模型
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super(GRUModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out = self.embedding(x)
out, _ = self.gru(out, h0)
out = out[:, -1, :]
out = self.fc(out)
return out
# 模型参数
input_size = 16
hidden_size = 8
output_size = 2
num_layers = 1
# 创建模型
model = GRUModel(input_size, hidden_size, output_size, num_layers)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):
for data, labels in dataloader:
outputs = model(data)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 5 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 测试模型
with torch.no_grad():
test_sentence = torch.tensor([[1, 2, 3, 4]])
prediction = model(test_sentence)
predicted_class = torch.argmax(prediction, dim=1)
print(f'Predicted class: {predicted_class.item()}')人体网格回归器
该回归器基于时序编码器的输出,回归出SMPL模型的参数,如:姿态、形状和相机参数,以生成3D人体网格。
上述两个模块整体损失函数如下:
SMPL模型:SMPL是一种参数化的人体模型,能够通过姿态参数和形状参数生成3D人体网格;
姿态参数:24个关节的旋转角度;
形状参数:10维的低维形状向量,控制人体的体型;
相机参数:用于将3D网格投影到2D图像平面的缩放和平移参数;
网络结构:人体网格回归器通常是MLP,将时序编码器的输出映射到SMPL模型的参数空间。
SMPL
SMPL模型能够通过一组低维参数生成逼真的3D人体网格,并且支持骨骼驱动的动画。SMPL模型的核心思想是通过一组低维参数,如:姿态参数和形状参数,以生成一个可变形的人体网格。这些参数控制人体的姿态和形状,使得模型能够灵活地表示不同姿态和体型的人体。

参数化表示
SMPL模型的输入主要包括以下两类参数:
- 姿态参数
SMPL模型定义了24个关节,每个关节的旋转用3维的轴角以描述人体的关节旋转。因此,姿态参数的总维度为 24 × 3 = 72 维。
- 形状参数
形状参数是一个10维的低维向量,通过主成分分析从大量3D扫描数据中学习得到以描述人体的体形。这些参数控制人体的高度、胖瘦、肢体比例等特征。
数学模型
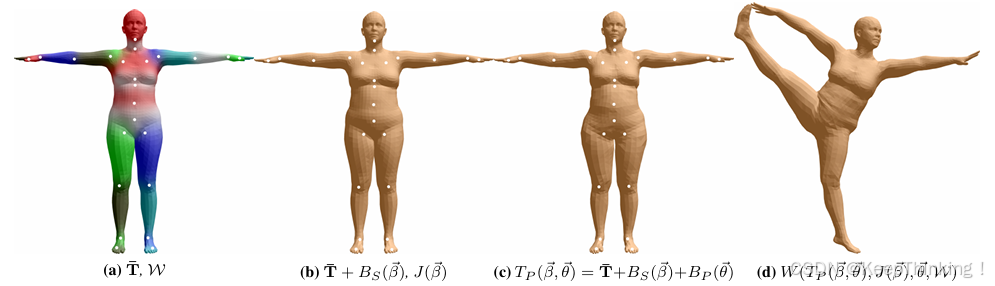
- 基础模板
SMPL模型的基础是一个平均人体模板网格,共包含 6890 个顶点和 13776 个面片。
- 形状变形
通过形状混合形状作用于模板网格,生成不同体型的人体网格。公式如下:
- 姿态变形
通过姿态混合形状和骨骼蒙皮作用于形状变形后的网格,生成不同姿态的人体网格。公式如下:
- 骨骼蒙皮
将变形后的网格顶点绑定到骨骼上,通过线性混合蒙皮计算最终顶点位置。公式如下:
对抗性判别器
通过对抗性训练,提升生成的3D人体网格的逼真性和时序一致性。判别器通常是一个基于GRU的时序判别器,用于区分生成的3D姿态序列和真实的3D姿态序列。如下图所示:
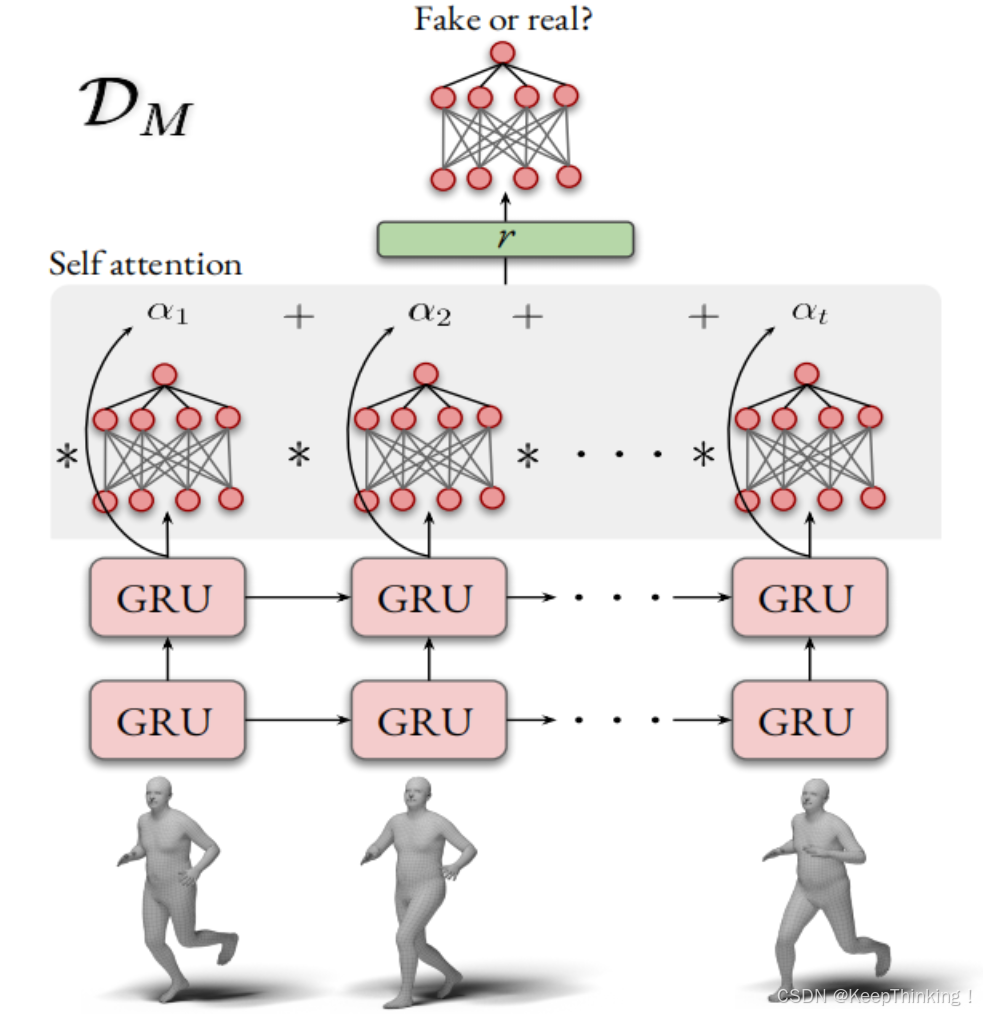
以生成的3D姿态序列或真实的3D姿态序列作为输入,输出一个标量值,表示输入序列的真实性。损失函数如下:
判别器的目标是区分真实和生成的3D姿态序列,而生成器的目标是生成逼真的序列以欺骗判别器。通过对抗性训练,生成器逐渐学会生成更加逼真和连贯的3D人体网格。
判别器通常会在训练过程中交替更新,以保持生成器和判别器之间的平衡。
代码
模型训练代码:
import os
os.environ['PYOPENGL_PLATFORM'] = 'egl'
import torch
import pprint
import random
import numpy as np
import torch.backends.cudnn as cudnn
from torch.utils.tensorboard import SummaryWriter
from lib.core.loss import VIBELoss
from lib.core.trainer import Trainer
from lib.core.config import parse_args
from lib.utils.utils import prepare_output_dir
from lib.models import VIBE, MotionDiscriminator
from lib.dataset.loaders import get_data_loaders
from lib.utils.utils import create_logger, get_optimizer
def main(cfg):
if cfg.SEED_VALUE >= 0:
print(f'Seed value for the experiment {cfg.SEED_VALUE}')
os.environ['PYTHONHASHSEED'] = str(cfg.SEED_VALUE)
random.seed(cfg.SEED_VALUE)
torch.manual_seed(cfg.SEED_VALUE)
np.random.seed(cfg.SEED_VALUE)
logger = create_logger(cfg.LOGDIR, phase='train')
logger.info(f'GPU name -> {torch.cuda.get_device_name()}')
logger.info(f'GPU feat -> {torch.cuda.get_device_properties("cuda")}')
logger.info(pprint.pformat(cfg))
# cudnn related setting
cudnn.benchmark = cfg.CUDNN.BENCHMARK
torch.backends.cudnn.deterministic = cfg.CUDNN.DETERMINISTIC
torch.backends.cudnn.enabled = cfg.CUDNN.ENABLED
writer = SummaryWriter(log_dir=cfg.LOGDIR)
writer.add_text('config', pprint.pformat(cfg), 0)
# ========= Dataloaders ========= #
data_loaders = get_data_loaders(cfg)
# ========= Compile Loss ========= #
loss = VIBELoss(
e_loss_weight=cfg.LOSS.KP_2D_W,
e_3d_loss_weight=cfg.LOSS.KP_3D_W,
e_pose_loss_weight=cfg.LOSS.POSE_W,
e_shape_loss_weight=cfg.LOSS.SHAPE_W,
d_motion_loss_weight=cfg.LOSS.D_MOTION_LOSS_W,
)
# ========= Initialize networks, optimizers and lr_schedulers ========= #
generator = VIBE(
n_layers=cfg.MODEL.TGRU.NUM_LAYERS,
batch_size=cfg.TRAIN.BATCH_SIZE,
seqlen=cfg.DATASET.SEQLEN,
hidden_size=cfg.MODEL.TGRU.HIDDEN_SIZE,
pretrained=cfg.TRAIN.PRETRAINED_REGRESSOR,
add_linear=cfg.MODEL.TGRU.ADD_LINEAR,
bidirectional=cfg.MODEL.TGRU.BIDIRECTIONAL,
use_residual=cfg.MODEL.TGRU.RESIDUAL,
).to(cfg.DEVICE)
if cfg.TRAIN.PRETRAINED != '' and os.path.isfile(cfg.TRAIN.PRETRAINED):
checkpoint = torch.load(cfg.TRAIN.PRETRAINED)
best_performance = checkpoint['performance']
generator.load_state_dict(checkpoint['gen_state_dict'])
print(f'==> Loaded pretrained model from {cfg.TRAIN.PRETRAINED}...')
print(f'Performance on 3DPW test set {best_performance}')
else:
print(f'{cfg.TRAIN.PRETRAINED} is not a pretrained model!!!!')
gen_optimizer = get_optimizer(
model=generator,
optim_type=cfg.TRAIN.GEN_OPTIM,
lr=cfg.TRAIN.GEN_LR,
weight_decay=cfg.TRAIN.GEN_WD,
momentum=cfg.TRAIN.GEN_MOMENTUM,
)
motion_discriminator = MotionDiscriminator(
rnn_size=cfg.TRAIN.MOT_DISCR.HIDDEN_SIZE,
input_size=69,
num_layers=cfg.TRAIN.MOT_DISCR.NUM_LAYERS,
output_size=1,
feature_pool=cfg.TRAIN.MOT_DISCR.FEATURE_POOL,
attention_size=None if cfg.TRAIN.MOT_DISCR.FEATURE_POOL !='attention' else cfg.TRAIN.MOT_DISCR.ATT.SIZE,
attention_layers=None if cfg.TRAIN.MOT_DISCR.FEATURE_POOL !='attention' else cfg.TRAIN.MOT_DISCR.ATT.LAYERS,
attention_dropout=None if cfg.TRAIN.MOT_DISCR.FEATURE_POOL !='attention' else cfg.TRAIN.MOT_DISCR.ATT.DROPOUT
).to(cfg.DEVICE)
dis_motion_optimizer = get_optimizer(
model=motion_discriminator,
optim_type=cfg.TRAIN.MOT_DISCR.OPTIM,
lr=cfg.TRAIN.MOT_DISCR.LR,
weight_decay=cfg.TRAIN.MOT_DISCR.WD,
momentum=cfg.TRAIN.MOT_DISCR.MOMENTUM
)
motion_lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
dis_motion_optimizer,
mode='min',
factor=0.1,
patience=cfg.TRAIN.LR_PATIENCE,
verbose=True,
)
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
gen_optimizer,
mode='min',
factor=0.1,
patience=cfg.TRAIN.LR_PATIENCE,
verbose=True,
)
# ========= Start Training ========= #
Trainer(
data_loaders=data_loaders,
generator=generator,
motion_discriminator=motion_discriminator,
criterion=loss,
dis_motion_optimizer=dis_motion_optimizer,
dis_motion_update_steps=cfg.TRAIN.MOT_DISCR.UPDATE_STEPS,
gen_optimizer=gen_optimizer,
start_epoch=cfg.TRAIN.START_EPOCH,
end_epoch=cfg.TRAIN.END_EPOCH,
device=cfg.DEVICE,
writer=writer,
debug=cfg.DEBUG,
logdir=cfg.LOGDIR,
lr_scheduler=lr_scheduler,
motion_lr_scheduler=motion_lr_scheduler,
resume=cfg.TRAIN.RESUME,
num_iters_per_epoch=cfg.TRAIN.NUM_ITERS_PER_EPOCH,
debug_freq=cfg.DEBUG_FREQ,
).fit()
if __name__ == '__main__':
cfg, cfg_file = parse_args()
cfg = prepare_output_dir(cfg, cfg_file)
main(cfg)测试代码:
import os
os.environ['PYOPENGL_PLATFORM'] = 'egl'
import cv2
import time
import torch
import joblib
import shutil
import colorsys
import argparse
import numpy as np
from tqdm import tqdm
from multi_person_tracker import MPT
from torch.utils.data import DataLoader
from lib.models.vibe import VIBE_Demo
from lib.utils.renderer import Renderer
from lib.dataset.inference import Inference
from lib.utils.smooth_pose import smooth_pose
from lib.data_utils.kp_utils import convert_kps
from lib.utils.pose_tracker import run_posetracker
from lib.utils.demo_utils import (
download_youtube_clip,
smplify_runner,
convert_crop_coords_to_orig_img,
convert_crop_cam_to_orig_img,
prepare_rendering_results,
video_to_images,
images_to_video,
download_ckpt,
)
MIN_NUM_FRAMES = 25
def main(args):
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
video_file = args.vid_file
# ========= [Optional] download the youtube video ========= #
if video_file.startswith('https://www.youtube.com'):
print(f'Donwloading YouTube video \"{video_file}\"')
video_file = download_youtube_clip(video_file, '/tmp')
if video_file is None:
exit('Youtube url is not valid!')
print(f'YouTube Video has been downloaded to {video_file}...')
if not os.path.isfile(video_file):
exit(f'Input video \"{video_file}\" does not exist!')
output_path = os.path.join(args.output_folder, os.path.basename(video_file).replace('.mp4', ''))
os.makedirs(output_path, exist_ok=True)
image_folder, num_frames, img_shape = video_to_images(video_file, return_info=True)
print(f'Input video number of frames {num_frames}')
orig_height, orig_width = img_shape[:2]
total_time = time.time()
# ========= Run tracking ========= #
bbox_scale = 1.1
if args.tracking_method == 'pose':
if not os.path.isabs(video_file):
video_file = os.path.join(os.getcwd(), video_file)
tracking_results = run_posetracker(video_file, staf_folder=args.staf_dir, display=args.display)
else:
# run multi object tracker
mot = MPT(
device=device,
batch_size=args.tracker_batch_size,
display=args.display,
detector_type=args.detector,
output_format='dict',
yolo_img_size=args.yolo_img_size,
)
tracking_results = mot(image_folder)
# remove tracklets if num_frames is less than MIN_NUM_FRAMES
for person_id in list(tracking_results.keys()):
if tracking_results[person_id]['frames'].shape[0] < MIN_NUM_FRAMES:
del tracking_results[person_id]
# ========= Define VIBE model ========= #
model = VIBE_Demo(
seqlen=16,
n_layers=2,
hidden_size=1024,
add_linear=True,
use_residual=True,
).to(device)
# ========= Load pretrained weights ========= #
pretrained_file = download_ckpt(use_3dpw=False)
ckpt = torch.load(pretrained_file)
print(f'Performance of pretrained model on 3DPW: {ckpt["performance"]}')
ckpt = ckpt['gen_state_dict']
model.load_state_dict(ckpt, strict=False)
model.eval()
print(f'Loaded pretrained weights from \"{pretrained_file}\"')
# ========= Run VIBE on each person ========= #
print(f'Running VIBE on each tracklet...')
vibe_time = time.time()
vibe_results = {}
for person_id in tqdm(list(tracking_results.keys())):
bboxes = joints2d = None
if args.tracking_method == 'bbox':
bboxes = tracking_results[person_id]['bbox']
elif args.tracking_method == 'pose':
joints2d = tracking_results[person_id]['joints2d']
frames = tracking_results[person_id]['frames']
dataset = Inference(
image_folder=image_folder,
frames=frames,
bboxes=bboxes,
joints2d=joints2d,
scale=bbox_scale,
)
bboxes = dataset.bboxes
frames = dataset.frames
has_keypoints = True if joints2d is not None else False
dataloader = DataLoader(dataset, batch_size=args.vibe_batch_size, num_workers=16)
with torch.no_grad():
pred_cam, pred_verts, pred_pose, pred_betas, pred_joints3d, smpl_joints2d, norm_joints2d = [], [], [], [], [], [], []
for batch in dataloader:
if has_keypoints:
batch, nj2d = batch
norm_joints2d.append(nj2d.numpy().reshape(-1, 21, 3))
batch = batch.unsqueeze(0)
batch = batch.to(device)
batch_size, seqlen = batch.shape[:2]
output = model(batch)[-1]
pred_cam.append(output['theta'][:, :, :3].reshape(batch_size * seqlen, -1))
pred_verts.append(output['verts'].reshape(batch_size * seqlen, -1, 3))
pred_pose.append(output['theta'][:,:,3:75].reshape(batch_size * seqlen, -1))
pred_betas.append(output['theta'][:, :,75:].reshape(batch_size * seqlen, -1))
pred_joints3d.append(output['kp_3d'].reshape(batch_size * seqlen, -1, 3))
smpl_joints2d.append(output['kp_2d'].reshape(batch_size * seqlen, -1, 2))
pred_cam = torch.cat(pred_cam, dim=0)
pred_verts = torch.cat(pred_verts, dim=0)
pred_pose = torch.cat(pred_pose, dim=0)
pred_betas = torch.cat(pred_betas, dim=0)
pred_joints3d = torch.cat(pred_joints3d, dim=0)
smpl_joints2d = torch.cat(smpl_joints2d, dim=0)
del batch
# ========= [Optional] run Temporal SMPLify to refine the results ========= #
if args.run_smplify and args.tracking_method == 'pose':
norm_joints2d = np.concatenate(norm_joints2d, axis=0)
norm_joints2d = convert_kps(norm_joints2d, src='staf', dst='spin')
norm_joints2d = torch.from_numpy(norm_joints2d).float().to(device)
# Run Temporal SMPLify
update, new_opt_vertices, new_opt_cam, new_opt_pose, new_opt_betas, \
new_opt_joints3d, new_opt_joint_loss, opt_joint_loss = smplify_runner(
pred_rotmat=pred_pose,
pred_betas=pred_betas,
pred_cam=pred_cam,
j2d=norm_joints2d,
device=device,
batch_size=norm_joints2d.shape[0],
pose2aa=False,
)
# update the parameters after refinement
print(f'Update ratio after Temporal SMPLify: {update.sum()} / {norm_joints2d.shape[0]}')
pred_verts = pred_verts.cpu()
pred_cam = pred_cam.cpu()
pred_pose = pred_pose.cpu()
pred_betas = pred_betas.cpu()
pred_joints3d = pred_joints3d.cpu()
pred_verts[update] = new_opt_vertices[update]
pred_cam[update] = new_opt_cam[update]
pred_pose[update] = new_opt_pose[update]
pred_betas[update] = new_opt_betas[update]
pred_joints3d[update] = new_opt_joints3d[update]
elif args.run_smplify and args.tracking_method == 'bbox':
print('[WARNING] You need to enable pose tracking to run Temporal SMPLify algorithm!')
print('[WARNING] Continuing without running Temporal SMPLify!..')
# ========= Save results to a pickle file ========= #
pred_cam = pred_cam.cpu().numpy()
pred_verts = pred_verts.cpu().numpy()
pred_pose = pred_pose.cpu().numpy()
pred_betas = pred_betas.cpu().numpy()
pred_joints3d = pred_joints3d.cpu().numpy()
smpl_joints2d = smpl_joints2d.cpu().numpy()
# Runs 1 Euro Filter to smooth out the results
if args.smooth:
min_cutoff = args.smooth_min_cutoff # 0.004
beta = args.smooth_beta # 1.5
print(f'Running smoothing on person {person_id}, min_cutoff: {min_cutoff}, beta: {beta}')
pred_verts, pred_pose, pred_joints3d = smooth_pose(pred_pose, pred_betas,
min_cutoff=min_cutoff, beta=beta)
orig_cam = convert_crop_cam_to_orig_img(
cam=pred_cam,
bbox=bboxes,
img_width=orig_width,
img_height=orig_height
)
joints2d_img_coord = convert_crop_coords_to_orig_img(
bbox=bboxes,
keypoints=smpl_joints2d,
crop_size=224,
)
output_dict = {
'pred_cam': pred_cam,
'orig_cam': orig_cam,
'verts': pred_verts,
'pose': pred_pose,
'betas': pred_betas,
'joints3d': pred_joints3d,
'joints2d': joints2d,
'joints2d_img_coord': joints2d_img_coord,
'bboxes': bboxes,
'frame_ids': frames,
}
vibe_results[person_id] = output_dict
del model
end = time.time()
fps = num_frames / (end - vibe_time)
print(f'VIBE FPS: {fps:.2f}')
total_time = time.time() - total_time
print(f'Total time spent: {total_time:.2f} seconds (including model loading time).')
print(f'Total FPS (including model loading time): {num_frames / total_time:.2f}.')
print(f'Saving output results to \"{os.path.join(output_path, "vibe_output.pkl")}\".')
joblib.dump(vibe_results, os.path.join(output_path, "vibe_output.pkl"))
if not args.no_render:
# ========= Render results as a single video ========= #
renderer = Renderer(resolution=(orig_width, orig_height), orig_img=True, wireframe=args.wireframe)
output_img_folder = f'{image_folder}_output'
os.makedirs(output_img_folder, exist_ok=True)
print(f'Rendering output video, writing frames to {output_img_folder}')
# prepare results for rendering
frame_results = prepare_rendering_results(vibe_results, num_frames)
mesh_color = {k: colorsys.hsv_to_rgb(np.random.rand(), 0.5, 1.0) for k in vibe_results.keys()}
image_file_names = sorted([
os.path.join(image_folder, x)
for x in os.listdir(image_folder)
if x.endswith('.png') or x.endswith('.jpg')
])
for frame_idx in tqdm(range(len(image_file_names))):
img_fname = image_file_names[frame_idx]
img = cv2.imread(img_fname)
if args.sideview:
side_img = np.zeros_like(img)
for person_id, person_data in frame_results[frame_idx].items():
frame_verts = person_data['verts']
frame_cam = person_data['cam']
mc = mesh_color[person_id]
mesh_filename = None
if args.save_obj:
mesh_folder = os.path.join(output_path, 'meshes', f'{person_id:04d}')
os.makedirs(mesh_folder, exist_ok=True)
mesh_filename = os.path.join(mesh_folder, f'{frame_idx:06d}.obj')
img = renderer.render(
img,
frame_verts,
cam=frame_cam,
color=mc,
mesh_filename=mesh_filename,
)
if args.sideview:
side_img = renderer.render(
side_img,
frame_verts,
cam=frame_cam,
color=mc,
angle=270,
axis=[0,1,0],
)
if args.sideview:
img = np.concatenate([img, side_img], axis=1)
cv2.imwrite(os.path.join(output_img_folder, f'{frame_idx:06d}.png'), img)
if args.display:
cv2.imshow('Video', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if args.display:
cv2.destroyAllWindows()
# ========= Save rendered video ========= #
vid_name = os.path.basename(video_file)
save_name = f'{vid_name.replace(".mp4", "")}_vibe_result.mp4'
save_name = os.path.join(output_path, save_name)
print(f'Saving result video to {save_name}')
images_to_video(img_folder=output_img_folder, output_vid_file=save_name)
shutil.rmtree(output_img_folder)
shutil.rmtree(image_folder)
print('================= END =================')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--vid_file', type=str,
help='input video path or youtube link')
parser.add_argument('--output_folder', type=str,
help='output folder to write results')
parser.add_argument('--tracking_method', type=str, default='bbox', choices=['bbox', 'pose'],
help='tracking method to calculate the tracklet of a subject from the input video')
parser.add_argument('--detector', type=str, default='yolo', choices=['yolo', 'maskrcnn'],
help='object detector to be used for bbox tracking')
parser.add_argument('--yolo_img_size', type=int, default=416,
help='input image size for yolo detector')
parser.add_argument('--tracker_batch_size', type=int, default=12,
help='batch size of object detector used for bbox tracking')
parser.add_argument('--staf_dir', type=str, default='/home/mkocabas/developments/openposetrack',
help='path to directory STAF pose tracking method installed.')
parser.add_argument('--vibe_batch_size', type=int, default=450,
help='batch size of VIBE')
parser.add_argument('--display', action='store_true',
help='visualize the results of each step during demo')
parser.add_argument('--run_smplify', action='store_true',
help='run smplify for refining the results, you need pose tracking to enable it')
parser.add_argument('--no_render', action='store_true',
help='disable final rendering of output video.')
parser.add_argument('--wireframe', action='store_true',
help='render all meshes as wireframes.')
parser.add_argument('--sideview', action='store_true',
help='render meshes from alternate viewpoint.')
parser.add_argument('--save_obj', action='store_true',
help='save results as .obj files.')
parser.add_argument('--smooth', action='store_true',
help='smooth the results to prevent jitter')
parser.add_argument('--smooth_min_cutoff', type=float, default=0.004,
help='one euro filter min cutoff. '
'Decreasing the minimum cutoff frequency decreases slow speed jitter')
parser.add_argument('--smooth_beta', type=float, default=0.7,
help='one euro filter beta. '
'Increasing the speed coefficient(beta) decreases speed lag.')
args = parser.parse_args()
main(args)效果展示:

总结
VIBE是一种基于视频的3D人体姿态和形状估计方法,通过引入时序编码器和对抗性训练,解决了单帧估计方法中存在的时序不一致性和动态运动捕捉不足等问题,显著提升了生成3D人体网格的逼真性和连贯性。其在3DPW、Human3.6M等数据集上达到了当时的最先进水平,尤其在长视频序列中表现优异。然而,VIBE对遮挡和复杂背景的鲁棒性不足,计算复杂度较高,且依赖大规模标注数据。未来可通过引入多模态信息、优化计算效率、探索自监督学习等方法进一步改进。VIBE的创新为3D人体姿态估计领域提供了重要参考,推动了虚拟现实、动作捕捉等应用的发展。

















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









