






Paper: https://arxiv.org/abs/2309.14611
Code: https://github.com/Event-AHU/EventVOT_Benchmark
Demo video: Demo video for EventVOT dataset - YouTube
Motivation
本文主要介绍了一种基于多尺度知识蒸馏的事件跟踪框架。现有的工作要么利用对齐的RGB和事件数据进行精确的跟踪,要么直接学习基于事件的跟踪器。第一类需要很高的推理成本,第二类可能很容易受到噪声事件或稀疏空间分辨率的影响。
为了解决上述问题,本文主要提出了一种新的多层次知识蒸馏框架称为HDETrack,该框架可以在训练过程中充分利用多模态/多视图信息来促进知识迁移,使得能够在测试过程中仅仅使用事件信号来实现高速和低延迟的视觉跟踪。具体来说,首先通过同时提供的RGB帧和事件流来训练一个基于教师Transformer的多模态跟踪框架。在此基础上,设计了一种新的层次知识蒸馏策略,包括两两相似性、特征表示和基于响应映射的知识蒸馏来指导学生Transformer网络的学习。
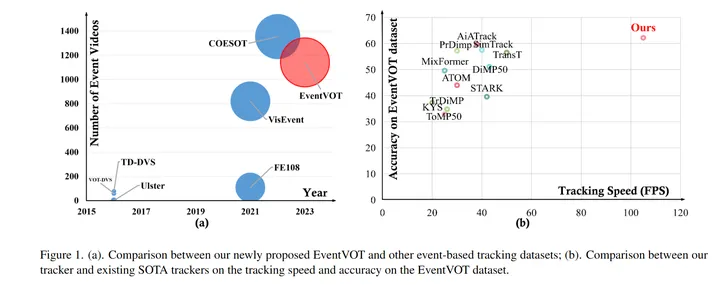
此外,由于现有的基于事件的跟踪数据集都是低分辨率的(346×260),本文提出了第一个大规模的高分辨率的(1280×720)数据集,命名为EventVOT。它包含了1141个视频,并涵盖了广泛的类别,如行人、车辆、无人机、乒乓球等。
最后,本文在低分辨率数据集(FE240hz,VisEvent,COESOT)和本文新提出的高分辨率EventVOT数据集上进行的大量实验,充分验证了所提出的方法的有效性。
Methodology
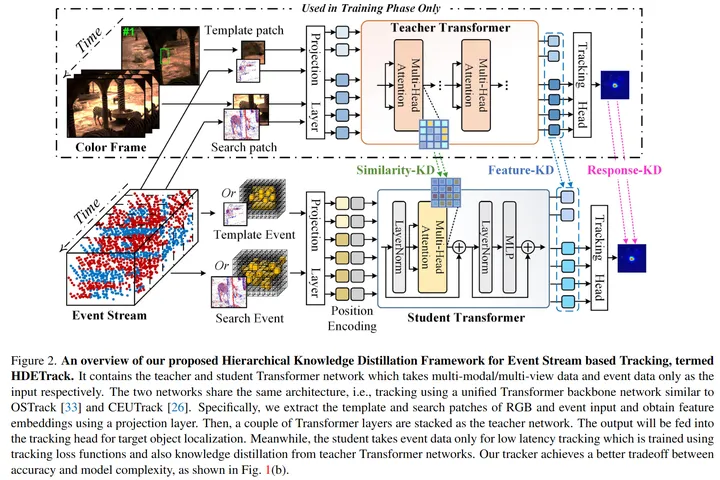
上图展示了HDETrack的框架图,其上半部分是教师的网络模型,仅在训练阶段使用,测试阶段使用下半部分的学生网络。HDETrack的训练分为两个阶段:
① 单独训练教师网络
第一阶段需要训练一个鲁棒的教师网络,通过输入RGB和事件流的双模态数据,利用Transformer作为骨干网络来提取特征并进行信息的交互和融合,Transformer的输出送入跟踪头来预测跟踪的响应结果。
② 训练学生网络并进行知识蒸馏
当第一阶段的教师网络训练完成之后,将教师网络学习好的网络参数冻结,来开始第二阶段学生网络的训练。第二阶段的训练是知识蒸馏的过程,教师网络输入的依然是RGB和事件流的双模态数据,学生网络输入的是单模态的事件数据(事件帧、Voxel、Time-surface、重构灰度图等数据形式),学生网络同样以Transformer作为骨干网络来提取特征,将输出的特征输入跟踪头预测跟踪结果。同时,通过三层知识蒸馏来利用教师网络的参数对学生网络的学习进行监督。
大规模高分辨率事件数据集EventVOT
本文提出了一个大规模的高分辨率(1280×720)事件跟踪数据集——EventVOT。该数据集共有1141个视频,包含19个类别和14个挑战属性,其目标物体的属性、类别和边界框中心点分布可视化效果图如下所示:
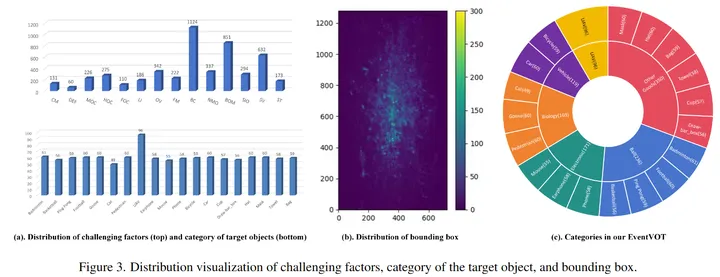
数据集的可视化样例
实验结果
除了新提出的EventVOT数据集外,本文还在现有的基于事件的跟踪数据集上与其他SOTA的视觉跟踪器进行了比较,包括FE240hz、VisEvent和COESOT数据集,实验结果如下:
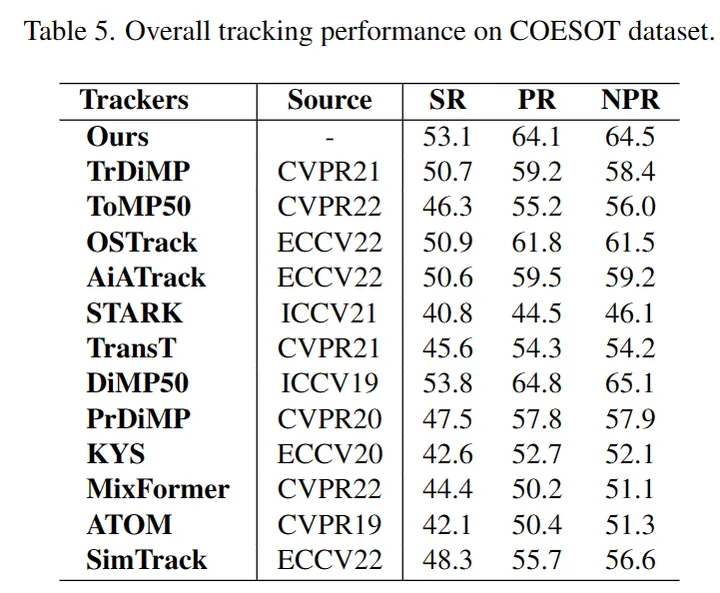
EventVOT
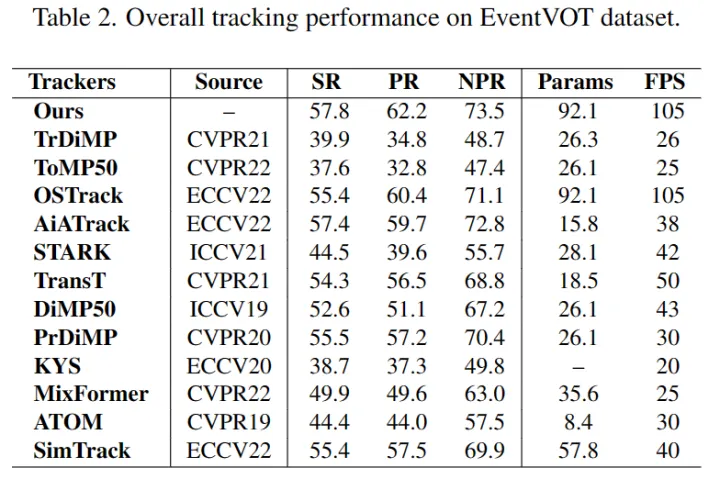
FE240hz
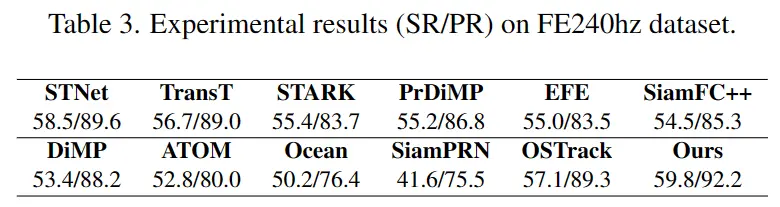
VisEvent
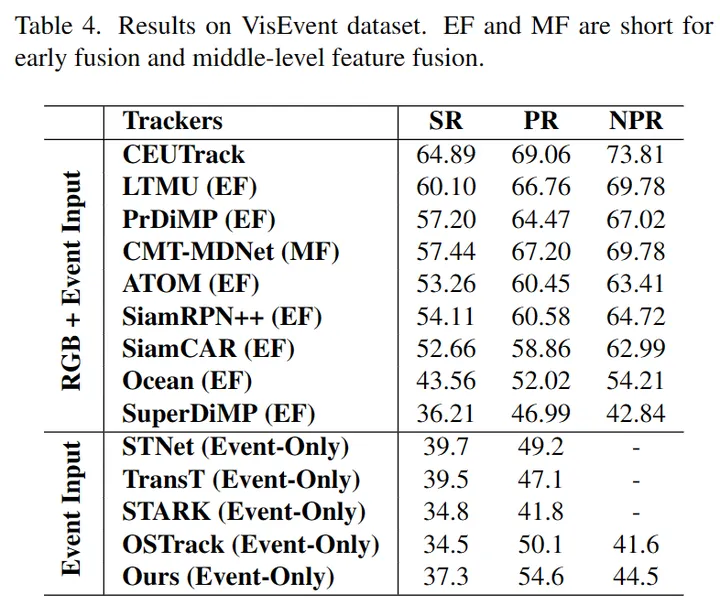
COESOT
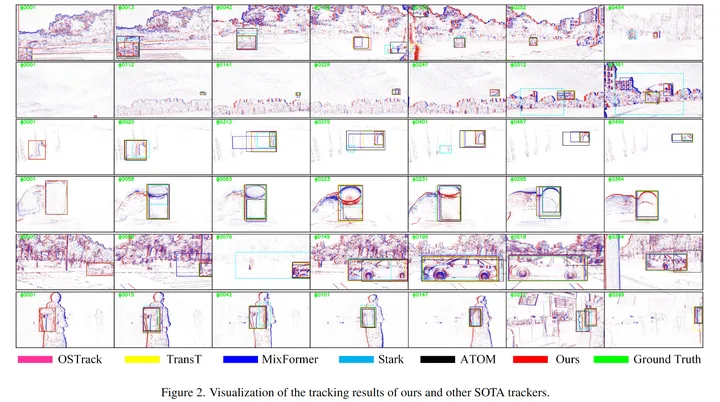
visualization

Reference
[1] Botao Ye, Hong Chang, Bingpeng Ma, and Shiguang Shan. Joint feature learning and relation modeling for tracking: one-stream framework. InEuropean Conference on ComputerVision, 2022.
[2] Chuanming Tang, Xiao Wang, Ju Huang, Bo Jiang, Lin Zhu,Jianlin Zhang, Yaowei Wang, and Yonghong Tian. Revisiting color-event based tracking: A unified network, dataset, and metric.arXiv preprint arXiv:2211.11010, 2022.
[3] Jiqing Zhang, Bo Dong, Haiwei Zhang, Jianchuan Ding, Felix Heide, Baocai Yin, and Xin Yang.Spiking transformers for event-based single object tracking. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 8801–8810, 2022
[4] Junfei Zhuang, Yuan Dong, and Hongliang Bai. Ensemble learning with siamese networks for visual tracking. Neuro-computing, 464:497–506, 2021.
[5] Xiao Wang, Jianing Li, Lin Zhu, Zhipeng Zhang, Zhe Chen, Xin Li, Yaowei Wang, Yonghong Tian, and Feng Wu. Visevent: Reliable object tracking via collaboration of frame and event flows.arXiv preprint arXiv:2108.05015, 2021.
其他事件跟踪工作
1.VisEvent: Reliable Object Tracking via Collaboration of Frame and Event Flows (Xiao Wang, Jianing Li, Lin Zhu, Zhipeng Zhang, Zhe Chen, Xin Li, Yaowei Wang, Yonghong Tian, Feng Wu)
Paper: https://arxiv.org/abs/2108.05015
Code: https://github.com/wangxiao5791509/VisEvent_SOT_Benchmark
Demo video: https://www.youtube.com/watch?v=U4uUjci9Gjc
2.Revisiting Color-Event based Tracking: A Unified Network, Dataset, and Metric (Chuanming Tang, Xiao Wang, Ju Huang, Bo Jiang, Lin Zhu, Jianlin Zhang, Yaowei Wang, Yonghong Tian)
Paper:https://arxiv.org/abs/2211.11010
Code: https://github.com/Event-AHU/COESOT/tree/main
Demo video: https://www.youtube.com/watch?

















 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









