







1、代码
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import torch
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(num_classes, pretrained=False, **kwargs):
"""VGG 11-layer model (configuration "A") with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['A'], batch_norm=True), num_classes, **kwargs)
if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['vgg11_bn']))
model.load_state_dict(torch.load("vgg11_bn-6002323d.pth"))
return model2、概念解读
(1)VGG概念
VGGNet是牛津大学视觉几何组提出的模型,并于2014ImageNet图像分类与定位挑战赛 ILSVRC-2014中取得在分类任务第二,定位任务第一的优异成绩。
VGGNet证明了很小的卷积,通过增加网络深度可以有效提高性能。
(2)VGG结构
weight layers只算了卷积层层数和全连接层层数,不计算池化层,因为池化层没有权重
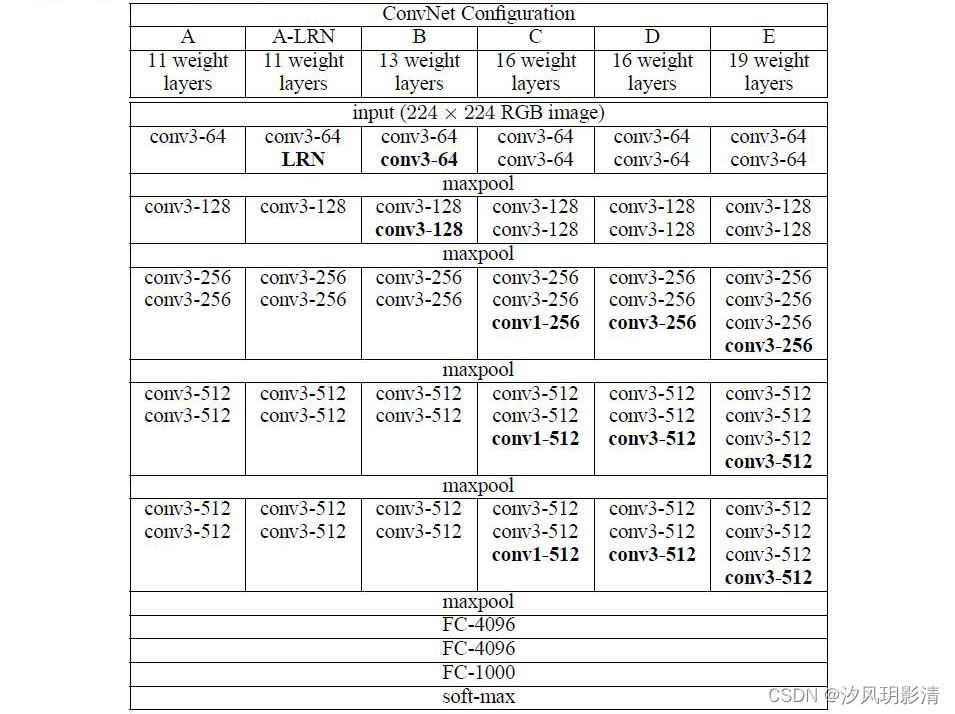
1)VGG11(A)
VGG11包含 11 层具有学习能力的层(8 个卷积层,3 个全连接层)。
卷积层配置[64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],数字表示卷积层的滤波器数量,'M' 表示最大池化层。
2)VGG13(B)
VGG13包含 13 层具有学习能力的层(10 个卷积层,3 个全连接层)。
卷积层配置:[64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
相比 VGG11,VGG13 在每个级别增加了一个卷积层
3)VGG16(C)
VGG16包含 16 层具有学习能力的层(13 个卷积层,3 个全连接层)。
卷积层配置:[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
相比 VGG13,VGG16 在第三、第四和第五个级别各增加了一个卷积层。
4)VGG19(D)
VGG19包含 19 层具有学习能力的层(16 个卷积层,3 个全连接层)。
卷积层配置:[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
相比 VGG16,VGG19 在第三、第四和第五个级别各增加了一个卷积层。
(3)VGG原理
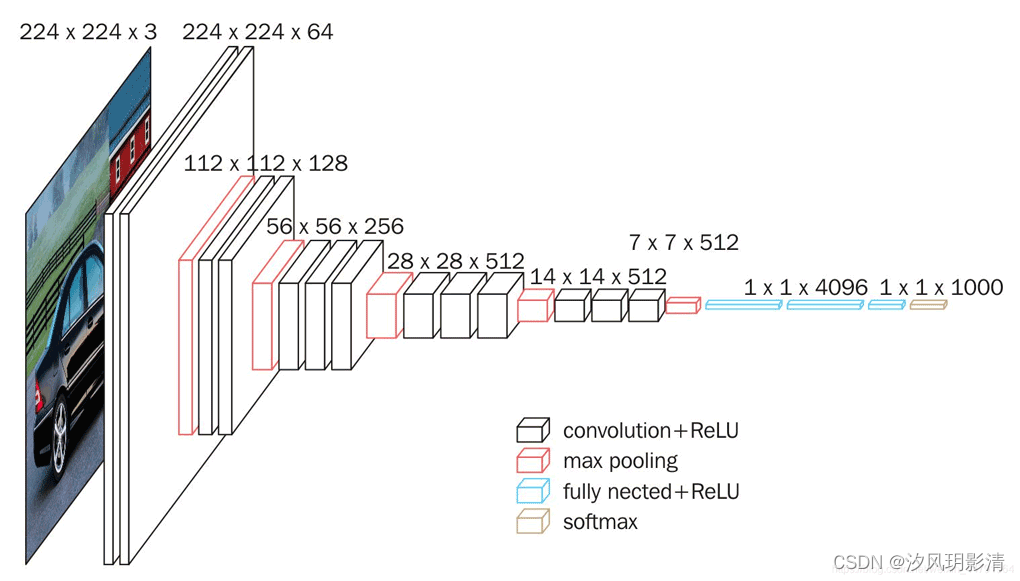
1)以长224宽224通道为3的图输入
2)经过第一个模块,得到长224宽224通道为64。随后经过池化层,长宽逐渐减半
3)经过第二个模块,得到长112宽112通道为128。随后再经过池化层,长款再次减半
......
4)到最后依次池化,得到7*7*512,然后经过三个全连接层,得到1*1*1000的分类结果
池化层作用:对输入特征图进行下采样来减少空间维度,同时保留重要特征信息。
3、代码解读
(1)VGG预训练模型
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
_all_列表定义了所有VGG模型及其变体(带有批归一化版本)
model_urls字典用于存储不同的VGG模型变体的预训练权重的下载链接。
加载模型时可以使用这些URL来自动下载并加载预训练权重,也可以提前下载。
(2)VGG网络框架
1)class VGG(nn.Module):
class VGG(nn.Module):
标准的类定义,继承自nn.Module
2)构造函数_init_
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x(i)def __init__(self, features, num_classes=1000, init_weights=True):
构造函数初始化类实例时调用。
参数features是由卷积层和池化层组成的序列,通常通过辅助函数生成
参数num_classes是输出类别的数量,默认值为1000
参数init_weights决定是否初始化权重,默认为True
(ii)super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
super(VGG, self).__init__()调用父类 nn.Module 的构造函数。
self.features 存储卷积层和池化层的组合。
self.avgpool 是一个自适应平均池化层,将输入特征图调整到 7x7 大小。
(iii)def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
forward 方法定义了数据通过网络的前向传播过程。
首先,将输入 x 传递给 self.features,执行卷积和池化操作。
然后,执行平均池化并调整特征图的大小。
使用 view 方法将特征图展平为二维张量,以便输入全连接层。
展平为二维张量例子:
通常在卷积神经网络中,特征图的形状为 (batch_size, num_channels, height, width)。例如,假设我们有一个大小为 (10, 512, 7, 7) 的特征图,表示批量大小为 10,每个样本有 512 个通道,每个通道的空间大小为 7x7。
x.size(0) 获取批量大小,这里是 10。-1 表示将剩余的维度展平为一维。对于我们的例子,(10, 512, 7, 7) 会被展平成 (10, 512 * 7 * 7),即 (10, 25088)。这样,每个样本的特征图就变成了一个长度为 25088 的向量,整个批量形成一个大小为 (10, 25088) 的二维张量。
最后,将展平的张量传递给 self.classifier 进行分类。
3)权重初始化
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
_initialize_weights 方法用于初始化神经网络中不同层的权重和偏差
(i)for m in self.modules():
self.modules() 是一个生成器,它会遍历模型中的所有子模块,包括卷积层、批归一化层和全连接层等
(ii)if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
对卷积层的权重使用 Kaiming 正态初始化(也称为 He 初始化)。这种方法适用于具有 ReLU 激活函数的网络。
mode='fan_out': 计算输出通道数的方差。
nonlinearity='relu': 指定非线性激活函数为 ReLU。
偏差初始化: 如果卷积层有偏差项,将其初始化为零。
(iii)elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
权重初始化将批归一化层的权重初始化为 1。
偏差初始化将批归一化层的偏差初始化为 0。
(iv)elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
正态分布初始化对全连接层的权重使用均值为 0、标准差为 0.01 的正态分布进行初始化。
偏差初始化将全连接层的偏差初始化为 0。
(3)构建卷积神经网络的层
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}1)参数说明
cfg是一个列表,指定每一层的输出通道数或池化操作。例如,[64, 'M', 128, 'M', 256, 256, 'M'] 表示构建的网络包含以下层序列:
卷积层,输出通道数 64
最大池化层
卷积层,输出通道数 128
最大池化层
卷积层,输出通道数 256
卷积层,输出通道数 256
最大池化层
batch_norm是布尔值,指示是否在每个卷积层后添加批归一化层。默认值为 False
2)函数逻辑
(i)layers = []
in_channels = 3
layers 用于存储各层的列表。
in_channels 初始值为 3,表示输入图像的通道数(RGB 图像)。
(ii)for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
如果 v 是 'M',则添加一个最大池化层,kernel_size=2 和 stride=2,减半特征图的尺寸。
(iii)else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
创建一个输入通道数为 in_channels,输出通道数为 v,卷积核大小为 3,填充为 1,使得输出尺寸与输入相同。
根据 batch_norm 的值决定是否添加批归一化层。如果 batch_norm 为 True,则在卷积层后添加批归一化层和 ReLU 激活函数。否则,仅添加卷积层和 ReLU 激活函数。
(4)VGG11示范代码
def vgg(num_classes, pretrained=False, **kwargs):
"""VGG 11-layer model (configuration "A") with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['A'], batch_norm=True), num_classes, **kwargs)
if pretrained:
# model.load_state_dict(model_zoo.load_url(model_urls['vgg11_bn']))
model.load_state_dict(torch.load("vgg11_bn-6002323d.pth"))
return model如果 pretrained 为 True,则将 kwargs 字典中的 init_weights 键设置为 False,以便在后面加载预训练权重时不再初始化模型的权重。
model = VGG(make_layers(cfg['A'], batch_norm=True), num_classes, **kwargs)
调用 make-layers函数使用配置 'A' 构建卷积层。
或者是根据下载的预训练模型进行训练

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









