







 本文详细介绍了VGG网络模型,包括其由来、原理和与AlexNet的区别。重点解析了VGG-16和VGG-19的结构,并提供了详细的卷积层配置。此外,还展示了代码实现的概要,用于图像预测。
本文详细介绍了VGG网络模型,包括其由来、原理和与AlexNet的区别。重点解析了VGG-16和VGG-19的结构,并提供了详细的卷积层配置。此外,还展示了代码实现的概要,用于图像预测。
VGG网络模型详解以及代码实现
一、背景
VGGNet是在2014年由Karen Simonyan和Andrew Zisserman提出的,网络模型包括VGG-11、VGG-13、VGG-16以及VGG-19,其中VGG-16和VGG-19在分类和定位任务上效果最好,因此作者在2014年ImageNet Challenge上获得分类第二和定位第一的网络。
论文地址:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNIT
1. VGG原理
VGG与AlexNet相比,它是将AlexNet模型中较大的卷积核(例如:11 x 11、7 x 7、5 x 5)换成连续几个3 x 3的卷积核。其目的是:减少网络参数量;由于参数量被大幅减小,于是可以用多个感受野小的卷积层替换掉之前一个感受野大的卷积层,从而增加网络的非线性表达能力。
例如:两个3x3的卷积层的感受野可以代替一个5x5的卷积层,三个3x3的卷积层可以代替一个7x7的卷积层,这样可以有效地减少参数计算成本。假设输入输出channel均为C,三个3x3参数个数为3x(3x3xCxC)=27xC²,一个7x7参数个数为7x7xCxC=49xC²,因此用三个3x3的卷积层代替一个7x7的卷积层可以节省近一半的参数计算量。
二、VGG网络模型详解及代码实现
1. VGG网络模型详解
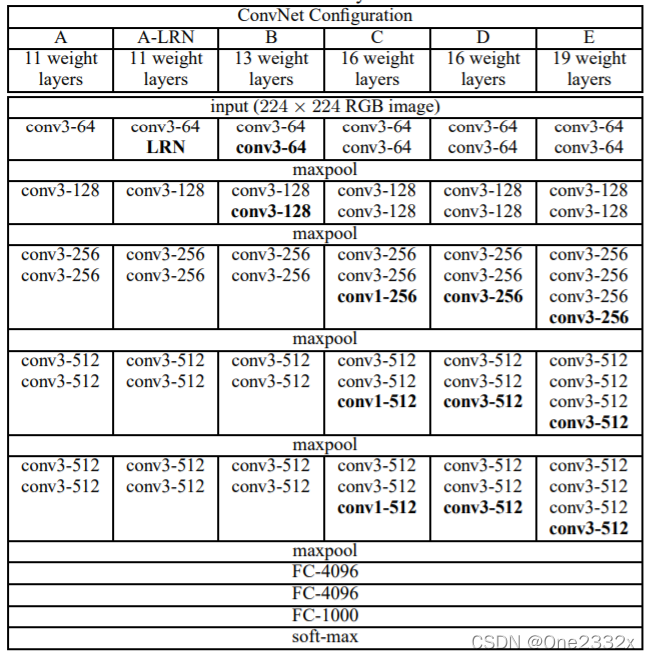
VGG-16和VGG-19如上图的D和E所示:
VGG-16:包括16个隐藏层(13个卷积层和3个全连接层)
VGG-19:包括19个隐藏层(16个卷积层和3个全连接层)
以VGG-16为例,如下图所示:
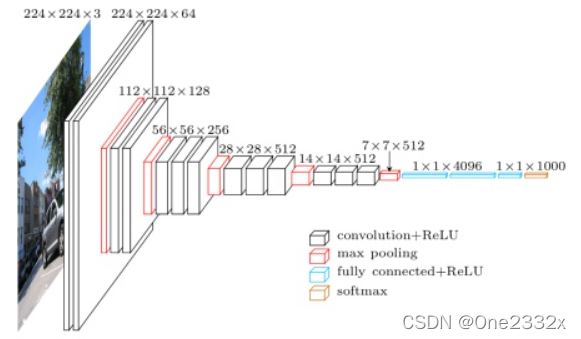
详细过程为:
block1:
- Conv1
- 输入图像大小:224 * 224 * 3 (RGB图像)
- 卷积核(filter)大小:3 * 3
- 卷积核个数:64
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:224 * 224 * 64
- Conv2
- 输入图像大小:224 * 224 * 64
- 卷积核(filter)大小:3 * 3
- 卷积核个数:64
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:224 * 224 * 64
- Pool1
- 输入图像大小:224 * 224 * 64
- 采样大小:2 * 2
- padding方式:SAME
- 输出图像大小:112 * 112 * 64
block2:
- Conv3
- 输入图像大小:112 * 112 * 64
- 卷积核(filter)大小:3 * 3
- 卷积核个数:128
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:112 * 112 * 128
- Conv4
- 输入图像大小:112 * 112 * 64
- 卷积核(filter)大小:3 * 3
- 卷积核个数:128
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:112 * 112 * 128
- Pool2
- 输入图像大小:112 * 112 * 128
- 采样大小:2 * 2
- padding方式:SAME
- 输出图像大小:56 * 56 * 128
block3:
- Conv5
- 输入图像大小:56 * 56 * 128
- 卷积核(filter)大小:3 * 3
- 卷积核个数:256
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:56 * 56 * 256
- Conv6
- 输入图像大小:56 * 56 * 256
- 卷积核(filter)大小:3 * 3
- 卷积核个数:256
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:56 * 56 * 256
- Conv7
- 输入图像大小:56 * 56 * 256
- 卷积核(filter)大小:3 * 3
- 卷积核个数:256
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:56 * 56 * 256
- Pool3
- 输入图像大小:56 * 56* 256
- 采样大小:2 * 2
- padding方式:SAME
- 输出图像大小:28 * 28 * 256
block4:
- Conv8
- 输入图像大小:28 * 28 * 256
- 卷积核(filter)大小:3 * 3
- 卷积核个数:512
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:28 * 28 * 512
- Conv9
- 输入图像大小:28 * 28 * 512
- 卷积核(filter)大小:3 * 3
- 卷积核个数:512
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:28 * 28 * 512
- Conv10
- 输入图像大小:28 * 28 * 512
- 卷积核(filter)大小:3 * 3
- 卷积核个数:512
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:28 * 28 * 512
- Pool4
- 输入图像大小:28 * 28 * 512
- 采样大小:2 * 2
- padding方式:SAME
- 输出图像大小:14 * 14 * 512
block5:
- Conv11
- 输入图像大小:14 * 14 * 512
- 卷积核(filter)大小:3 * 3
- 卷积核个数:512
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:14 * 14 * 512
- Conv12
- 输入图像大小:14 * 14 * 512
- 卷积核(filter)大小:3 * 3
- 卷积核个数:512
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:14 * 14 * 512
- Conv13
- 输入图像大小:14 * 14 * 512
- 卷积核(filter)大小:3 * 3
- 卷积核个数:512
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:14 * 14 * 512
- Pool5
- 输入图像大小:14 * 14 * 512
- 采样大小:2 * 2
- padding方式:SAME
- 输出图像大小:7 * 7* 512
最后三层全连接层和AlexNet最后三层相同,可以参考博客:AlexNet模型详解及代码实现
2. 代码实现
import matplotlib.pyplot as plt
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
impor 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1361
1361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









