






Abstract: 多模态基于方面的情感分析(MABSA)是一项细粒度的任务,主要关注于识别文本-图像对中的方面级情感信息。然而,我们观察到,在低质量的样本中很难识别方面的情感,例如那些低分辨率的图像往往包含噪声。而在现实世界中,数据的质量通常因样本的不同而不同,这种噪声称为数据的不确定性。但以往的MABSA任务对不同质量样本的重视程度相同,忽略了数据不确定性的影响。本文提出了一种新的基于数据不确定性的多模态情感分析方法UA-MABSA,该方法根据数据质量和难度对不同样本的损失进行加权。UA-MABSA采用了一种新颖的质量评估策略,同时考虑了图像质量和基于方面的跨模态相关性,从而使模型能够更多地关注高质量和具有挑战性的样本。
一、关键点
1.MABSA
MABSA(Multimodal Aspect-Based Sentiment Analysis)指的是多模态基于方面的情感分析。这是一种情感分析方法,旨在从图像和文本的组合中识别和分析特定方面的情感信息。与传统的情感分析方法不同,MABSA不仅关注整体情感,还专注于从多模态数据中提取细粒度的情感信息,特别是与特定方面(如产品特性、服务质量等)相关的情感。
在MABSA中,研究者通常会处理三个子任务:
-
多模态方面术语提取:从文本和图像中识别出与特定方面相关的术语。
-
多模态方面情感分类:根据提取的方面信息,判断文本和图像中表达的情感。
-
联合多模态基于方面的情感分析:同时考虑文本和图像数据,进行综合分析。
MABSA的挑战在于如何有效地整合来自不同模态(如文本和图像)的信息,并处理数据的不确定性和质量问题。
2.数据的不确定性
文中提到的数据不确定性是指在多模态数据(如图像和文本)中,由于样本质量的差异和噪声的存在,导致模型在学习和识别情感时面临的挑战。具体来说,数据不确定性可以理解为以下几个方面:
-
样本质量差异:在真实世界中,收集到的多模态数据往往存在质量不均的问题。例如,某些图像可能分辨率低、模糊不清,或者文本内容可能含糊不清,这些低质量样本会增加模型学习的难度。
-
噪声影响:低质量样本可能包含噪声,这些噪声会误导模型,使其无法准确识别情感。例如,图像中的某些特征可能难以识别,导致模型无法有效地将图像和文本中的情感信息进行对齐。
-
跨模态对齐的挑战:在多模态情感分析中,模型需要将图像和文本的信息进行有效结合。数据不确定性使得这一过程更加复杂,因为低质量样本可能导致模型学习到的跨模态对齐关系不准确。
-
重要性加权:UA-MABSA方法通过引入数据不确定性评估,能够对不同样本的重要性进行加权,优先关注高质量和具有挑战性的样本,从而提高模型的整体性能。
总之,数据不确定性反映了在多模态情感分析中,由于样本质量的变化和噪声的存在,模型面临的学习和识别情感的困难。通过对数据不确定性的建模,可以更好地处理这些问题,提高情感分析的准确性和鲁棒性。
3.基于方面的跨模态相关性
基于方面的跨模态相关性指的是在多模态情感分析中,如何有效地将不同模态(如图像和文本)之间的相关信息进行整合,以便更好地理解和分析特定方面的情感。这种相关性主要体现在以下几个方面:
-
方面定义:在情感分析中,"方面"通常指的是特定的主题或特征,例如在餐厅评论中,"食物"、"服务"和"环境"等都是不同的方面。跨模态相关性关注的是如何将图像(如餐厅的照片)与文本(如评论内容)中提到的方面进行有效的关联。
-
信息对齐:跨模态相关性涉及到如何将图像中的视觉信息与文本中的语言信息进行对齐。例如,图像中展示的食物的外观和文本中描述的食物的味道、质量等信息需要被有效结合,以便更准确地判断该方面的情感。
-
情感线索挖掘:在多模态情感分析中,图像和文本可能分别提供不同的情感线索。通过挖掘这些线索并理解它们之间的相关性,可以更全面地评估特定方面的情感。例如,图像中愉快的顾客表情可能与文本中对服务的积极评价相互支持。
-
弱监督学习:由于在许多多模态数据集中,图像和文本之间的对应关系可能并不明确,因此基于方面的跨模态相关性也面临弱监督的挑战。模型需要在缺乏明确标注的情况下,学习如何从图像和文本中提取和对齐信息。
-
数据不确定性:在考虑跨模态相关性时,数据的不确定性也扮演着重要角色。低质量的图像或模糊的文本可能会影响模型对跨模态信息的理解和整合。因此,评估和管理这种不确定性对于提高模型的性能至关重要。
综上所述,基于方面的跨模态相关性是多模态情感分析中的一个核心挑战,旨在通过有效整合图像和文本信息,以便更准确地分析和理解特定方面的情感。
二、Introduction
1.细粒度多模态情感分析
细粒度多模态情感分析旨在从图像-文本对中选择细粒度的方面,并确定它们的情感极性。这里的“细粒度”指的是分析的深度和具体性,不仅仅是对整体情感的判断,而是对特定方面(如产品的某个特征、服务的某个方面等)的情感评估。
以前的研究通常将细粒度多模态情感分析分为三个子任务,包括多模态方面项提取、多模态方面情感分类、联合多模态面向情感分析。
以往的研究在细粒度多模态情感分析方面取得了令人印象深刻的成果,但忽略了数据不确定性的影响。由于多模态数据采集自现实开放域,跨模态对齐监督较弱,低质量样本导致的数据不确定性将进一步加大跨模态对齐监督学习的难度。这对为真实世界的多模态数据构建多模态细粒度情感分析系统产生了负面影响。
2.细粒度多模态情感分析系统
集成的细粒度多模态情感分析系统可以分为四个阶段:
-
数据获取:这一阶段的目标是从真实社交媒体中收集和选择具有情感倾向的图像-文本对。数据的质量和相关性对于后续分析至关重要。
-
方面提取:在这一阶段,系统需要识别文本内容中的细粒度方面。这涉及到对文本进行分析,以找出与情感相关的具体特征或主题。
-
基于方面的情感分析:这一阶段的目标是基于多模态内容预测提取的方面的情感极性。也就是说,系统需要判断每个方面是积极、消极还是中性,这通常需要结合图像和文本的信息。
-
情感应用:最后,系统利用预测的方面-情感对进行社交媒体分析、推荐系统等相关应用。这一阶段强调了情感分析结果的实际应用价值。
3.数据的多样性和过滤方法
从不可控的开放领域收集的图像-文本对数据展示了显著的变异性。这意味着数据的质量和内容可能差异很大,因此需要在数据获取阶段应用一些过滤方法,例如过滤掉包含长文本或多张图像的样本,以确保后续分析的有效性。
然而,现有的方法忽略了由可变性引起的数据不确定性问题,低视觉可识别度的样本误导模型学习更多的偏差而不是跨模态交互:
-
数据可变性:
数据可变性指的是在现实世界中收集的数据往往具有不同的质量和特征。例如,某些图像可能模糊、低分辨率,或者与文本内容的关联性较弱。这种可变性使得数据的整体质量不均衡。
-
低视觉可识别度的样本:
低视觉可识别度的样本是指那些图像内容不清晰或难以辨认的样本。这些样本可能包含模糊的图像或不相关的视觉信息,使得模型在分析这些样本时面临挑战。
-
误导模型学习偏差:
当模型在训练过程中遇到这些低质量样本时,它可能会受到误导,导致其学习到的特征和模式偏向于这些不准确或不相关的信息。这种偏差会影响模型的整体性能,使其在处理更高质量的样本时表现不佳。
-
跨模态交互的缺失:
跨模态交互是指在多模态分析中,如何有效地结合和利用不同模态(如图像和文本)之间的信息。如果模型无法准确识别和理解低质量样本中的视觉信息,它就无法有效地进行跨模态的学习和推理。这意味着模型可能无法充分利用图像和文本之间的关联性,从而影响情感分析的准确性。

如图所示,示例(c)中的视觉内容难以识别,但被视为与示例(a)中的图像相同,由于模型也无法从文本内容中独立识别情感,因此引入了噪声。因此,我们建议引入数据不确定性评估来进行估计多模态细粒度情感分析数据的质量,降低了数据不确定性带来的噪声。
4.我们的方法
我们提出了两个原则来评估多模态情感样本的质量:
(1)考虑影响图像质量的因素;(2)考虑细粒度多模态信息的相关性。提出了一种数据不确定性感知方法UA-MABSA。UA-MABSA综合考虑了基于视觉模糊度的样本质量评价、图像与文本的相关性、图像与方面的细粒度信息相关性,并将它们结合在一个统一的损失函数中。UA-MABSA根据样本质量自适应地改变损失函数中的权重,对不同困难度的样本赋予不同的重要性。
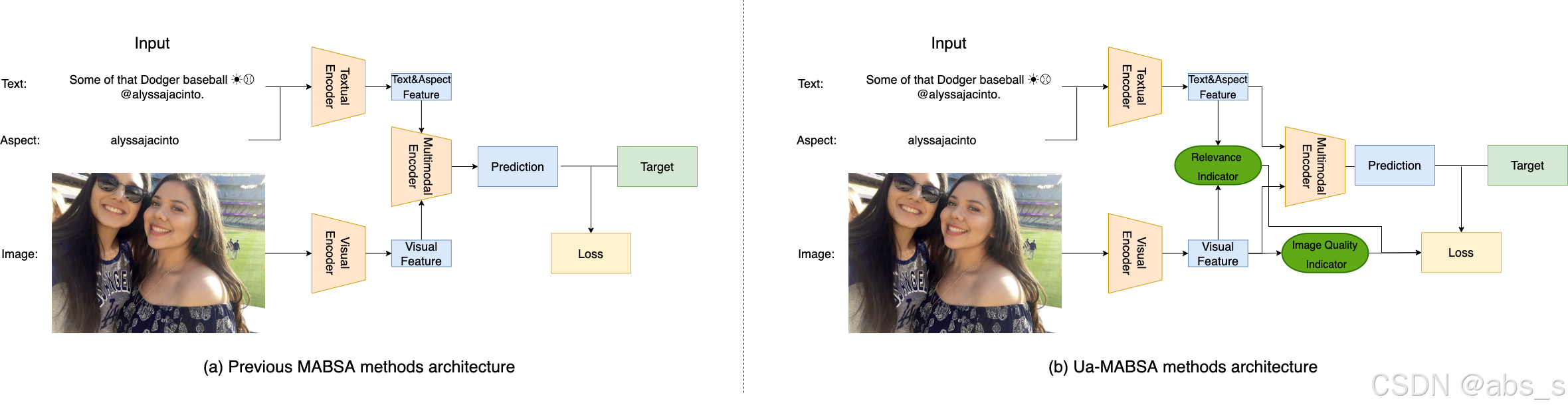
以前的MABSA方法结构与UA-MABSA方法结构:(a)单模态编码器和跨模态编码器的以前的MABSA方法结构。(b) UA-MABSA方法结构,根据图像质量、图像-文本相关性和方面-图像相关性调整损失权重。
5.我们的贡献
(1)我们首次从细粒度的角度探讨了数据的不确定性和质量问题多模态情感分析任务。
(2)我们通过广泛的实验验证了一组影响多模态数据质量的因素。我们提出了一种样本质量评估策略,该策略同时考虑了图像质量和基于方面的跨模式相关性,用于多模式基于方面的情感分析。
(3)我们提出了UA-MABSA方法,该方法采用了本文提出的质量评估策略,有效地防止了模型过拟合。
三、Method
1、概述
多模态基于方面的情感分析侧重于从开放域图像-文本对数据中学习跨模态细粒度情感语义。以往的研究提出,该任务面临两个核心挑战:(1)挖掘和利用视觉情感线索。(2)文本对数据弱监督下的跨模态细粒度对齐。我们认为,多模态数据的不确定性也是该任务的核心挑战之一。在实际应用中,多模态数据中的噪声是不可避免的,它会严重影响MABSA模型的性能。数据的不确定性会直接导致视觉模态信息挖掘效果不佳,并在跨模态细粒度对齐学习阶段引入大量噪声。因此,有必要在多模态细粒度情感分析模型中引入数据不确定性评估。
在分析多模态细粒度情感分析数据特征的基础上,我们提出了数据不确定性感知的多模态面向情感分析(UA-MABSA)模型。UA-MABSA模型包括三个部分:图像质量评估、相关性评估和骨干模型。
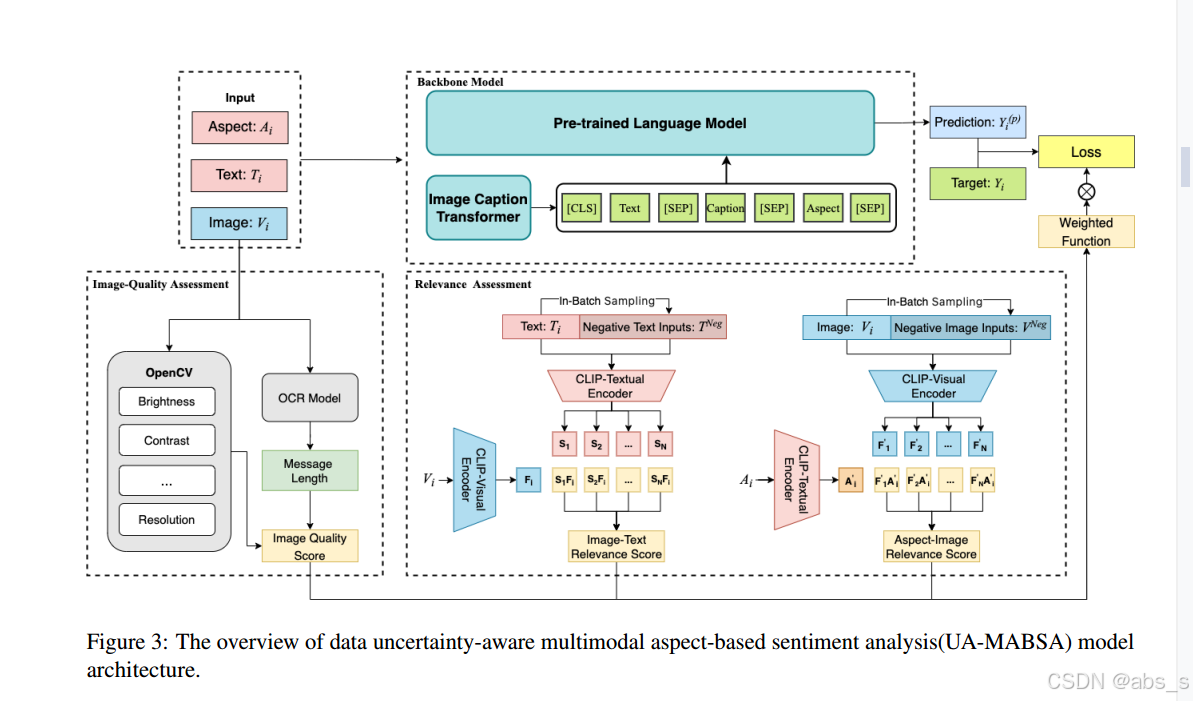
2、各部分说明
1.图像质量评估
图像质量评分:使用OpenCV工具评估图像的多个质量因素,如亮度、对比度、清晰度、色彩一致性和分辨率。通过设定分辨率阈值,计算图像的分辨率评分。
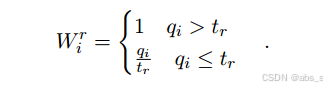 分辨率设定阈值评分
分辨率设定阈值评分
文本信息评估:通过OCR工具识别图像中的文本信息,并根据文本长度来评估图像质量。设定一个文本长度阈值,以此来计算文本信息的评分。
在现有的MABSA模型中,图像中的文本信息被视为额外的噪声。我们通过OCR工具(PaddleOCR2)识别图像中的文本信息,但实验表明,OCR识别的文本信息并没有显著提高MABSA任务的有效性。
因此,我们只使用图像中文本信息的长度作为衡量图像质量的一个因素。计算图像中文本信息得分的公式如下:
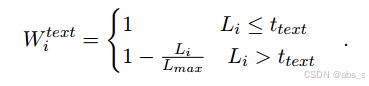
综合评分计算:综合考虑各个因素的评分,计算出一个综合的图像质量评分,以便更好地反映图像的整体质量。
2.相关性评估
粗粒度相关性评估:该方法主要关注图像与文本之间的整体相关性。通过计算图像和文本的余弦相似度来评估它们的关联程度。使用CLIP模型的单模态编码器提取图像和文本特征,并进行L2归一化,以获得粗粒度的相关性评分。这种评估方法能够识别图像和文本之间的基本关系,帮助判断样本的质量。
细粒度相关性评估:该方法关注图像与文本中具体方面(aspect)之间的相关性。由于每个样本的文本内容可能包含多个方面,但并非所有方面都出现在图像中,因此不同方面对额外视觉信息的需求是不同的。细粒度相关性评估通过CLIP模型计算每个方面与图像之间的相关性评分,从而避免以往方法对不同方面赋予相同权重所导致的偏差。
综合考虑:本文提出的相关性评估方法综合考虑了图像与文本的关系以及文本中各个方面的信息,旨在提高多模态情感分析任务的准确性和有效性。
3.骨架模型
本文的Backbone Model受到CapBERT和FITE的设计启发,采用了Caption Transformer将图像转换为标题,以克服不同模态之间的语义差距。为了实现文本模态中的充分交互,模型将图像标题与文本和目标方面连接在一起,形成一个新的句子。然后,将这个新句子输入到预训练的语言模型中,并对模型进行微调,以获得用于基于方面的情感分类的池化输出。模型使用标准的交叉熵损失进行参数优化,并在计算损失时引入基于图像质量评分和相关性评分的权重,以获得不确定性感知损失,使模型对高质量和具有挑战性的样本更敏感。
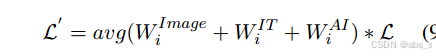
四、实验
1.数据集:实验使用了Twitter-2015和Twitter-2017两个数据集,这些数据集包含了标注了情感极性和目标方面的多模态推文。每个推文由一张图像和包含目标方面的文本组成。
 2.实验设置:模型的学习率设置为5e-5,使用12个注意力头,dropout率为0.1,批量大小为16,微调的周期为8,最大文本长度为256。所有模型在两个NVIDIA Tesla V100 GPU上基于PyTorch实现,并报告了5次独立训练的平均结果。
2.实验设置:模型的学习率设置为5e-5,使用12个注意力头,dropout率为0.1,批量大小为16,微调的周期为8,最大文本长度为256。所有模型在两个NVIDIA Tesla V100 GPU上基于PyTorch实现,并报告了5次独立训练的平均结果。
3.对比基线:实验中将UA-MABSA模型与多种基线模型进行比较,包括图像单一模型(Res-Target)和文本单一模型(LSTM、MGAM等),并报告了准确率和Macro-F1分数。
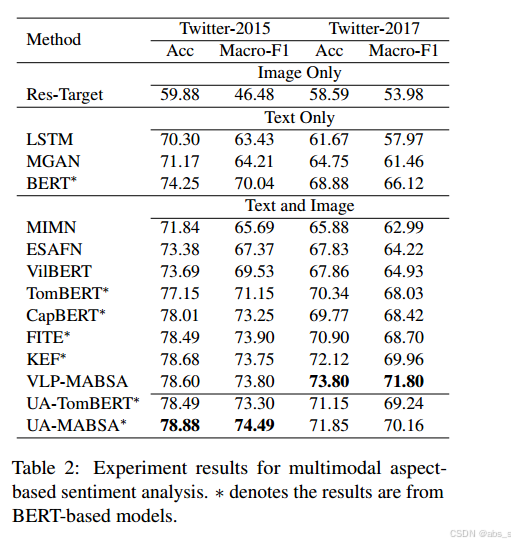
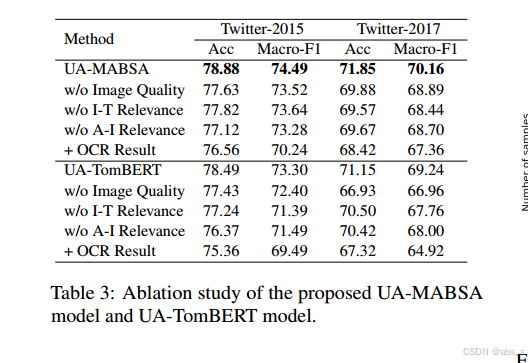
4.实验结果:实验结果表明,UA-MABSA在多模态基于方面的情感分析任务上达到了最先进的性能,有效防止了模型对低质量噪声样本的过拟合。此外,消融实验验证了不同质量评估策略的有效性。
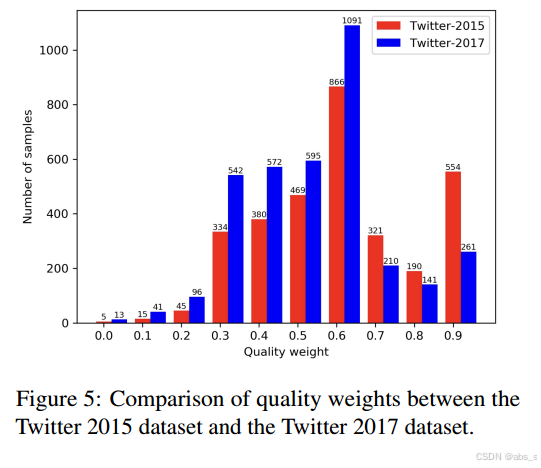
5.数据质量分析:通过分析数据质量,发现大多数样本的质量评分在0.3到0.7之间,模型能够有效捕捉数据集中的不确定性,并根据样本质量调整模型的注意力。
五、总结
-
提出的模型:本文提出了一种新的多模态基于方面的情感分析方法UA-MABSA,该方法有效地考虑了数据的不确定性和样本质量问题。
-
创新贡献:UA-MABSA首次探索了在细粒度多模态情感分析任务中数据不确定性和质量问题,并通过实验验证了一系列影响多模态数据质量的因素。
-
实验结果:实验结果表明,UA-MABSA在Twitter-2015和Twitter-2017数据集上实现了最先进的性能,证明了引入数据不确定性能够显著提高多模态细粒度情感分析系统的鲁棒性和解释性


















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









