






 本文介绍了如何利用YOLOv5的最新版本进行分类任务,特别是针对遥感图像中的大豆成熟度阶段。首先,无需额外标注,只需按类别创建文件夹即可构建数据集。接着,在Kaggle环境中,通过上传代码和数据集,利用GPU资源进行模型训练。文章提到了YOLOv5s模型的适用性,并展示了使用wandb进行结果可视化和监控。最后,文章涵盖了训练过程、验证步骤以及混淆矩阵的生成,以评估模型性能。
本文介绍了如何利用YOLOv5的最新版本进行分类任务,特别是针对遥感图像中的大豆成熟度阶段。首先,无需额外标注,只需按类别创建文件夹即可构建数据集。接着,在Kaggle环境中,通过上传代码和数据集,利用GPU资源进行模型训练。文章提到了YOLOv5s模型的适用性,并展示了使用wandb进行结果可视化和监控。最后,文章涵盖了训练过程、验证步骤以及混淆矩阵的生成,以评估模型性能。
构建YOLOv5分类数据集
YOLO即You Only Look Once,YOLOv5最初是著名的目标检测算法,但是从2022年8月更新的YOLOv5 v6.2版本开始支持分类功能,分类用到的代码主要在classify文件夹下。
YOLOv5代码下载地址https://github.com/ultralytics/yolov5,直接全部下载下来,不需要修改代码配置,上传到Kaggle中.
当然也可以直接在Kaggle中使用命令行下载代码。先初始化!git init,再clone 项目!git clone https://github.com/ultralytics/yolov5.git
下面是官方文档给出的YOLOv5分类方法和其它几种分类方法的准确率,可以看出YOLOv5x-cls模型具有最高的准确率,从n到x表示模型越来越大,准确率也是越来越高,相应的训练时间也就越长,训练出来的模型也越大,一般情况下使用s模型就可以满足大部分分类要求,有些情况下使用过度复杂的模型很容易造成过拟合。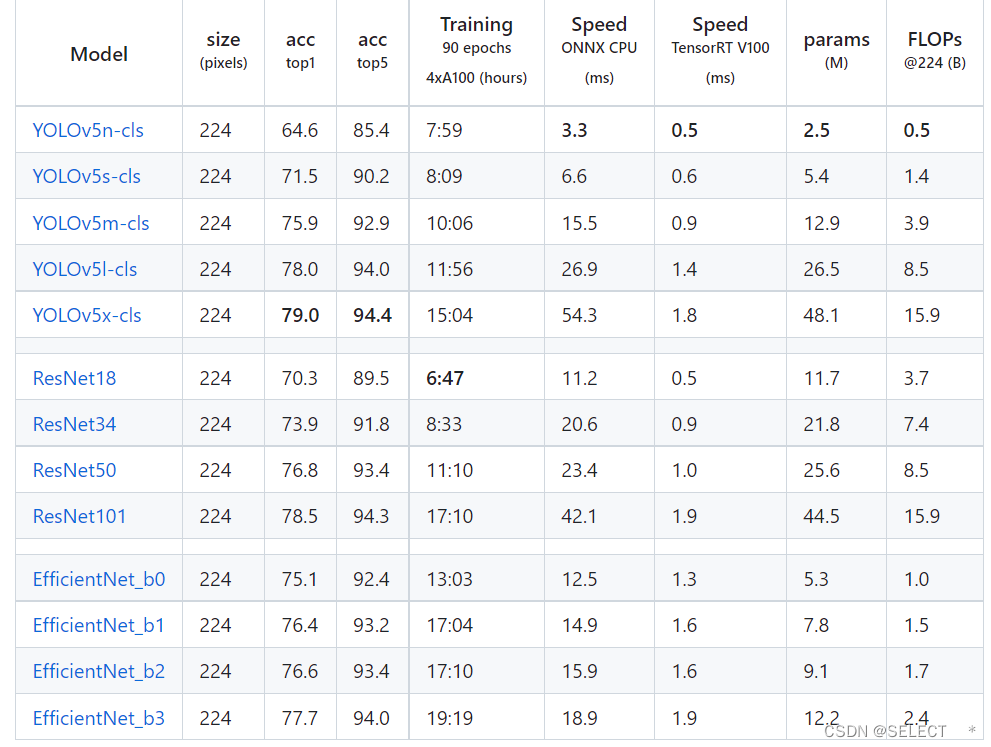
本文以大豆遥感图片为分类对象,建立不同成熟度时期的大豆数据集,大豆不同生长时期的照片如图所示,L0,L1,L2,L3分别代表未成熟,接近成熟,已成熟和已收割时期的大豆遥感地块图像。

YOLOv5的分类模型数据集构建不需要labelimg进行标注,直接按类别建立文件夹就可以,如图所示
train代表训练集,test代表验证集,用来在训练的过程中对模型进行测试,防止过拟合。YOLOv5的分类模型只需要train和test就可以训练了,这里的val是在训练结束后验证模型在独立的数据集上的准确度,以验证模型的泛化能力。上面每个文件夹内都建立四个类别
L0如图所示
最后再提醒一下,分类数据集的构建不需要建立txt,不需要labelimg,直接按类别建立文件夹,最后输入train和test的上一级文件夹进行训练。
在Kaggle上传自己的数据集和代码
使用kaggle的notebook可以自己写代码,也可以把写好的代码压缩上传到kaggle中,缺点是上传的代码不方便修改,因此建议自己在编译器上修改好后再上传。
- 选择左侧导航栏的Datasets——New Dataset,在title中输入一个自己命名的名字,文件路径会自动生成,然后可以选择拖拽文件压缩包或者选择点击Browse Files浏览电脑文件选择,最后选择creat,等上传完成,文件越大上传速度越长。代码和数据集可以放在一个文件一起上传,或者分两次上传,建议分两次上传,方便管理代码和数据集。
 - 点击Your Work可以查看自己上传的文件
- 点击Your Work可以查看自己上传的文件
- 接下来开始导入并开始训练
使用Kaggle训练自己的数据集
关于如何注册kaggle可以参考我这篇文章
- 打开Kaggle主页,选择左侧导航栏Create----New Notebook

- 选择页面最右侧一栏,先在Internet on 选项中打开连接网络,然后找到上面的ACCELERATOR选择自己想用的GPU
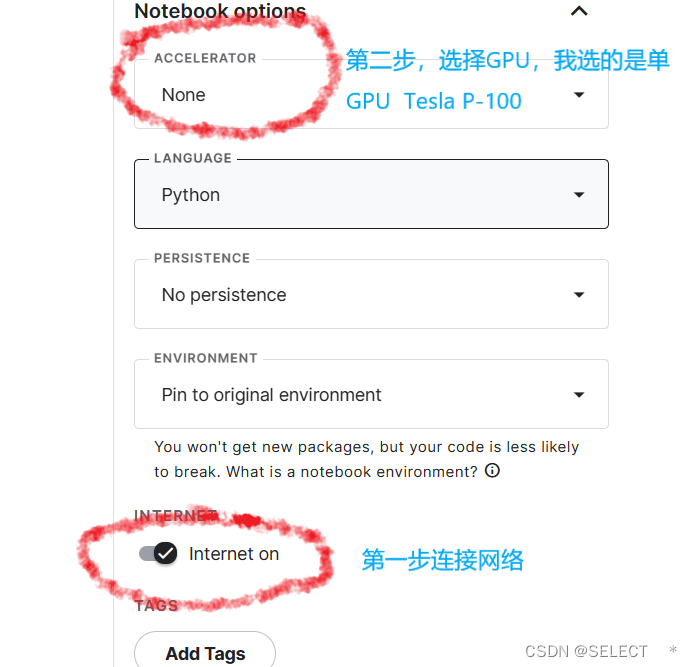
- 这里我选择使用P100,它有16G的内存,能满足大部分需求

- 这里选择turn on即可
- 接下来把上传的文件再上传到当前notebook中,Add Data,Your Datasets,点击文件后面的+即可
- 上传之后如图所示,文件在input中,input是只读文件,图片可以放在这里,但是代码需要复制到output文件中才能执行

- 新建一个代码行。输入下面代码,文件名注意改成自己的
!cp -rf /kaggle/input/yolov5-yuan/yolov5-yuan ./
notebook执行第一句代码需要启动服务器,所以执行这行代码耗费时间长一点,执行后代码文件就已经被复制到output文件中了,我这里是因为在代码文件里面放了训练图片所以整个文件有点大
- 导入需要用的包
!pip install -r /kaggle/working/yolov5-yuan/requirements.txt
- YOLOv5分类功能最终的训练结果目前还不支持用可视化功能展示,因此可以使用第三方工具实现结果可视化,这里使用wandb,注册后把自己的api key复制下来,在kaggle中登录
!wandb login 你的key
好了。接下来就可以训练了,执行下面代码,
!python /kaggle/working/yolov5-yuan/classify/train.py --model yolov5s-cls.pt --data /kaggle/input/f1-msr/f1_msr --epochs 10 --project runs
- model表示用的预训练模型,可以自己选;
- data表示训练的数据集;
- epochs表示训练次数
- project表示训练结果保存的地址,这里因为用了wandb,所以不能用默认的地址,否则wandb会报错
训练过程如图,top1-acc代表排名第一的类别与实际结果相符的准确率,即模型预测的正确率,top5-acc是指排名前五的类别包含实际结果的准确率,这里一共有四个类别,所以top5一直都是1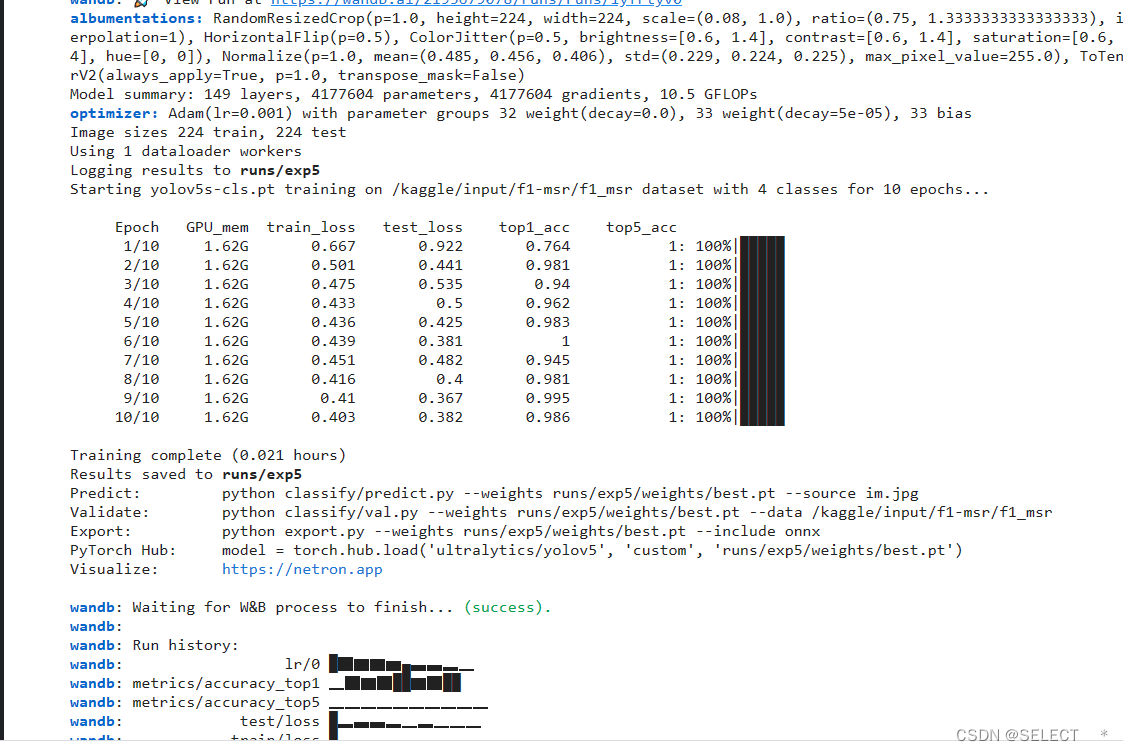 验证
验证
!python /kaggle/working/yolov5-yuan/classify/val.py --weights runs/exp5/weights/best.pt --data /kaggle/input/f1-msr/f1_msr
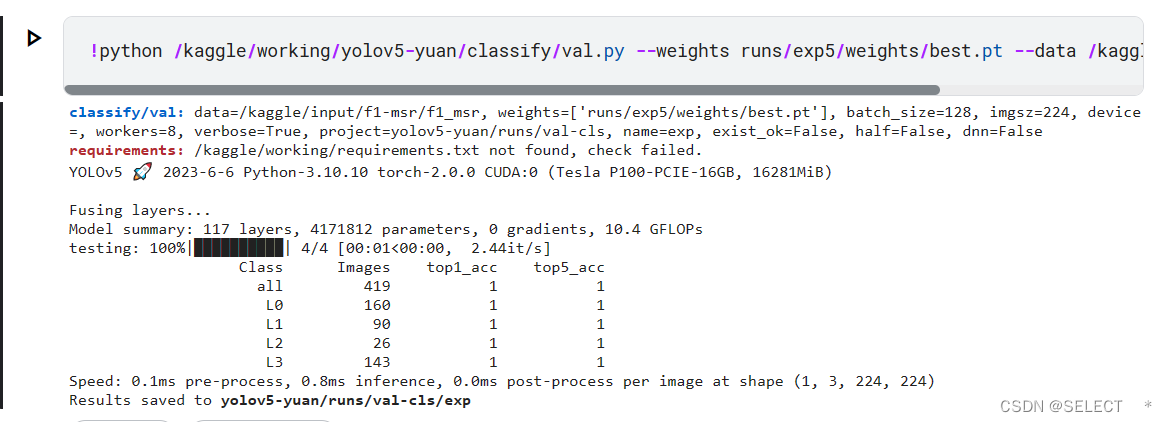
-
在测试集上验证
!python /kaggle/working/yolov5-yuan/classify/predict.py --weights runs/exp/weights/best.pt --source /kaggle/input/f1-msr/f1_msr/test/L0
修改路径可以测试不同的图片,也可以测试单独的图片,路径改为图片即可,图片上会显示预测类别的概率

-
训练完成后就可以打包下载训练的模型了,run.tar是打包压缩后的文件名,runs是要压缩的文件,压缩后output文件中会显示压缩的文件,点文件后的三个点下载即可
!tar -cf run.tar runs
- 训练结果也保存在runs文件夹中,也可以打开wandb官网查看训练结果
- 使用python实现混淆矩阵热力图,数组的值改为自己的数据即可
# confusion_matrix
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
classes = ['L0', 'L1', 'L2', 'L3']
confusion_matrix = np.array(
[[200,0,0,0],
[0,92,0,0],
[0,0,24,0],
[0,0,3,138],
], dtype=np.int) # 输入特征矩阵
proportion = []
length = len(confusion_matrix)
print(length)
for i in confusion_matrix:
for j in i:
temp = j / (np.sum(i))
proportion.append(temp)
# print(np.sum(confusion_matrix[0]))
# print(proportion)
pshow = []
for i in proportion:
pt = "%.2f%%" % (i * 100)
pshow.append(pt)
proportion = np.array(proportion).reshape(length, length) # reshape(列的长度,行的长度)
pshow = np.array(pshow).reshape(length, length)
# print(pshow)
config = {
"font.family": 'Times New Roman', # 设置字体类型
}
rcParams.update(config)
plt.imshow(proportion, interpolation='nearest', cmap=plt.cm.Blues) # 按照像素显示出矩阵
# (改变颜色:'Greys', 'Purples', 'Blues', 'Greens', 'Oranges', 'Reds','YlOrBr', 'YlOrRd',
# 'OrRd', 'PuRd', 'RdPu', 'BuPu','GnBu', 'PuBu', 'YlGnBu', 'PuBuGn', 'BuGn', 'YlGn')
# plt.title('confusion_matrix')
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, fontsize=12)
plt.yticks(tick_marks, classes, fontsize=12)
thresh = confusion_matrix.max() / 2.
# iters = [[i,j] for i in range(len(classes)) for j in range((classes))]
iters = np.reshape([[[i, j] for j in range(length)] for i in range(length)], (confusion_matrix.size, 2))
for i, j in iters:
if (i == j):
plt.text(j, i - 0.12, format(confusion_matrix[i, j]), va='center', ha='center', fontsize=10, color='white',
weight=5) # 显示对应的数字
plt.text(j, i + 0.12, pshow[i, j], va='center', ha='center', fontsize=10, color='white')
else:
plt.text(j, i - 0.12, format(confusion_matrix[i, j]), va='center', ha='center', fontsize=10) # 显示对应的数字
plt.text(j, i + 0.12, pshow[i, j], va='center', ha='center', fontsize=10)
plt.ylabel('True label', fontsize=16)
plt.xlabel('Predict label', fontsize=16)
plt.tight_layout()
plt.show()
# plt.savefig('混淆矩阵.png')

















 2585
2585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









