







一、主成分分析法(PCA)
PCA是一种常用的线性降维技术,它可以将高维数据投影到低维空间,同时保留数据中的主要变异方向。
你可以选择保留的主成分数量,这取决于你的具体应用和数据集。通常,你可以通过查看解释方差比来决定保留多少主成分。
数学原理以及代码实现可以参考我之前写的文章:http://t.csdnimg.cn/3rA3j
二、核主成分分析法(KPCA)
KPCA,即核主成分分析(Kernel Principal Component Analysis),是一种非线性降维技术,它通过使用核技巧(kernel trick)将数据映射到高维特征空间,使得在高维空间中数据变得线性可分,然后在该空间中进行主成分分析(PCA)。
-
核函数(Kernel Function):核函数是一种计算两个数据点在高维空间中内积的函数,它避免了直接在高维空间中计算的复杂性。常见的核函数有线性核、多项式核、径向基函数(RBF)核等。
-
映射到高维空间:KPCA首先使用核函数将原始数据从低维空间映射到一个高维(甚至是无限维)的特征空间。在这个过程中,数据点之间的关系被重新构建,使得原本在低维空间中非线性的关系在高维空间中可能变得线性。
-
中心化核矩阵:在映射后的高维空间中,计算所有数据点之间的核矩阵(即核函数的值构成的矩阵)。然后对核矩阵进行中心化处理,即减去核矩阵的行和列的均值,使得处理后的核矩阵的行和列的和都为零。
-
特征分解:对中心化后的核矩阵进行特征分解,求解其特征值和特征向量。特征值的大小反映了对应特征向量所代表的主成分的重要性,特征值越大,说明该主成分携带的信息越多。
-
选择主成分:根据特征值的大小,选择最大的几个特征值对应的特征向量作为主成分。这些主成分是原始数据在高维空间中的线性组合,它们能够最大程度地保留数据的信息。
-
降维:将数据点投影到选定的主成分上,实现数据的降维。由于是在高维空间中进行的线性组合,所以KPCA能够处理非线性数据分布。
KPCA的核心思想是利用核函数将数据从低维空间映射到高维空间,在高维空间中进行线性主成分分析,从而能够揭示和处理原始空间中的非线性结构。这种方法在处理非线性数据集时非常有效,因为它不需要显式地计算高维空间中的数据点,而是通过核函数间接地进行计算。
想象一下,你有一堆照片,这些照片上有各种各样的动物,但因为照片堆得太密集,动物间的区别看起来很小,就像我们无法从复杂或混乱的数据中清楚地辨识模式一样。这就是KPCA要解决的问题,让我们通过一个故事来简化这个过程:
1. 魔法相机(核函数):首先,想象你有一台魔法相机。当你用它重新拍摄那些动物的照片时,动物们就会被传送到一个神奇的世界(高维空间),在这个世界里,它们彼此之间的距离变得非常明显,就像把它们放在了巨大的草原上,每种动物都有足够的空间来展示自己的独特性。
2. 魔法相册(中心化核矩阵):然后,你将这些新拍的照片放进一个魔法相册。这个相册可以自动调整照片,确保每个动物都在相册的正中心展示,没有一个是被边缘化的。这就是中心化的过程,确保了在这个新的魔法世界里,没有哪个动物是比其他动物更重要或更显眼的。
3. 魔法放大镜(特征分解):接下来,你拿出了一只魔法放大镜。通过这只放大镜观察每一张照片,你可以看到某些动物比其他动物更加突出—这就像找到了哪些方向(特征向量)上动物的区别最大。这样,你就知道在哪个方向上看这个世界,能看到最多的不同种类的动物。
4. 精选集(选择主成分):通过使用魔法放大镜,你决定制作一个精选集,只包含那些显示最多动物独特性的照片。这相当于KPCA中选择携带最多信息(特征值较大)的主成分,这样做可以最大程度地保留原始数据的结构和信息,同时去除不必要的部分。
5. 展览(降维):最后,你决定举办一个展览,只展出精选集里的照片。通过展出的照片,观众可以很容易地看出不同动物之间的差异,即使是原本在照片堆中难以辨识的。在KPCA中,这就是降维的过程,通过保留最重要的特征(主成分),使得数据更容易被理解和分析。

通过这个故事,KPCA的过程被简化为:使用魔法相机(核函数)捕获数据的本质,通过魔法相册(中心化核矩阵)调整视角,利用魔法放大镜(特征分解)找到最能展示数据多样性的角度(主成分),最后通过精选集(选择主成分)和展览(降维)让数据的重要信息更加突出和易于理解。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.decomposition import KernelPCA
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
X, y = make_moons(n_samples=100, random_state=123)
kpca = KernelPCA(n_components=2, kernel="rbf", gamma=15) # 使用RBF核
X_kpca = kpca.fit_transform(X)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red', marker='^', alpha=0.5)
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue', marker='o', alpha=0.5)
plt.title("原始数据")
plt.subplot(1, 2, 2)
plt.scatter(X_kpca[y == 0, 0], X_kpca[y == 0, 1], color='red', marker='^', alpha=0.5)
plt.scatter(X_kpca[y == 1, 0], X_kpca[y == 1, 1], color='blue', marker='o', alpha=0.5)
plt.title("KPCA后的数据")
plt.tight_layout()
plt.show()

三、线性判别分析(LDA)
LDA是一种有监督的线性降维方法,它旨在找到最大化类间差异和最小化类内差异的投影方向。如果你有标签信息,LDA可以帮助你找到更有判别性的特征。
假设你正在组织一个学校的运动会,有很多不同年级的学生参与,你的任务是确保比赛公平,让各个年级的学生在各自的比赛中竞争。但是,现在问题来了:学生们都混杂在一起,你需要快速把他们根据年级分开,而且,为了让比赛更有趣,你还希望能够找出哪些体育特长生,因为他们的体能可能远超同年级的普通学生。

如何将学生分组?
首先,你决定根据学生们的身高和体重来将他们分成不同的年级组。这里,身高和体重就像是我们在数据分析中的"特征"。但是,你很快发现,仅仅根据单一的特征(比如身高)来分组并不够好,因为不同年级的学生在这些特征上可能有重叠。这时,你意识到需要同时考虑身高和体重两个特征来进行分组。
如何突出体育特长生?
接下来,你想要进一步区分出每个年级中潜在的体育特长生。为此,你不只是简单地看他们在身高和体重上的绝对值,而是要看他们相对于各自年级的普通学生在这些特征上的"差异"。如果某个学生在身高和体重的综合评分上显著高于同年级的平均水平,那么他很可能是一个体育特长生。
LDA做了什么?
在LDA的世界里,你的目标是找到一个最佳的"视角"(或者说,一个最佳的"方向"),从这个视角观察,不同组(年级)的学生之间的区别被最大化,而同一组内部的差异被最小化。换句话说,LDA试图找到一个投影方向,使得投影后,不同年级的学生群组之间尽可能地分开(最大化组间差异),而每个年级内部的学生尽可能地聚在一起(最小化组内差异)。
数学上,这涉及到计算数据的“组间散布矩阵”和“组内散布矩阵”,然后找到一个方向,使得这个方向上的组间散布与组内散布的比值最大。这个方向就是LDA寻找的最佳投影方向。
通过LDA找到的这个"最佳方向",就像是你找到的那个能够最好地区分不同年级并且突出体育特长生的方法。在这个方向上查看数据,可以更清晰地看到数据的结构,便于进一步的分析和处理,比如分类或降维。简而言之,LDA帮助我们从最有信息的角度来看待数据,以便更好地理解和使用它们。
下面介绍一下LDA(线性判别分析)的详细数学原理主要涉及到查找一个或多个线性组合的特征,这些特征能够最好地区分两个或多个类别。这一过程可以通过以下数学步骤进行详细说明:
-
计算每个类别的均值向量:首先,我们需要了解每个类别的数据平均情况是怎样的,这通过计算每个类别中所有数据点的平均值来实现。简单来说,就是找出每个类别数据的“中心”位置。
-
衡量类内数据的分散程度:接下来,我们要看看每个类别内部的数据它们相互之间是紧密聚集的,还是比较分散。这一步是为了确保我们后面找到的新特征能够确保同一个类别内的数据点之间仍旧保持较小的差异。
-
衡量类间数据的分离程度:此步骤的目的是要度量不同类别的数据集“中心”之间的距离,以确保我们最终找到的新特征能使不同类别之间有尽可能大的差异。
-
寻找最佳的数据投影方向:这一步是核心,LDA的目标就是要找到一种方式,按此方式投影(或“映射”)数据后,能够使得我们之前提到的类内数据点保持紧密(内部差异小),而不同类别之间的数据点则相互远离(类间差异大)。这就像是在多维空间中找到一个最佳观察角度,使得不同类别的数据在这个角度下看起来互相分隔得最开。
-
选择并应用最佳投影:在找到一个或多个最佳的投影方向后,我们接着根据这些方向来重新组织我们的数据,这样做的结果是产生了一个新的数据表现形式,它在新的空间中有更好的分类效果。
-
数据降维和分类:通过上述步骤,我们可以将数据投影到较低维度的空间中,这不仅帮助我们减少了数据处理的复杂度,同时也使得数据的类别之间更容易区分,从而提高分类算法的性能。
整个LDA的过程,可以看作是一种寻找数据在新空间中最佳表示的方法,这种表示强调了不同数据集之间的区别,使得分类任务变得更加容易。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.datasets import make_classification
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
# 创建一个虚拟的分类数据集
X, y = make_classification(n_samples=100, n_features=20, n_informative=3, n_redundant=10,
n_classes=3, random_state=42) # 确保有三个类别
# 创建LDA模型实例,并指定降维后的维度数为2
lda = LinearDiscriminantAnalysis(n_components=2)
# 使用LDA进行降维
X_lda = lda.fit_transform(X, y)
# 降维后的数据形状
print("Original shape: ", X.shape)
print("LDA shape: ", X_lda.shape)
# 可视化
plt.figure(figsize=(8, 6))
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y, edgecolor='k', alpha=0.7)
plt.title('LDA降维')
plt.xlabel('LDA成分1')
plt.ylabel('LDA成分2')
plt.colorbar(label='类型标签')
plt.show()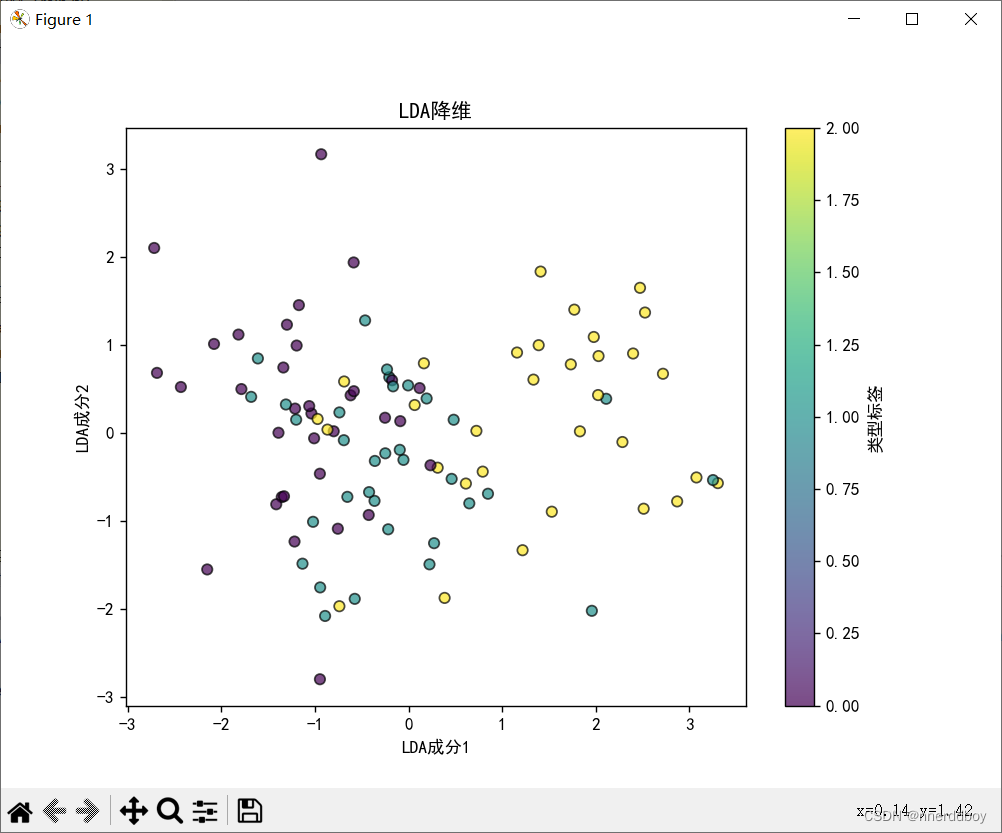
四、t-分布随机邻域嵌入(t-SNE)
t-SNE是一种非线性降维技术,特别适用于可视化高维数据。它通过保持数据点之间的局部邻域关系来工作,但可能不适合直接用于分类或回归任务。
想象一下你在举办一场大型派对,邀请了来自全国各地的朋友们。每个人都与不同的社交圈子有联系,有些人互相认识,有些人则不认识。你的目标是让派对顺利进行,让每个人都能找到话题和乐趣。把这个场景与高维数据集中的点进行类比,每个点就像是一个客人,点与点之间的距离表示他们的相似度。

在派对开始之前,你决定制定一个"社交地图"来指导客人如何互动。在高维空间里(就像是每个人的全国性社交网络),很难直接看到谁和谁更有可能成为朋友,因为所有的社交联系和距离都交织在一起。这就是你需要t-SNE的地方。
t-SNE的工作就像是创建一个适合派对的简化版社交地图。首先,它仔细观察高维空间中的每个人(数据点),理解谁与谁关系紧密。然后,t-SNE试图在一个更小的房间内(也就是低维空间,通常是二维平面),重新安排每个人的位置,以保持原来的社交距离:互相认识的人在派对中靠得更近,而不太熟的人则相对远一些。
但t-SNE有一个特别的地方:它知道在小房间里,人们不太可能保持很远的距离(因为这样会显得很不礼貌),所以它使用一种特殊的方法来确保远处的人不会太远,但又不会干扰彼此间的亲密关系。这就是为什么t-SNE特别适合展示小团体和社交圈子。
最终,当你查看t-SNE生成的二维地图时,你会看到一个派对的缩影:那些可能互相了解的人形成小组聚在一起,而那些与众不同的人则被放在一旁。这样,即使是在复杂的大型数据集中,你也能一眼看出哪些数据点可能有共同点,哪些则是异常点或属于特殊类别。
t-SNE的数学原理可以分为两个主要步骤:
-
高维空间中的相似度计算:首先,t-SNE在原始的高维空间中计算数据点之间的相似度。这些相似度是通过高斯分布来衡量的,即两个点越接近,它们之间的相似度越高。这个步骤的目的是捕捉数据点之间的局部邻域关系。
-
低维空间中的相似度匹配:接下来,t-SNE试图在低维空间中找到一个映射,使得在这个映射下,高维空间中的相似度关系得以保持。在低维空间中,相似度的计算使用了一种特殊的分布,即t分布(也称为学生t分布),这种分布的特点是尾部比高斯分布更重,这意味着在低维空间中,距离较远的点之间的相似度不会被过分低估,从而有助于保持数据点之间的全局结构。
t-SNE通过一个迭代过程来优化低维空间中的映射,这个过程称为梯度下降。在这个过程中,t-SNE会不断调整低维空间中数据点的位置,直到高维和低维空间中的相似度分布尽可能接近。这个优化过程的目标是最小化一个名为Kullback-Leibler散度的度量,它衡量了两个概率分布之间的差异。t-SNE的数学原理是通过在高维空间中计算相似度,然后在低维空间中寻找一个映射,使得这两个空间中的相似度分布尽可能一致,从而实现高维数据的有效可视化。
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
# 加载数据集,这里使用的是手写数字识别数据集
digits = load_digits()
X = digits.data # 特征数据
y = digits.target # 标签数据,用于后续的颜色编码
# 初始化t-SNE模型并设置降维目标维度为2
tsne = TSNE(n_components=2, random_state=0)
# 对数据进行降维处理
X_2d = tsne.fit_transform(X)
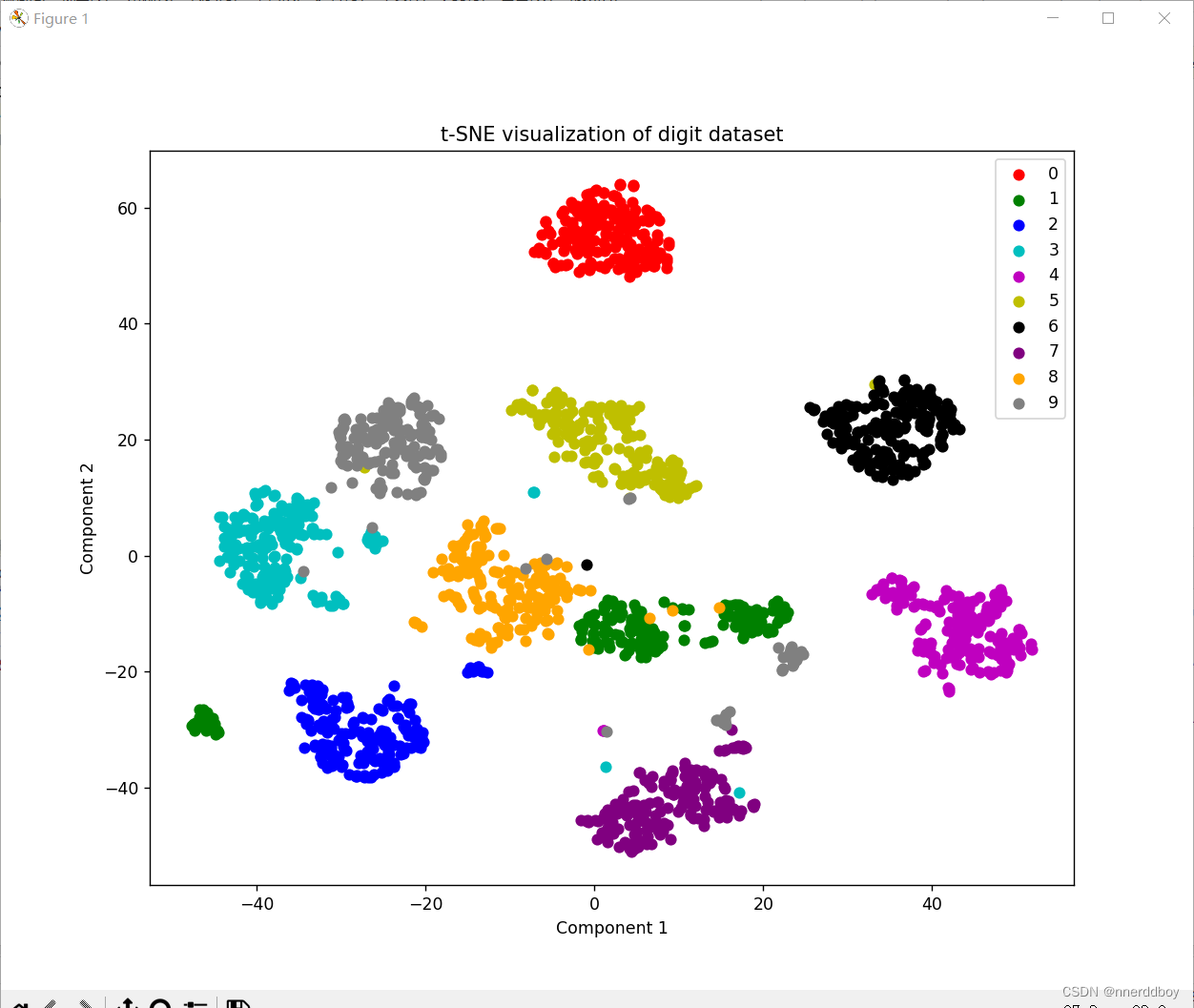
plt.figure(figsize=(10, 8))
colors = 'r', 'g', 'b', 'c', 'm', 'y', 'k', 'purple', 'orange', 'gray'
for i, c, label in zip(range(10), colors, range(10)):
plt.scatter(X_2d[y == i, 0], X_2d[y == i, 1], c=c, label=label)
plt.legend()
plt.title('t-SNE visualization of digit dataset')
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.show()
五、UMAP(Uniform Manifold Approximation and Projection)
UMAP是一种较新的非线性降维方法,它能够保留数据的局部结构和全局结构。
与t-SNE相比,UMAP通常在计算效率上更优,并且可以用于更高维度的数据。
作为一种用于降维和数据可视化的算法,它的数学原理可以通过一个比喻来解释。想象一下,你是一位城市规划师,你的任务是将一个复杂的城市网络映射到一个更简单的平面图上,以便人们可以更容易地理解和导航。

-
理解城市的复杂结构: 在UMAP的比喻中,城市的高维网络就像是你的原始数据集,每个建筑物、街道和交叉口都是一个数据点。你需要理解这些点之间的关系,就像理解城市中各个地点之间的连接方式。UMAP通过计算数据点之间的距离来捕捉这种关系,就像你记录城市中每个地点之间的实际距离和路径。
-
创建一个简化的地图: 接下来,你需要创建一个简化的地图,这个地图要尽可能保留原始城市的结构,同时减少细节以方便人们使用。在UMAP中,这对应于将高维数据映射到一个低维空间。UMAP使用一种叫做“模糊集合”的方法来实现这一点,就像你在地图上用不同的颜色和线条粗细来表示不同类型的街道和区域。
-
保持局部结构和全局结构: 在创建简化地图时,你希望保持城市的局部结构(比如邻近的街道和社区)和全局结构(比如主要道路和交通枢纽)。UMAP通过优化一个损失函数来实现这一点,这个损失函数旨在最小化原始高维空间和低维映射之间的差异。这就像你在地图上确保主要的街道和地标被准确地表示,同时邻近的建筑物和街区也被合理地聚集在一起。
-
平衡细节和简洁性: 最后,你希望你的地图既不过于复杂,也不过于简化。UMAP通过调整参数来控制这种平衡,就像你在地图上决定哪些细节是必要的,哪些可以省略。UMAP的参数允许你调整对局部结构和全局结构的重视程度,以及对数据点之间距离的敏感度。
最终,UMAP生成的低维映射就像是一个精心设计的城市地图,它既保留了原始城市的复杂性,又提供了足够的简化,使得人们可以轻松地导航和理解。在数据科学中,UMAP帮助我们以一种直观的方式探索和理解高维数据集,就像城市规划师帮助人们理解和导航复杂的城市网络一样。
它的数学原理基于几个关键概念:
-
局部和全局结构的保持:UMAP旨在在低维空间中保持数据的局部结构和全局结构。这意味着它不仅要确保相似的数据点在低维表示中保持接近,还要确保数据的整体分布和形状得到保留。
-
模糊拓扑:UMAP使用模糊集合的概念来描述数据点之间的关系。在模糊拓扑中,数据点之间的连接不是二元的(即要么连接,要么不连接),而是连续的,表示为连接的强度或概率。这允许UMAP捕捉到数据点之间复杂的关系。
-
优化过程:UMAP通过一个优化过程来找到最佳的低维表示。这个过程涉及到最小化一个特定的损失函数,该函数衡量了原始高维空间中的模糊拓扑与低维空间中的模糊拓扑之间的差异。通过调整数据点在低维空间中的位置,UMAP不断迭代,直到找到一个能够最好地保持原始数据结构的低维映射。
-
参数调整:UMAP算法包含一些参数,这些参数允许用户调整算法的性能。例如,可以调整参数来控制对局部结构的重视程度,或者调整对数据点之间距离的敏感度。这些参数的选择会影响最终的降维结果。
-
高效计算:UMAP设计时考虑了计算效率,它使用了一些技术来加速计算过程,例如使用随机梯度下降来优化损失函数,以及使用近似最近邻搜索来快速找到数据点之间的邻居。
总的来说,UMAP的数学原理是通过模糊拓扑来捕捉数据点之间的关系,然后通过一个优化过程在低维空间中找到一个能够最好地保持这些关系的表示。这个过程是迭代的,并且可以通过调整参数来适应不同的数据集和分析需求。UMAP的目标是提供一个既能够保持数据结构,又能够在计算上高效的降维方法。
导入umap-learn包:
pip install umap-learnimport numpy as np
import umap
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
# 加载数据集,这里使用的是手写数字识别数据集
digits = load_digits()
X = digits.data # 特征数据
y = digits.target # 标签数据,用于后续的颜色编码
# 初始化UMAP模型并设置降维目标维度为2
mapper = umap.UMAP(n_components=2, random_state=42)
# 对数据进行降维处理
embedding = mapper.fit_transform(X)
# 可视化
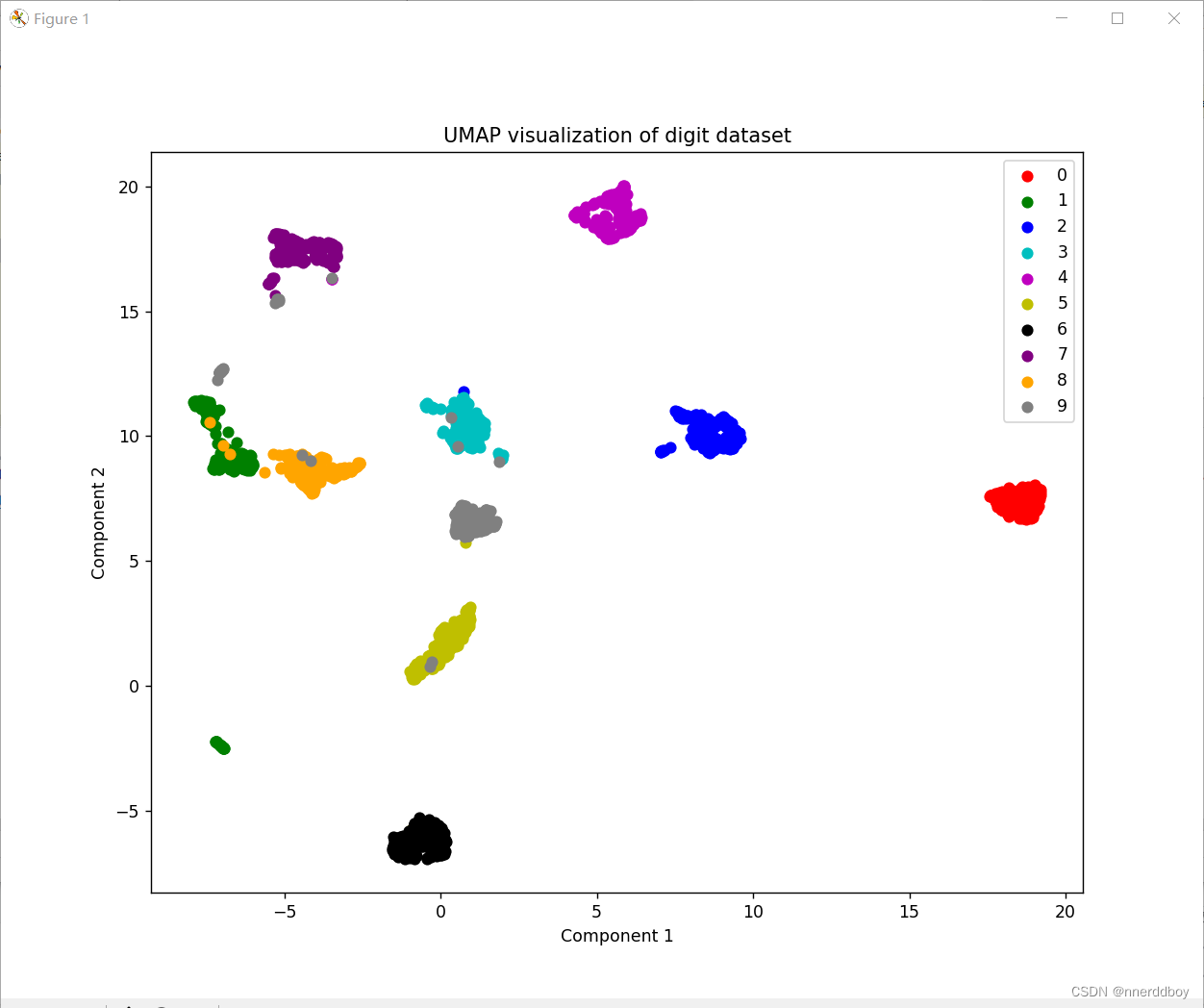
plt.figure(figsize=(10, 8))
# 为每个目标类别选择不同的颜色
colors = 'r', 'g', 'b', 'c', 'm', 'y', 'k', 'purple', 'orange', 'gray'
for i, c, label in zip(range(10), colors, range(10)):
plt.scatter(embedding[y == i, 0], embedding[y == i, 1], c=c, label=label)
plt.legend()
plt.title('UMAP visualization of digit dataset')
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.show()
















 4637
4637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









