







一、朗伯-比尔定律与修正的朗伯-比尔定律
朗伯-比尔定律 是一个描述光通过溶液时被吸收的规律。想象你有一杯有色液体,比如一杯红茶。当你用一束光照射这杯液体时,光的一部分会被液体吸收,导致透过液体的光变弱。朗伯-比尔定律告诉我们,透过液体的光的强度减少的程度与以下三个因素有关:
- 光的传输路径长度:如果你增加液体的深度(即光穿过的路径更长),光被吸收得更多,透过液体的光就更少。
- 吸光物质的浓度:如果液体中吸收光的物质(比如茶叶中的色素)更多,光被吸收得更多,透过液体的光就更少。
- 消光系数:这是一个物质的特性,表示这种物质吸收光的能力。不同的物质有不同的消光系数。
朗伯-比尔定律的数学表达式是:
OD=ϵ⋅C⋅L
其中:
- OD是光密度(Optical Density),表示光被吸收的程度。
- ϵ 是消光系数,表示物质吸收光的能力。
- C 是吸光物质的浓度。
- L 是光穿过的路径长度。
修正的朗伯-比尔定律 是在朗伯-比尔定律的基础上考虑了光在生物组织中的散射效应。在生物组织中,光不仅会被吸收,还会因为与组织中的微粒碰撞而改变方向,这种现象叫做散射。散射使得光在组织中的实际路径比直线更长,因此光被吸收得更多。
修正的朗伯-比尔定律考虑了这一点,并引入了两个新的参数:
- 路径长度修正因子(DPF):这个因子表示由于散射效应,光在组织中的实际路径长度是直线长度的多少倍。
- 其他因素引起的光强衰减总和(G):这个参数表示除了吸光物质之外,其他因素(如颅骨、脑脊液等)引起的光强衰减。
修正的朗伯-比尔定律的数学表达式是:
OD=ϵ⋅C⋅DPF⋅L+G
在实际应用中,由于 G 很难测量,通常我们只关注吸光物质浓度的相对变化,而不是绝对值。通过测量不同时间点的光衰减量,并利用修正的朗伯-比尔定律,可以求解出血红蛋白浓度的相对变化,这对于研究脑功能等生物学过程非常有用。
二、因变量与自变量选取
在认知心理学领域,fNIRS脑成像实验通过操纵自变量(如不同刺激或行为)来记录血液动力学响应的变化,以此作为因变量,探索认知功能的神经基础。因变量在fNIRS研究中通常表现为血液动力学响应的变化,具体可以取的值包括氧合血红蛋白和脱氧血红蛋白的浓度变化、脑区血流量的变化等。
自变量是实验者可以操纵的因素,其不同取值称为不同水平或条件。自变量可以通过操作化定义转换为具体、可量化的指标,以便于实验操作和结果分析。例如,受试者对任务的参与程度可以通过可能获得的报酬数量来量化,通过设置不同等级的报酬来实现对受试者参与程度这个变量的操纵。自变量可以根据数据类型(类别变量或连续变量)、来源(作业/任务变量、环境变量、受试者变量)和可操作性进行分类。类别变量的例子如性别(男/女),连续变量的例子如学习成绩(0—100的任意取值)。
单因素设计通过比较实验条件与基线条件来计算神经响应指标。减法法则要求比较两种任务的反应时差异,以分离特定认知过程的反应时。因变量在这种情况下可以取的值包括反应时、正确率等行为响应指标,以及神经活动引起的局部血液动力学响应。
共性法则通过多个减法实验求得共性部分,提高脑区与认知成分关联的可能性。因素设计同时操纵多个自变量,每个因素设置多个水平,以探索因素间的交互作用。因变量在因素设计中可以取的值包括不同实验条件下神经活动的变化,如脑区血红蛋白浓度的变化。
参数设计将感兴趣的变量视为连续变量,通过在多个水平上观察和记录因变量的值,来确定自变量与神经响应之间的具体关系模式。因变量在参数设计中可以取的值包括随着自变量变化,脑活动的变化模式,如线性或非线性关系。
三、数据预处理
-
去漂移(Detrending):
- 原因:成像系统(如机器)在工作过程中逐渐升温,环境温度和光照的改变或受试者缓慢的头动,通常表现为较长时间范围内的缓慢波动。这种漂移会使fNIRS信号的基线发生改变,影响信号的稳定性和准确性。
- 方法:通过拟合信号中的线性或非线性趋势项,然后从原始信号中减去这些趋势项来实现去漂移。
- 数学原理:去漂移是通过拟合信号中的线性或非线性趋势项,然后从原始信号中减去这些趋势项来实现的。
- 公式:假设原始信号为 y(t),拟合的趋势项为 T(t),去漂移后的信号为
,则有:
-
周期性噪声滤波(Filtering):
- 原因:周期性噪声包括机器噪声(如工频噪声50Hz和随机热噪声高于2Hz)和生理噪声(如心率约1Hz、呼吸约0.2—0.3Hz、Mayer wave约0.1Hz和极低频的生理波动低于0.01Hz)。这些噪声成分具有明显的周期性波动特点,会影响信号的纯净度。
- 方法:通过高通滤波、低通滤波和带通滤波等频域滤波方法去除信号中具有明显周期性波动特点的噪声成分。
- 数学原理:滤波是通过在频域中去除特定频率成分来实现的。高通滤波、低通滤波和带通滤波是常用的滤波方法。
- 公式:假设原始信号为 y(t),滤波后的信号为
,滤波器的传递函数为 H(f),则有:
-
头动噪声和浅层噪声去除:
- 头动噪声去除:
- 原因:受试者头动可能导致光极与头皮接触不良,这种头动噪声往往体现为信号中的大幅跳变。由于其出现时间和位置都较为随机,传统的频域滤波预处理方法很难去除这种噪声。
- 方法:通过异常点检测方法检测到头动噪声,将任意时间点信号的幅值与一段时间内信号的平均幅值做对比,并且设置一定的阈限来标出异常点,然后去除这些异常点。
- 数学原理:头动噪声通常表现为信号中的大幅跳变,可以通过异常点检测方法来识别和去除。
- 公式:假设信号的均值为 μ,标准差为 σ,阈值为 k,则异常点检测公式为:异常点←∣y(t)−μ∣>k⋅σ
- 浅层噪声去除:
- 原因:头皮、颅骨和脑膜等浅层组织中含丰富的毛细血管,呼吸、心跳等生理波动及任务相关的自主神经活动都会引起这些毛细血管中血红蛋白浓度的变化,从而导致fNIRS光衰减量的变化(即浅层生理噪声)。
- 方法:通过短间隔通道法或空间滤波方法去除浅层噪声。短间隔通道法利用额外的短间距fNIRS通道记录浅层生理噪声,再从信号中将其去除。
- 数学原理:浅层噪声可以通过短间隔通道法或空间滤波方法来去除。短间隔通道法利用额外的短间距fNIRS通道记录浅层生理噪声,然后从信号中减去这些噪声。
- 公式:假设浅层噪声信号为 n(t),原始信号为 y(t),去除浅层噪声后的信号为
,则有:
- 头动噪声去除:
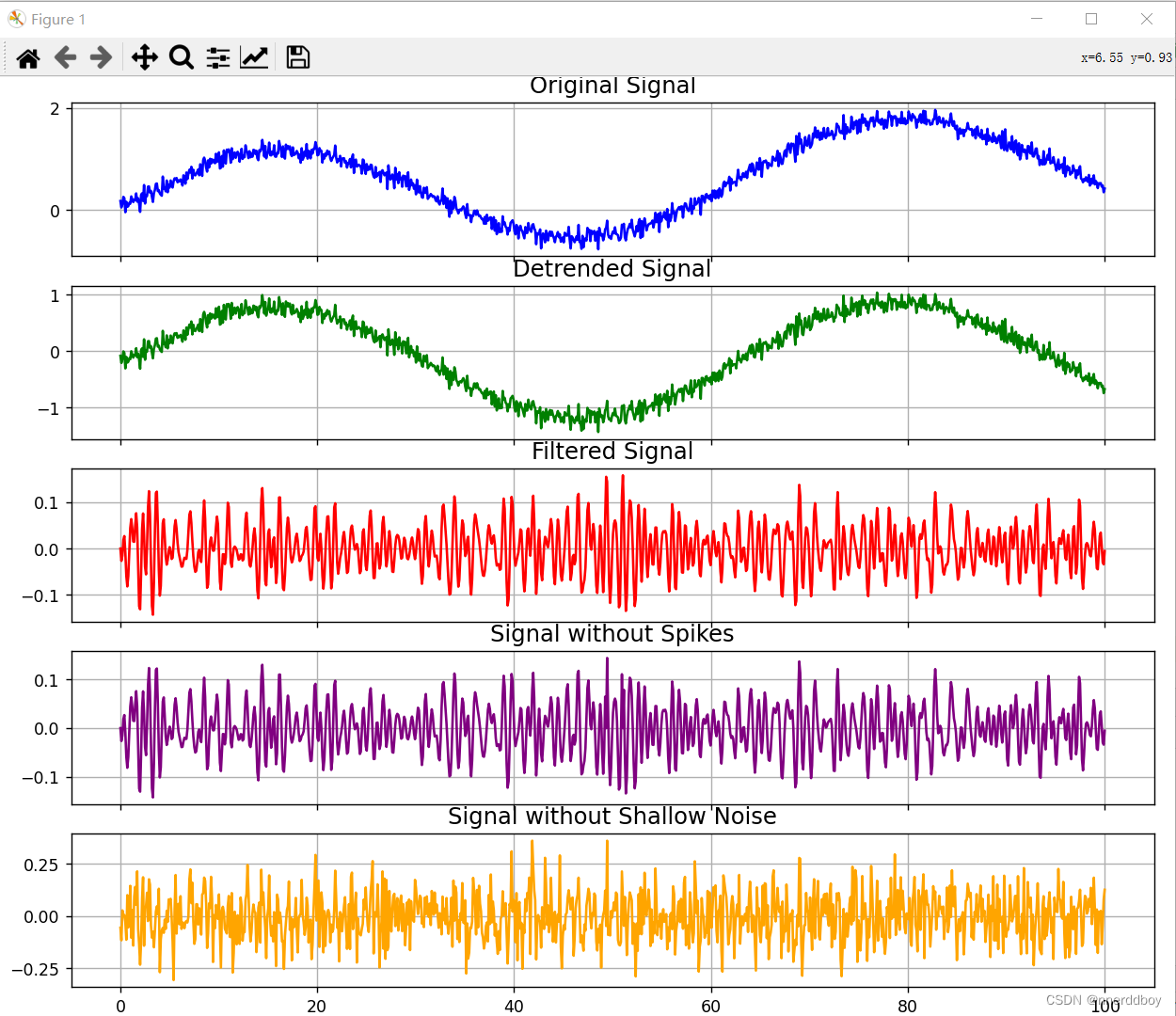
四、Python代码实现
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import detrend, butter, filtfilt
np.random.seed(0) # 模拟生成
t = np.linspace(0, 100, 1000)
y = np.sin(0.1 * t) + 0.1 * np.random.randn(1000) # 添加正弦信号和噪声
y += 0.01 * t # 添加线性漂移
# 去漂移
y_detrend = detrend(y)
# 周期性噪声滤波
def butter_bandpass_filter(data, lowcut, highcut, fs, order=4):
nyq = 0.5 * fs
low = lowcut / nyq
high = highcut / nyq
b, a = butter(order, [low, high], btype='band')
filtered = filtfilt(b, a, data)
return filtered
fs = 10 # 采样频率
lowcut = 0.5
highcut = 2.0
y_filtered = butter_bandpass_filter(y_detrend, lowcut, highcut, fs)
# 头动噪声去除
def remove_spikes(data, threshold=3):
mean = np.mean(data)
std = np.std(data)
outliers = np.abs(data - mean) > threshold * std
data_clean = np.copy(data)
data_clean[outliers] = mean
return data_clean
y_no_spikes = remove_spikes(y_filtered)
# 浅层噪声去除(实际应用中需要额外的短间距通道数据)
y_no_shallow = y_no_spikes - 0.1 * np.random.randn(1000)
fig, axs = plt.subplots(5, 1, figsize=(10, 15), sharex=True)
plt.rcParams['font.family'] = 'serif'
plt.rcParams['font.size'] = 12
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['lines.linestyle'] = '-'
axs[0].plot(t, y, color='blue')
axs[0].set_title('Original Signal', fontsize=14)
axs[0].grid(True)
axs[1].plot(t, y_detrend, color='green')
axs[1].set_title('Detrended Signal', fontsize=14)
axs[1].grid(True)
axs[2].plot(t, y_filtered, color='red')
axs[2].set_title('Filtered Signal', fontsize=14)
axs[2].grid(True)
axs[3].plot(t, y_no_spikes, color='purple')
axs[3].set_title('Signal without Spikes', fontsize=14)
axs[3].grid(True)
axs[4].plot(t, y_no_shallow, color='orange')
axs[4].set_title('Signal without Shallow Noise', fontsize=14)
axs[4].grid(True)
plt.xlabel('Time (s)', fontsize=14)
plt.tight_layout()
plt.show()
结果如下:


















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









