







随机过程论就是研究随时间变化的动态系统中随机现象的统计规律的一门数学学科。
目录
前言
随机过程理论产生于本世纪初,起源于统计物理学领域。布朗运动和热噪声是随机过程的最早例子。随机过程理论在社会科学、自然科学和工程技术的各个领域中都有着广泛的应用。例如:现代电子技术、现代通讯、自动控制、系统工程的可靠性工程、市场经济的预测和控制、随机服务系统的排队论﹑储存论、生物医学工程、人口的预测和控制等等。只要人们要研究随时间变化的动态系统的随机现象的统计规律时,就要应用到随机过程的理论。
一、随机过程的定义及分类
1、定义
随机过程可以形式化地定义为一个随机变量的集合 {X(t), t ∈ T},其中 T 是一个表示时间的参数集合。对于每个时间点 t ∈ T,X(t) 是一个随机变量,表示在该时间点上观察到的随机现象的取值。这样的集合 {X(t), t ∈ T} 被称为随机过程。
在实际应用中,随机过程通常分为离散时间和连续时间两种情况。如果参数集合 T 是离散的,那么随机过程是离散时间随机过程;如果参数集合 T 是连续的,那么随机过程是连续时间随机过程。
随机过程的性质可以通过其概率分布、相关性函数、平均值等统计量来描述,这些性质可以用来分析随机过程的行为和特征。 常见的随机过程包括布朗运动、泊松过程、马尔可夫过程等。

说明:{X(t,),t e T}
- 参数集T在实际问题中,常常指的是时间参数,但有时也用其它物理量作为参数集。
- X(t,o)是定义在T×Q上的二元函数。
- t固定时,X(t,o)是随机变量。o固定时,X(t,o)是T的样本函数。
- 随机过程{X(t),t aT}是时刻t上的取值x,称为状态,状态的全体称为状态空间。记为:E={x : X(t)=x,t eT}
2、分类
按状态空间和参数集分类:
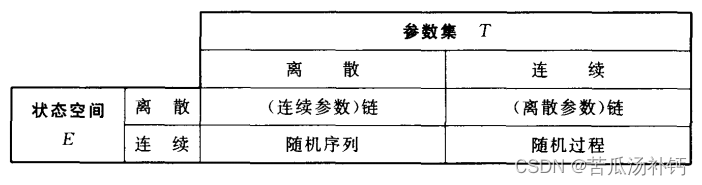
按概率分布规律分类:随机过程{X(t),t∈ T}按其概率分布规律分为:独立过程、独立增量过程、正态过程﹑泊松过程、维纳过程﹑平稳过程和马尔可夫过程等等。
二、随机过程的分布及其数字特征
1、分布函数
一维分布函数和一维概率密度是用来描述随机变量的统计性质的工具。它们是概率论中的基本概念,用于描述随机变量在不同取值上的概率分布。
一维分布函数 (Cumulative Distribution Function, CDF):
- 一维分布函数是一个函数,表示随机变量小于或等于某个特定取值的累积概率。
- 用 F(x) 表示,其中 x 是随机变量的某个具体取值。
- 公式:F(x)=P(X≤x)
- 分布函数具有以下性质:
- 0≤F(x)≤1 对所有 x 成立。
- F(x) 是非递减函数,即对于 x1<x2,有 F(x1)≤F(x2)。
- 当x→−∞ 时,F(x)→0,当 x→+∞ 时,F(x)→1。
一维概率密度 (Probability Density Function, PDF):
- 一维概率密度是一个函数,表示随机变量在某个取值附近的概率密度。
- 用 f(x) 表示,其中 x 是随机变量的某个具体取值。
- 公式:f(x)=dxdF(x)
- 概率密度具有以下性质:
- 对于所有 x,f(x)≥0。
- 在整个实轴上的积分等于 1,即∫−∞+∞f(x)dx=1。
- 在某个区间上的概率可以通过概率密度函数在该区间上的积分来计算。
在实际应用中,分布函数和概率密度函数是用来描述
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2862
2862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









