







介绍直接法的原理,并利用 g2o 实现直接法中的一些核心算法。
前言
1. 理解光流法跟踪特征点的原理。
2. 理解直接法是如何估计相机位姿的。
3. 使用 g2o 进行直接法的计算。
哔哩哔哩课程连接:视觉SLAM十四讲ch7_2_哔哩哔哩_bilibili
一、直接法的引出
视觉slam十四讲学习笔记(六)视觉里程计 1-CSDN博客介绍了使用特征点估计相机运动的方法。尽管特征点法在视觉里程计中占据主流地位,但有以下几个缺点:
- 关键点的提取与描述子的计算非常耗时。实践当中,SIFT 目前在 CPU 上是无法实时计算的,而 ORB 也需要近 20 毫秒的计算。如果整个 SLAM 以 30 毫秒/帧的速度运行,那么一大半时间都花在计算特征点上。
- 使用特征点时,忽略了除特征点以外的所有信息。一张图像有几十万个像素,而特征点只有几百个。只使用特征点丢弃了大部分可能有用的图像信息。
- 相机有时会运动到特征缺失的地方,往往这些地方没有明显的纹理信息。例如,有时会面对一堵白墙,或者一个空荡荡的走廓。这些场景下特征点数量会明显减少,可能找不到足够的匹配点来计算相机运动。
几种思路:
- 保留特征点,但只计算关键点,不计算描述子。同时,使用光流法(Optical Flow)来跟踪特征点的运动。这样可以回避计算和匹配描述子带来的时间,但光流本身的计算需要一定时间;
- 只计算关键点,不计算描述子。同时,使用直接法(Direct Method)来计算特征点在下一时刻图像的位置。这同样可以跳过描述子的计算过程,而且直接法的计算更加简单。
- 既不计算关键点、也不计算描述子,而是根据像素灰度的差异,直接计算相机运动。
第一种方法仍然使用特征点,只是把匹配描述子替换成了光流跟踪,估计相机运动时仍使用对极几何、PnP 或 ICP 算法。而在后两个方法中,会根据图像的像素灰度信息来计算相机运动,它们都称为直接法。
使用特征点法估计相机运动时,把特征点看作固定在三维空间的不动点。根据它们在相机中的投影位置,通过最小化重投影误差(Reprojection error)来优化相机运动。
在直接法中,并不需要知道点与点之间之间的对应关系,而是通过最小化光度误差(Photometric error)来求得它们。
二、光流(Optical Flow)
直接法是从光流演变而来的。它们非常相似,具有相同的假设条件。光流描述了像素在图像中的运动,而直接法则附带着一个相机运动模型。
LK 光流法示意图
光流是一种描述像素随着时间,在图像之间运动的方法。随着时间的经过,同一个像素会在图像中运动,而希望追踪它的运动过程。计算部分像素运动的称为稀疏光流,计算所有像素的称为稠密光流。稀疏光流以 Lucas-Kanade 光流为代表,并可以在 SLAM 中用于跟踪特征点位置。
Lucas-Kanade 光流
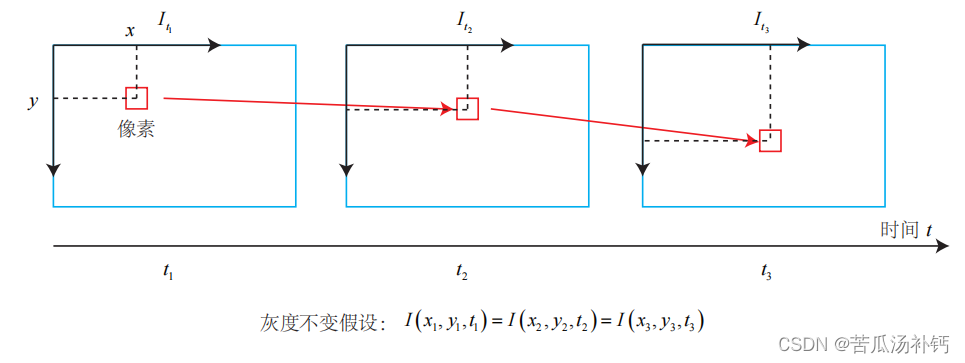
在 LK 光流中,认为来自相机的图像是随时间变化的。图像可以看作时间的函数: I(t)。那么,一个在 t 时刻,位于 (x, y) 处的像素,它的灰度可以写成:
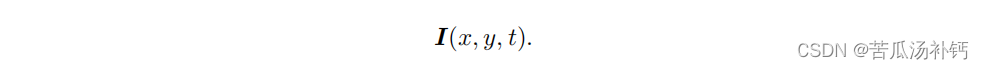 这种方式把图像看成了关于位置与时间的函数,它的值域就是图像中像素的灰度。
这种方式把图像看成了关于位置与时间的函数,它的值域就是图像中像素的灰度。
灰度不变假设:同一个空间点的像素灰度值,在各个图像中是固定不变的。
在 LK 光流中,假设某一个窗口内的像素具有相同的运动。
光流是描述图像中像素随时间变化的位移的一种技术。Lucas-Kanade(LK)光流是一种基于局部区域的光流方法,用于估计图像中每个像素的运动矢量。该方法假设在一个小的局部区域内,图像灰度不随时间变化,从而简化了运动场的估计。
以下是Lucas-Kanade光流方法的基本思想和步骤:
-
基本假设: LK光流假设在一个小的局部窗口内,图像灰度是恒定不变的。这个窗口可以是一个小的矩形区域。
-
运动模型: 使用一个简单的运动模型,通常是二维的平移模型,来描述窗口内的像素运动。这个模型有两个参数,表示水平和垂直方向上的位移。
-
光流方程: 利用灰度恒定不变的假设,可以得到光流方程。对于一个窗口内的像素点,其灰度不随时间变化,可以表示为:
Ixu+Iyv=−It
其中,Ix 和 Iy 是图像在x和y方向上的梯度,It 是图像随时间的变化率。u 和 v 分别是像素点在水平和垂直方向上的位移。
-
方程求解: 对于每个窗口内的像素点,可以形成一个方程,构成一个线性方程组。通过求解这个方程组,可以得到每个像素点的运动矢量 u 和 v。
-
稀疏或密集估计: LK光流可以应用于稀疏点集或整个图像。在稀疏点集中,选择一些具有代表性的点进行光流估计;在密集估计中,对整个图像中的每个像素都进行估计。
Lucas-Kanade光流方法是一种常用的光流估计技术,特别适用于描述相对较小的位移。然而,它对于像素变化剧烈的区域可能表现不佳,这时候可能需要其他更复杂的光流方法。
当 t 取离散的时刻而不是连续时间时,可以估计某块像素在若干个图像中出现的位置。由于像素梯度仅在局部有效,所以如果一次迭代不够好的话,会多迭代几次这个方程。在 SLAM 中,LK 光流常被用来跟踪角点的运动。
三、实践:LK 光流
1 使用 TUM 公开数据集
准备了若干张数据集图像,存放在程序目录中的 data/文件夹下。来自于慕尼黑工业大学(TUM)提供的公开 RGB-D 数据集,称之为 TUM 数据集。
http://vision.in.tum.de/data/datasets/rgbd-dataset/download它含有许多个 RGB-D 视频,可以作为 RGB-D 或单目 SLAM 的实验数据。它还提供了用运动捕捉系统测量的精确轨迹,可以作为标准轨迹以校准 SLAM 系统。
数据位于本章目录的 data/下,以压缩包形式提供(data.tar.gz)。由于 TUM 数据集是从实际环境中采集的,需要解释一下它的数据格式(数据集一般都有自己定义的格式)。在解压后,你将看到以下这些文件:
- rgb.txt 和 depth.txt 记录了各文件的采集时间和对应的文件名。
- rgb/ 和 depth/目录存放着采集到的 png 格式图像文件。彩色图像为八位三通道,深度图为 16 位单通道图像。文件名即采集时间。
- groundtruth.txt 为外部运动捕捉系统采集到的相机位姿,格式为,可以把它看成标准轨迹。
请注意彩色图、深度图和标准轨迹的采集都是独立的,轨迹的采集频率比图像高很多。在使用数据之前,需要根据采集时间,对数据进行一次时间上的对齐,以便对彩色图和深度图进行配对。原则上,可以把采集时间相近于一个阈值的数据,看成是一对图像。并把相近时间的位姿,看作是该图像的真实采集位置。TUM 提供了一个 python 脚本“associate.py”(或使用 slambook/tools/associate.py)帮我们完成这件事。请把此文件放到数据集目录下,运行:
python associate.py rgb.txt depth.txt > associate.txt这段脚本会根据输入两个文件中的采集时间进行配对,最后输出到一个文件 associate.txt。输出文件含有被配对的两个图像的时间、文件名信息,可以作为后续处理的来源。
2 使用 LK 光流
使用 LK 的目的是跟踪特征点。对第一张图像提取 FAST 角点,然后用 LK 光流跟踪它们,并画在图中。slambook/ch8/useLK/useLK.cpp
根据《视觉slam十四讲》实践,结果如下:

也可以自己写一个程序实现:
import cv2
import numpy as np
# 读取第一张图像
img1 = cv2.imread('image1.jpg', 0)
# 初始化FAST角点检测器
fast = cv2.FastFeatureDetector_create()
# 在第一张图像中检测FAST角点
keypoints = fast.detect(img1, None)
# 转换成NumPy数组
pts1 = np.array([kp.pt for kp in keypoints], dtype=np.float32).reshape(-1, 1, 2)
# 创建一个空图像,用于绘制角点
img_with_keypoints = np.copy(img1)
img_with_keypoints = cv2.cvtColor(img_with_keypoints, cv2.COLOR_GRAY2BGR)
# 用红色标记角点
cv2.drawKeypoints(img_with_keypoints, keypoints, img_with_keypoints, color=(0, 0, 255))
# 读取第二张图像
img2 = cv2.imread('image2.jpg', 0)
# 使用Lucas-Kanade光流跟踪角点
pts2, status, error = cv2.calcOpticalFlowPyrLK(img1, img2, pts1, None)
# 筛选跟踪失败的点
good_pts1 = pts1[status == 1]
good_pts2 = pts2[status == 1]
# 在第二张图像上绘制跟踪结果
for i, (new, old) in enumerate(zip(good_pts2, good_pts1)):
a, b = old.ravel()
c, d = new.ravel()
img_with_keypoints = cv2.line(img_with_keypoints, (int(a), int(b)), (int(c), int(d)), (0, 255, 0), 2)
img_with_keypoints = cv2.circle(img_with_keypoints, (int(c), int(d)), 5, (0, 255, 0), -1)
# 显示结果图像
cv2.imshow('Tracking with LK Optical Flow', img_with_keypoints)
cv2.waitKey(0)
cv2.destroyAllWindows()四、直接法(Direct Methods)
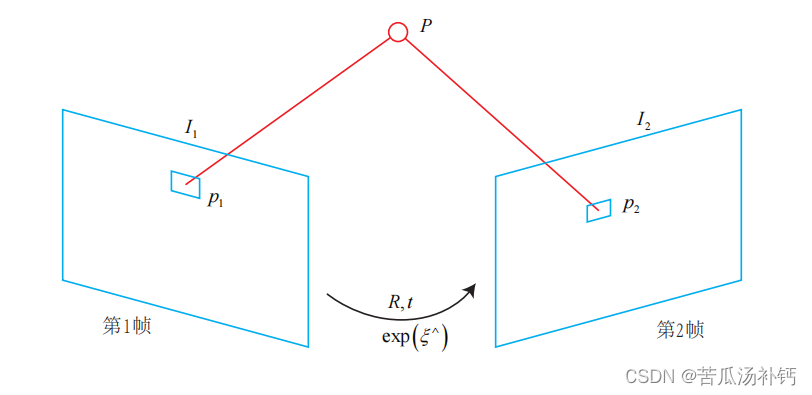
P 是一个已知位置的空间点,根据 P 的来源,可以把直接法进行分类:
1. P 来自于稀疏关键点,称之为稀疏直接法。通常使用数百个至上千个关键点,并且像 L-K 光流那样,假设它周围像素也是不变的。这种稀疏直接法不必计算描述子,并且只使用数百个像素,因此速度最快,但只能计算稀疏的重构。
2. P 来自部分像素。如果像素梯度为零,整一项雅可比就为零,不会对计算运动增量有任何贡献。因此,可以考虑只使用带有梯度的像素点,舍弃像素梯度不明显的地方。这称之为半稠密(Semi-Dense)的直接法,可以重构一个半稠密结构。
3. P 为所有像素,称为稠密直接法。稠密重构需要计算所有像素(一般几十万至几百万个),因此多数不能在现有的 CPU 上实时计算,需要 GPU 的加速。但是,梯度不明显的点,在运动估计中不会有太大贡献,在重构时也会难以估计位置。
从稀疏到稠密重构,都可以用直接法来计算。它们的计算量是逐渐增长的。稀疏方法可以快速地求解相机位姿,而稠密方法可以建立完整地图。具体使用哪种方法,需要视机器人的应用环境而定。特别地,在低端的计算平台上,稀疏直接法可以做到非常快速的效果,适用于实时性较高且计算资源有限的场合。
五、实践:RGB-D 的直接法
1 稀疏直接法
1. 优化变量为一个相机位姿,因此需要一个位姿顶点。由于在推导中使用了李代数,故程序中使用李代数表达的 SE(3) 位姿顶点。将使用“VertexSE3Expmap”作为相机位姿。
2. 误差项为单个像素的光度误差。由于整个优化过程中 I1(p1) 保持不变,可以把它当成一个固定的预设值,然后调整相机位姿,使 I2(p2) 接近这个值。于是,这种边只连接一个顶点,为一元边。由于 g2o 中本身没有计算光度误差的边,需要自己定义一种新的边。
先来定义一种用于直接法位姿估计的边,然后,使用该边构建图优化问题并求解之。实验工程位于“slambook/ch8/directMethod”中。
2 定义直接法的边
首先来定义计算光度误差的边。按照前面的推导,还需要给出它的雅可比矩阵: slambook/ch8/directMethod/direct_sparse.cpp
在程序中,相机位姿是用浮点数表示的,投影到像素坐标也是浮点形式。为了更精细地计算像素亮度,要对图像进行插值。这里采用了简单的双线性插值,也可以使用更复杂的插值方式,但计算代价可能会变高一些。
3 使用直接法估计相机运动
定义了 g2o 边后,将节点和边组合成图,就可以调用 g2o 进行优化了。实现代码位于 slambook/ch8/directMethod/direct_sparse.cpp 中。
在这个实验中,读取数据集的 RGB-D 图像序列。以第一个图像为参考帧,然后用直接法求解后续图像的位姿。在参考帧中,对第一张图像提取 FAST 关键点(不需要描述子),并使用直接法估计这些关键点在第二个图像中的位置,以及第二个图像的相机位姿。这就构成了一种简单的稀疏直接法。最后,画出这些关键点在第二个图像中的投影。
build/direct_sparse ~/dataset/rgbd_dataset_freiburg1_desk
稀疏直接法的实验。左:误差随着迭代下降。右:参考帧与后 1 至 9 帧对比(选取部分关键点)。
在两个图像相差不多的时候,直接法会调整相机的位姿,使得大部分像素都能够正确跟踪。但是,在稍长一点的时间内,比如说 0-9 帧之间的对比,发现由于相机位姿估计不准确,特征点出现了明显的偏移现象。
4 半稠密直接法
很容易就能把程序拓展成半稠密的直接法形式。对参考帧中,先提取梯度较明显的像素,然后用直接法,以这些像素为图优化边,来估计相机运动。slambook/ch8/direct_semidense.cpp
// select the pixels with high gradiants
for ( int x=10; x<gray.cols-10; x++ )
for ( int y=10; y<gray.rows-10; y++ )
{
Eigen::Vector2d delta (
gray.ptr<uchar>(y)[x+1] - gray.ptr<uchar>(y)[x-1],
gray.ptr<uchar>(y+1)[x] - gray.ptr<uchar>(y-1)[x]
);
if ( delta.norm() < 50 )
continue;
ushort d = depth.ptr<ushort> (y)[x];
if ( d==0 )
continue;
Eigen::Vector3d p3d = project2Dto3D ( x, y, d, fx, fy, cx, cy, depth_scale );
float grayscale = float ( gray.ptr<uchar> (y) [x] );
measurements.push_back ( Measurement ( p3d, grayscale ) );
}这只是一个很简单的改动。把先前的稀疏特征点改成了带有明显梯度的像素。于是在图优化中会增加许多的边。这些边都会参与估计相机位姿的优化问题,利用大量的像素而不单单是稀疏的特征点。由于并没有使用所有的像素,所以这种方式又称为半稠密方法(Semi-dense)。把参与估计的像素取出来并把它们在图像中显示出来。
5 直接法的讨论
相比于特征点法,直接法完全依靠优化来求解相机位姿。像素梯度引导着优化的方向。如果想要得到正确的优化结果,就必须保证大部分像素梯 度能够把优化引导到正确的方向。

半稠密直接法的实验。参考帧与 2,5,8 帧的对比,绿色为参与优化的像素
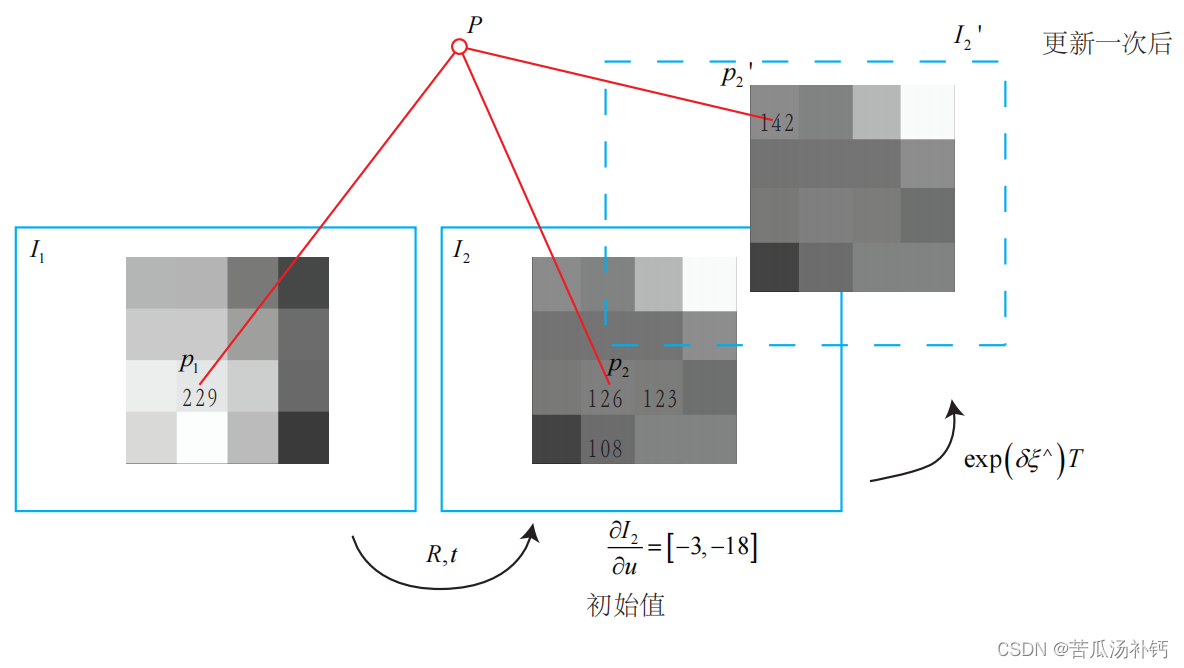
一次迭代的图形化显示
6 直接法优缺点总结
优点如下:
- 可以省去计算特征点、描述子的时间。
- 只要求有像素梯度即可,无须特征点。因此,直接法可以在特征缺失的场合下使用。比较极端的例子是只有渐变的一张图像。它可能无法提取角点类特征,但可以用直接法估计它的运动。
- 可以构建半稠密乃至稠密的地图,这是特征点法无法做到的。
另一方面,它的缺点也很明显:
- 非凸性——直接法完全依靠梯度搜索,降低目标函数来计算相机位姿。其目标函数中需要取像素点的灰度值,而图像是强烈非凸的函数。这使得优化算法容易进入极小,只在运动很小时直接法才能成功。
- 单个像素没有区分度。找一个和他像的实在太多了!——于是我们要么计算图像块,要么计算复杂的相关性。由于每个像素对改变相机运动的“意见”不一致。只能少数服从多数,以数量代替质量。
- 灰度值不变是很强的假设。如果相机是自动曝光的,当它调整曝光参数时,会使得图像整体变亮或变暗。光照变化时亦会出现这种情况。特征点法对光照具有一定的容忍性,而直接法由于计算灰度间的差异,整体灰度变化会破坏灰度不变假设,使算法失败。针对这一点,目前的直接法开始使用更细致的光度模型标定相机,以便在曝光时间变化时也能让直接法工作。
总结
直接法是介绍的重点。它是为了克服特征点法的上述缺点而存在的。直接法根据像素的亮度信息,估计相机的运动,可以完全不用计算关键点和描述子,于是,既避免了特征的计算时间,也避免了特征缺失的情况。只要场景中存在明暗变化(可以是渐变,不形成局部的图像梯度),直接法就能工作。根据使用像素的数量,直接法分为稀疏、稠密和半稠密三种。相比于特征点法只能重构稀疏特征点(稀疏地图),直接法还具有恢复稠密或半稠密结构的能力。















 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









