







在上一篇文章中,通过调取sklearn库中的tree模块来构建在鲍鱼数据集上的决策树,并对测试集鲍鱼的年龄进行预测,但是,通过调库的方式只能处理数值型的属性,若数据集中既包含连续型属性和离散型属性,则处理起来比较困难。而在本文中,将具体实现决策树的构建过程,并能分别处理连续型属性和离散型属性,最后对 鲍鱼数据集 中的鲍鱼年龄进行预测。
目录
前言
本文将具体实现决策树的构建过程,并对 鲍鱼数据集 中的鲍鱼年龄进行预测。
以下是本篇文章正文内容
一、 数据集
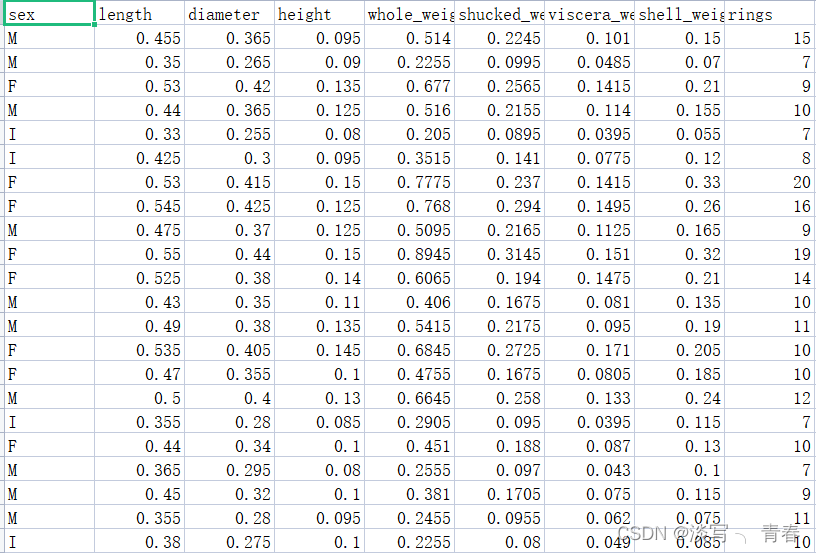
训练集:
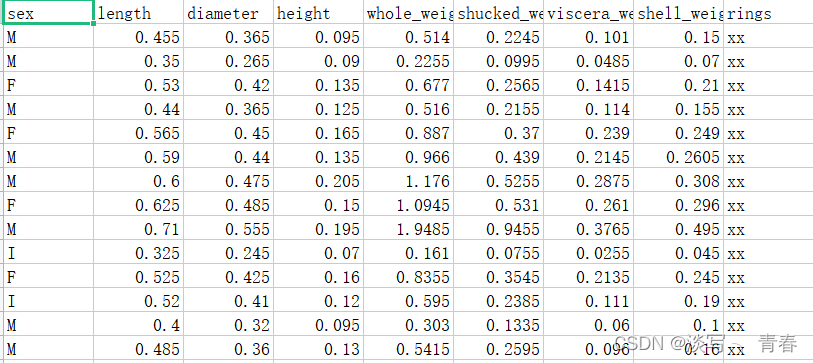
测试集:
数据集下载:
训练集:https://pan.baidu.com/s/1f4yf9vlndVar2J4cLqfjDg 提取码:U1S1
测试集:https://pan.baidu.com/s/1QQxqDsyoSrs529H49LLg2g 提取码:U2S2
二、步骤
1.引入库
代码如下:(当然有些没有用到)
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import precision_score
from scipy.stats import multivariate_normal
from mpl_toolkits.mplot3d import Axes3D
import copy
2.读入数据
代码如下:
# 读取数据
train_datas=pd.read_csv(path1,header=None)
test_datas=pd.read_csv(path2,header=None)
path为文件路径
3.数据预处理
#转换成列表
train_data=np.array(train_datas[1:][:]).tolist()
label=train_datas[:1][:]
labels=np.array(label).tolist()[0][:-1]
labelProperties = [0, 1, 1, 1, 1, 1, 1, 1] # 属性的类型,0表示离散,1表示连续
test_data=test_datas.drop(columns=[8])
#转换成列表
testData=np.array(test_data[1:][:]).tolist()4.计算信息增益
def cal_Ent(dataSet):
# 计算Ent(D)
# 训练集大小
length=len(dataSet)
# 标签字典
Ent_D_dict={}
for data in dataSet:
label=data[-1]
if label in Ent_D_dict:
Ent_D_dict[label]+=1
else:
Ent_D_dict[label]=1
Ent_D=0
for i in Ent_D_dict.values():
odd=i/length
Ent_D-=odd*np.log2(odd)
return Ent_D5.划分数据集
(连续型属性):
# 划分数据集, axis:按第几个特征划分, value:划分特征的值, LorR: value值左侧(小于)或右侧(大于)的数据集
def splitDataSet_c(dataSet, axis, value, LorR='L'):
retDataSet = []
featVec = []
if LorR == 'L':
for featVec in dataSet:
if float(featVec[axis]) < value:
retDataSet.append(featVec)
else:
for featVec in dataSet:
if float(featVec[axis]) > value:
retDataSet.append(featVec)
return retDataSet(离散型属性):
def splitDataSet(dataSet, axis, value):
retDataSet = [] #创建返回的数据集列表
for featVec in dataSet: #遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #去掉axis特征
reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return retDataSet 6.计算最优划分属性
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit_c(dataSet, labelProperty):
numFeatures = len(labelProperty) # 特征数
baseEntropy = cal_Ent(dataSet) # 计算根节点的信息熵
bestInfoGain = 0.0
bestFeature = -1
bestPartValue = None # 连续的特征值,最佳划分值
for i in range(numFeatures): # 对每个特征循环
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) # 该特征包含的所有值
newEntropy = 0.0
bestPartValuei = None
if labelProperty[i] == 0: # 对离散的特征
for value in uniqueVals: # 对每个特征值,划分数据集, 计算各子集的信息熵
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * cal_Ent(subDataSet)
else: # 对连续的特征
sortedUniqueVals = list(uniqueVals) # 对特征值排序
sortedUniqueVals.sort()
listPartition = []
minEntropy = float("inf")
for j in range(len(sortedUniqueVals) - 1): # 计算划分点
partValue = (float(sortedUniqueVals[j]) + float(
sortedUniqueVals[j + 1])) / 2
# 对每个划分点,计算信息熵
dataSetLeft = splitDataSet_c(dataSet, i, partValue, 'L')
dataSetRight = splitDataSet_c(dataSet, i, partValue, 'R')
probLeft = len(dataSetLeft) / float(len(dataSet))
probRight = len(dataSetRight) / float(len(dataSet))
Entropy = probLeft * cal_Ent(
dataSetLeft) + probRight * cal_Ent(dataSetRight)
if Entropy < minEntropy: # 取最小的信息熵
minEntropy = Entropy
bestPartValuei = partValue
newEntropy = minEntropy
infoGain = baseEntropy - newEntropy # 计算信息增益
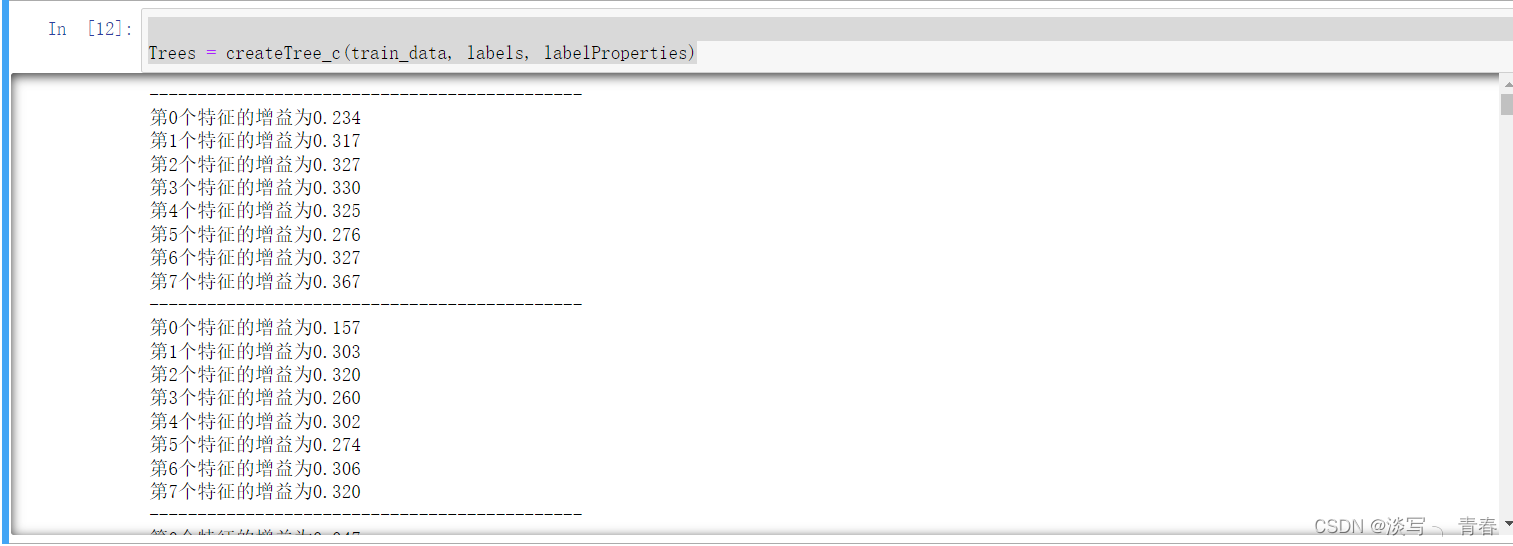
print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if infoGain > bestInfoGain: # 取最大的信息增益对应的特征
bestInfoGain = infoGain
bestFeature = i
bestPartValue = bestPartValuei
return bestFeature, bestPartValuedef majorityCnt(classList):
classCount = {}
for vote in classList: #统计classList中每个元素出现的次数
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
return sortedClassCount[0][0]7.构建决策树
# 创建树, 样本集 特征 特征属性(0 离散, 1 连续)
def createTree_c(dataSet, labels, labelProperty):
print("---------------------------------------------")
# print dataSet, labels, labelProperty
classList = [example[-1] for example in dataSet] # 类别向量
if classList.count(classList[0]) == len(classList): # 如果只有一个类别,返回
return classList[0]
if len(dataSet[0]) == 1: # 如果所有特征都被遍历完了,返回出现次数最多的类别
return majorityCnt(classList)
bestFeat, bestPartValue = chooseBestFeatureToSplit_c(dataSet,
labelProperty) # 最优分类特征的索引
if bestFeat == -1: # 如果无法选出最优分类特征,返回出现次数最多的类别
return majorityCnt(classList)
if labelProperty[bestFeat] == 0: # 对离散的特征
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
labelsNew = copy.copy(labels)
labelPropertyNew = copy.copy(labelProperty)
del (labelsNew[bestFeat]) # 已经选择的特征不再参与分类
del (labelPropertyNew[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueValue = set(featValues) # 该特征包含的所有值
for value in uniqueValue: # 对每个特征值,递归构建树
subLabels = labelsNew[:]
subLabelProperty = labelPropertyNew[:]
myTree[bestFeatLabel][value] = createTree_c(
splitDataSet(dataSet, bestFeat, value), subLabels,
subLabelProperty)
else: # 对连续的特征,不删除该特征,分别构建左子树和右子树
bestFeatLabel = labels[bestFeat] + '<' + str(bestPartValue)
myTree = {bestFeatLabel: {}}
subLabels = labels[:]
subLabelProperty = labelProperty[:]
# 构建左子树
valueLeft = '是'
myTree[bestFeatLabel][valueLeft] = createTree_c(
splitDataSet_c(dataSet, bestFeat, bestPartValue, 'L'), subLabels,
subLabelProperty)
# 构建右子树
valueRight = '否'
myTree[bestFeatLabel][valueRight] = createTree_c(
splitDataSet_c(dataSet, bestFeat, bestPartValue, 'R'), subLabels,
subLabelProperty)
return myTree
Trees = createTree_c(train_data, labels, labelProperties)运行结果:
三.预测
# 测试算法
def classify_c(inputTree, featLabels, featLabelProperties, testVec):
firstStr = list(inputTree.keys())[0] # 根节点
firstLabel = firstStr
lessIndex = str(firstStr).find('<')
if lessIndex > -1: # 如果是连续型的特征
firstLabel = str(firstStr)[:lessIndex]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstLabel) # 跟节点对应的特征
classLabel = None
for key in secondDict.keys(): # 对每个分支循环
if featLabelProperties[featIndex] == 0: # 离散的特征
if testVec[featIndex] == key: # 测试样本进入某个分支
if type(secondDict[key]).__name__ == 'dict': # 该分支不是叶子节点,递归
classLabel = classify_c(secondDict[key], featLabels,
featLabelProperties, testVec)
else: # 如果是叶子, 返回结果
classLabel = secondDict[key]
else:
partValue = float(str(firstStr)[lessIndex + 1:])
# print(testVec[featIndex],partValue)
if float(testVec[featIndex]) < partValue: # 进入左子树
if type(secondDict['是']).__name__ == 'dict': # 该分支不是叶子节点,递归
classLabel = classify_c(secondDict['是'], featLabels,
featLabelProperties, testVec)
else: # 如果是叶子, 返回结果
classLabel = secondDict['是']
else:
if type(secondDict['否']).__name__ == 'dict': # 该分支不是叶子节点,递归
classLabel = classify_c(secondDict['否'], featLabels,
featLabelProperties, testVec)
else: # 如果是叶子, 返回结果
classLabel = secondDict['否']
return classLabelfor i in range(len(testData)):
testClass = classify_c(Trees, labels, labelProperties, testData[i])
print("第",i,"条测试数据的预测ring为:",testClass)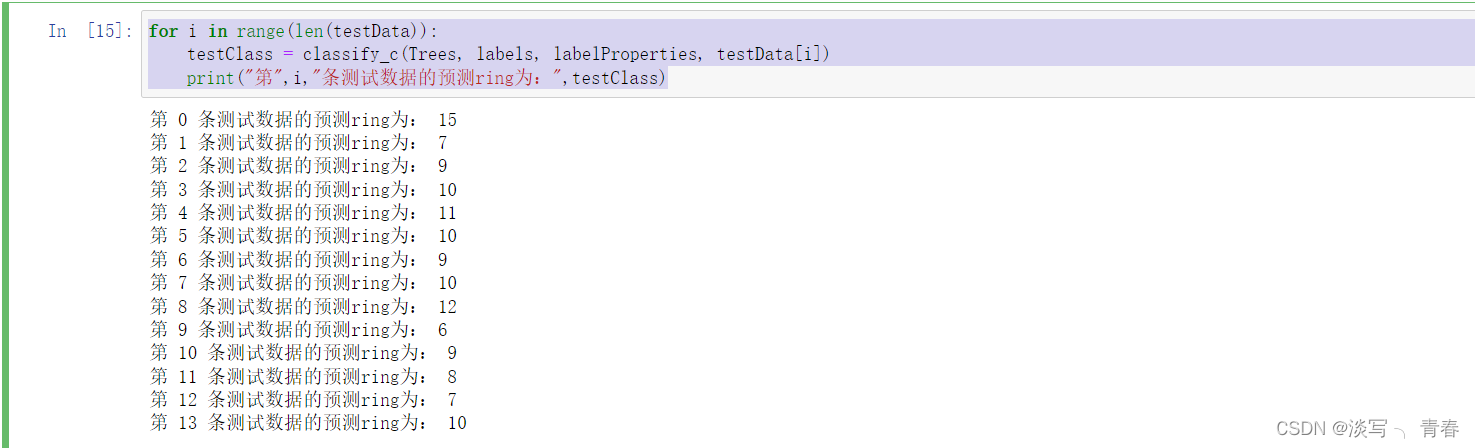 与调库的方法进行对比:
与调库的方法进行对比:
参考上一篇文章:
调库预测的结果:
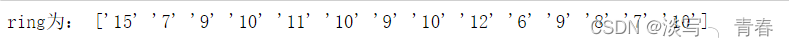 发现结果一样!
发现结果一样!
总结
以上就是实现决策树算法的所有内容,当然以上算法也可以处理其他的数据集,无论是离散属性和连续属性都可以处理。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









