




前言
DINOv3 是一系列多功能视觉基础模型,无需微调即可在各种设置中优于专业技术水平。DINOv3 产生高质量的密集特征,在各种视觉任务中实现出色的性能,显着超越以前的自监督和弱监督基础模型。
模型型号介绍
以下是按照 DINOv3 论文中描述的方法训练的 Vision Transformer 和 ConvNeXt 模型所提供的 12 种模型变体:
- 10 个模型在 Web 数据上预训练(LVD-1689M 数据集)
- 从头开始训练的ViT-7B
- 从 ViT-7B 中蒸馏出来的 ViT-S/S+/B/L/H+
- 从 ViT-7B 中提炼而来的 ConvNeXt-{T/S/B/L} 型号
- 2 个在卫星数据上预训练的模型(SAT-493M 数据集)
- 从头开始训练的ViT-7B
- 从 ViT-7B 中蒸馏出来的ViT-L
模型输入和输出
每个基于 Transformer 的模型都采用图像作为输入,并返回类令牌、补丁令牌(和注册器令牌)。这些模型遵循 ViT 架构,补丁大小为 16。对于 224x224 映像,这将产生 1 个类令牌 + 4 个寄存器令牌 + 196 个补丁令牌 = 201 个令牌(对于具有寄存器的 DINOv2,这导致 1 + 4 + 256 = 261 个令牌)。
如果图像形状是补丁大小的倍数,则模型可以接受更大的图像。如果未验证此条件,则模型将裁剪到最接近的补丁大小的较小倍数。
相关地址
-
Github Repository: https://github.com/facebookresearch/dinov3
-
Hugginface地址: https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
相关的介绍可以参考 https://huggingface.co/facebook/dinov3-vit7b16-pretrain-lvd1689m
权重下载
- huggingface(目前无法使用):目前在huggingface上下载需要获取权限(刚上线的时候还是不用的,所以还是要及时下载)
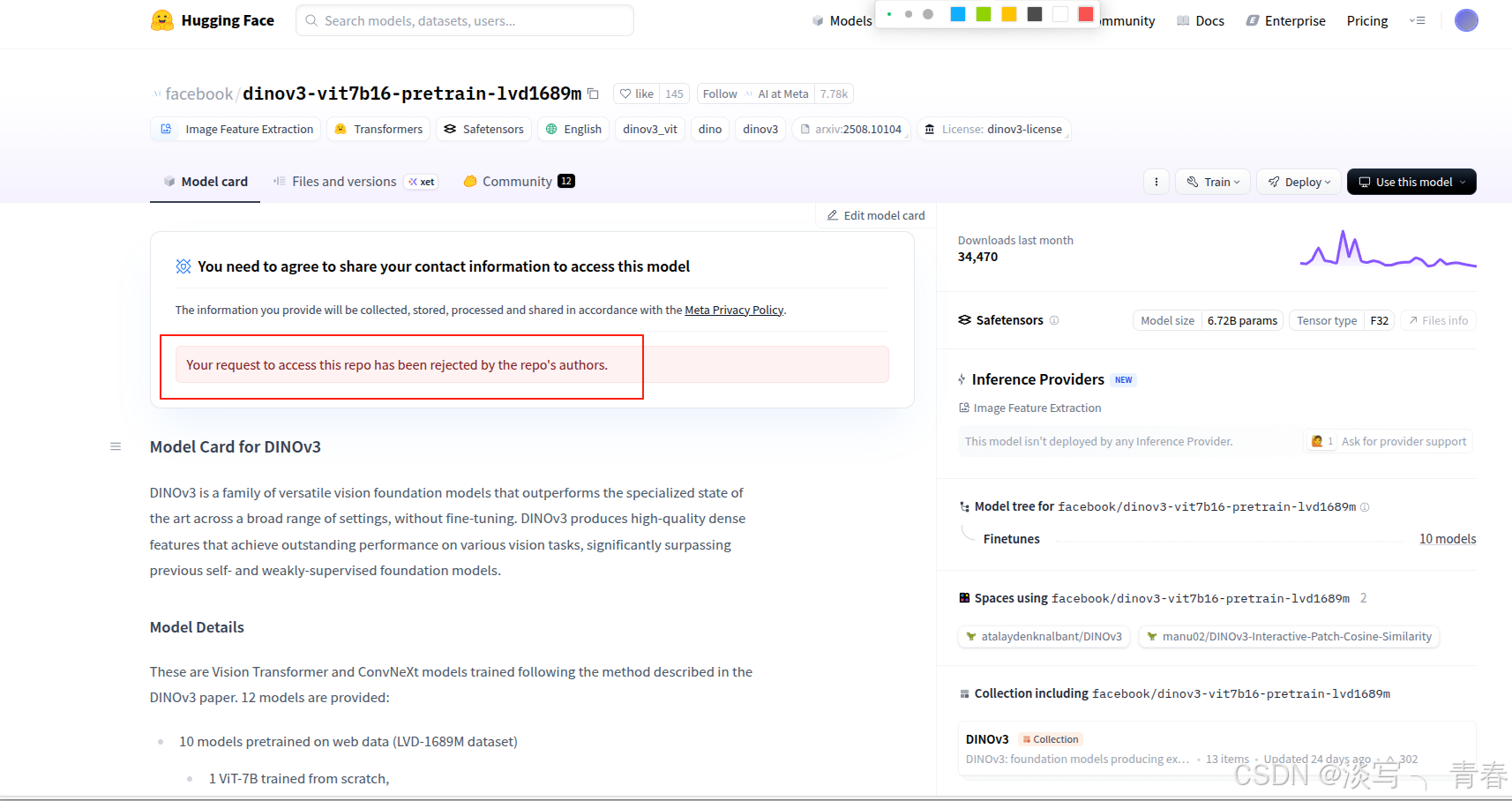
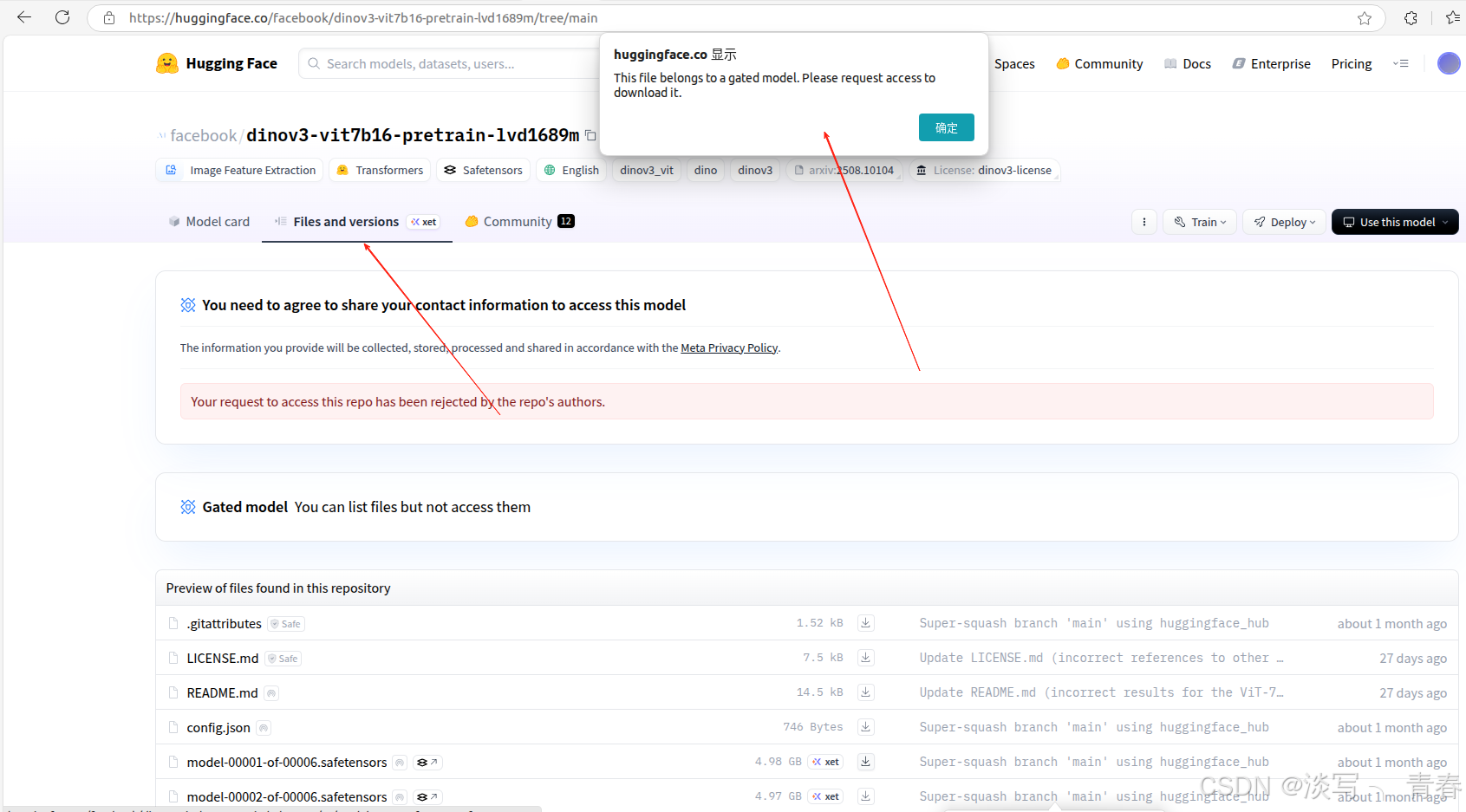
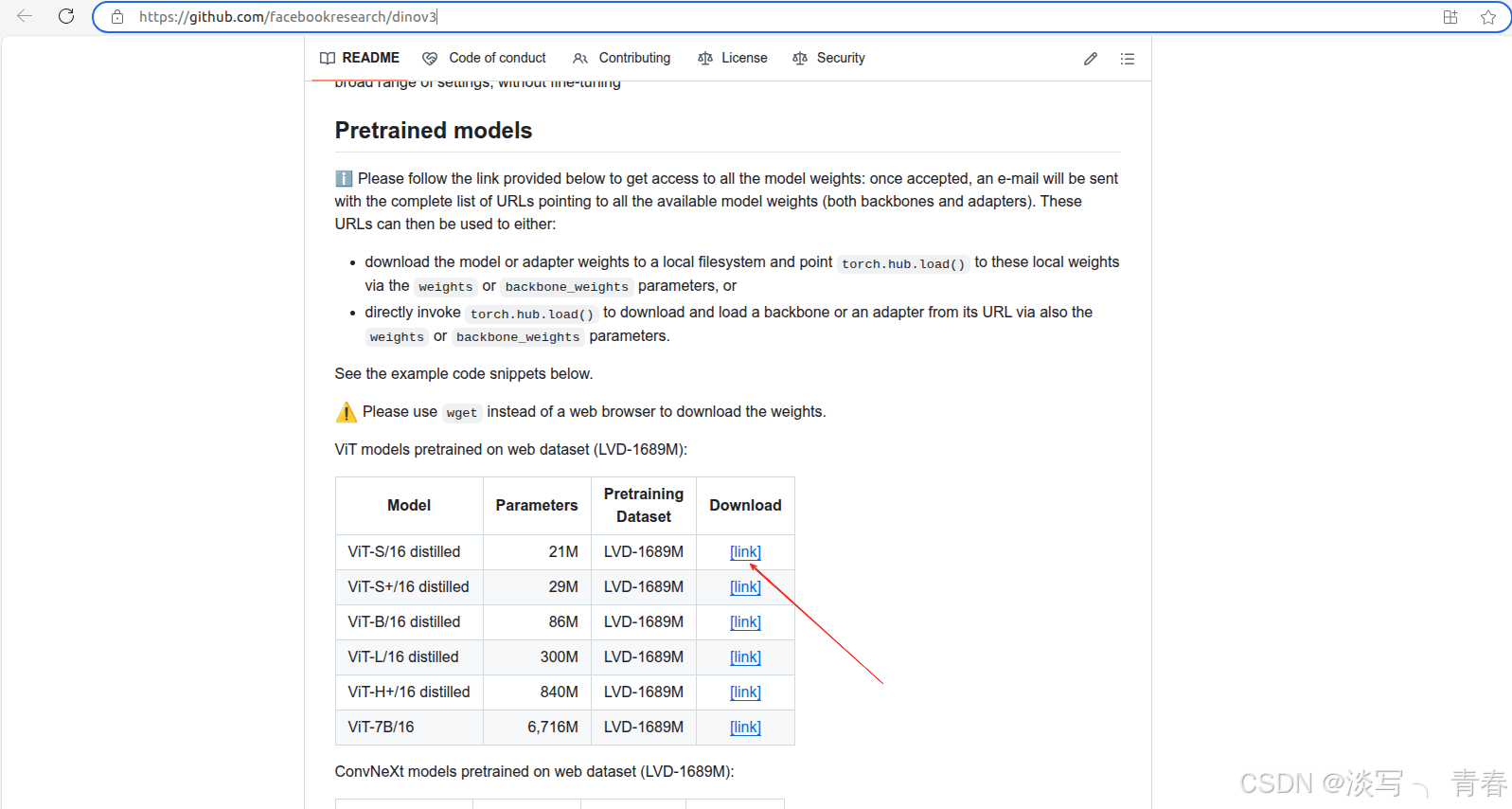
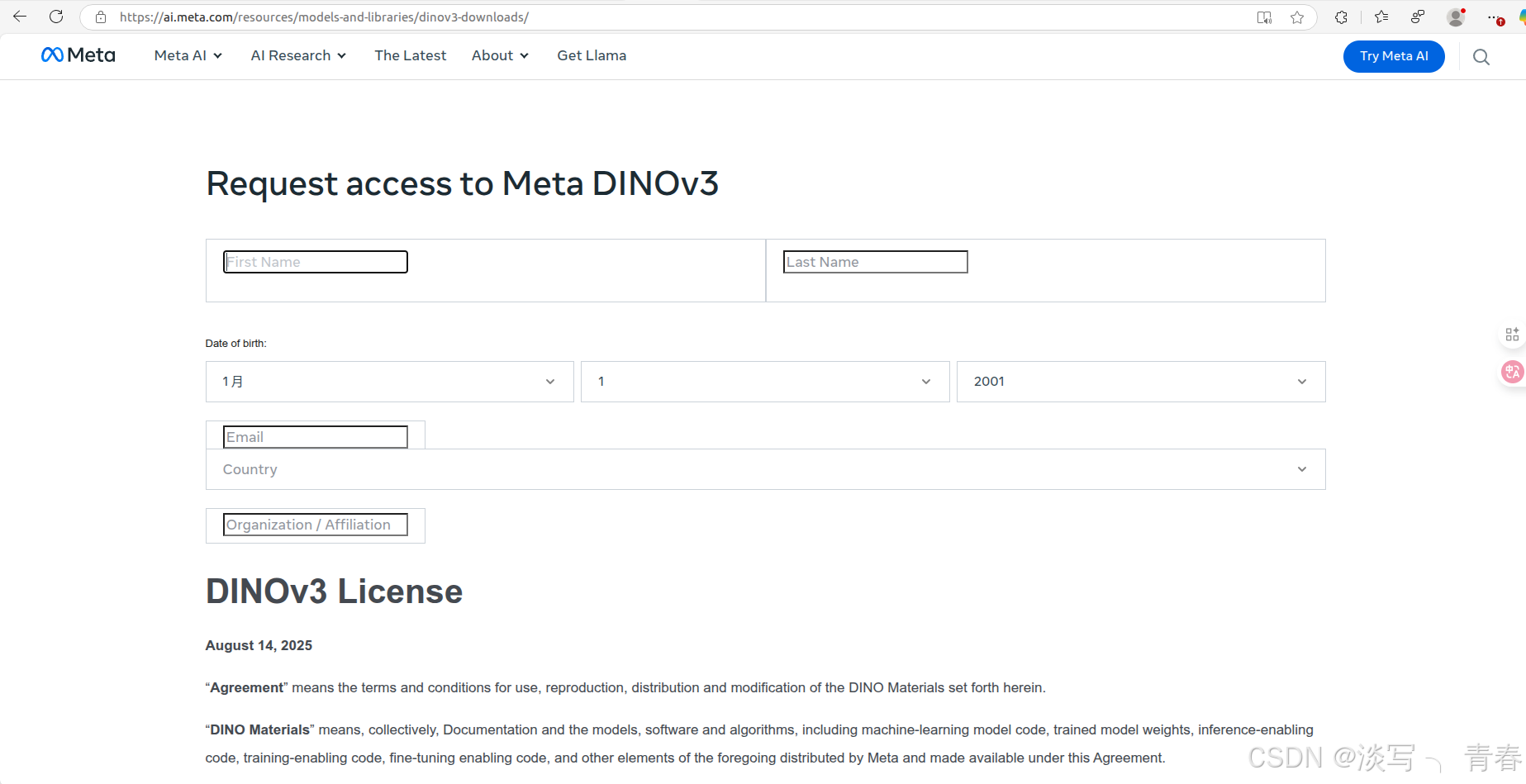
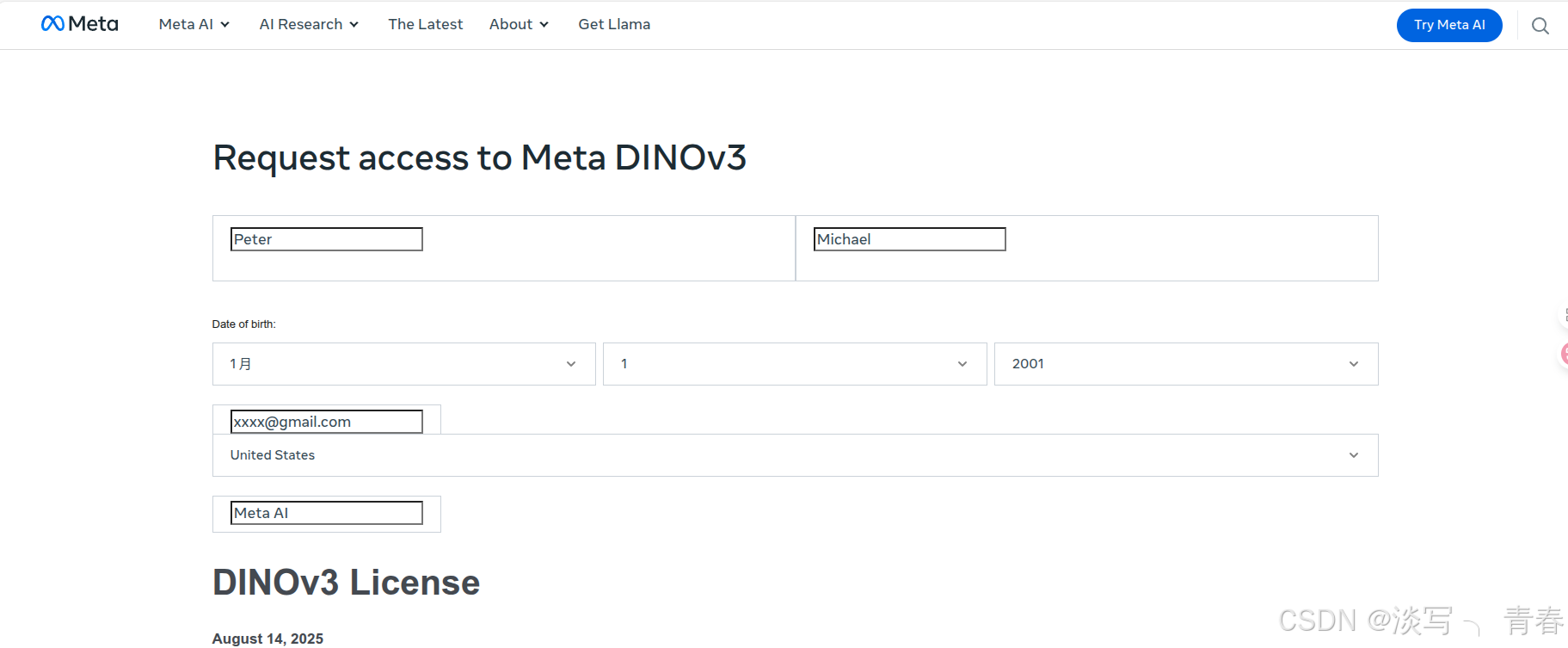
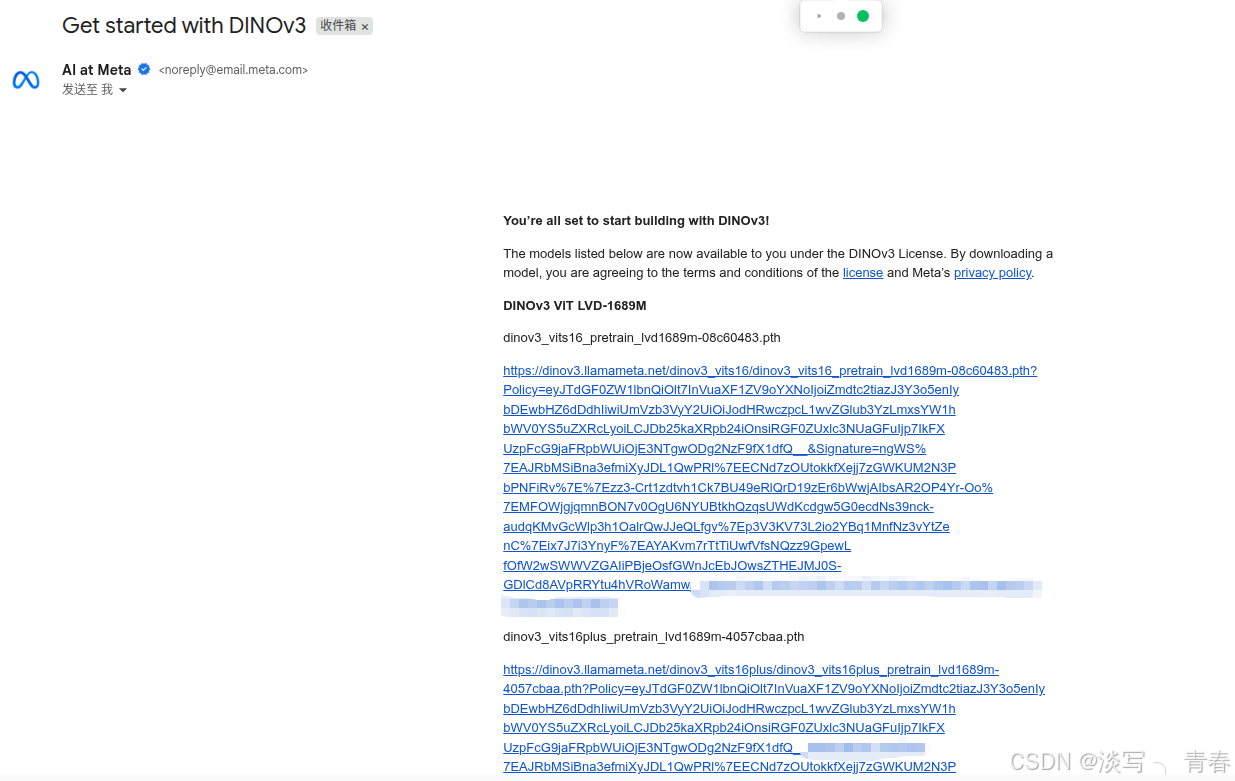
- github仓库(需申请后可正常使用): 在页面中点击模型下载链接(见下图1),并填写相关信息即可。为提高申请成功率,建议使用美国 IP,姓名可随意填写英文,邮箱推荐使用 Gmail,地区选择美国,机构可填写 Meta AI。通常几分钟后即可收到包含下载地址的邮件,点击其中的链接即可获取权重文件。

















 4005
4005








 到【灌水乐园】发言
到【灌水乐园】发言







