







目录
4.2.1 Reconstruction at Two Scale Levels
4.2.2 Reconstruction at Three Scale Levels
5.5. Transfer Learning on Downstream Datasets
5.5.1 Land Cover Classification
5.5.2 Multi-Label Classification
论文:http://arxiv.org/abs/2403.05419
开源代码:https://github.com/techmn/satmae_pp
0.摘要
无监督学习的最新进展表明,通过对大量未标记数据进行预训练,大型视觉模型能够在下游任务上取得有希望的结果。由于大量未标记数据的可用性,这种预训练技术最近也在遥感领域进行了探索。与标准的自然图像数据集不同,遥感数据是通过各种传感器技术获取的,并且表现出不同范围的尺度变化和模式。现有的卫星图像预训练方法要么忽略遥感图像中存在的尺度信息,要么限制自己只使用单一类型的数据模式。
在本文中,我们重新访问变压器预训练和利用多尺度信息,有效地利用了多种模式。我们提出的方法,名为SatMAE++,执行多尺度预训练,并利用基于卷积的上采样块在更高尺度上重建图像,使其可扩展到包括更多尺度。与已有的研究成果相比,本文提出的SatMAE++多尺度预训练对光学和多光谱图像都同样有效。在六个数据集上进行的广泛实验揭示了所提出的贡献的优点,从而在所有数据集上实现了最先进的性能。在BigEarthNet数据集的多标签分类任务中,SatMAE++实现了2.5%的平均精度(mAP)增益。
1.绪论
遥感采用广泛的传感器技术,通过卫星和飞机获取对地观测和监测数据。根据传感器技术和高度的不同,所获得的数据在地面样本距离(GSD)方面可能有所不同。GSD是指在地面上测量到的两个相邻像素之间的距离,即图像中GSD为0.3米,表示图像中相邻像素在地面上的距离为0.3米。因此,根据图像的GSD大小,大小为10 × 10像素的图像可以跨越城市。因此,在一张图像中,物体的比例可能会有很大的变化。此外,从卫星捕获的多光谱(Sentinel-2)数据利用不同的传感器获取数据。因此,在同一幅图像中,多光谱数据可能具有不同的gsd。利用多光谱数据中的不同波段组合,可以突出显示不同的信息。例如,短波和近红外波段组合可用于作物和农业监测。因此,需要利用各种传感器数据的多尺度信息来完成遥感任务。
尽管利用预训练模型对大数据量进行遥感应用越来越受欢迎,但遥感数据中的多尺度信息很少被视觉界利用。近年来,遥感数据的自监督学习得到了广泛的探索[2,16 - 18]。
SatMAE[5]证明了对各种下游遥感任务的大量数据进行变压器预训练的有效性。然而,SatMAE[5]没有利用遥感卫星图像中存在的多尺度信息,无法在具有多尺度图像的域上进行泛化。
ScaleMAE[21]是一个新引入的框架,提出了一种对光学遥感数据中存在的多尺度信息进行编码的策略。作者提出了一种基于GSD的位置编码(GSDPE)来告知模型补丁标记的位置和比例。然而,所提出的GSDPE仅限于使用RGB(光学)图像。由于多光谱(Sentinel-2)图像在不同通道下的GSD分辨率不同(详见表1),且ScaleMAE要求图像通道堆叠在一起[21],因此不能将GSDPE用于多光谱数据。此外,ScaleMAE引入了一个复杂的基于拉普拉斯金字塔的解码器,使模型能够学习多尺度表示。
另外,SatMAE显示了标准正弦位置编码可以很容易地扩展到多光谱数据。我们认为,在不使用GSDPE和复杂的基于拉普拉斯的解码器的情况下,MAE仍然可以更好地学习多尺度表示。为此,我们提出了一个框架SatMAE++,它使用标准位置编码,并利用基于卷积的上采样块在多个尺度上重建图像。
标准位置编码(Standard Positional Encoding)是一种用于将位置信息嵌入到序列数据中的技术,常用于自然语言处理领域中的序列模型,如Transformer模型。
在自然语言处理任务中,文本数据通常是一个由单词或字符组成的序列。为了在序列模型中捕捉词语或字符的位置信息,标准位置编码被引入。它能够为序列中的每个位置分配一个唯一的编码向量。
标准位置编码的常见形式是使用正弦和余弦函数来编码位置信息。对于序列中的每个位置,可以计算两个编码向量,分别对应于该位置的奇数和偶数维度。
通过将标准位置编码与输入的词向量或字符向量相加,序列模型可以同时考虑词语或字符的语义信息和位置信息。这有助于模型在处理序列数据时捕捉到位置相关的模式和依赖关系。
标准位置编码是Transformer模型中的一个重要组成部分,它使得Transformer能够在不使用循环神经网络(如LSTM)的情况下,有效地处理序列数据,并在机器翻译、文本分类、语言建模等任务中取得了显著的成果。
总的来说,我们的贡献是:
•我们通过经验证明,标准位置编码以及多尺度重建鼓励模型学习更好的特征表示。
•基于我们的观察,我们提出了一种简单而有效的多尺度预训练方法,称为SatMAE++,它在光学和多光谱卫星图像上都取得了令人印象深刻的性能。
•我们在六个数据集上进行了广泛的实验,以验证我们的多尺度预训练框架的有效性。我们的SATMAE++在所有六个数据集上设置了新的最先进的技术。在土地覆盖分类的下游任务上,我们的SatMAE++实现了比基线3.6%的绝对增益[5]。
2.相关工作
2.1.卫星图像的表示学习
近年来,自监督学习已被广泛用于各种遥感任务的预训练步骤,使模型能够从未标记的数据中学习到丰富的特征表示。GASSL[2]和SeCo[16]采用对比学习策略来证明预训练在不同下游任务上的有效性。Mendieta等人[17]在他们的工作中研究了持续学习策略和面具图像建模技术。SatMAE[5]利用掩膜图像建模对多光谱、时相和光学遥感数据进行建模。ScaleMAE[21]为光学卫星图像引入了一种基于地面样本距离(ground sample distance, GSD)的位置编码,对遥感数据中的比例尺信息进行编码。虽然ScaleMAE在光学卫星数据上显示了良好的结果,但其复杂的GSD位置编码限制了其在多光谱数据上的应用能力。相比之下,我们简化了从光学和多光谱卫星数据中提取多尺度信息的思路
2.2. 多尺度信息
视觉图像通常包含各种大小和比例的对象。因此,需要利用多尺度信息来学习更好的语义表示。卷积神经网络和变压器[1、7、9、10、14、15、19、20、23]采用了多尺度信息和分割任务。
ConvMAE[8]引入了一种分层掩蔽策略来学习混合卷积-变压器编码器的多尺度特征。
point - m2ae[25]提出了一种用于三维点云的多尺度自动编码器。
ScaleMAE[21]提出了一种基于拉普拉斯的解码器来学习多尺度信息。我们对该方法进行了改进,并引入了一个基于可扩展卷积的上采样块来重建多尺度的特征映射
3. 背景
Masked Auto-Encoder (MAE)
Masked Auto-Encoder (MAE) 是一种自动编码器(Auto-Encoder)的变种。自动编码器是一种无监督学习算法,用于数据降维和特征学习。它由一个编码器和一个解码器组成,通过将输入数据压缩到低维表示(编码)然后重构回原始数据(解码)来学习数据的表示。
MAE 在传统的自动编码器基础上引入了掩码(Mask)机制,以处理输入数据中的缺失值或遮挡(Masking)情况。掩码是一个与输入数据具有相同维度的二进制矩阵,其中缺失的元素或被遮挡的元素被标记为 0,而非缺失的元素保持为 1。通过将掩码与输入数据逐元素相乘,可以将缺失值或被遮挡的元素置为 0,从而在自动编码器的训练过程中忽略这些位置的信息。
MAE 的训练过程与传统的自动编码器类似,但在计算损失函数时,只考虑那些没有被掩码的输入元素与重构输出之间的差异。这样可以使得 MAE 能够对部分缺失或遮挡的数据进行建模和重构,从而能够处理带有缺失值或遮挡的数据集。
MAE 在实践中具有一定的灵活性,可以适应各种类型的数据,如图像、文本、时间序列等。它在处理缺失数据、数据修复、数据插值以及生成缺失数据样本等任务上具有应用潜力。此外,MAE 还可以与其他机器学习技术结合使用,如生成对抗网络(GAN)等,以实现更复杂的数据修复和生成任务。
Positional Encodings 位置编码
Positional Encodings 是一种用于处理序列数据的编码方法,主要应用于自然语言处理(NLP)和机器翻译领域。在这些任务中,输入数据通常是一个序列,如句子或文档。
传统的神经网络模型(如循环神经网络和卷积神经网络)在处理序列数据时,无法直接捕捉到元素之间的顺序信息,因为它们是基于固定权重的模型。为了解决这个问题,Positional Encodings 被引入到模型中,以提供序列元素的位置信息。
Positional Encodings 的基本思想是为序列中的每个元素分配一个表示其位置信息的向量。这个向量可以被添加到元素的原始表示中,从而保留了位置信息。具体来说,常用的 Positional Encodings 方法是使用正弦和余弦函数生成一系列固定的编码向量。
例如,在 Transformer 模型中,Positional Encodings 被添加到输入序列的嵌入表示中,以提供位置信息。这允许 Transformer 模型在编码和解码过程中同时考虑元素的内容和位置,从而更好地理解序列数据的语义和结构。
Positional Encodings 的设计可以根据具体任务和模型的需求进行调整。常见的设计包括基于绝对位置的编码和基于相对位置的编码。在基于绝对位置的编码中,每个位置都有唯一的编码表示。而在基于相对位置的编码中,位置之间的关系被编码为相对的偏移量。
总之,Positional Encodings 是一种用于为序列数据添加位置信息的编码方法,它在处理序列任务中起到了重要的作用,特别是在自然语言处理和机器翻译领域的 Transformer 模型中。
4. 方法
4.1 Baseline Framework
我们采用最近的SatMAE[5]框架作为我们的基线。SatMAE遵循第3节中讨论的基于普通MAE的RGB数据体系结构。为了处理多光谱数据,SatMAE根据多光谱信道的gsd进行信道分组。为了使训练稳定,减少自注意操作对记忆的要求,我们将输入的空间大小从标准的224 × 224减小到96 × 96[5]。相应地,patch大小减少为8。然后,它创建单独的补丁嵌入层,并将它们在空间维度上连接起来。SatMAE对MAE的位置编码进行了修改,加入了光谱信息。为此,为每个通道组创建单独的编码,并将其连接到xpos、i、ypos、i位置编码,使最终编码维度为d。然后,它将特征传递给转换器编码器。
与普通的MAE类似,解码器接受变压器编码器的输出,将可见标记放置到其原始位置,并添加可学习的掩码标记以获得N个标记。随后,频谱编码被添加到贴片令牌并馈送到一系列变压器块。最后,利用均方误差(MSE)损失来衡量重建质量。
局限性:尽管上述基线框架在RGB和多光谱数据上运行良好,但它没有利用遥感数据中存在的多尺度信息。此外,上述基线框架力求在具有多个尺度级别的图像的域之间进行泛化。此外,ScaleMAE[21]表明,尺度信息可以通过基于GSD的位置嵌入进行编码。然而,ScaleMAE引入的基于GSD的位置嵌入只能用于每个通道具有相同GSD分辨率的RGB数据[21]。因此,需要重新考虑SatMAE框架的设计,以学习不受单一数据模态约束的多尺度信息。
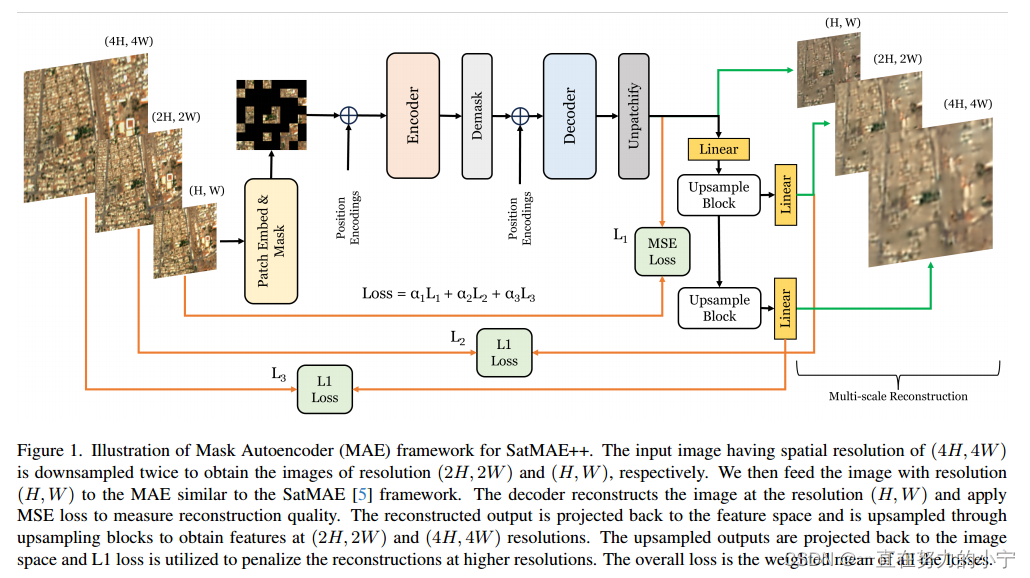
4.2 Overall Architecture
图1展示了SatMAE++的总体框架,它克服了基线框架SatMAE[5]和其他最近的多光谱(fMoW-Sentinel)和RGB数据(fMoW-RGB)的多尺度预训练方法的局限性。我们以三个尺度中的大多数为输入图像,并将最低尺度的图像馈送到SatMAE框架。基本框架接受输入图像,应用补丁嵌入和屏蔽操作,并将可见令牌提供给变压器编码器。随后,解码器取编码器的输出,重构出与最低尺度输入相同空间维度的图像。上样本块利用SatMAE模型的重建输出在更高的尺度上执行细粒度重建。更高尺度的重建鼓励模型学习多尺度表示,从而提高在各种下游任务上的性能。
上样块:图2显示了上样块的架构。它接受输入特征X∈R C×H×W,并通过转置卷积层对特征的空间分辨率进行上采样。我们对上采样特征进行归一化处理,然后应用泄漏激活操作。然后,利用由两个卷积层组成的残差块进行局部特征增强。利用线性投影层将增强特征~ X∈R C×2H×2W投影回空间域,利用平均绝对误差计算输入与重建图像之间的重建误差。接下来,我们在两个和三个尺度上详细讨论了多尺度重建过程。
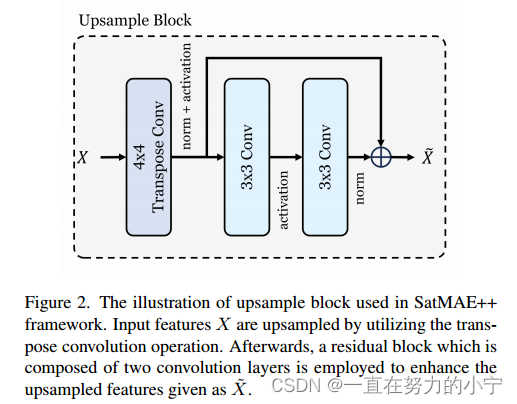
4.2.1 Reconstruction at Two Scale Levels
设I∈R C×H×W为MAE的输入图像。我们取分辨率为R C×2H×2W的图像I,并将其缩小以获得大小为R C×H×W的图像I。将图像I输入到MAE中,该MAE首先利用补丁嵌入层对输入图像进行补丁化。在多光谱输入的情况下,对不同的频段信道组使用单独的patch嵌入层。然后,将不同组的patch token沿着空间维度进行连接。我们屏蔽了75%的补丁令牌,类似于其他MAE方法。然后,将位置编码添加到可见的补丁标记中。接下来[5],我们使用不依赖于GSD信息的通用位置编码(如Eq. 1所示)。可见补丁令牌被馈送到一系列产生编码可见特征的变压器块。与SatMAE类似,解码器从变压器编码器中获取编码的可见特征,并应用线性投影来降低嵌入维数。然后,将可见特征放回其原始索引位置,并将可学习的掩码标记附加到可见标记上。然后,将RGB或多光谱位置编码添加到patch令牌中。最后,贴片令牌被馈送到解码器变压器,最后的投影层将解码的特征映射回空间域。将解码后的图像F重构为原始输入尺寸,利用均方误差计算重构质量。
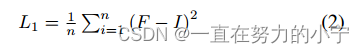
在从解码器获得重构输入后,我们使用线性投影将重构图像映射回特征空间。然后,我们利用转置卷积以(2H × 2W)的分辨率对特征映射进行上采样。上采样特征映射从由两个卷积层组成的残差块传递。最后,我们将特征投影回图像空间,得到缩放后的重构图像F,并应用L1损失来分析模型在更高尺度下的重建性能。
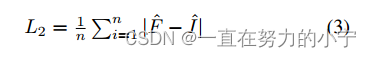
L2 =1 n滑n i=1 | F−i |(3)类似的超分辨率方法,我们在更高的尺度上利用L1损失,使模型能够学习重建实际图像值。总损失为:
![]()
4.2.2 Reconstruction at Three Scale Levels
对于多光谱数据,我们在三个尺度上重建图像,因为模型输入的分辨率比RGB数据小(RGB使用224 × 224像素)。在这里,我们以更高的分辨率R C×4H×4W取图像¯I。然后我们对图像¯I进行两次下采样,分别得到图像I∈R C×2H×2W和I∈R C×H×W。如前一节所述,我们以(H, W)的空间分辨率重建图像F。然后,应用线性投影层将数据投影到特征空间并输入到上样本块。上样块使用转置卷积将空间分辨率提高两倍,然后将其馈送到残差卷积块以获得具有空间分辨率(2H, 2W)的特征F。将特征F输入到另一个上样块中,得到尺寸为(4H, 4W)的特征F。特征F和¯F都被投影回图像空间,L1损失被用来衡量重构特征的质量。总损失为三次损失的加权平均,如下所示:


5. Experiments
在本节中,我们首先讨论主流数据集。然后,我们解释了用于主流基准测试的预训练和微调过程。然后,我们讨论了用于迁移学习实验的数据集及其微调方法。通过对SatMAE++的简化多尺度MAE预训练,进一步讨论了学习表征的性能,并给出了下游任务的微调结果。
5.1 预训练数据集
我们利用两个公开的大规模数据集在多光谱和RGB卫星数据上对视觉转换器进行预训练。
fMoW- rgb: Functional Map of World (fMoW)[4]是一个大规模公开的高分辨率卫星图像数据集。该数据集分为62个类别用于分类任务,包含约363k张训练图像和53k张测试图像。
fMoW-Sentinel: SatMAE[5]对fMoW-RGB进行了改进和扩展,用于分类任务,包括图像的Sentinel-2数据。与fMoW-RGB类似,该数据集有62个类类别。该数据集包含更多的图像,包括712874张训练图像、84939张验证图像和84966张测试图像。
重建结果:在fMoW-Sentinel数据集上的多尺度重建结果如图3所示。通过多尺度预训练,我们观察到图像重建质量的提高。此外在图4中,我们将我们的方法与基线方法(SatMAE)的重建结果进行了比较。SatMAE在可见斑块上的重建质量比掩膜斑块差得多。然而,我们的多尺度方法提高了可见和掩蔽斑块的重建质量。虽然与SatMAE相比,我们获得了良好的重建效果(见图3和图4),但我们发现,在某些情况下,我们的方法很难重建细粒度的结构细节。

5.2 fMoW-RGB的预训练和微调
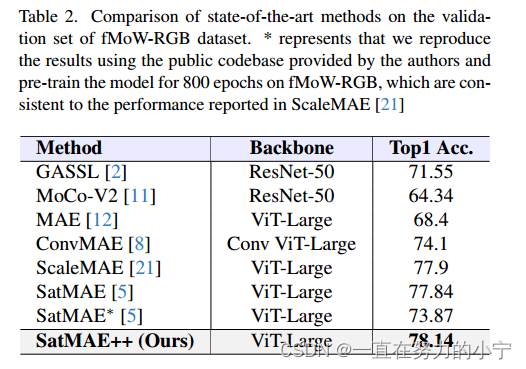
5.3 fMoW-Sentinel的预训练和微调
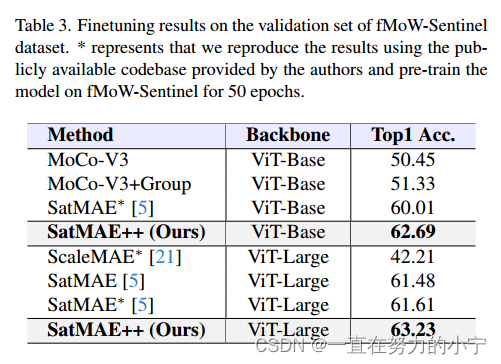
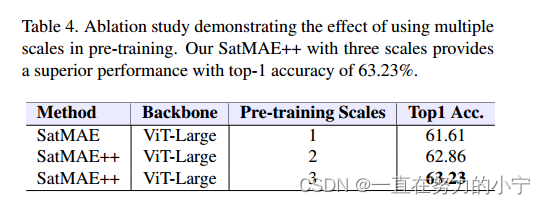
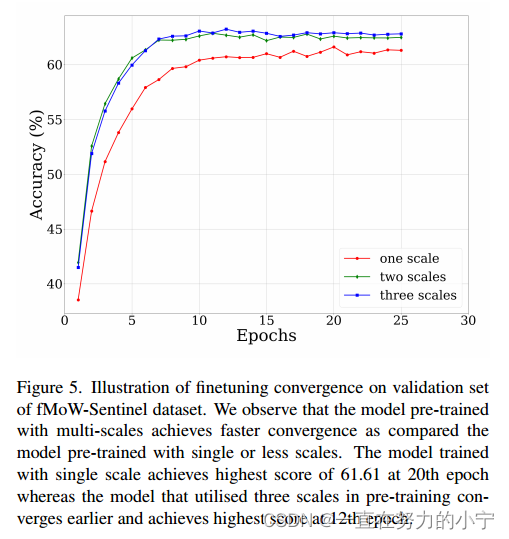
5.4. Downstream Datasets
EuroSAT[13]是一个公开的用于土地利用和土地覆盖(LULC)分类的遥感数据集。它被分为10类,包括27000张图片。数据集有RGB格式和多光谱(Sentinel-2)格式。在[5]之后,我们使用[18]提供的数据分割。
RESISC-45[3]是另一个公开的遥感场景分类数据集,包含31500张图像,有45个场景类。对于数据集的train / val分割,我们遵循[21]。
UC-Merced[24]是一个包含21个场景类的公共土地利用遥感图像数据集。每个类包括从美国地区手动选择的100张图像。在实验中,我们遵循[18]提供的数据分割。
BigEarthNet[22]是一个多标签的土地覆盖分类数据集,可公开用于研究目的。该数据集由590326张Sentinel-2图像组成,分为19类。在[5]之后,我们在实验中使用了10%的训练数据,并利用了[18]中可用的数据分割。
5.5. Transfer Learning on Downstream Datasets
迁移学习的目标是通过利用源领域(source domain)的知识来改善目标领域(target domain)的学习性能。源领域通常是一个大规模的数据集,而目标领域可能是一个相对较小的数据集。迁移学习的核心思想是,通过将源领域的知识迁移到目标领域中,可以加速目标领域的学习过程,并提高其性能。
迁移学习可以分为以下几种类型:
基于特征的迁移学习(Feature-based Transfer Learning):在这种方法中,源领域和目标领域之间共享相同的特征表示。首先,使用源领域的数据训练一个模型,然后将这个模型的特征提取器部分应用于目标领域的数据,作为目标领域的特征表示。最后,可以使用这些特征来训练一个目标领域的模型。
基于模型的迁移学习(Model-based Transfer Learning):在这种方法中,源领域和目标领域之间共享相同的模型架构,但模型参数可能不同。通常,先在源领域上训练一个模型,然后将该模型的参数初始化为目标领域的模型参数的初始值。接下来,使用目标领域的数据对模型进行微调,以适应目标领域的特点。
基于关系的迁移学习(Relation-based Transfer Learning):这种方法主要用于处理源领域和目标领域之间的分布差异。它通过学习源领域和目标领域之间的关系,来推断目标领域的标签或概率分布。这种方法可以通过对源领域和目标领域的数据进行关系建模来实现。
5.5.1 Land Cover Classification
我们在EuroSAT[13]、RESISC-45[3]和UC-Merced[24]三个公开的遥感数据集上进行了土地覆盖分类任务的迁移学习实验。我们利用fMoW-RGB调优实验中使用的配置设置在这些数据集上进行迁移学习。
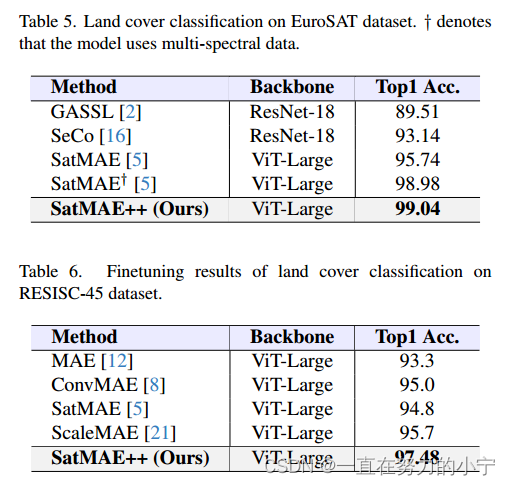
EuroSAT上的微调:我们在表5中给出了EuroSAT数据集的微调结果。我们观察到,与其他方法相比,多尺度预训练方法提供了合理的改进。值得注意的是,在不使用多光谱信息的情况下,SatMAE++超过了最先进的SatMAE的性能分数,达到了99.01%的准确率。
resiscc -45上的微调:表6显示了resiscc -45数据集上的场景分类性能。在最近的方法中,ScaleMAE[21]取得了更好的性能,然而,当使用我们方法的预训练权值进行微调时,viti - large超过了ScaleMAE得分,达到了97.48%的准确率。
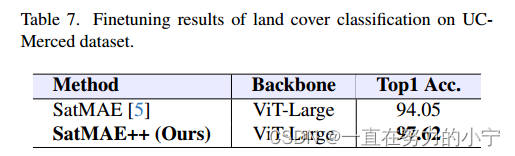
UC-Merced上的微调:我们进一步报告了在另一个流行的LULC数据集上多尺度MAE预训练的有效性(表7)。在这里,我们分别通过加载SatMAE和我们的方法的预训练权值,报告了在UC-Merced数据集上对viti - large模型进行微调的结果。当使用SatMAE预训练的权值时,ViT-Large模型的准确率为94.05%。然而,当通过加载我们方法的预训练权值进行微调时,ViTLarge的性能提高了约3.6%。
5.5.2 Multi-Label Classification
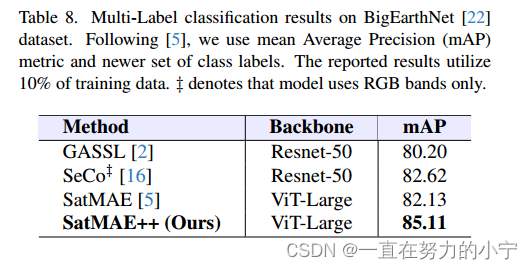
最后,我们报告了我们的方法在多标签分类任务上的性能。我们通过加载fMoW-Sentinel数据集的预训练权值,对BigEarthNet[22]数据集上的ViT-Large模型进行微调。我们保留了与fMoW-Sentinel实验中使用的相同配置进行微调。由于任务是多标签分类,因此用多标签软裕度损失代替软目标交叉熵损失。接下来[5],我们使用平均精度度量作为模型的性能度量。
表8显示了BigEarthNet数据集上的调优结果。与其他下游任务类似,我们的框架在多标签分类任务的情况下表现良好。与最先进的框架相比,SeCo[16]表现相当好,达到了82.62%的最先进分数。与SeCo[16]相比,SatMAE[5]的得分略低,为82.13%。然而,我们的框架提供了显著的改进,达到了85.11%的平均精度分数。
6. Conclusion
遥感图像提供了广泛的分辨率和光谱波段,其中包含了多尺度信息。现有的最先进的方法难以有效地利用多尺度信息和多光谱数据。我们提出了一个名为SatMAE++的框架来整合多尺度信息,从而提高模型性能并在微调过程中实现更快的收敛。我们的SatMAE++很容易扩展到多个规模级别,并且不局限于单一类型的数据模式。在几个下游和主流数据集上进行的大量实验揭示了我们的方法的有效性。未来的工作包括将提出的多尺度预训练扩展到密集预测任务。
SatMAE++的关键创新之一是在多个尺度级别上进行图像的重建。这包括使用基于卷积的上采样块来在更高的尺度上重建图像,同时维持在原始较低尺度上的重建能力。具体来说,它先在最低尺度上使用Transformer编码器进行特征提取,然后通过解码器重建图像。接着,利用上采样块将解码器的输出上采样到更高的尺度,并在每个尺度上进行图像重建,从而使模型能够学习到不同尺度上的特征表示。
SatMAE++的训练包括两个阶段:预训练和微调。在预训练阶段,模型在大规模未标注的卫星图像数据集(如fMoW-RGB和fMoW-Sentinel)上进行训练,目标是学习图像的有效特征表示。在微调阶段,预训练得到的模型权重被迁移到具体的下游任务上,如土地覆盖分类,通过少量标注数据进行微调,以优化模型在特定任务上的表现。


















 2259
2259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









