










深度学习简单调参实验二——手写数字问题
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别等领域,大大缩短了业务处理时间,提升了工作效率和质量。
手写数字识别常用的数据集是 mnist,该数据集是入门机器学习、深度学习 经典的数据集。
项目结构和数据结构:
使用数据集为经典的MNIST数据集。MNIST应该算是一个被用烂了的数据集了,非常非常适合初学,数据量比较小,数据处理、训练和预测的时间都比较短,可以很好地用于把控网络搭建的整个过程。
任务要求和思路:
# 要求Accuracy的精准度大于96%
# 思路:
# 尝试不同的迭代器
# 调整lr参数
# epoch次数是否需要增大,可能还未到达最优点的周围位置,也就是训练次数不够
# 初始化的w和b的维度是否能做相应的修改使得其表达能力更强
# 能否增加网络的层数
# 能否使用其他激活函数
# 能否使用其他损失函数
# 能否冻结住某一层参数不更新
导入相关依赖与设定随机种子
import torch
import torch.optim as optim
from torch.nn import functional as F
import torch.nn as nn
import torchvision
seed = 233242
# torch.manual_seed(seed) # 为CPU设置随机种子
torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子
# # torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子
初始化w1,b1的值
#初始化w1,b1的值
w1, b1 = torch.randn(200, 784, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\
torch.zeros(10, requires_grad=True)
# w1, b1 = torch.randn(500, 784, requires_grad=True),\
# torch.zeros(500, requires_grad=True)
# w2, b2 = torch.randn(200, 500, requires_grad=True),\
# torch.zeros(200, requires_grad=True)
# w3, b3 = torch.randn(100, 200, requires_grad=True),\
# torch.zeros(100, requires_grad=True)
# w4, b4 = torch.randn(10, 100, requires_grad=True),\
# torch.zeros(10, requires_grad=True)
将w1,w2,w3赋予特定的值
#将w1,w2,w3赋予特定的值
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
# torch.nn.init.kaiming_normal_(w4)
前向传播
#前向传播
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x) # logits
# x = x @ w1.t() + b1
# x = F.leaky_relu(x)
# x = x @ w2.t() + b2
# x = F.leaky_relu(x)
# x = x @ w3.t() + b3
# x = F.leaky_relu(x) # logits
# x = x @ w4.t() + b4
# x = torch.relu(x) # logits
return x
部分参数设置
learning_rate = 0.04
epochs = 1
batch_size = 64
加载数据集,数据预处理
#加载数据集,数据预处理
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data',
train=True,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])), batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data/',
train=False,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307, ), (0.3081, ))
])),batch_size=batch_size*10,shuffle=False)
权重更新和梯度下降算法、loss函数
#将权重放入list中
params=[w1, b1, w2, b2, w3, b3]
#不把w4,b4加入params就不会更新w4,b4的值也就冻住了w4,b4
#params=[w1, b1, w2, b2, w3, b3,w4,b4]
#一种梯度下降的算法()
optimizer = optim.SGD(params, lr=learning_rate)
# optimizer =optim.Adagrad(params, lr=learning_rate, lr_decay=0, weight_decay=0, initial_accumulator_value=0)
# optimizer = optim.Adam(params, lr=learning_rate, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
#交叉熵损失函数
criterion = nn.CrossEntropyLoss()
Train
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
#图像的大小为28*28
data = data.view(-1, 28 * 28)
#前向传播求出预测的值
logits = forward(data)
#求出损失函数
loss = criterion(logits, target)
#梯度清零防止梯度爆炸
optimizer.zero_grad()
#反向传播更新w,b
loss.backward()
#只有用了这个模型才会更新
optimizer.step()
if batch_idx % 100 == 0:
#查看每100个batch后Accuracy和loss值
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
test_loss += criterion(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
我的最佳结果
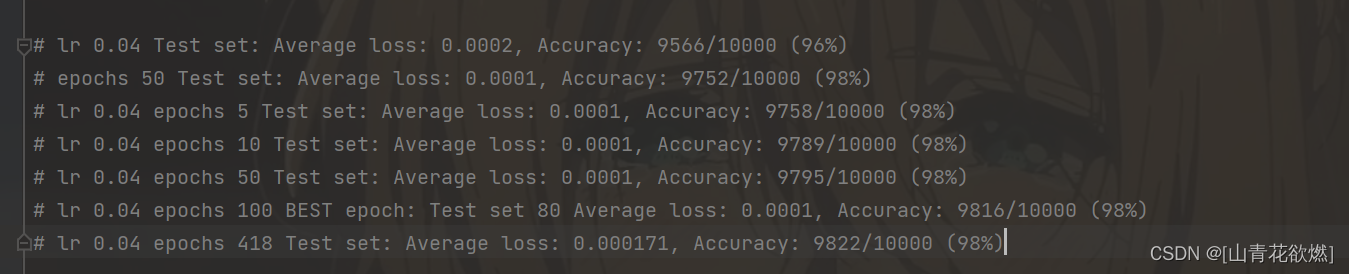
最后祝大家学习愉快,调参涨分啦,一起学习鸭!
















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











