










深度学习简单调参实验一——一元线性回归求近似解
线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析,即简单线性回归。
简单线性回归:所谓简单,是指只有一个样本特征,即只有一个自变量;所谓线性,是指方程是线性的;所谓回归,是指用方程来模拟变量之间是如何关联的。也就是说,我们需要一条直线,最大程度的拟合样本特征和样本数据标记之间的关系
项目结构和数据结构:
导入相关依赖包
#首先需要在Terminal中的指定conda虚拟环境中使用
# pip install numpy
# pip install matplotlib
import numpy as np
import matplotlib.pyplot as plt
#实验内容一元线性回归求近似解
loss函数
#loss损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。
def compute_error_for_line_given_points(b,w,points):
totalError=0
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
totalError+=((w*x+b)-y)**2
return totalError/float(len(points))
迭代计算
#通过输入大量的点去迭代
def step_gradient(b_current,w_current,points,learningRate):
b_gradient=7#此处不一定需要设置为0
w_gradient=1#此处不一定需要设置为0
#获取点的数量,你们可以print(len(points))试以下,会发现有100个点
N=float(len(points))
#range(0,len(points))start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);stop: 计数到 stop 结束,但不包括 stop。
#range()函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
#list()函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。
#这是一个循环i的值会从0变化到100-1,也就是len(points)-1
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
b_gradient=b_gradient + 2*( ((w_current*x)+b_current) -y)
w_gradient=w_gradient + 2*x*( ((w_current*x)+b_current) -y)
b_gradient=b_gradient/N
w_gradient=w_gradient/N
#下面是w和b的拟合的过程
new_b=b_current-(learningRate*b_gradient)
new_w=w_current-(learningRate*w_gradient)
#返回一个list,相当于一个可以扩充的数组,里面有new_b,new_w这两个数据项
return [new_b,new_w]
参数初始化
def gradient_descent_runner(points,starting_b,starting_w,learning_rate,num_iterations):
b=starting_b
w=starting_w
for i in range(num_iterations):
b,w=step_gradient(b,w,np.array(points),learning_rate)
# 将b,w存在列表中并返回
return [b,w]
调参
def run():
#使用numpy中的函数导入x,y值
points=np.genfromtxt("data.csv",delimiter=",")
# 可修改
#0.0003 负
learning_rate=0.000003
# 可修改
initial_b = 7.99102098,
# 可修改
initial_w = 1.32243102
# 可修改
num_iterations=100
#下面是打印结果的操作,这是运行前线行函数的w,b,error值
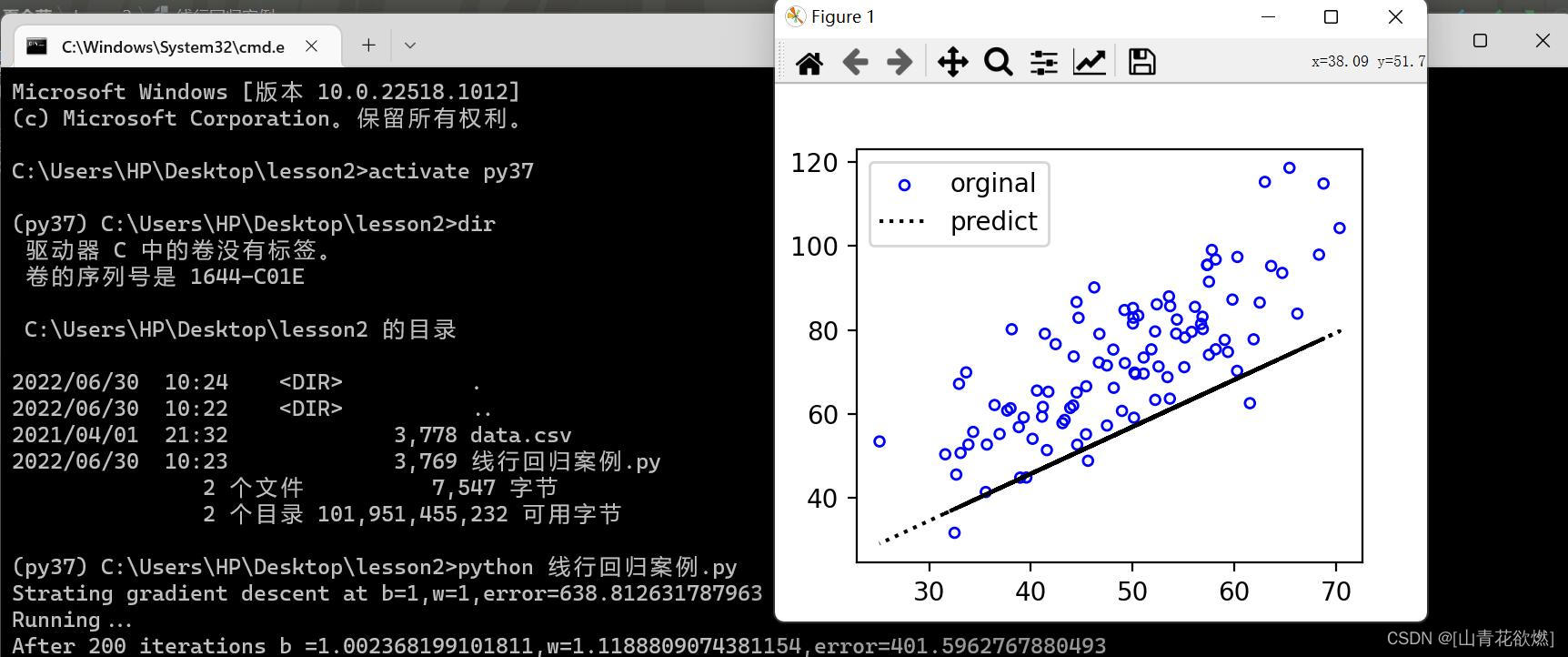
print("Strating gradient descent at b={0},w={1},error={2}".format(initial_b,initial_w,compute_error_for_line_given_points(initial_b,initial_w,points)))
print("Running...")
[b,w]=gradient_descent_runner(points,initial_b,initial_w,learning_rate,num_iterations)
#面是打印结果的操作,这是运行后线行函数的w,b,error值
print("After {0} iterations b ={1},w={2},error={3}".format(num_iterations,b,w,compute_error_for_line_given_points(b,w,points)))
#绘制图像,不用改
x = points[:, 0]
y = w * x + b
plt.scatter(points[:, 0], points[:, 1], c='none', edgecolors=['y','b','r','g'], s=15, label='orginal')
plt.plot(x, y, c='blue', label='predict', linestyle=':')
plt.legend()
plt.show()
#当线行回归案列.py这个文件被用来做主函数时run()会调用,如果在其他py文件中导入线行回归案例模块时run()函数不会被调用
if __name__ =='__main__':
run()
完整代码
#首先需要在Terminal中的指定conda虚拟环境中使用
# pip install numpy
# pip install matplotlib
import numpy as np
import matplotlib.pyplot as plt
#实验内容一元线性回归求近似解
#loss损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。
def compute_error_for_line_given_points(b,w,points):
totalError=0
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
totalError+=((w*x+b)-y)**2
return totalError/float(len(points))
#通过输入大量的点去迭代
def step_gradient(b_current,w_current,points,learningRate):
b_gradient=7#此处不一定需要设置为0
w_gradient=1#此处不一定需要设置为0
#获取点的数量,你们可以print(len(points))试以下,会发现有100个点
N=float(len(points))
#range(0,len(points))start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);stop: 计数到 stop 结束,但不包括 stop。
#range()函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
#list()函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。
#这是一个循环i的值会从0变化到100-1,也就是len(points)-1
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
b_gradient=b_gradient + 2*( ((w_current*x)+b_current) -y)
w_gradient=w_gradient + 2*x*( ((w_current*x)+b_current) -y)
b_gradient=b_gradient/N
w_gradient=w_gradient/N
#下面是w和b的拟合的过程
new_b=b_current-(learningRate*b_gradient)
new_w=w_current-(learningRate*w_gradient)
#返回一个list,相当于一个可以扩充的数组,里面有new_b,new_w这两个数据项
return [new_b,new_w]
def gradient_descent_runner(points,starting_b,starting_w,learning_rate,num_iterations):
b=starting_b
w=starting_w
for i in range(num_iterations):
b,w=step_gradient(b,w,np.array(points),learning_rate)
# 将b,w存在列表中并返回
return [b,w]
def run():
#使用numpy中的函数导入x,y值
points=np.genfromtxt("data.csv",delimiter=",")
# 可修改
#0.0003 负
learning_rate=0.000003
# 可修改
initial_b = 7.99102098,
# 可修改
initial_w = 1.32243102
# 可修改
num_iterations=100
# After 5000 iterations b =[1.75641085],w=[1.44497039],error=[111.72486774]
# After 10000 iterations b =[2.42378544],w=[1.43185334],error=[111.42751328]
# After 10000 iterations b =[3.55186295],w=[1.40968132],error=[111.00135457]
# After 10000 iterations b =[4.45136384],w=[1.39200191],error=[110.73040101]
# After 100000 iterations b =[7.62325877],w=[1.32965928],error=[110.26248956]
# After 1000000 iterations b =[7.99102098],w=[1.32243102],error=[110.25738347]
#下面是打印结果的操作,这是运行前线行函数的w,b,error值
print("Strating gradient descent at b={0},w={1},error={2}".format(initial_b,initial_w,compute_error_for_line_given_points(initial_b,initial_w,points)))
print("Running...")
[b,w]=gradient_descent_runner(points,initial_b,initial_w,learning_rate,num_iterations)
#面是打印结果的操作,这是运行后线行函数的w,b,error值
print("After {0} iterations b ={1},w={2},error={3}".format(num_iterations,b,w,compute_error_for_line_given_points(b,w,points)))
#绘制图像,不用改
x = points[:, 0]
y = w * x + b
plt.scatter(points[:, 0], points[:, 1], c='none', edgecolors=['y','b','r','g'], s=15, label='orginal')
plt.plot(x, y, c='blue', label='predict', linestyle=':')
plt.legend()
plt.show()
#当线行回归案列.py这个文件被用来做主函数时run()会调用,如果在其他py文件中导入线行回归案例模块时run()函数不会被调用
if __name__ =='__main__':
run()
##作业优化相关参数使得error值小于给定的error=401.5962767880493值,越小越好
#最终请上传你最小error的截图
我的最佳结果:
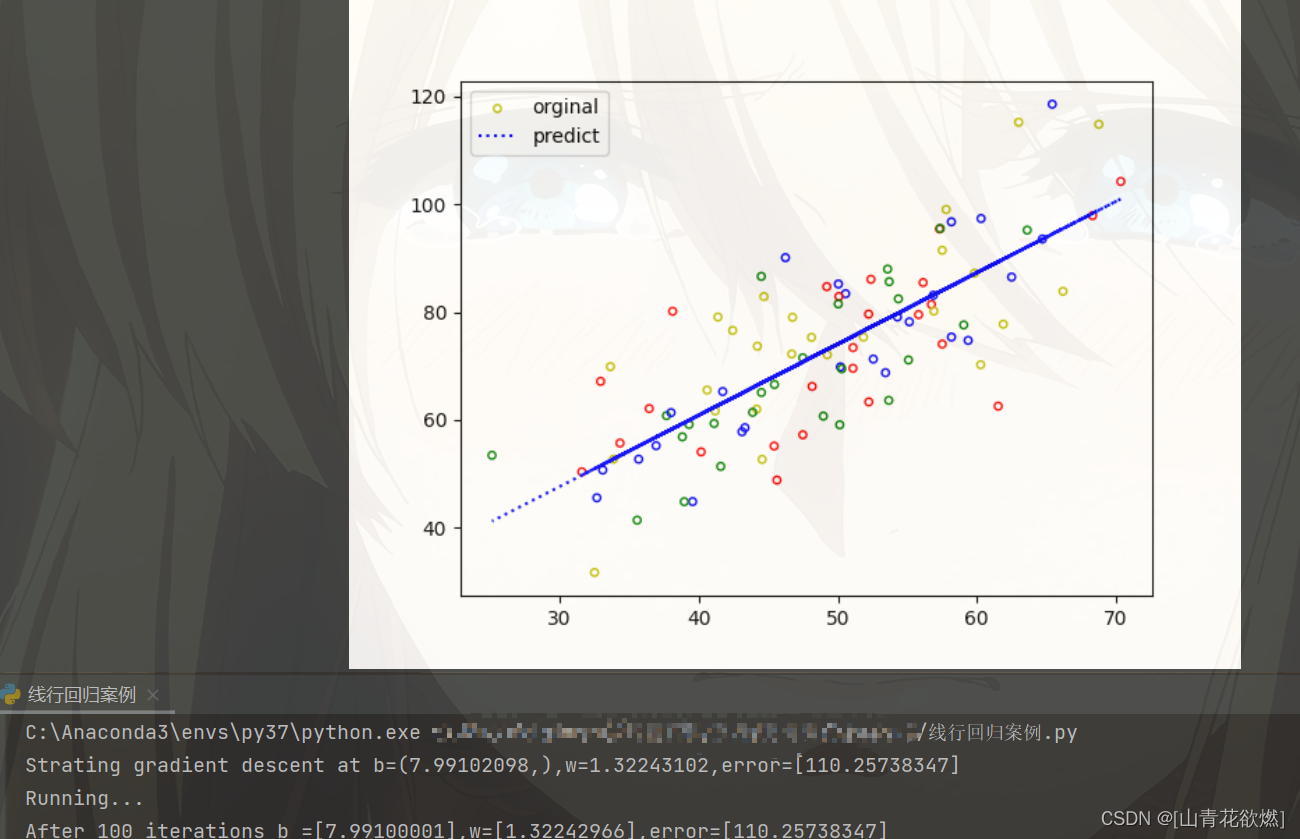
最后祝大家学习愉快,调参涨分啦,一起学习鸭!
















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











