







 本文对深度学习网络中的注意力机制进行实证研究,涉及自然语言处理和计算机视觉任务。提出广义注意力公式,分析Transformer注意力、可变形卷积和动态卷积等机制。实验发现不同机制在不同任务中的性能差异,挑战了传统理解,表明注意力机制设计有改进空间。
本文对深度学习网络中的注意力机制进行实证研究,涉及自然语言处理和计算机视觉任务。提出广义注意力公式,分析Transformer注意力、可变形卷积和动态卷积等机制。实验发现不同机制在不同任务中的性能差异,挑战了传统理解,表明注意力机制设计有改进空间。
Generalized Attention
An Empirical Study of Spatial Attention Mechanisms in Deep Networks
论文网址:Generalized Attention
论文代码:文章最后有GeneralizedAttention的实现代码
简读论文
本文主要研究了深度学习网络中的注意力机制。作者们从不同的角度对注意力机制进行了全面的分析和实证研究,包括自然语言处理(NLP)和计算机视觉(CV)任务。
首先,论文介绍了注意力机制的背景和发展。注意力机制最初在自然语言处理领域中用于编码器-解码器的注意力模块,以促进神经机器翻译。后来,自注意力模块被提出,用于建模句子内部的关系。随着Transformer注意力模块的出现,注意力建模在NLP领域取得了显著的成功,并逐渐被应用于计算机视觉领域,如目标检测和语义分割等任务。
接下来,论文提出了一个广义的注意力公式,可以表示不同的注意力模块,包括Transformer注意力、可变形卷积和动态卷积。作者们通过消融实验(ablation study)研究了不同注意力因素和机制对性能的影响。
实验结果发现:
- 在自注意力场景中,查询敏感项(尤其是查询和键内容项)的影响较小,而查询内容与相对位置以及键内容项对性能的影响较大。
- 在编码器-解码器注意力中,查询和键内容项至关重要。
- 可变形卷积在图像识别任务中比Transformer注意力更有效,而在自然语言处理任务中与Transformer注意力相当。
- 适当结合可变形卷积和键内容项的Transformer注意力可以实现比原始Transformer注意力更高的准确性和更低的计算开销。
这些发现挑战了关于当前空间注意力机制的传统理解,并表明在设计注意力机制方面仍有很大的改进空间。作者希望通过这篇论文激发更多关于建模空间注意力的研究。
摘要
注意力机制已成为深度神经网络中的一个流行组件,但很少有人研究不同的影响因素和计算这些因素的注意力的方法如何影响性能。为了更好地理解注意力机制,本文提出了一项实证研究,消除了广义注意力公式中的各种空间注意力元素,包括占主导地位的 Transformer 注意力以及普遍的可变形卷积和动态卷积模块。这项研究在各种应用上进行,得出了关于深度网络空间注意力的重要发现,其中一些与传统理解背道而驰。例如,本文发现 Transformer 注意力中查询和关键内容的比较对于自注意力来说可以忽略不计,但对于编码器-解码器注意力至关重要。另一方面,可变形卷积与关键内容显着性的适当组合实现了自注意力的最佳准确性-效率权衡。本文的结果表明,注意力机制的设计还有很大的改进空间。
引言
注意力机制使神经网络能够更多地关注输入的相关元素,而不是不相关的部分。它们首先在自然语言处理 (NLP) 领域进行研究,其中开发了编码器-解码器注意模块以促进神经机器翻译。在计算给定查询元素(例如,输出句子中的目标单词)的输出时,根据查询对某些关键元素(例如,输入句子中的源单词)进行优先级排序。后来,提出了用于建模句子内关系的自注意力模块,其中键和查询都来自同一组元素。在一篇里程碑式的论文 [Attentions is all you need] 中,提出了 Transformer 注意力模块,取代了过去的作品并大大超越了它们的性能。 NLP 中注意力建模的成功导致其在计算机视觉中得到采用,其中 Transformer 注意力的不同变体应用于识别任务,例如目标检测和语义分割 ,其中查询和键是视觉元素,例如图像像素或感兴趣的区域。
在确定分配给给定查询的某个键的注意力权重时,通常会考虑输入的几个属性。一是查询的内容。对于自注意力的情况,查询内容可以是图像中查询像素处的特征,或者句子中单词的特征。另一个是键的内容,其中键可以是查询的局部邻域内的像素,或者句子中的另一个单词。第三个是查询和键的相对位置。
基于这些输入属性,有四种可能的注意因素,根据这些因素确定键相对于查询的注意权重,因为这些因素必须考虑有关键的信息。具体来说,这些因素是(1)查询和键内容,(2)查询内容和相对位置,(3)仅关键内容,以及(4)仅相对位置。在最新版本的 Transformer 注意力中,注意力权重被表示为四项之和(E1、E2、E3、E4),每个注意力因子对应一个项,如图 1 所示。依赖关系的性质这些条款所涉及的内容各不相同。例如前两个(E1,E2)对查询内容敏感。而后两者(E3、E4)不考虑查询内容,而是分别主要捕获显着的关键元素并利用全局位置偏差。尽管注意力权重可以根据这些因素分解为术语,但它们在各种推理问题中的相对重要性尚未在文献中得到仔细研究。此外,诸如可变形卷积 和动态卷积 等流行模块虽然看似与 Transformer 注意力正交,但也采用了专注于输入的某些部分的机制。这些模块是否可以从统一的角度来看待,以及它们的运行机制有何不同,也尚未得到探讨。
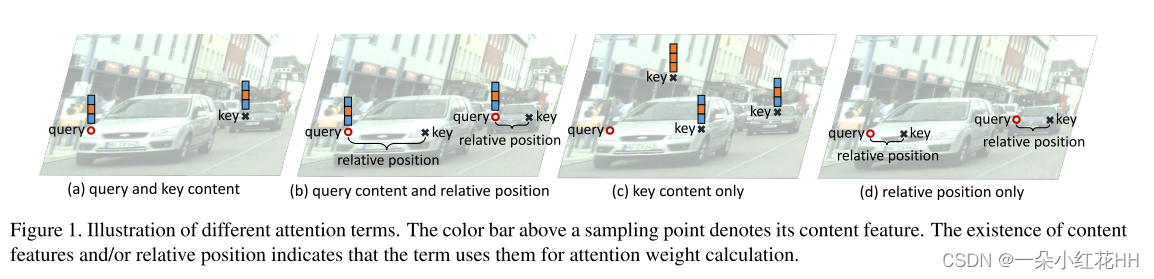
本文将 Transformer 注意力、可变形卷积和动态卷积模块视为空间注意力的各种实例,涉及注意力因素的不同子集并以不同的方式解释这些因素。为了理清不同注意因素和机制的影响,本文提出了空间注意的实证研究,其中注意机制的各种要素在广义注意公式中被消除。这项研究针对各种应用进行,即神经机器翻译、语义分割和目标检测。从这项研究中,本文发现:1)在 Transformer 注意力模块中,查询敏感术语,尤其是查询和关键内容术语,在自注意力中发挥次要作用。但在编码器-解码器注意力中,查询和关键内容术语至关重要。 2)虽然可变形卷积利用仅基于查询内容和相对位置项的注意力机制,但它在图像识别上比 Transformer 注意力中的对应机制更加有效和高效。 3)在self-attention中,查询内容&相对位置和仅关键内容的因素是最重要的。可变形卷积和 Transformer 注意力中的关键内容项的适当组合可提供比 Transformer 注意力模块更高的准确性,并且图像识别任务的计算开销要低得多。
本文的观察结果挑战了对当前空间注意力机制的传统理解。例如,人们普遍认为他们的成功主要归功于查询敏感的注意力,特别是查询和关键内容术语。这种理解或许源于编码器解码器注意力模块在神经机器翻译中的初步成功。因此,在最近的一些变体中,例如非本地块和交叉注意模块,仅保留查询和关键内容术语,以及所有其他术语已删除。这些模块在自注意力应用中仍然运行良好,这强化了这种感知。然而,本文的研究表明这种理解是错误的。本文发现这些仅具有查询敏感术语的注意力模块实际上与仅具有查询不相关术语的注意力模块表现相同。本文的研究进一步表明,这种退化可能是由于注意模块的设计造成的,而不是自注意的固有特征,因为发现可变形卷积可以在图像识别任务中有效且高效地利用查询内容和相对位置。
这一实证分析表明,深层网络中空间注意力机制的设计还有很大的改进空间。本文使用其研究结果在这个方向上取得了一些初步进展,并希望这项研究将促进对空间注意力建模中使用的操作机制的进一步研究。
相关工作
基于注意力的模块的开发和应用。 : 近年来,NLP 领域的注意力机制得到了稳步发展。从神经机器翻译中引入注意力模块开始,各种注意力因素和基于这些因素的权重分配函数被利用。在[Effective approaches to attention-based neural machine translation]中,建议使用编码查询和关键内容的向量的内积来计算注意力权重,并将绝对空间位置作为注意力因子。在[Convolutional sequence to sequence learning]中,权重分配还考虑了高维向量中编码的空间位置的内积。 Transformer 的里程碑式工作设定了新标准,其最新变体使用相对位置而不是绝对位置以获得更好的泛化能力 。本文对这一系列作品中 Transformer 注意力的最新实例进行了实证研究。
受 NLP 任务成功的推动,注意力机制也被应用于计算机视觉应用中,例如对象之间的关系推理 、图像字幕 、图像生成 、图像识别 和视频识别。在视觉中,键和查询指的是视觉元素,但除此之外,大多数这些作品都使用类似于 Transformer 注意力的公式。由于不同注意力模块元素的效果可能会随着目标应用的不同而变化,因此我们对受注意力模型影响较大的三个不同任务进行了实证研究,即自然语言处理中的神经机器翻译,以及计算机视觉中的对象检测和语义分割。
除了 Transformer 注意力之外,还有卷积的变体,例如可变形卷积和动态卷积,它们也可以被视为注意力机制的类型,它们使用不同的注意力权重对注意力因子的子集进行操作功能。它们也被纳入研究以供检查。
值得一提的是空间注意力的双重形式,称为通道特征注意力。由于不同的特征通道编码不同的语义概念,这些工作试图通过激活/停用某些通道来捕获这些概念之间的相关性。同时,在空间域中,对不同空间位置的元素之间的关系进行建模,对分配给相关空间位置的特征通道赋予相同的注意力权重。通道特征注意力的发展主要集中在某些图像识别任务上,例如语义分割和图像分类。在本文中,实证研究专门研究了为广泛应用而设计的空间注意机制。
Analysis of spatial attention mechanisms. : 尽管空间注意力机制在深层网络中普遍存在,但对空间注意力机制的分析相对较少。这项研究主要是通过可视化或分析仅在 NLP 任务上学习到的整个注意力模块的注意力权重来进行的。许多工作表明编码器-解码器注意力中的注意力权重分配起着类似于传统方法中的单词对齐的作用。这些工作中隐含的基本假设是赋予高注意力权重的输入元素负责模型输出。然而,最近的研究对这一假设提出了质疑,发现注意力权重与特征重要性度量没有很好的相关性,并且反事实的注意力权重配置不会在预测中产生相应的变化。
本文对 NLP 和计算机视觉任务中的空间注意模块的要素进行了首次全面的实证研究。不同的注意力因素和权重分配函数被仔细地分解,它们的效果直接通过这些任务的最终表现来衡量。
Study of Spatial Attention Mechanisms
为了促进本文的研究,本文开发了一种能够代表各种模块设计的广义注意力公式。然后,本文展示了如何在该公式中表示主要注意机制,以及如何使用该公式针对不同的注意模块元素进行消融。
Generalized attention formulation (广义注意力公式)
给定一个查询元素和一组关键元素,注意力函数根据衡量查询密钥对兼容性的注意力权重自适应地聚合关键内容。为了让模型能够关注来自不同表示子空间和不同位置的关键内容,多个注意力函数(头)的输出与可学习的权重进行线性聚合。令 q 索引内容为 zq 的查询元素,k 索引内容为 xk 的关键元素。然后多头注意力特征 yq 计算为
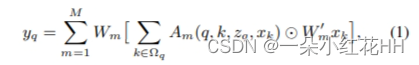
其中m索引注意力头,Ωq指定查询的支持关键区域,Am(q,k,zq,xk)表示第m个注意力头中的注意力权重,Wm和W‘m是可学习的权重。通常,注意力权重在 Ωq 内标准化,如Σk∈Ωq Am(q, k, zq, xk) = 1。
在编码器-解码器注意力中,键和查询来自两个不同的元素集,在大多数应用中,这两个元素集需要正确对齐。例如,在神经机器翻译的编码器-解码器注意力中,键和查询元素分别对应于输入和输出句子中的单词,其中正确的对齐对于正确的翻译是必要的。同时,在自注意力中,键和查询来自同一组元素。例如,键和查询都是输入或输出句子中的单词。在这种情况下,自注意力机制有望捕获元素之间的内部关系,并且通常查询和关键内容由同一组特征建模,即 x = z。
Transformer attention
在 Transformer 注意力模块的最新实例中,每个查询密钥对的注意力权重计算为基于不同注意力因子的四个项 {Ej}4 j=1 的总和,如下所示
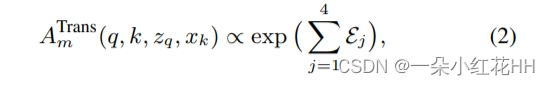
通过 Σk∈Ωq ATrans m (q, k, zq, xk) = 1 标准化,其中支持关键区域 Ωq 跨越关键元素(例如,整个输入句子)。默认情况下,本文使用 8 个注意力头。
E1和E2术语对查询内容敏感。 E1 项衡量查询和关键内容的兼容性,如 E1 = z q U mVC mxk,其中 Um、VC m 分别是查询和关键内容的可学习嵌入矩阵。它使得网络在内容方面更加关注与查询兼容的键。可能的结果是相似查询和关键元素之间的对应关系,如图 1 (a) 所示。对于 E2 项,它基于查询内容和相对位置,如 E2 = z q U mVR mRk−q,其中 Rk−q 通过将相对位置 k−q 投影到高维表示来对其进行编码计算不同波长的正弦和余弦函数1 [41]。 VR m 是编码相对位置 Rk−q 的可学习嵌入矩阵。该术语允许网络根据查询内容自适应地确定在哪里分配高注意力权重。它可能有助于将外观与图像识别中的空间变换分开,如图 1 (b) 所示。
E3和E4术语与查询内容无关。 E3项仅涉及关键内容,因为E3 = u mVC mxk,其中um是可学习向量。它捕获任务应该关注的显着关键内容,并且与查询无关。示例如图1©所示。至于E4项,它仅涉及相对位置,因为E4 = v mVR mRk−q,其中vm是可学习向量。它捕获键和查询元素之间的全局位置偏差,如图 1 (d) 所示。
人们普遍认为,查询敏感的优先级,特别是查询和关键内容兼容性项E1,是Transformer注意力成功的关键。因此,在最近的一些变体中,仅保留E1,而其他项全部被删除。
在 Transformer 注意力中,方程中的 Wm 和 W’m 都为: (1)是可学习的。 ‘m 将 xk 的特征投影到相对较低的维度以减少计算开销,Wm 将聚合的特征投影回与 yq 相同的维度。
Regular and deformable convolution
规则卷积和可变形卷积可以被视为空间注意力机制的特殊实例,其中涉及注意力因子的子集。
在常规卷积中,给定查询元素,根据相对于查询的预定位置偏移,对固定数量的关键元素(例如,3×3)进行采样。从等式的角度来看。 (1)、正则卷积的注意力权重可以表示为:
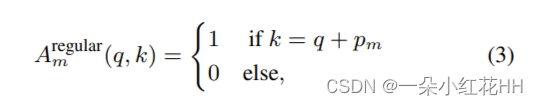
其中每个采样的关键元素都是一个单独的注意力头(例如,3×3正则卷积对应9个注意力头),pm表示第m个采样位置的偏移量。此外,方程中的权重W’m (1) 被固定为恒等式,使 Wm 成为可学习的。在常规卷积中,仅涉及相对位置,没有用于适应内容注意力的可学习参数。支持关键区域 Ωq 仅限于以查询位置为中心的局部窗口,并由卷积核大小确定。
在可变形卷积中,添加可学习的偏移量来调整关键元素的采样位置,从而捕获空间变换。可学习的偏移量是根据查询内容预测的,因此对于输入来说是动态的。键和查询元素来自同一集合。它也可以作为自注意力的特殊实例纳入广义注意力公式中,其中注意力权重为:
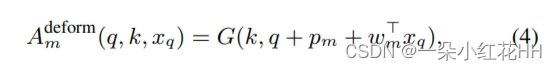
其中pm也表示预定偏移量,w mxq根据可学习向量wm 2将查询内容xq投影到变形偏移量。G(a, b)是N维空间中的双线性插值核,可以分解为1 -d 双线性插值为 G(a, b) = N n=1 g(an, bn),其中 an 和 bn 分别表示 a 和 b 的第 n 维,g(an, bn) = max( 0, 1 − |an − bn|)。与常规卷积类似,式中的权重Wm (1) 固定为恒等式。
在可变形卷积中,注意力因素是查询内容和相对位置。由于引入了可学习偏移,支持关键区域 Ωq 可以跨越所有输入元素,同时将非零权重分配给执行双线性插值的稀疏关键元素集。
Dynamic convolution
最近提出动态卷积来取代自注意力中的Transformer注意力模块,并声称更简单、更高效。它建立在具有共享动态内核权重的深度可分离卷积之上,该权重是根据查询内容进行预测的。在深度可分离卷积中,标准卷积被分解为深度卷积和称为点卷积的 1×1 卷积,以减少计算量和模型大小。在深度卷积中,单个滤波器应用于每个输入通道,该滤波器的所有位置都是固定的。在动态卷积中,深度卷积的内核权重是根据输入特征动态预测的,然后进行 Softmax 归一化。为了节省计算量,输入通道被分为几个组,每个组共享相同的动态内核权重。在系统中,在动态卷积模块之前应用称为门控线性单元(GLU)的正交模块来提高精度。本文纳入 GLU 是为了尊重原始设计。
动态卷积也可以合并到等式中的一般注意力公式中。 (1) 稍加修改,其中每个输入特征通道都有一个单独的注意力头。可以表示为:
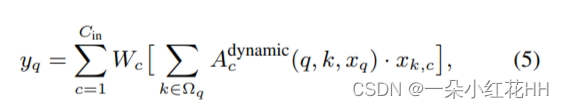
其中c枚举输入特征的通道(总共Cin个通道),xk,c表示xk的第c个通道的特征值,Wc是1×1逐点卷积的特征值。 adynamic c(q,k,xq)是深度卷积中动态核指定的注意力权重,写为:
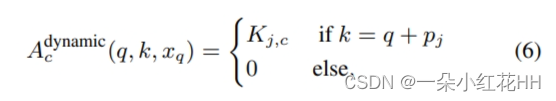
其中pj表示动态内核中的第j个采样位置,Kj,c是相应的内核权重。零注意力权重被分配给内核外部的键。内核权重 Kj,c 根据输入特征进行预测,并在同一组中的通道之间共享,如下所示:
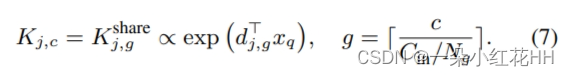
输入特征分为 Ng 组(默认 Ng = 16)。 Kshare j,g 表示第 g 组的动态核权重,dj,g 是相应的可学习权重向量。 Kshare j,g 通过 Nk j=1 Kshare j,g = 1 进行归一化,其中 Nk 表示动态内核中的元素数量。
在动态卷积中,注意力分配基于查询内容和相对位置因子。支持关键区域 Ωq 被限制在动态内核覆盖的查询位置周围的局部窗口。
Comparing attention mechanisms
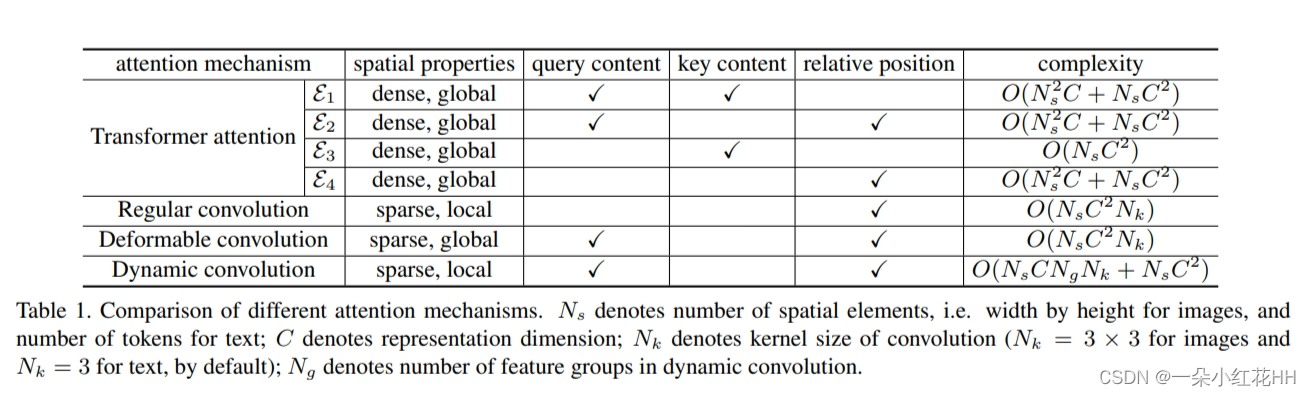
图 1 比较了上面讨论的三种注意力机制。 Transformer 注意力利用查询和密钥中的全面内容和位置信息。 E1、E2 和 E4 项需要与查询和关键元素编号的乘积成比例的计算,因为它们涉及每个查询-关键对的遍历。 E3 项仅捕获关键内容,因此涉及与关键元素编号成线性关系的计算。在神经机器翻译中,关键元素和查询元素通常是句子中的几十个单词,因此E1、E2和E4的计算开销与E3相当。在图像识别中,关键元素和查询元素由图像中的大量像素组成。因此E1、E2和E4的计算开销比E3重得多。请注意,当这四个术语放在一起时,一些计算开销可以在它们之间共享。
与E2项类似,可变形卷积也是基于查询内容和相对位置。但可变形卷积只为每个查询采样一组稀疏的关键元素,并且复杂度与查询元素数量呈线性关系。因此,可变形卷积的计算速度比图像识别的 E2 快得多,并且在速度上与机器翻译的 E2 相当。
动态卷积还依赖于查询内容和相对位置。关键元素的注意力权重由动态卷积核根据查询内容分配。非零注意力权重仅存在于动态内核覆盖的局部范围内。计算开销与内核大小和查询元素数量的乘积成正比。与 E2 项相比,如果内核大小远小于关键元素数量,则计算开销会显着降低。
本文试图进一步理清不同注意力因素的影响,并便于与使用因素子集的其他空间注意力实例进行比较。因此,Transformer注意模块中引入了手动开关,这使本文能够手动激活/停用特定术语。这表示为:
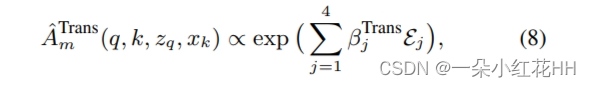
其中 {βTrans j } 取 {0, 1} 中的值来控制相应项的激活,并且 Aˆ Trans m (q, k, zq, xk) 通过 k∈Ωq Aˆ Trans m (q, k, zq, xk) = 1。
Incorporating attention modules into deep networks
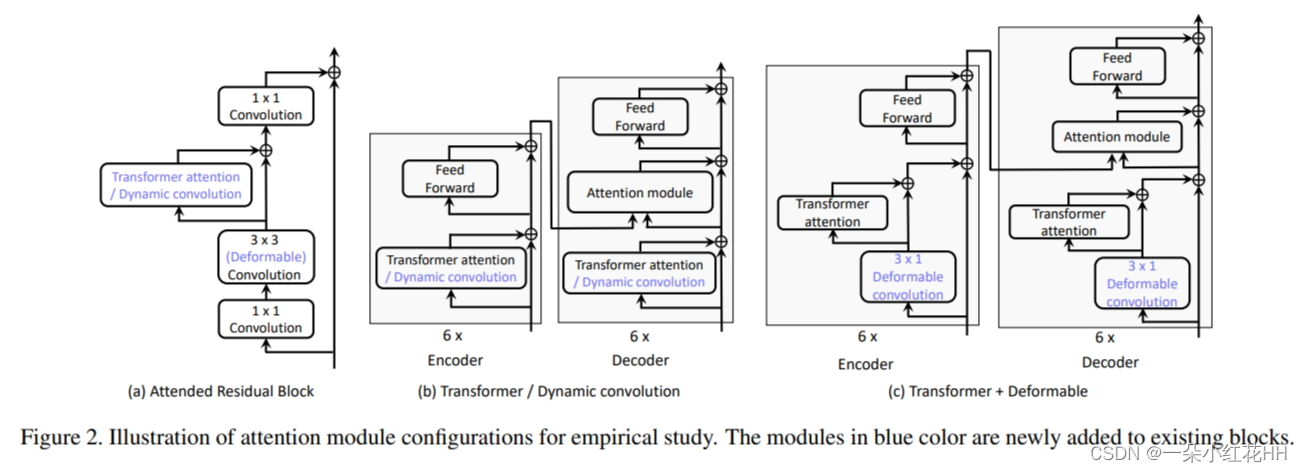
本文将各种注意力机制纳入深度网络中以研究其效果。插入模块有不同的设计选择,例如串联还是并联,以及将模块放置在骨干网络中的何处。凭经验观察到,对于不同的经过深思熟虑的设计,结果非常相似。本文选择图2中的设计选择。
对于目标检测和语义分割任务,选择 ResNet-50作为主干,仅涉及自注意力机制。 Transformer 注意力模块通过将其应用于残差块中的 3×3 卷积输出来合并。为了在不破坏初始行为的情况下插入到预训练模型中,Transformer 注意力模块包含一个残差连接,其输出乘以一个初始化为零的可学习标量。合并动态卷积的方式是相同的。为了利用可变形卷积,残差块中的 3 × 3 常规卷积被其可变形对应部分取代。由此产生的架构称为“有人参与的残差块”,如图 2 (a) 所示。
在神经元机器翻译(NMT)任务中,网络架构遵循 Transformer 基础模型,其中同时涉及自注意力机制和编码器-解码器注意力机制。与原始论文不同,本文用最新的相对位置版本更新了 Transformer 注意模块中的绝对位置嵌入。 2. 由于可变形卷积和动态卷积都捕获 self-attention,因此它们仅添加到 Transformer 中捕获 self-attention 的块中。对于动态卷积,我们直接用动态卷积替换 Transformer 注意力模块,如[44]中所示。其架构如图2(b)所示。对于其可变形卷积对应部分,由于 Transformer 模型不使用任何空间卷积(内核大小大于 1),因此本文在 Transformer 注意模块的输入之前插入可变形卷积单元(内核大小为 3)。由此产生的架构称为“Transformer + Deformable”,如图 2 © 所示。
代码
class GeneralizedAttention(nn.Module):
"""GeneralizedAttention module.
See 'An Empirical Study of Spatial Attention Mechanisms in Deep Networks'
(https://arxiv.org/abs/1711.07971) for details.
Args:
in_dim (int): Channels of the input feature map.
spatial_range (int): The spatial range.
-1 indicates no spatial range constraint.
num_heads (int): The head number of empirical_attention module.
position_embedding_dim (int): The position embedding dimension.
position_magnitude (int): A multiplier acting on coord difference.
kv_stride (int): The feature stride acting on key/value feature map.
q_stride (int): The feature stride acting on query feature map.
attention_type (str): A binary indicator string for indicating which
items in generalized empirical_attention module are used.
'1000' indicates 'query and key content' (appr - appr) item,
'0100' indicates 'query content and relative position'
(appr - position) item,
'0010' indicates 'key content only' (bias - appr) item,
'0001' indicates 'relative position only' (bias - position) item.
"""
def __init__(self,
in_dim,
spatial_range=-1,
num_heads=9,
position_embedding_dim=-1,
position_magnitude=1,
kv_stride=2,
q_stride=1,
attention_type='1111'):
super(GeneralizedAttention, self).__init__()
# hard range means local range for non-local operation
self.position_embedding_dim = (
position_embedding_dim if position_embedding_dim > 0 else in_dim)
self.position_magnitude = position_magnitude
self.num_heads = num_heads
self.channel_in = in_dim
self.spatial_range = spatial_range
self.kv_stride = kv_stride
self.q_stride = q_stride
self.attention_type = [bool(int(_)) for _ in attention_type]
self.qk_embed_dim = in_dim // num_heads
out_c = self.qk_embed_dim * num_heads
if self.attention_type[0] or self.attention_type[1]:
self.query_conv = nn.Conv2d(
in_channels=in_dim,
out_channels=out_c,
kernel_size=1,
bias=False)
self.query_conv.kaiming_init = True
if self.attention_type[0] or self.attention_type[2]:
self.key_conv = nn.Conv2d(
in_channels=in_dim,
out_channels=out_c,
kernel_size=1,
bias=False)
self.key_conv.kaiming_init = True
self.v_dim = in_dim // num_heads
self.value_conv = nn.Conv2d(
in_channels=in_dim,
out_channels=self.v_dim * num_heads,
kernel_size=1,
bias=False)
self.value_conv.kaiming_init = True
if self.attention_type[1] or self.attention_type[3]:
self.appr_geom_fc_x = nn.Linear(
self.position_embedding_dim // 2, out_c, bias=False)
self.appr_geom_fc_x.kaiming_init = True
self.appr_geom_fc_y = nn.Linear(
self.position_embedding_dim // 2, out_c, bias=False)
self.appr_geom_fc_y.kaiming_init = True
if self.attention_type[2]:
stdv = 1.0 / math.sqrt(self.qk_embed_dim * 2)
appr_bias_value = -2 * stdv * torch.rand(out_c) + stdv
self.appr_bias = nn.Parameter(appr_bias_value)
if self.attention_type[3]:
stdv = 1.0 / math.sqrt(self.qk_embed_dim * 2)
geom_bias_value = -2 * stdv * torch.rand(out_c) + stdv
self.geom_bias = nn.Parameter(geom_bias_value)
self.proj_conv = nn.Conv2d(
in_channels=self.v_dim * num_heads,
out_channels=in_dim,
kernel_size=1,
bias=True)
self.proj_conv.kaiming_init = True
self.gamma = nn.Parameter(torch.zeros(1))
if self.spatial_range >= 0:
# only works when non local is after 3*3 conv
if in_dim == 256:
max_len = 84
elif in_dim == 512:
max_len = 42
max_len_kv = int((max_len - 1.0) / self.kv_stride + 1)
local_constraint_map = np.ones(
(max_len, max_len, max_len_kv, max_len_kv), dtype=np.int)
for iy in range(max_len):
for ix in range(max_len):
local_constraint_map[iy, ix,
max((iy - self.spatial_range) //
self.kv_stride, 0):min(
(iy + self.spatial_range +
1) // self.kv_stride +
1, max_len),
max((ix - self.spatial_range) //
self.kv_stride, 0):min(
(ix + self.spatial_range +
1) // self.kv_stride +
1, max_len)] = 0
self.local_constraint_map = nn.Parameter(
torch.from_numpy(local_constraint_map).byte(),
requires_grad=False)
if self.q_stride > 1:
self.q_downsample = nn.AvgPool2d(
kernel_size=1, stride=self.q_stride)
else:
self.q_downsample = None
if self.kv_stride > 1:
self.kv_downsample = nn.AvgPool2d(
kernel_size=1, stride=self.kv_stride)
else:
self.kv_downsample = None
self.init_weights()
def get_position_embedding(self,
h,
w,
h_kv,
w_kv,
q_stride,
kv_stride,
device,
feat_dim,
wave_length=1000):
h_idxs = torch.linspace(0, h - 1, h).cuda(device)
h_idxs = h_idxs.view((h, 1)) * q_stride
w_idxs = torch.linspace(0, w - 1, w).cuda(device)
w_idxs = w_idxs.view((w, 1)) * q_stride
h_kv_idxs = torch.linspace(0, h_kv - 1, h_kv).cuda(device)
h_kv_idxs = h_kv_idxs.view((h_kv, 1)) * kv_stride
w_kv_idxs = torch.linspace(0, w_kv - 1, w_kv).cuda(device)
w_kv_idxs = w_kv_idxs.view((w_kv, 1)) * kv_stride
# (h, h_kv, 1)
h_diff = h_idxs.unsqueeze(1) - h_kv_idxs.unsqueeze(0)
h_diff *= self.position_magnitude
# (w, w_kv, 1)
w_diff = w_idxs.unsqueeze(1) - w_kv_idxs.unsqueeze(0)
w_diff *= self.position_magnitude
feat_range = torch.arange(0, feat_dim / 4).cuda(device)
dim_mat = torch.Tensor([wave_length]).cuda(device)
dim_mat = dim_mat**((4. / feat_dim) * feat_range)
dim_mat = dim_mat.view((1, 1, -1))
embedding_x = torch.cat(
((w_diff / dim_mat).sin(), (w_diff / dim_mat).cos()), dim=2)
embedding_y = torch.cat(
((h_diff / dim_mat).sin(), (h_diff / dim_mat).cos()), dim=2)
return embedding_x, embedding_y
def forward(self, x_input):
num_heads = self.num_heads
# use empirical_attention
if self.q_downsample is not None:
x_q = self.q_downsample(x_input)
else:
x_q = x_input
n, _, h, w = x_q.shape
if self.kv_downsample is not None:
x_kv = self.kv_downsample(x_input)
else:
x_kv = x_input
_, _, h_kv, w_kv = x_kv.shape
if self.attention_type[0] or self.attention_type[1]:
proj_query = self.query_conv(x_q).view(
(n, num_heads, self.qk_embed_dim, h * w))
proj_query = proj_query.permute(0, 1, 3, 2)
if self.attention_type[0] or self.attention_type[2]:
proj_key = self.key_conv(x_kv).view(
(n, num_heads, self.qk_embed_dim, h_kv * w_kv))
if self.attention_type[1] or self.attention_type[3]:
position_embed_x, position_embed_y = self.get_position_embedding(
h, w, h_kv, w_kv, self.q_stride, self.kv_stride,
x_input.device, self.position_embedding_dim)
# (n, num_heads, w, w_kv, dim)
position_feat_x = self.appr_geom_fc_x(position_embed_x).\
view(1, w, w_kv, num_heads, self.qk_embed_dim).\
permute(0, 3, 1, 2, 4).\
repeat(n, 1, 1, 1, 1)
# (n, num_heads, h, h_kv, dim)
position_feat_y = self.appr_geom_fc_y(position_embed_y).\
view(1, h, h_kv, num_heads, self.qk_embed_dim).\
permute(0, 3, 1, 2, 4).\
repeat(n, 1, 1, 1, 1)
position_feat_x /= math.sqrt(2)
position_feat_y /= math.sqrt(2)
# accelerate for saliency only
if (np.sum(self.attention_type) == 1) and self.attention_type[2]:
appr_bias = self.appr_bias.\
view(1, num_heads, 1, self.qk_embed_dim).\
repeat(n, 1, 1, 1)
energy = torch.matmul(appr_bias, proj_key).\
view(n, num_heads, 1, h_kv * w_kv)
h = 1
w = 1
else:
# (n, num_heads, h*w, h_kv*w_kv), query before key, 540mb for
if not self.attention_type[0]:
energy = torch.zeros(
n,
num_heads,
h,
w,
h_kv,
w_kv,
dtype=x_input.dtype,
device=x_input.device)
# attention_type[0]: appr - appr
# attention_type[1]: appr - position
# attention_type[2]: bias - appr
# attention_type[3]: bias - position
if self.attention_type[0] or self.attention_type[2]:
if self.attention_type[0] and self.attention_type[2]:
appr_bias = self.appr_bias.\
view(1, num_heads, 1, self.qk_embed_dim)
energy = torch.matmul(proj_query + appr_bias, proj_key).\
view(n, num_heads, h, w, h_kv, w_kv)
elif self.attention_type[0]:
energy = torch.matmul(proj_query, proj_key).\
view(n, num_heads, h, w, h_kv, w_kv)
elif self.attention_type[2]:
appr_bias = self.appr_bias.\
view(1, num_heads, 1, self.qk_embed_dim).\
repeat(n, 1, 1, 1)
energy += torch.matmul(appr_bias, proj_key).\
view(n, num_heads, 1, 1, h_kv, w_kv)
if self.attention_type[1] or self.attention_type[3]:
if self.attention_type[1] and self.attention_type[3]:
geom_bias = self.geom_bias.\
view(1, num_heads, 1, self.qk_embed_dim)
proj_query_reshape = (proj_query + geom_bias).\
view(n, num_heads, h, w, self.qk_embed_dim)
energy_x = torch.matmul(
proj_query_reshape.permute(0, 1, 3, 2, 4),
position_feat_x.permute(0, 1, 2, 4, 3))
energy_x = energy_x.\
permute(0, 1, 3, 2, 4).unsqueeze(4)
energy_y = torch.matmul(
proj_query_reshape,
position_feat_y.permute(0, 1, 2, 4, 3))
energy_y = energy_y.unsqueeze(5)
energy += energy_x + energy_y
elif self.attention_type[1]:
proj_query_reshape = proj_query.\
view(n, num_heads, h, w, self.qk_embed_dim)
proj_query_reshape = proj_query_reshape.\
permute(0, 1, 3, 2, 4)
position_feat_x_reshape = position_feat_x.\
permute(0, 1, 2, 4, 3)
position_feat_y_reshape = position_feat_y.\
permute(0, 1, 2, 4, 3)
energy_x = torch.matmul(proj_query_reshape,
position_feat_x_reshape)
energy_x = energy_x.permute(0, 1, 3, 2, 4).unsqueeze(4)
energy_y = torch.matmul(proj_query_reshape,
position_feat_y_reshape)
energy_y = energy_y.unsqueeze(5)
energy += energy_x + energy_y
elif self.attention_type[3]:
geom_bias = self.geom_bias.\
view(1, num_heads, self.qk_embed_dim, 1).\
repeat(n, 1, 1, 1)
position_feat_x_reshape = position_feat_x.\
view(n, num_heads, w*w_kv, self.qk_embed_dim)
position_feat_y_reshape = position_feat_y.\
view(n, num_heads, h * h_kv, self.qk_embed_dim)
energy_x = torch.matmul(position_feat_x_reshape, geom_bias)
energy_x = energy_x.view(n, num_heads, 1, w, 1, w_kv)
energy_y = torch.matmul(position_feat_y_reshape, geom_bias)
energy_y = energy_y.view(n, num_heads, h, 1, h_kv, 1)
energy += energy_x + energy_y
energy = energy.view(n, num_heads, h * w, h_kv * w_kv)
if self.spatial_range >= 0:
cur_local_constraint_map = \
self.local_constraint_map[:h, :w, :h_kv, :w_kv].\
contiguous().\
view(1, 1, h*w, h_kv*w_kv)
energy = energy.masked_fill_(cur_local_constraint_map,
float('-inf'))
attention = F.softmax(energy, 3)
proj_value = self.value_conv(x_kv)
proj_value_reshape = proj_value.\
view((n, num_heads, self.v_dim, h_kv * w_kv)).\
permute(0, 1, 3, 2)
out = torch.matmul(attention, proj_value_reshape).\
permute(0, 1, 3, 2).\
contiguous().\
view(n, self.v_dim * self.num_heads, h, w)
out = self.proj_conv(out)
out = self.gamma * out + x_input
return out
def init_weights(self):
for m in self.modules():
if hasattr(m, 'kaiming_init') and m.kaiming_init:
kaiming_init(
m,
mode='fan_in',
nonlinearity='leaky_relu',
bias=0,
distribution='uniform',
a=1)


















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











