









TR3D
TOWARDS REAL-TIME INDOOR 3D OBJECT DETECTION
迈向实时室内3D目标检测
论文网址:TR3D
论文代码:TR3D
论文简读
这篇论文提出了TR3D,一个用于室内3D对象检测的快速且准确的全卷积网络方法。主要贡献如下:
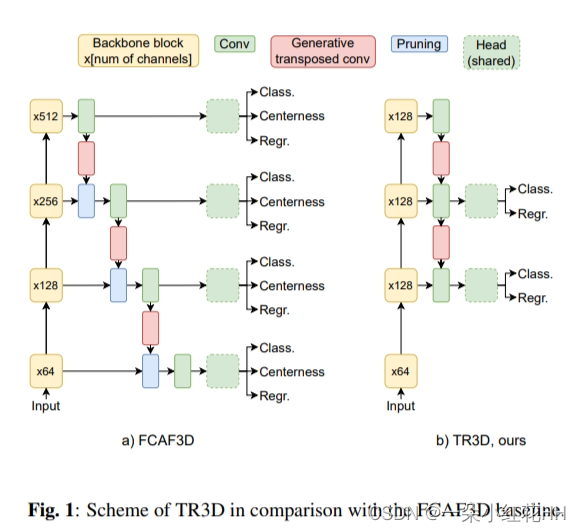
- 提出TR3D网络结构,相比普通的连通域卷积处理稀疏的3D数据更有效率。TR3D是在FCAF3D(ECCV 2022)的基础上改进的,FCAF3D是一个用于3D对象检测的全卷积 Anchor-free 网络(如果不了解,请看这篇文章讲解Fcaf3d),主要改进如下:
- 删除的头两层和尾层来自FCAF3D的多尺度特征。FCAF3D有4个 尺度输出,TR3D只保留中间2个尺度。
- 删除的centerness分支也来自FCAF3D。FCAF3D原网络有centerness预测分支。
- 设计多层分配器,提高小目标的检测效果
- DIoU损失替代了FCAF3D使用的IoU损失。
-
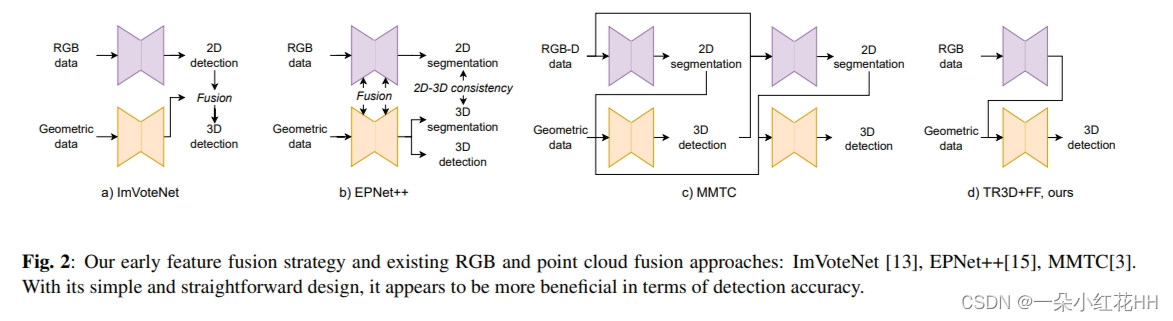
提出早期特征融合策略,将2D图像特征融合到3D点云特征中(1.使用预训练的ResNet50+FPN网络提取RGB图像的2D特征。将2D特征投影到3D空间,与3D点云的体素位置对应。具体投影方法论文中没有说明。3.在Backbone的第一个Block之前,将 above 提取的2D图像特征与3D点云的稀疏卷积特征直接按元素相加进行融合。4.之后融合后的特征继续输入到TR3D网络中进行3D对象检测。所以关键在于,图像2D特征与点云3D特征是在经过网络提取初始特征之后最早的阶段就进行融合的。这种早期融合简单高效,也避免了后期特征对齐等复杂操作。),构建出TR3D+FF多模态网络。相比其他后期特征融合方法,该策略更简单高效。
-
在ScanNet, SUN RGB-D和S3DIS三个室内3D数据集上验证了方法,TR3D在仅点云输入下达到当时最优的检测性能,TR3D+FF在点云+RGB输入下也优于其他多模态方法。
总体来说,论文提出了一个快速高效且精度很高的3D物体检测网络TR3D,并通过早期特征融合扩展到多模态输入,在多个标准基准上都取得了state-of-the-art的结果。论文为实时和多模态3D检测提供了有价值的框架和思路。
摘要
最近,稀疏 3D 卷积改变了 3D 目标检测。 3D CNN 的性能与基于投票的方法相当,内存效率高,并且可以更好地扩展到大型场景。然而,仍有改进的空间。通过有意识的、以实践为导向的解决问题的方法,本文分析这些方法的性能并找出弱点。通过解决所发现的问题,最终得到了 TR3D:一种经过端到端训练的快速全卷积 3D 目标检测模型,在标准基准 ScanNet v2 、SUN RGB-D 和 S3DIS上实现了最先进的结果。此外,为了同时利用点云和 RGB 输入,引入了 2D 和 3D 特征的早期融合。本文采用融合模块使传统的 3D 目标检测方法成为多模态,并展示了令人印象深刻的性能提升。具有早期特征融合的模型(称之为 TR3D+FF)优于 SUN RGB-D 数据集上现有的 3D 对象检测方法。总体而言,TR3D 和 TR3D+FF 模型除了准确之外,还具有轻量级、内存高效且快速的特点,从而标志着实时 3D 目标检测之路上的另一个里程碑。
引言
最近出现的自动驾驶、AR/VR 应用、3D 建模和家用机器人技术引起了人们对 3D 目标检测作为核心场景理解技术的关注。
现代 3D 目标检测方法可分为基于投票的、基于 Transformer 的和 3D 卷积的。基于投票的方法使用特征提取器网络处理点,使用中心投票来创建对象提议,并累积每个组内的点特征。许多基于投票的方法可扩展性较差,限制了它们的使用。
基于Transformer的方法不使用特定领域的启发式方法和超参数,而是使用端到端学习和前向传递推理。更普遍的是,它们在处理更大的场景时仍然存在问题。
3D 卷积方法将点云表示为体素,从而可以有效地处理稀疏 3D 数据。密集体积特征需要大量内存,因此使用稀疏表示和稀疏 3D 卷积来代替。与其他方法相比,3D 稀疏卷积方法内存效率高,并且可以在不牺牲点密度的情况下很好地扩展到大型场景。直到最近,此类方法还缺乏准确性,但由于该领域的最新进展,快速、可扩展且准确的方法被开发出来[Fcaf3d-2022]。
总体而言,现代 3D 检测方法仅使用几何输入就能获得令人印象深刻的结果;然而,利用其他模式的数据进行 3D 物体检测的可能性也得到了研究。点云很难获取,需要额外的设备,而 RGB 摄像机则更容易获取。它们通常集成在捕捉设备中,可提供廉价、易用但信息量极大的数据。现有的方法都是在后期阶段添加 RGB 数据;它们要么具有复杂、耗费内存的架构 [Imvoxelnet-2021],要么依赖于限制其使用的自定义程序 [Multi-modality task cascade for 3d object detection-2021],要么运行缓慢的迭代方案 [Multimodal token fusion for vision transformers-2022]。与此相反,本文提出了一种早期融合策略,这种策略也可以集成到其他基于点云的模型中。该策略与所提出的简单而高效的全卷积管道相结合,可从点云和 RGB 数据中获得最先进的三维物体检测结果。
related work
3D object detection in point clouds. : 基于投票的方法开创了该领域的先河,VoteNet 是第一个为 3D 目标检测引入点投票的方法。 VoteNet 从 3D 点中提取特征,根据投票中心为每个候选对象分配一组点,并计算每个点组的对象特征。 BRNet 利用投票中心的代表点来细化投票结果,从而改善了对精细局部结构特征的捕获。 H3DNet 通过预测几何基元的混合集改进了点组生成过程。 RBGNet 提出了一种基于射线的特征分组模块,该模块通过从簇中心均匀发射射线来聚合物体表面上的逐点特征。
Transformer-based methods. : 在基于Transformer的方法中,分组不是由一组超参数明确引导的,这使得它们的领域特定性较差。 GroupFree [2021] 使用transformer模块来迭代更新对象查询位置并累积中间结果。 3DETR [2021] 是第一个使用 Transformer 模型解决 3D 目标检测任务的模型。
Voxel-based methods. : 基于体素的 3D 对象检测方法将点转换为体素并使用 3D 卷积网络对其进行处理。然而,密集的体积特征仍然消耗大量内存。 GSDN [2020] 使用稀疏 3D 卷积缓解了这个问题,但明显不如现代基于投票的方法准确。与 GSDN 不同,Fcaf3d [2022] 不使用锚点,并以数据驱动的方式解决 3D 对象检测问题,使其成为第一个基于体素的方法,其性能与最先进的基于投票的方法相当方法。在本文的工作中,使用 Fcaf3d 作为强大的基线。
Point cloud and RGB fusion. : 图像中包含的语义数据可能为 3D 目标检测提供额外的线索。最近的工作 [Imvotenet-2020, Epnet-2020, Epnet+±2021] 生成初始区域建议,然后使用 RGB 特征作为指导对其进行细化。 ImVoteNet 利用 2D 检测结果进行投票。 EPNet++ 将图像特征与特征提取模型的中间输出融合。 MMTC [2021] 使用级联,包括 3D 目标检测网络第一级和第二级之间的 2D 分割网络。 TokenFusion [2022] 将点云和 RGB 信息与Transformer模型融合,并学习用投影和聚合的模态间特征替换无信息的标记。
PROPOSED METHOD
TR3D 基于 Fcaf3d,继承了其简单的全卷积设计(图 1),但进行了一些更新,提高了其功效和准确性。此外,本文提出了一种基于 RGB 和点云早期特征融合的 3D 目标检测网络,并将融合模块合并到 TR3D 中以构建多模态 TR3D+FF 模型。
TR3D: 3D Object Detection Method
考虑 Fcaf3d作为基线,引入了一些修改。 TR3D 是所有这些修改共同应用的结果(图 1 b)。为了确保这些修改以期望的方式对最终性能做出贡献,逐渐地、一次一个地应用它们,并估计 S3DIS 上的检测精度、内存占用和推理速度。
Efficacy : 首先,本文的目标是将基线模型转变为快速且轻量级的模型。性能检查表明,第一级头部的单个生成转置卷积层消耗了总内存的三分之一。因此,本文将头放在第一级:它不仅对内存占用产生重大影响,从 661 Mb 减少到 415 Mb,减少了 1.5 倍,而且还增加了 +6 FPS。没有这个头,剪枝层显得多余,所以省略它。然后,在第四层移除头部,因为它专注于处理大型物体,这在室内场景中很少见。此外,如果限制骨干块中的输出通道数量,参数数量将从 68.3 M 急剧减少到 14.7 M,并且内存消耗减半。
Accuracy. : 在第二轮改进中,主要关注检测精度。实验表明中心性对预测质量没有贡献,可以无害地跳过。 Fcaf3d 分配器仅考虑 3D 边界框内的点。因此,这会带来丢失薄或小物体(例如白板)的风险,这些物体可能落在位置之间,因此不会被分配地面实况框。因此,引入了 TR3D 分配器,不考虑内部点,而是考虑最近的点,这些点也可能位于边界框之外。此外,预先定义了每个对象类别的头部级别:通常大型对象(例如床或沙发)在第三层处理,较小的对象(例如椅子或床头柜)在第二层处理。切换到新的多级分配器可将性能从 61.5 mAP 提升至 72.9。使用新颖的分配器,分配的点可能位于真实边界框之外。因此,IoU 可能等于 0,因此,为了强制训练过程,将 IoU 损失替换为 DIoU 损失,这成功地解决了这种情况。此最终更新允许在 21 FPS 下实现 74.5 mAP,具有 14.7M 参数和 207 Mb 峰值内存消耗的轻量级模型。总体而言,TR3D 消耗的内存比基准少 3 倍,参数减少 4.5 倍,并且需要的时间减少 2 倍。
TR3D+FF: RGB and Point Cloud Fusion
TR3D 执行早期 2D-3D 特征融合。首先,使用预训练的冻结 ResNet50+FPN 网络处理 RGB 图像,以解决 2D 对象检测任务。然后,提取的 2D 特征被投影到 3D 空间,与[Imvoxelnet]中相同。最后,通过将投影的 2D 特征与 3D 特征逐元素相加来执行融合。与现有方法相比,该策略明显更简单、更节省时间和内存(图 2);令人惊讶的是,它确保了更好的结果。
本文将融合模块合并到 VoteNet 和 TR3D 中,并评估基于点云和多模态设置的性能。此外,将 VoteNet+FF 与在 VoteNet 之上实现另一种特征融合策略的 ImVoteNet 进行比较。根据实验结果所示,本文的早期特征融合将 VoteNet 的检测精度提高了 +6.8 mAP@0.25,而 ImVoteNet 的增益较小,为 5.7 mAP@0.25。同时,通过特征融合,TR3D的检测精度提高了+2.3 mAP@0.25和+3.0 mAP@0.5。这种轻微但稳定的改进证明几何数据是主要的信息来源,而视觉数据是补充,可以作为改变估计的指导。
结论
本文介绍了 TR3D,一种新颖的 3D 物体检测方法。此外,开发了一种早期融合策略,将视觉特征合并到 3D 处理流程中,并提出了一种名为 TR3D+FF 的 TR3D 修改方案,它利用了点云和 RGB 输入。在标准基准测试上:ScanNet v2、SUN RGB-D 和 S3DIS评估了所提出的方法。通过实验,证明TR3D在精度和速度上都优于现有方法,从而在基于点云的3D物体检测中树立了新的最先进水平,而TR3D+FF在使用RGB和点的方法中取得了最好的结果。


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











