







摘要
本周的学习内容涵盖了领域自适应和强化学习两个方面。在领域自适应方面,深入研究了领域转移的概念,即如何应对数据从一个领域到另一个领域的变化。还学习了领域对抗训练,其中包括特征提取器、领域分类器的工作原理,以及该方法的局限性。
在强化学习方面,探究了其本质,即通过智能体与环境的交互来学习决策以最大化累积奖励。学习了强化学习的步骤,其中包括强化学习的难点以及与生成对抗网络的类比。深入研究了策略梯度方法,包括不同版本的策略梯度方法,为了优化智能体的决策策略,从而最大化累积奖励。
Abstract
This week’s study covered two main topics: domain adaptation and reinforcement learning. In the domain adaptation realm, a deep exploration was conducted into the concept of domain shift, addressing the challenges of data transitioning between different domains. The study also encompassed domain adversarial training, including the mechanisms of feature extraction and domain classification, along with acknowledging the limitations associated with this approach.
Within the realm of reinforcement learning, an inquiry into its fundamental essence was undertaken, emphasizing the learning of decision-making through interactions between an agent and its environment, with the aim of maximizing cumulative rewards. The steps involved in reinforcement learning were studied, encompassing the inherent difficulties and a comparison with generative adversarial networks. Furthermore, an in-depth analysis of policy gradient methods was conducted, covering various versions of this approach that seek to optimize decision-making policies of agents to maximize cumulative rewards.
1.Domain Adaptation
领域自适应是机器学习中的一个重要概念,指的是将模型从一个领域(源域)迁移到另一个领域(目标域)的过程,以便在目标域中获得良好的性能。在目标域中,可能存在与源域不同的数据分布和特征分布,因此需要通过各种技术和方法来解决领域差异,以确保模型的泛化能力和性能。领域自适应在实际应用中具有广泛的应用,如将在一个领域训练的模型应用于另一个领域,从而节省时间和资源,并在不同的数据分布下取得良好的效果。
1.1 Domain shift
在前面介绍的模型中,一般都会假设训练资料和测试资料符合相同的分布,这样模型才能够有较好的效果。而如果训练资料和测试资料是来自于不同的分布,这样就会让模型在测试集上的效果很差,这种问题称为Domain shift。那么对于这种两者分布不一致的情况,称训练的资料来自于Source Domain,测试的资料来自于Target Domain。那么对于领域转变的问题,具体的做法随着对于目标领域的了解程度不同而不同,主要有以下几种情况:
- 当前拥有少量目标领域的样本且含有标注:具体做法是取其中的一小部分去“微调”训练好的模型,但要注意不能够训练太多次迭代否则可能会对小部分的样本产生过拟合
- 拥有目标领域的大量资料但是没有标注
- 拥有很少量的目标领域的资料且没有标注
- 根据对于目标领域没有认识与了解
主要关注第二种情况,它是现实生活中的常见情况。那么最基本的想法是能不能训练一个 Feature Extractor,它可以接受训练集和测试集的样本,然后输出是对这些样本的关键特征进行提取,例如下图的例子中就是去除掉颜色的影响,提取它作为数字最关键的特征。
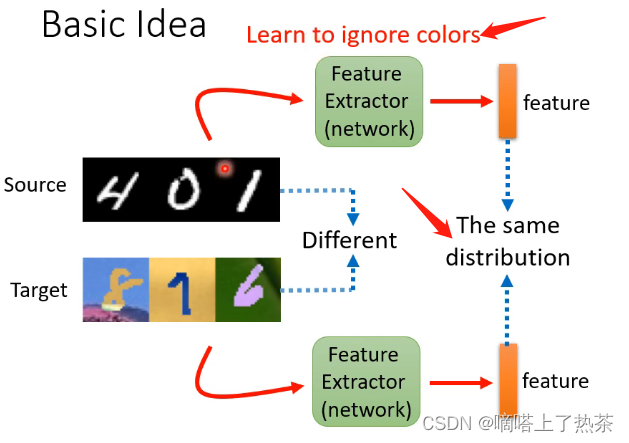
1.2 Domain Adversarial Training
1.2.1 Feature Extractor
如何找出这样的一个 Feature Extractor,以手写数字数据集来举例。把一个一般的 Classifier,分成 Feature Extractor,跟 Label Predictor 两个部分,那么卷积层就是特征提取,全连接层就是分类。
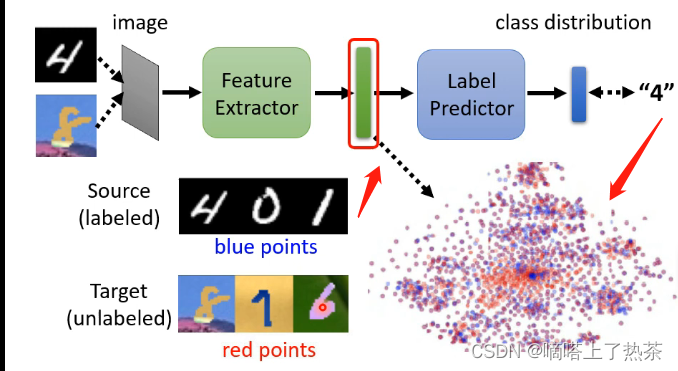
今天的方法是Domain Adversarial Training:
把有标注的 Source Domain 的资料丢进去,跟训练一个一般的分类器一样,它通过 Feature Extractor,再通过 Label Predictor,可以产生正确的答案。
而Target Domain 的这些资料是没有任何的标注的,把这些图片丢进这个 Image Classifier,然后把 Feature Extractor 的 Output 拿出来看,希望两个 Domain 的图片丢进去产生的 Feature,它们看起来分不出差异。
图片中就是让蓝色的点跟红色的点分不出差异。
1.2.2 Domain Classifier
这时候就想到了对抗的思想,可以加入一个Domain Classifier,它的输入就是Feature Extractor的这个输出向量,而输出就是该向量是来自于训练集还是测试集,因此可以将Feature Extracto看成是生成器,将Domain Classifier看成是二分类器,Feature Extractor是不断调整参数来骗过Domain Classifier,而Domain Classifier则不断学会来区分,如下图:
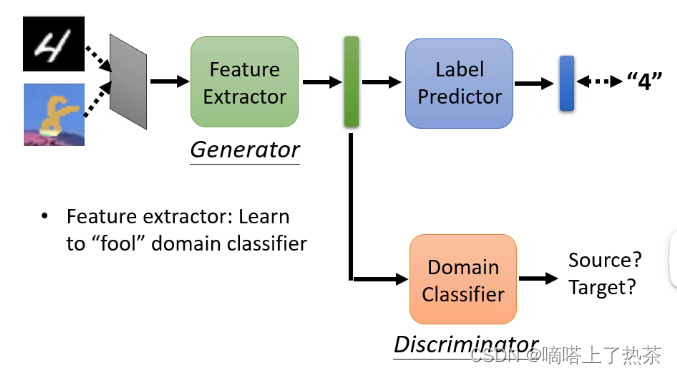
训练一个 Domain Classifier,它就是一个二元的分类器,它把这个 vector 当作输入,它要做的事情就是判断这个 vector 是来自于 Source Domain,还是来自于 Target Domain。
而 Feature Extractor 它学习的目标,就是要去想办法骗过这个 Domain Classifier,让它分辨不出来。(与GAN很相似)
用下面的图片把刚才讲过的事情,再说得更清楚一点:
- 假设Label Predictor的参数叫做θp;
- Domain Classifier的参数叫做θd;
- Feature Extractor的参数叫做θf;
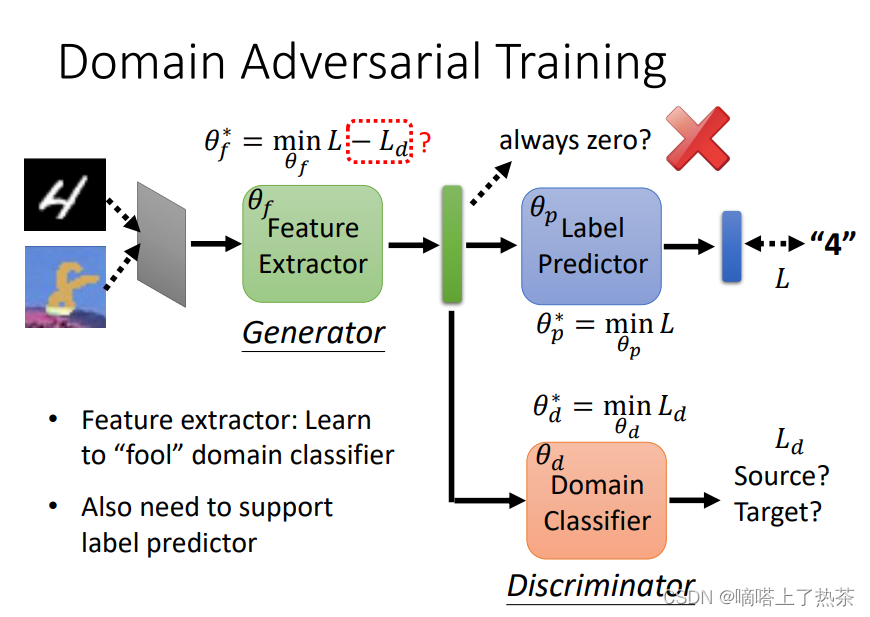
对于Feature Extractor的优化,一方面是为了能够降低后面预测数字分类的误差,另一方面是为了让Domain Classifier无法分辨,从而来使得两个分布更加接近。
1.2.3 Limitation
假设当前样本的类别有两类,那么对于有标签的训练集可以明显地划分为两类,那么对于没有标签的测试希望它的分布能够和训练集的分布越接近越好,如下图所示。
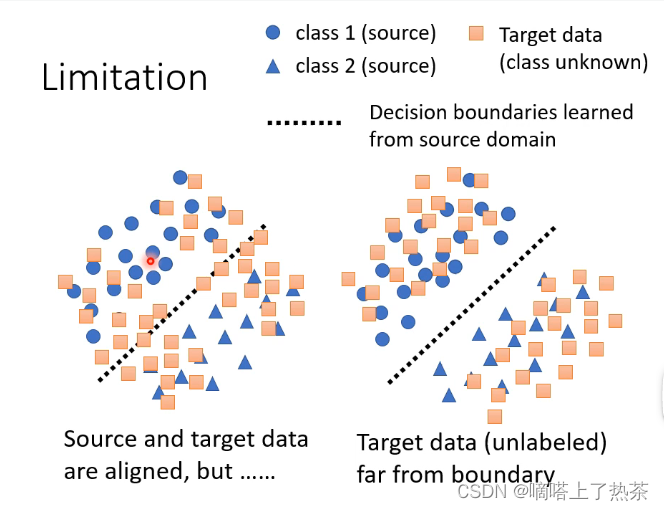
那么在这个思路上进行拓展的话,对于刚才手写识别的例子,输入一张图片得到的是一个向量,其中含有属于每一个分类的概率,那希望的是这个测试集的样本离分界线越远越好,那就代表它得到的输出向量要更加集中于某一类的概率,不能够各个分类的可能性都差不多,如下图所示。
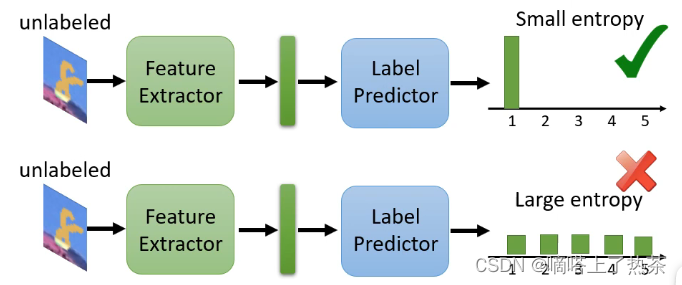
那么上述想法的问题在于,有没有可能训练集和测试集的分类根据就是不同的呢?例如训练集中可以分为老虎和狮子两类,而测试集还有另外的狼呢?如下图所示。
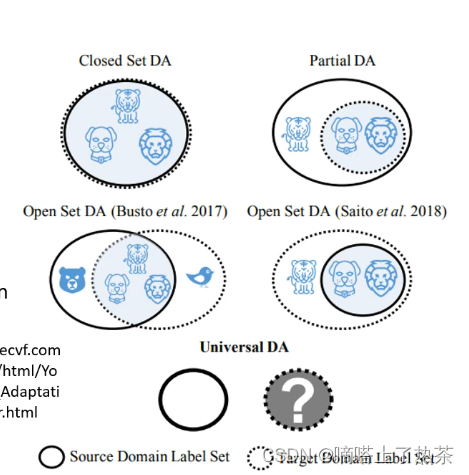
所以在这个前提之下,硬要把 Source Domain 跟 Target Domain 完全 Align 在一起是有问题的。
举例来说在这个 Case 里面,你要让 Source Domain 的 Data,跟 Target Domain 的 Data 的 Feature 完全 Match 在一起,那意味着说,你硬是要让老虎去变得跟狗像,或者是老虎硬是要变得跟狮子像,到时候你就分不出老虎这个类别了。如何解决请参考下面的论文 Universal Domain Adaptation。
2.Reinforcement Learning
强化学习是一种机器学习方法,旨在使机器通过与环境的交互来学习如何做出决策,以最大化累积的奖励。在强化学习中,机器通过尝试不同的行动,并根据环境的反馈来调整其策略,从而逐步学会在特定环境中采取最优行动。
2.1 The essence of reinforcement learning
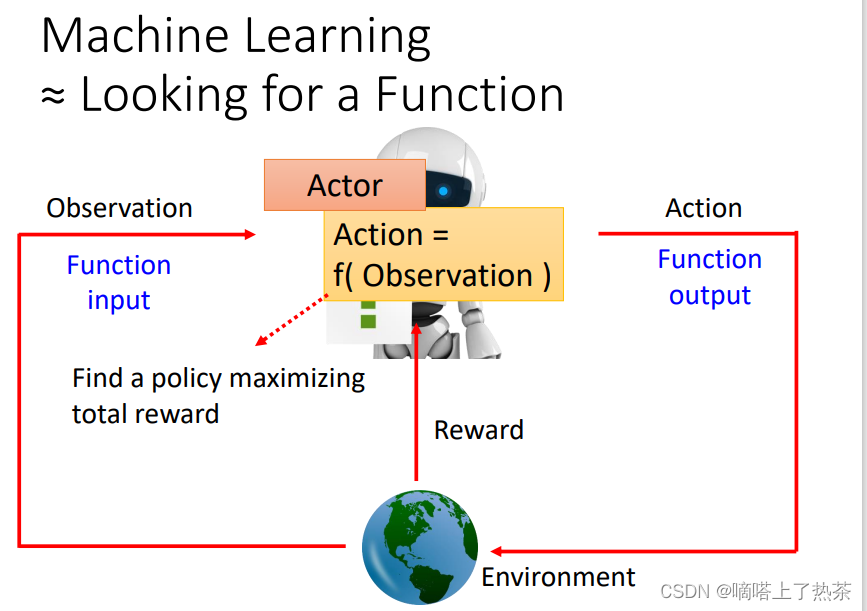
强化学习的过程和机器学习是一样的,都是寻找函数。不过在强化学习中寻找的函数叫做actor,actor 跟Environment会进行互动,actor能够接受环境给予的observation(观察),做出action去影响 Environment,然后Environment会给这个 Actor 一些 reward(奖励),这个reward说明action是好是坏。目的就是寻找一个用 Observation 当作Input,输出 Action,能将Reward总和最大化的actor,如下图所示。
2.2 Steps in Reinforcement Learning
还是三个步骤:
- 定义有未知参数的函数;
- 根据训练资料定义loss;
- 找出能够使loss最小化的函数(优化)
第一步:有未知参数的函数
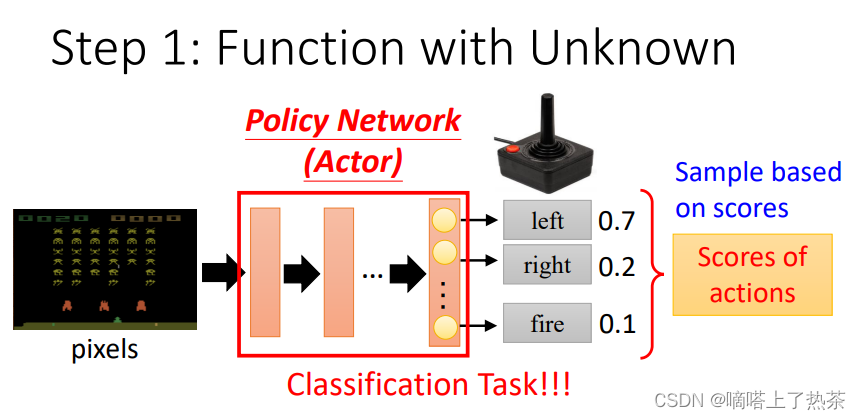
将机器的观察用向量或矩阵来表示,作为actor的输入;actor输出的每个action对应输出层的每个神经元,每个action会有一个分数。这样看和分类任务是一个东西,不同的点是:强化学习将这些分数作为几率,按照这个几率随机产生输出,也就是sample(采样),而不是将分数最高的那个作为输出。
Sample 有一个好处是说,就算是看到同样的游戏画面,机器每一次採取的行为也会略有不同,在很多的游戏裡面这种随机性也许是重要的,比如说你在做剪刀石头布的时候如果总是会出石头,就很容易被打爆,如果有一些随机性就比较不容易被打爆,如下图所示。
第二步:定义Loss
这里定义loss也就是定义分数的获得机制,但是最后想要最大化的是整局的全部分数之和,而不是局部某一次的分数。负的 Total Reward当做 Loss,最大化Total Reward等于最小化负的Total Reward,如下图所示。
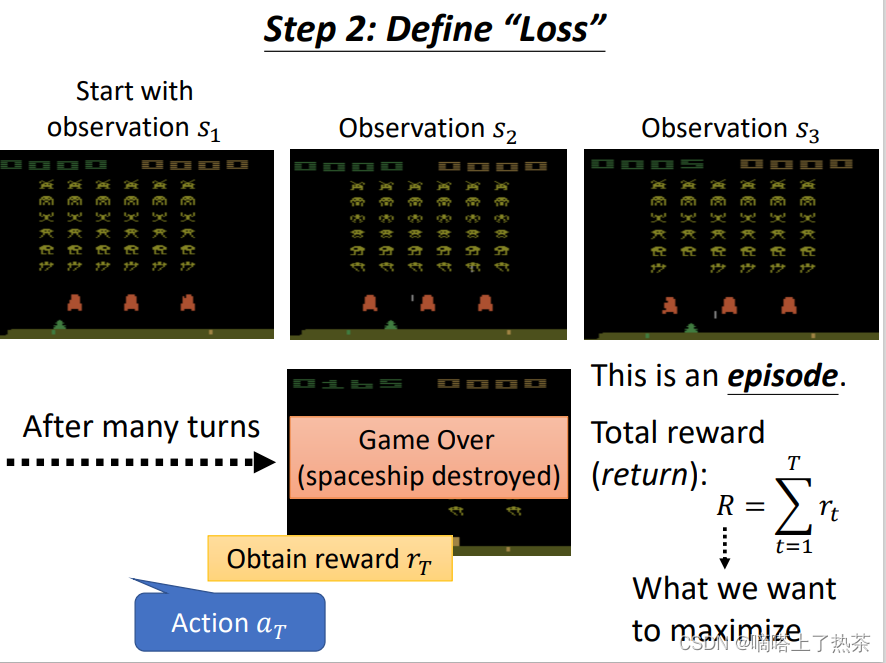
注:一局游戏就是一个episode;reward是某一个行为能立即得到的奖励,return是所有分数相加(total reward)。
第三步:Optimization
环境产生的Observation s1 (画面)进入actor(NN),actor通过采样输出一个a1(行动),a1再进入环境产生s2,如此往复循环,直到满足游戏中止的条件。s 跟 a 所形成的这个 Sequence又叫做 Trajectory,用 𝜏 来表示。
优化目标:找到 Actor 的一组参数,让R(𝜏)的值越大越好,如下图所示。
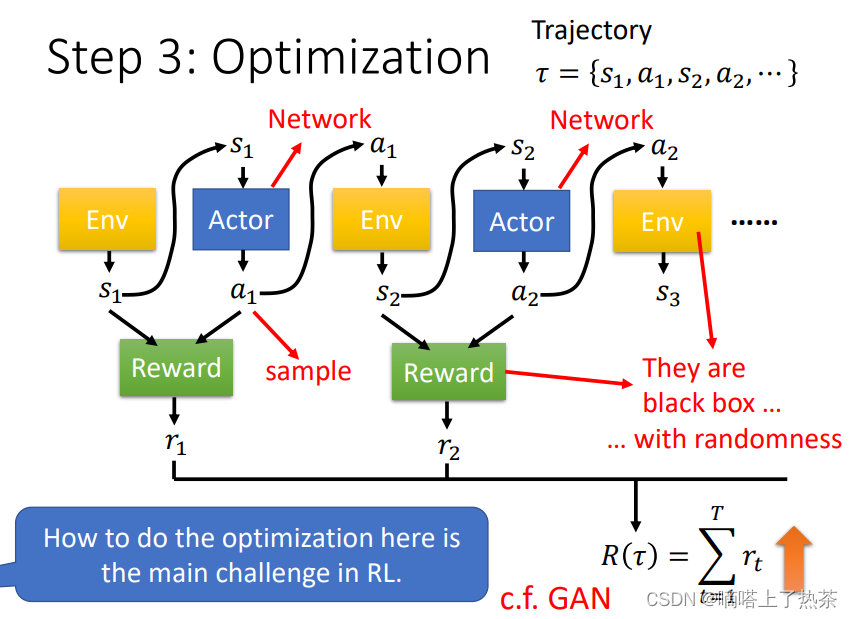
需要注意的是reward不是只看action,还需要看 Observation。
2.2.1 RL的难点
强化学习最主要的难点就是如何做optimizaton:
- action是通过采样产生的,具有很大的随机性,给相同的s,产生的a可能是不一样的。
- 一般的Network在不同的random seed设定下的随机性,是"Training"中的随机性,比如初始化参数随机;但是在Testing中,同样的输入会获得同样的输出。
- RL的随机性是在测试时,固定模型参数,同样的输入observation,会有不同的输出action。
- 只有actor是Network,Environment 和 Reward根本就不是 Network只是一个黑盒子而已;Environment与Reward都有随机性。
- 环境是黑箱,采取一个行为环境会有对应的回应,但是不知道到底是怎么产生这个回应,给定同样的行为,它可能每次的回应也都是不一样,具有随机性。
2.2.2 类比GAN
- 相同点:将actor看成是generator,将环境和reward看成是discriminator,训练出的generator能够使discriminator的corss entropy越大。
- 不同点:GAN的discriminator是network,而RL的discriminator不是network,无法用梯度下降等方法来调整参数来得到最好的结果。
2.3 Policy Gradient(策略梯度)
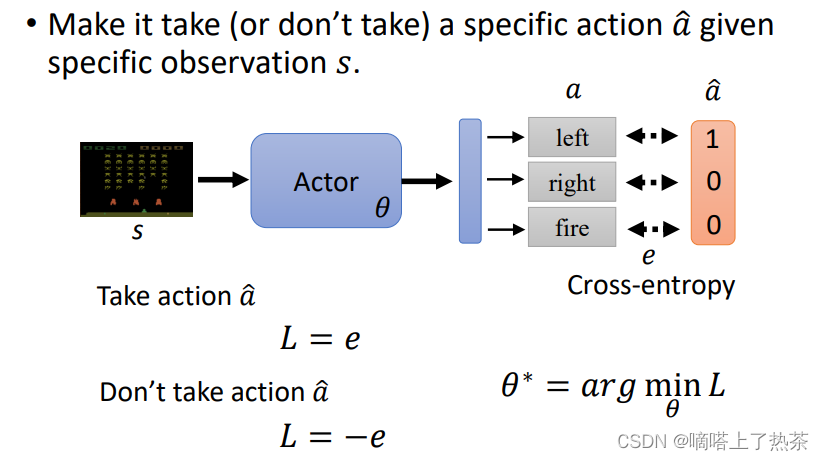
一个RL做optimization 常用的演算法,叫Policy Gradient。该如何控制actor呢,定义一个采取的确定行为的标签,然后计算loss,可以通过正负号实现采取或者不采取该项行为,如下图所示。
Loss等于想要的action的cross-enropy减去不想要的action的cross-enropy,如下图所示。
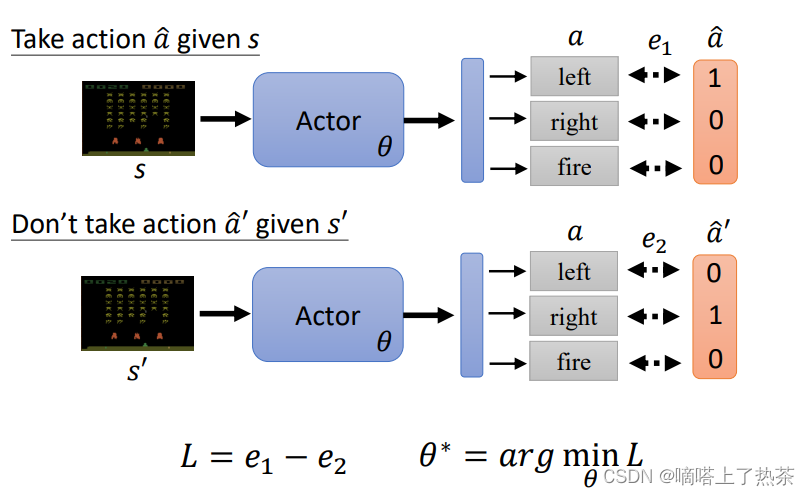
以上的是一个observation的Loss,现在延伸到N个observation。收集一堆这种资料,定义一个 Loss Function,训练 Actor,Minimize 这个 Loss Function,如下图所示。
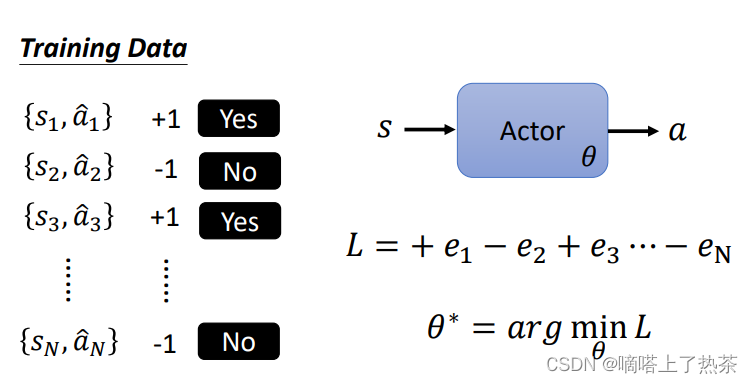
再加上使用权重和影响系数,控制每个行为的重要性,有多希望 Actor 去执行,这样train出来的actor才会更加好,如下图所示。

现在的问题是成对的训练资料和权重系数在哪里来?如何得来?
成对的训练资料通过随机的actor产生的结果{ }。
权重系数A有很多种表示方法,下面将会分几个版本介绍。
2.3.1 Version 0
让一个(随机的)Actor 去跟环境做互动,把它在每一个Observation执行的行为action都记录下来,每一个行为对应一个奖励Reward,将这个即时的Reward作为每个pair的A值。通常收集资料不会只把 Actor 跟环境做一个 Episode,通常会做多个 Episode,然后期待可以收集到足够的资料。
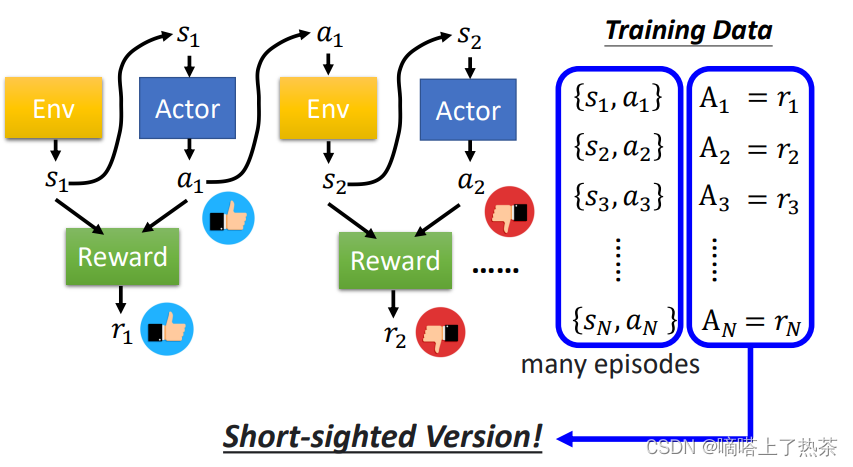
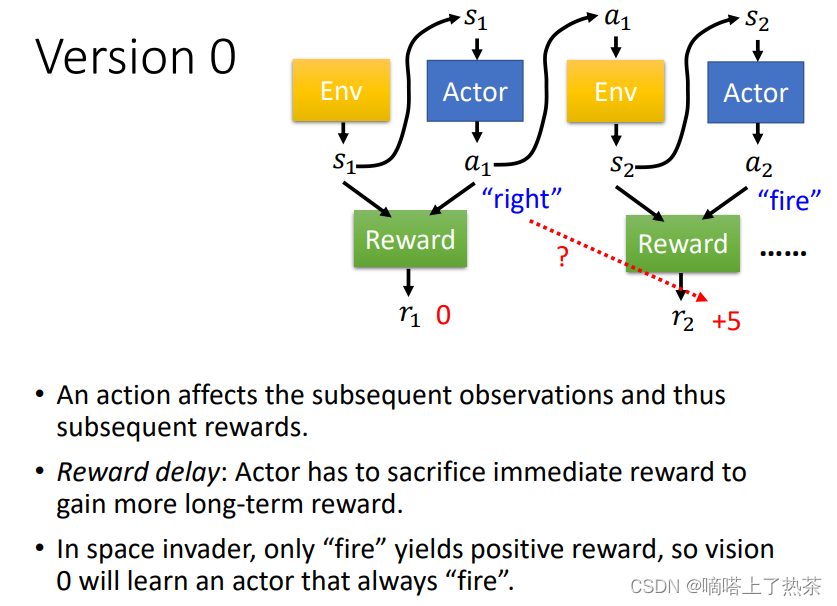
上图是version 0的想法,这样训练出来的actor没有长远的规划,只在乎一时的得失。因为每个行为不是独立的,会影响互动接下来的发展,有些奖励是会有延迟的Reward Delay,需要牺牲短暂的奖励来获得长程的奖励。以太空游戏为例,左右移动是没有奖励的,只有开火会有奖励,采用版本0则会导致actor一直做开火动作,不会左右移动。
2.3.2 Version 1
如下图所示,现在考虑长远规划,思想是每个行为对后面的影响是从这个行为开始到最后结束的每一步reward的总和,这样虽然解决了上述version 0的目光短浅,但是也带来了新的问题,就是当前这一步对后面的每一步影响真的都一样大吗?
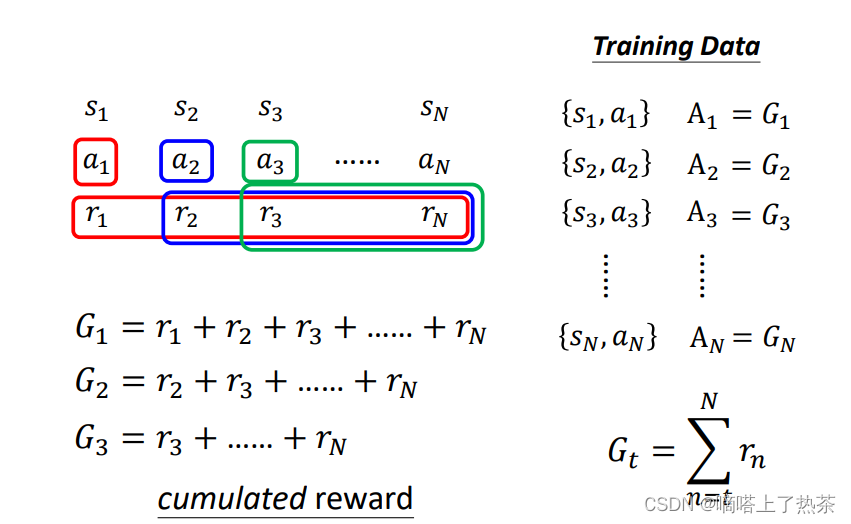
2.3.3 Version 2
为了解决version 1的问题,加入discount factor(折扣系数),一般取次方等等。这个折扣系数成幂次增长。这次计算出来的奖励称为discount cumulated reward(折扣累积奖励)。可以给离a1比较近的那些 Reward比较大的权重,比较远的那些 Reward比较小的权重,如下图所示。

version 2看起来好像已经很好了,但是还是存在一定的问题,就是没有考虑标准化,算出来的奖励是不具备参考性的,因为好的奖励分数和坏的奖励分数是相对的。同样是60分,全班很多人都考了90分,那60分就是差的,全班很多人都不及格,那60分就是好的。如果只是单纯的把 G 算出来,可能每一个行为都会给正的分数,只是有大有小的不同,有些行为其实是不好的,但是你仍然会鼓励Model去采取这些行为。
2.3.4 Version 3
标准化奖励,把所有的 G’ 都减掉一个 b(这个 b通常叫做 Baseline),A就有正有负了(采用减去b的方法), 这样就知道这个奖励在整体中到底是好是差,类似于算排名的感觉。

总结
本周的学习内容涵盖了领域自适应和强化学习的关键概念和方法。在领域自适应方面,了解了领域转移和领域对抗训练的原理,并认识到在实际应用中可能会面临的限制。在强化学习方面,深入理解了其核心概念,以及智能体如何通过与环境交互来学习最优决策策略。通过学习策略梯度方法,进一步扩展了对强化学习技术的认识,为进一步探索这一领域奠定了基础。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









