







深度学习基础概念
深度学习的目的就是找一个函数f,完成 y = f(x),x就是输入数据,y就是输出
输入x有三种类型:
1、向量
2、矩阵(张量):比如图片
3、序列:比如视频
输出y也有三种类型:
1、回归任务:填空题
2、分类任务:选择题
3、生成任务:结构化输出,其实是包含了前两种的,例如gpt,图片...
深度学习任务步骤

step1:定义一个线性函数  (也可以是二次的)
(也可以是二次的)
y^:预测值(输出),x:数据(输入),y:标签,x,y是已有的数据
w: weight权重,b: bias偏置/偏差,这两是未知数,需要我们学习不断更新的
step2:求损失函数
Loss就是判断我们的模拟函数(未知参数w,b)怎么样的函数,loss越小,就说明和真实值偏差越小,模拟函数越好
Loss是关于未知参数w,b的函数L(w,b),只是其中一种(均绝对误差MAE),也可以是绝对值的平方(均方误差MSE)

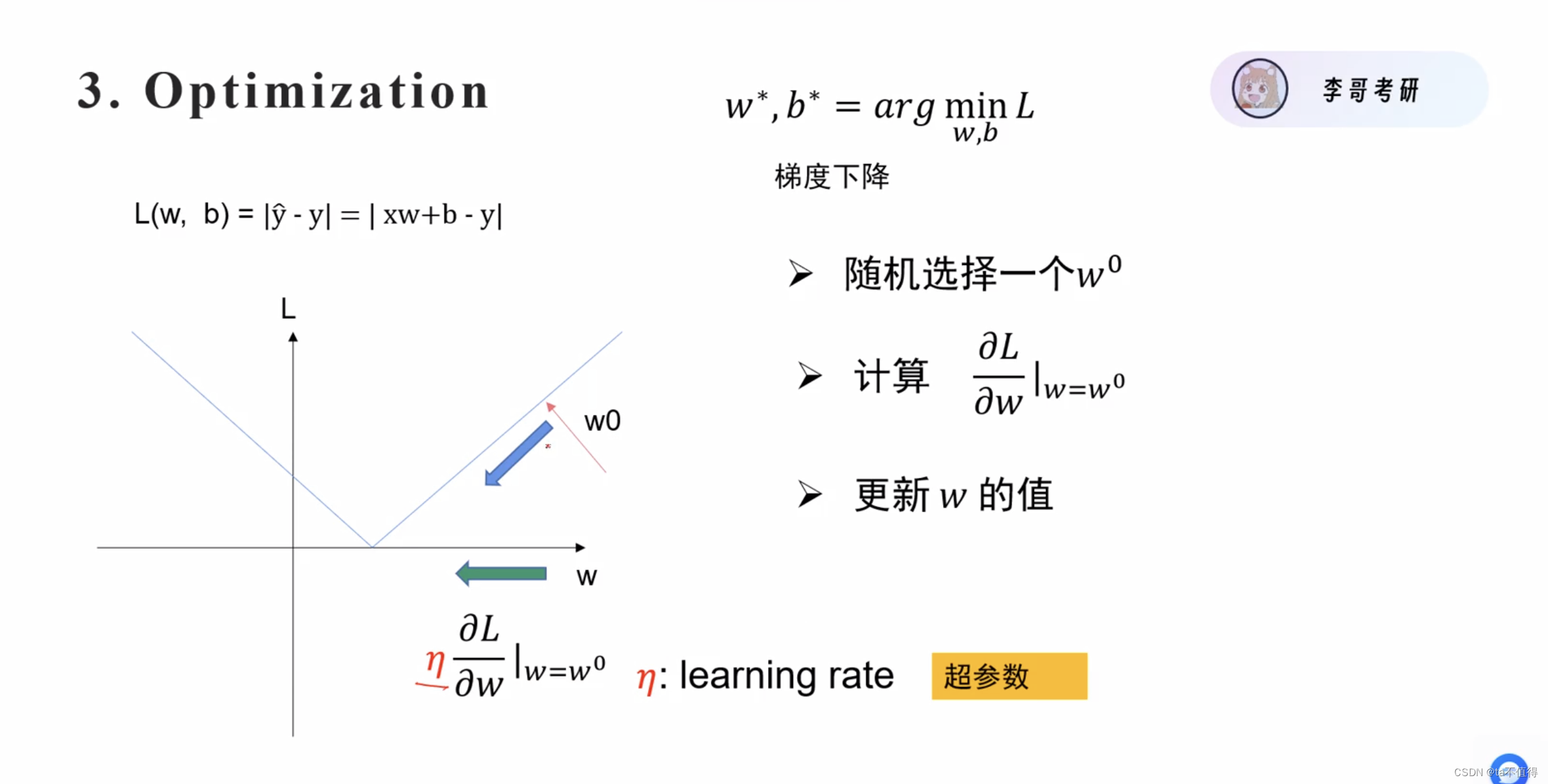
step3:优化Loss函数,求出让loss最小的w和b
方法:梯度下降(具体步骤在后续介绍)
先随机取一个w0,再计算loss在w0点的偏导数n,如果大于0,则说明斜率大于0,最小值点肯定在左边,要往左走,走n*lr的距离,lr是学习率(超参数,learning rate),“调参侠”的参数就是指这个参数。
w1 = w0 - lr*n,w2.... b同理

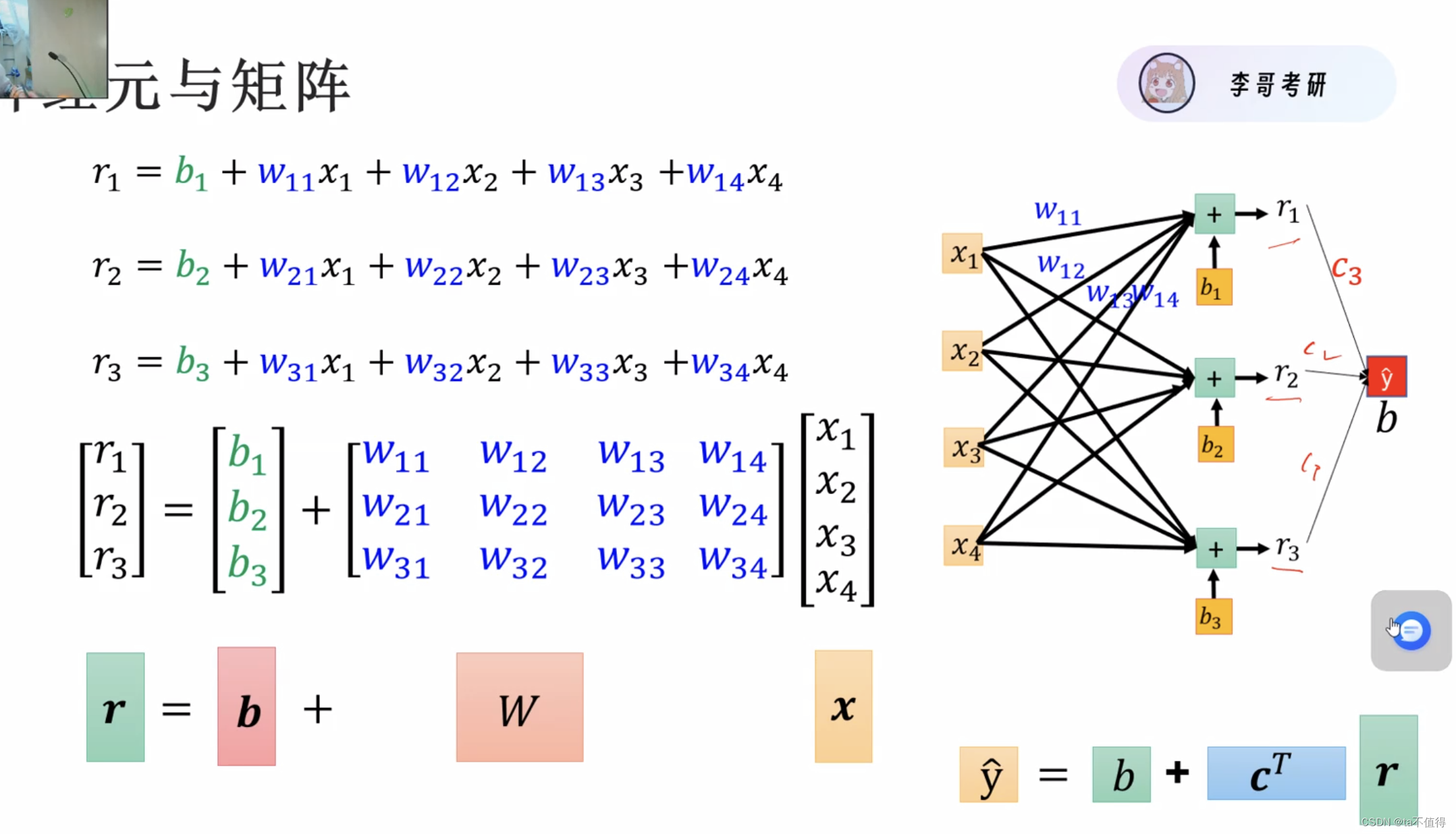
神经网络与神经元
通常一个输出y可能受到多种因素的影响(模拟神经元的多个突触),x1,x2,x3....每一种输入数据x都会分别对应一个权重w1,w2,w3,最终的输出y是它们的累加之和再加偏置b

如果多个神经元组成的神经网络,y的计算就是矩阵的运算,见下图
如果每一个神经元都只是线性函数的串联传递,最终化简得到的式子都是一个关于最开始的输入x1,x2,x3的线性关系,即这样一来再深的神经网络输入和输出都是线性关系,故要添加激活函数。
激活函数
激活函数,例如sigmoid,relu函数,激活函数最重要的特点是能求导,因为要更新参数需要梯度下降,即要求偏导,添加了激活函数,在复合求导的过程中也要对激活函数求导,所以必须可导。


参数量
参数量θ就是这个神经网络模型中有多少个w,b,要学会计算一个模型的参数量

深度学习的训练过程
梯度下降:
梯度是一个向量,表示的是损失函数在某个点处各输入参数相对于输出变化率的最大方向和大小。在训练过程中,我们采用梯度下降法(Gradient Descent)来更新参数,即按照梯度的反方向调整参数值,这样可以使损失函数逐步减小,从而让模型更好地拟合训练数据。
具体步骤:
- 前向传播(Forward Propagation): 输入数据x通过神经网络,通过各种矩阵以及激活函数计算出预测值y^和相应的损失值loss。例如算
- 梯度回传(Backward Propagation): 利用链式法则逐层反向求导,计算损失函数关于各个参数的梯度。
- 参数更新(Parameter Update): 根据梯度信息一层层地反向更新模型参数θ。

过拟合和欠拟合
过拟合(Overfitting): 过拟合发生在模型在训练数据上表现得非常好,但在新的、未见过的数据上表现不佳。这通常是因为模型学习到了训练数据中的噪声和细节(想把每一个数据都串起来),而不仅仅是底层的数据分布。过拟合的模型复杂度过高,它能够捕捉到训练数据中的每一个小波动,包括那些并不具有普遍性的波动。
过拟合的常见原因包括:
- 模型过于复杂:拥有太多参数的模型更容易过拟合。
- 训练数据不足:如果训练数据量太少,模型可能无法学习到数据的真实分布。
- 数据泄露:模型在训练过程中不小心接触到了测试数据。
欠拟合(Underfitting): 欠拟合则是指模型在训练数据上的表现都不好,更不用说在新数据上了。这通常发生在模型太简单,无法捕捉数据中的复杂关系时。欠拟合的模型复杂度不够,它忽略了数据中的重要信息,导致无法学习到数据的真实结构。
欠拟合的常见原因包括:
- 模型过于简单:模型结构不足以捕捉数据的复杂性。
- 训练不充分:模型没有足够的时间或数据来学习数据的特征。
- 特征工程不足:没有足够的特征或特征选择不当,导致模型无法学习到有用的信息。
为了解决这些问题,可以采取以下策略:
- 对于过拟合,可以尝试使用正则化(如L1、L2正则化)、增加数据量、使用Dropout、简化模型结构、使用数据增强等方法。
- 对于欠拟合,可以尝试增加模型复杂度、提供更多的训练时间、改进特征工程等。
在实际应用中,通常需要在模型的复杂度和泛化能力之间找到一个平衡点,以确保模型既不会过拟合也不会欠拟合。这通常通过交叉验证和调整模型的超参数来实现。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









