







Kaggle
Kaggle是一个提供免费CPU,GPU,TPU的编程(主要是机器学习,其他也行),学习,竞赛的网站。(若有colab,可无视此篇)
对于只为了编程的作用而言(如果你的电脑GPU足够强劲,可以不用过多关心了,数据分析Jupyter,常规编程Pycharm,Vim,Sublime等等这些足够了)
Kaggle的注册,验证账号等等,网上文章众多,在此就不赘述。。。
文件
常用的,帮助显示你的文件夹内容的一些命令
import os
print(os.listdir('./')) # 显示当前运行的文件夹内容
print(os.listdir('/kaggle')) #显示kaggle目录下所有文件
print(os.listdir('/')) #显示文件根目录
1.文件压缩包的下载和解压
该压缩包与Kaggle官网无关,只是我在机器学习使用的一些数据
!wget --no-check-certificate \
http://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip \
-O /tmp/validation-horse-or-human.zip
!wget --no-check-certificate \
http://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \
-O /tmp/horse-or-human.zip
import zipfile
train = zipfile.ZipFile("/tmp/horse-or-human.zip")
train.extractall(path="/tmp/horse-or-human")
validation = zipfile.ZipFile("/tmp/validation-horse-or-human.zip")
validation.extractall(path="/tmp/validation-horse-or-human")
2.文件目录结构
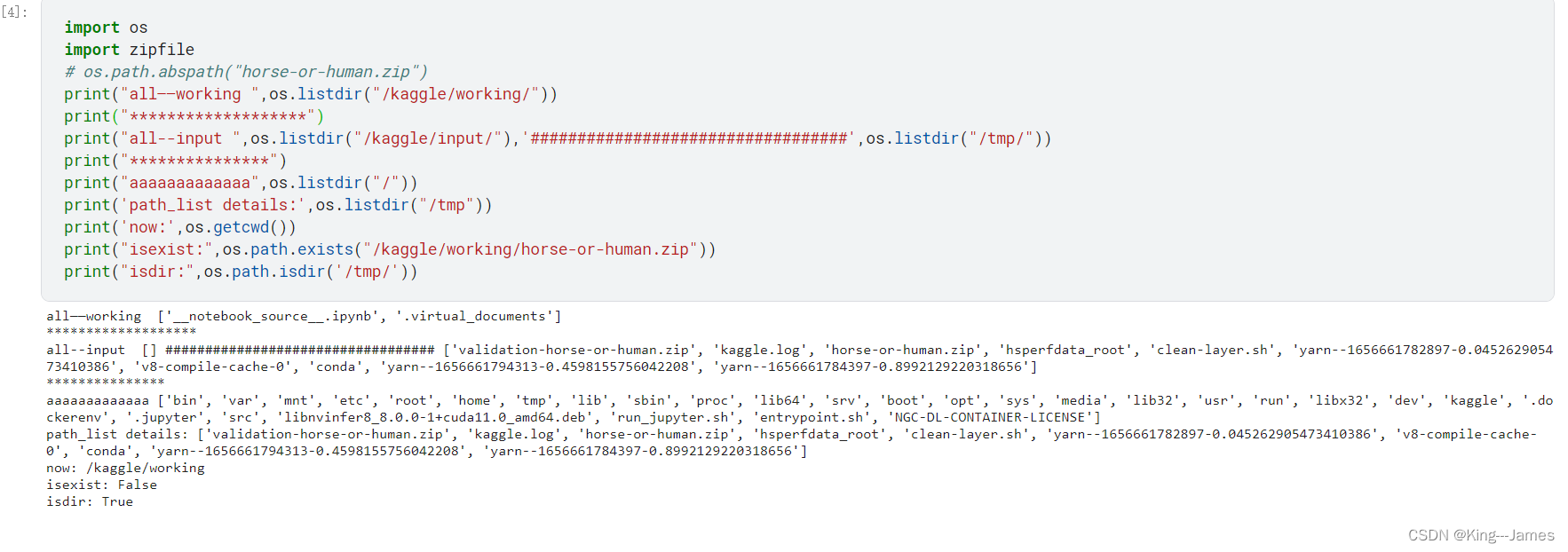
kaggle的详细目录结果如图所示,注意并非只有working和input目录,并且kaggle也不是根目录,只是一个子目录
3.Kaggle目录中的文件下载到本地
在本人多次尝试下(但也可能不一定对[doge]),应该只有把你要下载的文件夹,放到/kaggle/working/这个目录下,才能正确使用一下代码
new_movies.to_csv("/kaggel/working/Douban_movie.csv") #保存文件
import os
os.chdir('/kaggle/working') #将cell的文件夹切换到下载的文件所在文件夹
from IPython.display import FileLink
FileLink('Douban_movie.csv')
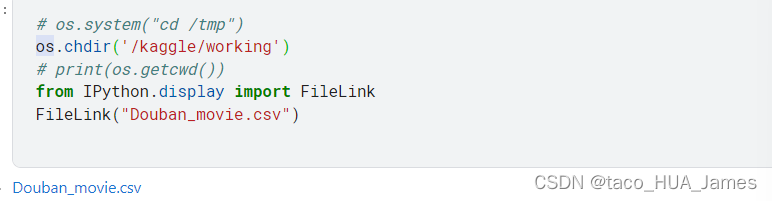
执行完后,会出现链接,如下所示的右下角蓝体字,点击后就会下载
注意
在你每次更换Accelerator后,所有下载文件,创建的目录,原来缓存的数据,结果都会被清空。
在你重启后也会清空。
语法补全
Tab键补全
%config Completer.use_jedi = False
比原来的自身的补全,强一些(本人感觉不太明显[doge]),但还是比不上Kite
个人觉得Kaggle还是不错,免费处理器,足够的文件储存空间,而且对于国内用户还是比较友好的
另外也推荐colab,只是国内一般不好访问,而且访问到了也容易断
以上均为个人见解,求轻喷


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











