






多模态模型:CLIP
这个就是chatgpt使用的text-images模型
论文标题:Learning Transferable Visual Models From Natural Language Supervision
时间 2021
期刊 ICML
论文网址:[2103.00020] Learning Transferable Visual Models From Natural Language Supervision
主要文章参考:【论文&模型讲解】CLIP(Learning Transferable Visual Models From Natural Language Supervision)-CSDN博客
1.摘要
首先目前的SOTA计算机视觉系统通常用来被训练固定的预定对象类别,这大大限制了他们的通用性与适用性。(就是我们传统的图像分类思想就是,我们先去标记猫狗数据集,然后让模型训练,训练之后只能分类猫狗)
(举个例子就是我做了一个猫狗分类系统,他只能分类猫狗,我忽然加了一头鸭嘴兽的图片,他无法分辨,我们必须把猪的图片标记出来,我们才知道他是一头猪)。作者这个思路就是我们在训练图像时,我们把他们的语义信息也去进行一个学习,我们学习 猫 狗 鸭嘴兽的语义,这样的话我们就可以根据语义信息(比如扁嘴,有毛发,水生哺乳动物)来去找出找出我们视觉系统中没有出现的鸭嘴兽。
作者的思路是先去进行一个预训练任务(那个任务的内容就是根据文本信息去对图像信息进行分类,作者凭借文本来去判断图像)作者通过自监督来去预训练出一个大模型。
预处理之后,我们的这个模型就是根据文本信息去判断图片信息的(判断出的图片可能是使我们没学过的,也可能是我们学过的,比如我们只学过猫狗,但是我们仍然可以通过必要的文本信息来判断出来鸭嘴兽,(就是可以做到一个推理的作用,也就算是实现了零样本训练))。
(后面就是废话 说作者这个模型不训练就很吊)
2.引言与启发性研究
bert,gpt,t5这几年很牛逼,但他们无论是使用还是所谓的自回归预测还是“完形填空”,他们的函数都与下游无关,只要资源够多,他们的性能都能无限提升。他们都是text-to-text文字,并不是分类任务(这也是与下游无关的,他们几乎不需要再去学习下游的数据集)。包括作者做的这个也是,他与下游关系不大。
上面例子说明:在text-to-text领域,我们大量的没有标注的数据集要远远比少量的人工标注好的数据集要有效得多。当时在CV领域,还是那种传统的先去训练数据集,然后根据数据集去判断别的,他没有一个类似GPT这种上游的大规模模型。作者就是想去开创这个先例,弄一个大规模的模型。
在Transformer没出现之前,已经有人提出了这个思路,但是由于当时没出现Transformer,所以它的性能并不好,然后又出现了“对比学习”“完形填空”“transformer”,一些学者也尝试去弄一个大型的模型,但是他们都有各自的缺点(VirTex使用自回归的预测方式做模型的预训练;ICMLM使用 ”完形填空“ 的方法做预训练;ConVIRT 与 CLIP 很相似,但只在医学影像上做了实验)
作者跑了三十多个数据集,发现效果很好,为了验证CLIP特征提取的有效性,作者先不进行零样本训练,而是使用了linear-probe,(在预训练模型训练好之后就把模型参数冻结,只训练最后一层的分类头去做分类任务)效果良好。然后开始零样本训练,发下CLIP的零样本训练比其他模型在ImageNet数据集上训练效果要好。
2. 方法
2.1 自然语言监督
作者思想的核心思路为:用自然语言的监督信号来去训练一个比较好的视觉模型。
作者的这个思路在前几年就被人反复提及过了。很多人提出了从与图像配对的文本中学习视觉表征的方法,但他们分别将自己的方法描述为无监督、自监督、弱监督和有监督的。
作者的核心就是把重点放在了自然语言监督学习方面,作者把所有的方法都放在自然语言中监督学习。与其他方法相比,自然语言不需要采用大量的人工数据标注,而是可以从大量的互联网文字上进行大规模的自动学习。自然语言不仅仅是一个表征,它能够将表征与语言建立联系,从而更容易实现迁移,更加容易去坐零样本学习。
模型的整体结构:
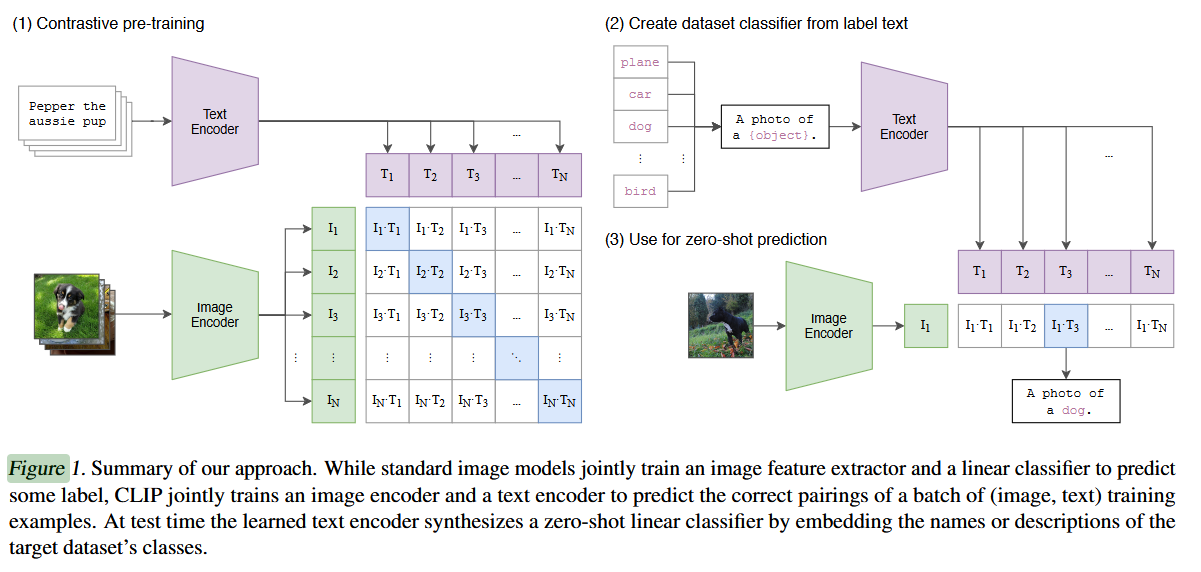
图 1. 我们的方法概述。标准图像模型会联合训练图像特征提取器和线性分类器来预测某些标签,而 CLIP(对比语言 - 图像预训练)则联合训练图像编码器和文本编码器,以预测一批(图像,文本)训练示例的正确配对。在测试时,经过训练的文本编码器通过嵌入目标数据集类别的名称或描述,合成一个零样本线性分类器。

模型的输入是若干个 图像-文本 对儿(如图最上面的数据中图像是一个小狗,文本是 ”Pepper the aussie pup”)。
2.1.1 Contrastive pre-training
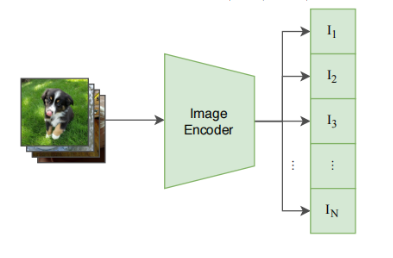
模型的输入是若干个 图像-文本 对儿(如图最上面的数据中图像是一个小狗,文本是 ”Pepper the aussie pup”)这个 encoder 既可以是 ResNet,也可以是 Vision Transformer。
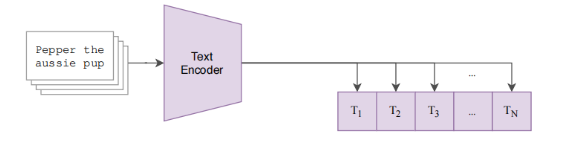
文本部分:文本通过一个 Text Encoder 得到一些文本的特征。同样假设每个 training batch 都有 N 个 图像。
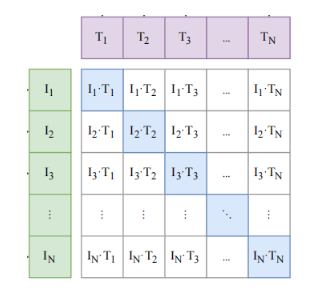
CLIP 就是在以上这些特征上去做对比学习,对比学习非常灵活,只需要正样本和负样本的定义,其它都是正常套路。蓝色就是正样本,其他为负样本。有了正负样本之后,就可以让模型通过对比学习去进行训练,不需要手工标准,也就是无监督训练。(openai使用了一个4亿图片-文本对的数据集,所以CLIP效果很吊)。
2.2.2 Create dataset classifier from label text
CLIP 经过预训练后只能得到视觉上和文本上的特征,并没有在任何分类的任务上去做继续的训练或微调,所以它没有分类头,那么 CLIP 是如何做推理的,这里是他的分类头。
作者提出 prompt template:以 ImageNet 为例,CLIP 先把 ImageNet 这1000个类(如图中"plane", “car”, “dog”, …, “brid”)变成一个句子,也就是将这些类别去替代 “A photo of a {object}” 中的 “{object}” ,以 “plane” 类为例,它就变成"A photo of a plane",那么 ImageNet 里的1000个类别就都在这里生成了1000个句子,然后通过先前预训练好的 Text Encoder 就会得到1000个文本的特征。
其实如果直接用单词(“plane”, “car”, “dog”, …, “brid”)直接去抽取文本特征也是可以的,但是因为在模型预训练时,与图像对应的都是句子,如果在推理的时候,把所有的文本都变成了单词,那这样就跟训练时看到的文本不太一样了,所以效果就会有所下降。此外,在推理时如何将单词变成句子也是有讲究的,作者也提出了 prompt engineering 和 prompt ensemble,而且不需要重新训练模型。
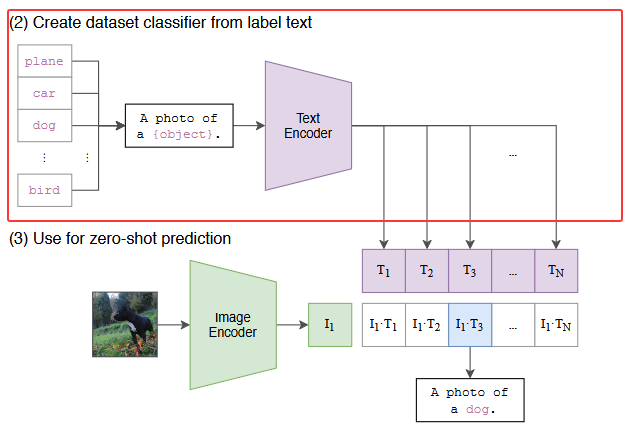
2.2.3 Use for zero-shot prediction
在推理时,无论来了任何一张图片,只要把这张图片扔给 Image Encoder,得到图像特征,然后把图像特征和所有的文本特征去进行一个结合,就拿这个图片特征去跟所有的文本特征,去做 cosine similarity(余弦相似度)计算相似度,来看这张图片与哪个文本最相似,就把这个文本特征所对应的句子挑出来,从而完成这个分类任务。
在实际应用中,在实际应用中,这个类别的标签也是可以改的,不必非得是 ImageNet 中的1000个类,可以换成任何的单词;这个图片也不需要是 ImageNet 的图片,也可以是任何的图片,依旧可以通过算相似度来判断这图中含有哪些物体。
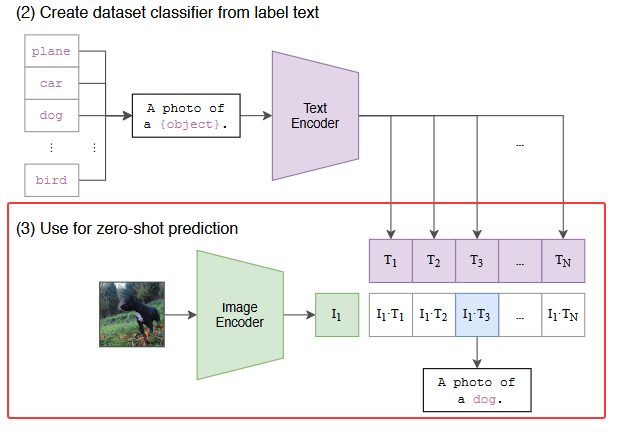
CLIP 彻底摆脱了 categorical label 的限制,无论在训练时,还是在推理时,都不需要有这么一个提前定好的标签列表,任意给出一张图片,都可以通过给模型不同的文本句子,从而知道这张图片里有没有我想要的物体。
2.2创建足够大的数据集
现有研究主要使用了三个数据集,即微软通用对象上下文(MS - COCO)数据集、视觉基因组(Visual Genome)数据集和 YFCC100M 数据集。这些数据集太小了,有一些很大的数据集,但是他们质量不太好,所以也没法用。总结:目前的所有数据集规模都太小了。
采用自然语言监督的原因是:互联网上有大量这种形式的公开可用数据。由于现有数据集未能充分体现这种可能性,仅基于这些数据集得出的结果会低估这一研究方向的潜力。作者构建了一个新的数据集4 亿个(图像,文本)对。50 万个查询词之一的(图像,文本)对。每个查询词最多包含 2 万个(图像,文本)对。这个数据集成为WIT。
2.3选择高效的预训练方法
最先进的计算机视觉系统需要大量的计算资源。所以预训练非常重要。
起初,研究团队像 VirTex 那样,从零联合训练图像 CNN 和文本 transformer 来预测图像标题,但扩展时遇到困难,发现预测文本具体词汇很难,计算量很大。后来受相关研究启发,团队换了个思路:不预测文本具体词汇,而是预测哪段文本和哪张图像匹配。(原来是用图片推文本,现在是根据文本描述去选择那个图片更合适),这与的话速度就变得非常快。
下图中,绿色的目标函数是对比形目标函数,黄色的是对比形目标函数,只是改了一个预测函数,效率提高了四倍。

图2,蓝线部分就是基于 Transformer 做预测型任务(如 GPT)的训练效率;橘黄色线是使用 BOW 的方式做预测任务,也就是说不需要逐字逐句地去预测文本,文本已经被全局化地抽成了一些特征,约束也就放宽了,可以看到约束放宽以后训练效率提高了三倍;如果进一步放宽约束,即不在去预测单词,只是判断图片和文本是否匹配(图中绿线),这个效率又进一步提高了4倍。

因为数据量非常大,所以基本不需要什么数据增强,作者使用的唯一数据增强就是随机裁剪。
由于模型和数据集太大了,他不好进行调参数,所以作者把temperature 设置为可学习的log-parametized 乘法标量,让他自己去调,调着调着,他就把自己优化掉了,就不用管调参的事情了。



2.4 模型的选择与收缩
这段就是介绍了一下CLIP 模型中图像编码器和文本编码器所采用的架构。
图像编码器:
基于 ResNet - 50 的架构:选用广泛应用且性能可靠的 ResNet - 50 作为基础架构,并依据其他研究成果做了多处修改,如采用 ResNet - D 改进、抗锯齿矩形 2 模糊池化,还将全局平均池化层替换为注意力池化机制。(我也不知道这个ResNet-D和锯齿形矩阵模糊池化是啥意思,先当成Resnet50去看)
视觉 Transformer(ViT)架构:尝试使用 ViT 作为另一种图像编码器架构,在遵循其原始实现的基础上,仅做了细微修改,如增加一层归一化处理和采用不同的初始化方案。(视为一个VIT架构)
文本编码器:
采用 Transformer 架构,并参考相关研究进行了架构修改。基础版本是一个具有 6300 万个参数、12 层、宽度为 512 且有 8 个注意力头的模型,对文本进行小写字节对编码(BPE)处理,为提升计算效率限制最大序列长度,通过特定方式获取文本特征表示并映射到多模态嵌入空间,同时使用掩码自注意力机制保留特定能力。**模型扩展策略**:
对于 ResNet 图像编码器,采用在宽度、深度和分辨率上平均分配额外计算资源的方式进行扩展;对于文本编码器,仅按比例缩放宽度,因为 CLIP 性能对其深度不敏感。
2.5训练
作者训练了 5 个 ResNet 模型和 3 个视觉 Transformer模型。
ResNet - 50
ResNet - 101
EfficientNet 风格的模型扩展方式又训练了 3 个。他们都计算量特别大。
对于视觉 Transformer 模型,我们训练了 ViT- B/32、ViT - B/16 和 ViT - L/14。
epoch=32。
Adam 优化器
余弦退火调度衰减学习率
batch=32768
混合精度训练节省内存
梯度检查点
半精度 Adam 统计量
最后得到 ViT - L/14性能最佳
3.实验
3.1零样本迁移
3.1.1动机
零样本学习通常指研究如何将模型泛化到图像分类中未见过的目标类别。就是研究模型对未见过的数据集的泛化能力。以此衡量机器学习系统的任务学习能力,而非仅关注表征学习能力。同时指出许多计算机视觉数据集是通用基准,在这类数据集上做零样本迁移,更多评估的是模型对数据分布变化和领域泛化的鲁棒性。
(后面两段没太理解啥意思,没太看懂)
3.1.2使用 CLIP 进行零样本迁移
CLIP 经过预先训练,能判断图像和一段文本在它的训练数据里是不是一对儿。这个就是重点
对于处理数据集时,我们先把所有的文字和图片全部列举出来,然后让CLIP找出来那一对是最有可能相互匹配的。
具体做法:先用图像编码器算出图像的特征,再用文本编码器算出那些类别名文本的特征,接着算图像和每个文本特征之间的相似度,用一个叫温度参数 τ 的东西调整一下这个相似度数值,最后通过softmax函数把这些数值变成概率,概率最高的那对,就是预测结果。
图像编码器是核心部分,他主要用来计算特征表示,文本编码器根据视觉概念的文本,去生成线性分类器的权重。
(基本也是废话)
3.1.3 与 Visual N-grams 对比
Visual N-grams 首次以上述方式研究了 zero-shot 向现有图像分类数据集的迁移。(就是CLIP的预训练数据集数据量是Visual N-Grams预训练数据集的十倍,,使用的视觉模型每次预测所需的计算量几乎是其 100 倍,训练所需的计算量可能超过其 1000 倍)(他没有进行控制变量法,他只是为了凸显CLIP的牛逼,因为两个方法已经相差了四年)
这俩都是零样本去分类。
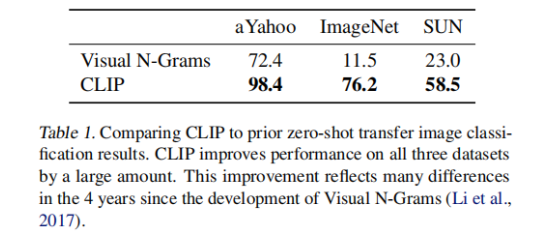
表 1. CLIP 与先前零样本迁移图像分类结果的比较。CLIP 在全部三个数据集上的性能都有大幅提升。自视觉 N 元语法模型开发以来的四年中出现的诸多变化,促成了这一提升。
3.1.4提示工程与集成
prompt 主要是在做做推理时的一种方法,而不是在预训练阶段,所以不需要那么多的计算资源,并且效果也很好。prompt 指的是提示,即文本的引导作用。
为什么需要去做提示?
一词多义:我们在做文本图片匹配时,会遇到一些有歧义的情况,比如Crane,它有鹤和起重机两个意思,如果我们的提示词应该考虑全局情况,比如我们在工地时,他应该考虑起重机而不是鹤,我们的提示词应该是一个句子。
做预训练时,匹配的文本一般都是一个句子,很少是一个单词。如果推理时传进来的是一个单词的话,很容易出现 distribution gap,提取的特征可能不是很好。
为了解决以上两种问题,作者设置了prompt template(提示模板),“A photo of a { label }”这样的话,他就不容易引起错误指引,而且Label 也一般都是名词,也能减少歧义性的问题。使用后准确率上升了1.3%。
大改八十多种模板:

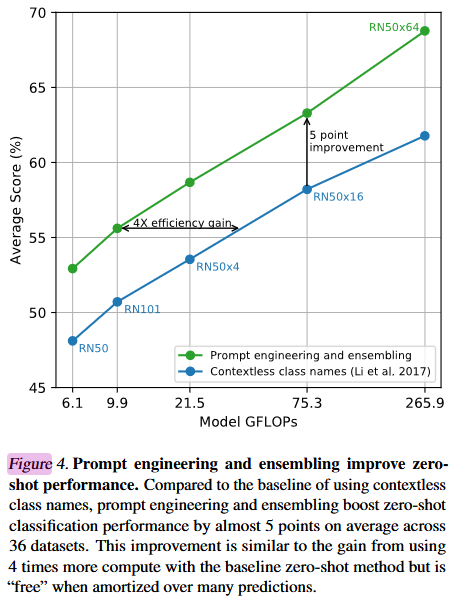
图 4. 提示工程和集成提升零样本性能。与使用无上下文类别名称的基线方法相比,提示工程和集成在 36 个数据集上平均将零样本分类性能提高了近 5 个百分点。这种提升效果与在基线零样本方法上使用 4 倍计算量所带来的提升相近,但在进行多次预测时,它的计算效率要高得多。
提示工程和集成对 CLIP 模型零样本分类性能的影响,对比对象是直接使用无上下文类别名称的基线方法

3.1.5零样本 CLIP 性能分析
作者在 27 个数据集上衡量了 CLIP 做 zero-shot 迁移的效果,如图 Figure 5,比较的双方分别是 做 zero-shot 的 CLIP 和 在 ResNet50 上做 linear probe(linear probe:把预训练好的模型中的参数冻结,只从里面去提取特征,然后只训练最后一层即 FC 分类头层)。这个 ResNet 是在 ImageNet 有监督训练好的模型,从中去抽特征,然后在下游任务中去添加新的分类头,在新的分类头上做 linear probe 的微调。
(总结一下就是这里的CLIP在作者的4亿数据集中预训练过,这里的Resnet50在那个一千类别ImageNet 进行了预训练,然后改变分类头,去数据集上训练自己的最后一层再去得到结果)
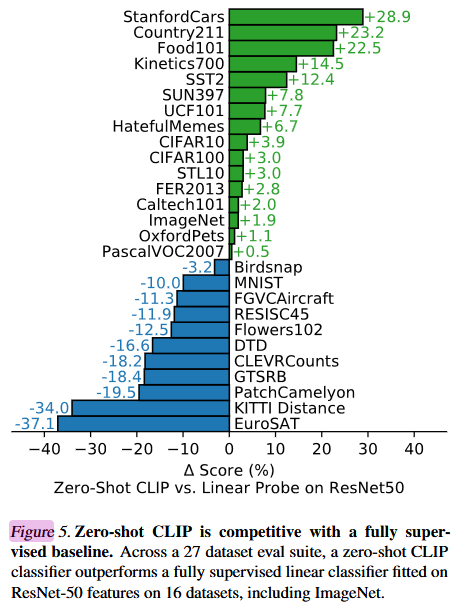
图 5. 零样本 CLIP 与完全监督的基线模型相比颇具竞争力。在由 27 个数据集组成的评估套件中,零样本 CLIP 分类器在 16 个数据集(包括 ImageNet)上的表现超过了基于 ResNet - 50 特征拟合的线性分类器。
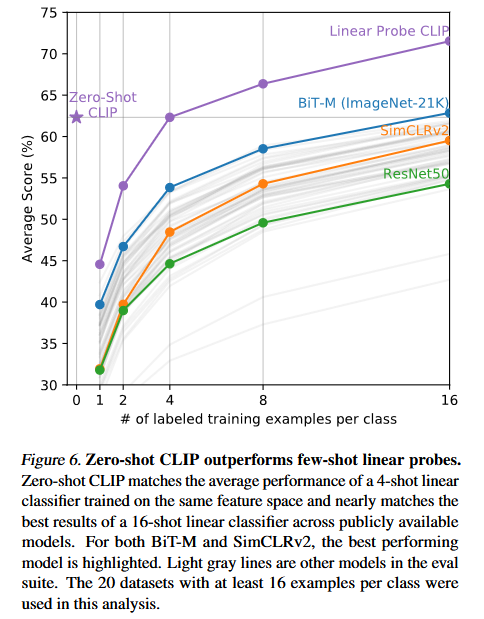
者对 zero-shot CLIP,few-shot CLIP 和之前 few-shot 的一些方法(预训练好冻结参数,然后做 linear probe,在下游任务数据集上进行训练)做了一些比较。这里 CLIP 的 few-shot 是将 Image Encoder 的参数冻结,然后做 linear probe。


3.2特征学习
这里作者讨论了下游任务用全部数据,CLIP 的效果会如何。
特征学习一般都是先预训练一个模型,然后在下游任务上用全部的数据做微调。这里在下游任务上用全部数据就可以和之前的特征学习方法做公平对比了。
衡量模型的性能最常见的两种方式就是通过 linear probe 或 fine-tune 后衡量其在各种数据集上的性能。linear probe 就是把预训练好的模型参数冻结,然后在上面训练一个分类头;fine-tune 就是把整个网络参数都放开,直接去做 end-to-end 的学习。fine-tune 一般是更灵活的,而且在下游数据集比较大时,fine-tune往往比 linear probe 的效果要好很多。
本文作者选用了 linear probe。
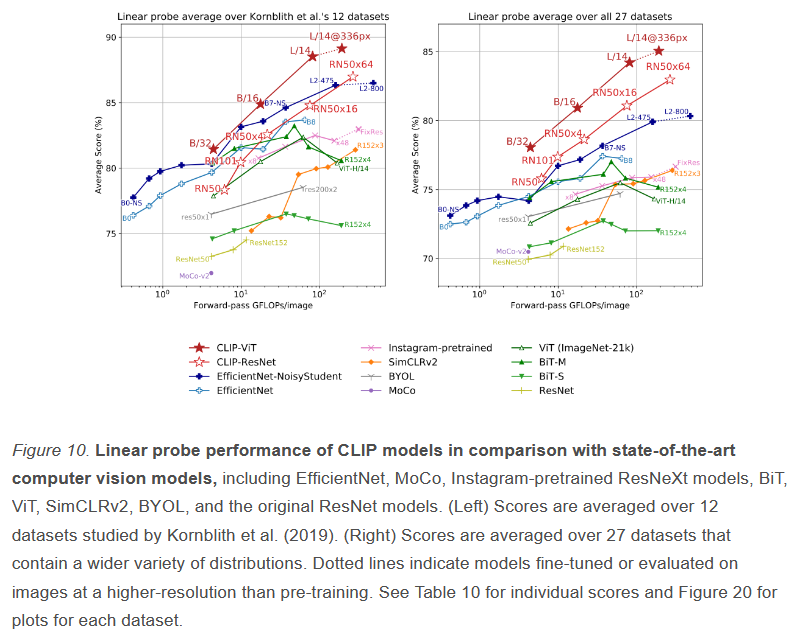
如 Figure 10 右图所示,是在先前提到的那 27 个数据集进行比较,CLIP(实心、空心红色五角星)比所有的其他模型都要好,不光是上文中讲过的 zero-shot 和 few-shot,现在用全部的数据去做训练时 CLIP 依然比其他模型强得多。
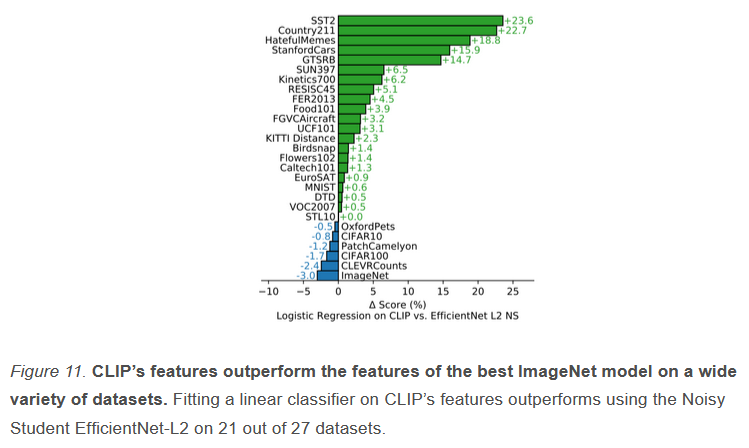
图 11. CLIP 的特征在多种数据集上优于最佳 ImageNet 模型的特征。
在 CLIP 的特征上拟合线性分类器,在 27 个数据集中的 21 个上,表现优于使用 Noisy Student EfficientNet - L2(模型) 。
随后作者又将 CLIP 与 之前在 ImageNet 上表现最好的模型 EfficientNet L2 NS(最大的 EfficientNet 并使用为标签的方式训练)进行对比。在 27 个数据集中,CLIP 在其中 21 个数据集都超过了 EfficientNet,而且很多数据集都是大比分超过,少部分数据集也仅仅是比 EfficientNet 稍低一点点。
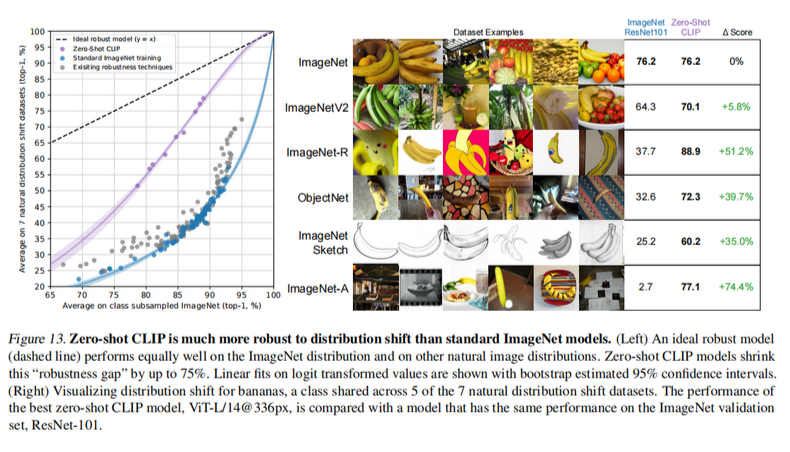
4与人类表现对比
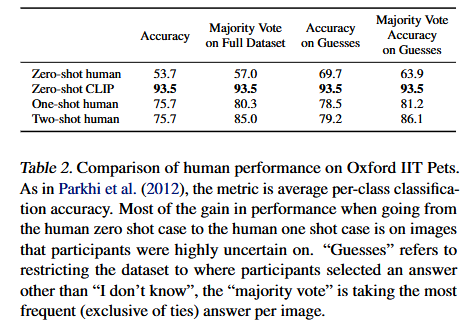
表 2. 人类在牛津大学互联网学院(Oxford IIT)宠物数据集上的表现对比
与帕克希(Parkhi)等人(2012 年)的研究一样,这里的评估指标是每类的平均分类准确率。人类从无样本到单样本时,表现提升的主要原因是排除了参与者非常不确定的图像。“猜测数据” 指的是将数据集限定为参与者选择了除 “我不知道” 以外答案的数据;“多数投票” 指的是选取出现频率最高(互斥)的标签作为预测图像的答案 。
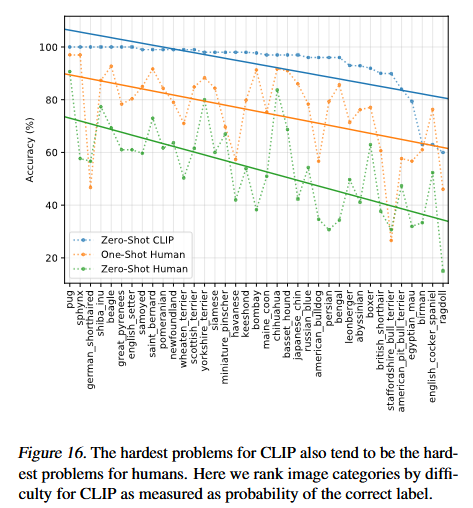
5 数据重叠分析
为了分析是否是因为本文使用的数据集与其他的数据集之间有重叠而导致模型的性能比较好,作者在这部分做了一些去重的实验,最后的结论还是 CLIP 本身的泛化性能比较好。
6 Limitations
(1) CLIP 在很多数据集上平均来看都能和普通的 baseline 模型(即在 ImageNet 训练的 ResNet50)打成平手,但是在大多数数据集上,ResNet50 并不是 SOTA,与最好的模型比还是有所差距的,CLIP 很强,但又不是特别强。实验表明,如果加大数据集,也加大模型的话,CLIP 的性能还能继续提高,但如果想把各个数据集上的 SOTA 的差距弥补上的话,作者预估还需要在现在训练 CLIP 的计算量的基础上的 1000 倍,这个硬件条件很难满足。如果想要 CLIP 在各个数据集上都达到 SOTA 的效果,必须要有新的方法在计算和数据的效率上有进一步的提高。
(2) zero-shot CLIP 在某些数据集上表现也并不好,在一些细分类任务上,CLIP 的性能低于 ResNet50。同时 CLIP 也无法处理抽象的概念,也无法做一些更难的任务(如统计某个物体的个数)。作者认为还有很多很多任务,CLIP 的 zero-shot 表现接近于瞎猜。
(3) CLIP 虽然泛化能力强,在许多自然图像上还是很稳健的,但是如果在做推理时,这个数据与训练的数据差别非常大,即 out-of-distribution,那么 CLIP 的泛化能力也很差。比如,CLIP 在 MNIST 的手写数字上只达到88%的准确率,一个简单的逻辑回归的 baseline 都能超过 zero-shot CLIP。 语义检索和近重复最近邻检索都验证了在我们的预训练数据集中几乎没有与MNIST数字相似的图像。 这表明CLIP在解决深度学习模型的脆弱泛化这一潜在问题上做得很少。 相反,CLIP 试图回避这个问题,并希望通过在如此庞大和多样的数据集上进行训练,使所有数据都能有效地分布在分布中。
(4) 虽然 CLIP 可以做 zero-shot 的分类任务,但它还是在你给定的这些类别中去做选择。这是一个很大的限制,与一个真正灵活的方法,如 image captioning,直接生成图像的标题,这样的话一切都是模型在处理。 不幸的是,作者发现 image captioning 的 baseline 的计算效率比 CLIP 低得多。一个值得尝试的简单想法是将对比目标函数和生成目标函数联合训练,希望将 CLIP 的高效性和 caption 模型的灵活性结合起来。
(5) CLIP 对数据的利用还不是很高效,如果能够减少数据用量是极好的。将CLIP与自监督(Data-Efficient Image Recognition with Contrastive Predictive Coding;Big Self-Supervised Models are Strong Semi-Supervised Learners)和自训练(Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Network;Self-training with Noisy Student improves ImageNet classification)方法相结合是一个有希望的方向,因为它们证明了比标准监督学习更能提高数据效率。
(6) 在研发 CLIP 的过程中为了做公平的比较,并得到一些回馈,往往是在整个测试的数据集上做测试,尝试了很多变体,调整了很多超参,才定下了这套网络结构和超参数。而在研发中,每次都是用 ImageNet 做指导,这已经无形之中带入了偏见,且不是真正的 zero-shot 的情况,此外也是不断用那 27 个数据集做测试。创建一个新的任务基准,明确用于评估广泛的 zero-shot 迁移能力,而不是重复使用现有的有监督的数据集,将有助于解决这些问题。
(7) 因为数据集都是从网上爬的,这些图片-文本对儿基本是没有经过清洗的,所以最后训练出的 CLIP 就很可能带有社会上的偏见,比如性别、肤色、宗教等等。
(8) 虽然我们一直强调,通过自然语言引导图像分类器是一种灵活和通用的接口,但它有自己的局限性。 许多复杂的任务和视觉概念可能很难仅仅通过文本来指导,即使用语言也无法描述。不可否认,实际的训练示例是有用的,但 CLIP 并没有直接优化 few-shot 的性能。 在作者的工作中,我们回到在CLIP特征上拟合线性分类器。 当从 zero-shot 转换到设置 few-shot 时,当 one-shot、two-shot、four-shot 时反而不如 zero-shot,不提供训练样本时反而比提供少量训练样本时查了,这与人类的表现明显不同,人类的表现显示了从 zero-shot 到 one-shot 大幅增加。今后需要开展工作,让 CLIP 既在 zero-shot 表现很好,也能在 few-shot 表现很好。
7 结论
作者的研究动机就是在 NLP 领域利用大规模数据去预训练模型,而且用这种跟下游任务无关的训练方式,NLP 那边取得了非常革命性的成功,比如 GPT-3。作者希望把 NLP 中的这种成功应用到其他领域,如视觉领域。作者发现在视觉中用了这一套思路之后确实效果也不错,并讨论了这一研究路线的社会影响力。在预训练时 CLIP 使用了对比学习,利用文本的提示去做 zero-shot 迁移学习。在大规模数据集和大模型的双向加持下,CLIP 的性能可以与特定任务的有监督训练出来的模型竞争,同时也有很大的改进空间。


















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









