







1.ResNet背景
2. ResNet论文
3. ResNet模型结构
4. ResNet优缺点
一、ResNet背景
ResNet 在2015 年由微软研究院提出的一种深度卷积神经网络结构,在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中取得了冠军(分类、目标检测、图像分割)。
ResNet论文是"Deep Residual Learning for Image Recognition",由Kaiming He、Xiangyu Zhang、Shaoqing Ren和Jian Sun于2016年发表在CVPR(Conference on Computer Vision and Pattern Recognition)会议上。
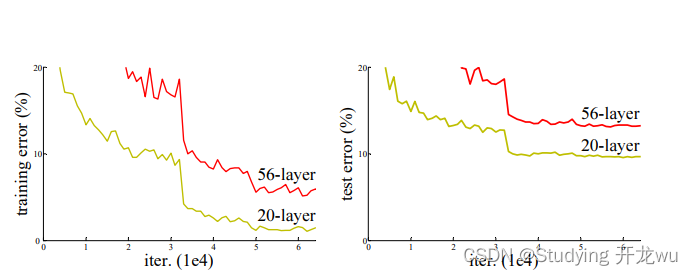
二、ResNet论文
1.Deep Residual Learning for Image Recognition
原论文https://arxiv.org/pdf/1512.03385.pdf
如果打不开私聊我
论文中介绍了ResNet的基本思想和网络结构。主要的创新是在网络中引入了残差模块(residual block),其中输入和输出之间添加了一个跳跃连接(skip connection),将输入直接加到输出上。这种跳跃连接的设计使得网络可以更轻松地学习残差,从而解决了梯度消失和模型退化的问题。论文还提出了不同深度的ResNet模型,包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152等。这些模型的深度和复杂度不断增加,但由于引入了残差学习,它们在准确性和性能方面都超过了传统的深层网络。论文通过在ImageNet数据集上进行了大量的实验证明了ResNet的有效性。在ImageNet图像分类任务上,ResNet相对于以往的方法取得了更低的错误率,并在ImageNet图像分类挑战赛中获得了显著的突破。
三、ResNet模型结构
1.结构
ResNet网络是参考了VGG19网络(最左边),在这基础上进行修改,并通过短路机制加入了残差单元,如下图。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图中最右边展示的34-layer的ResNet。
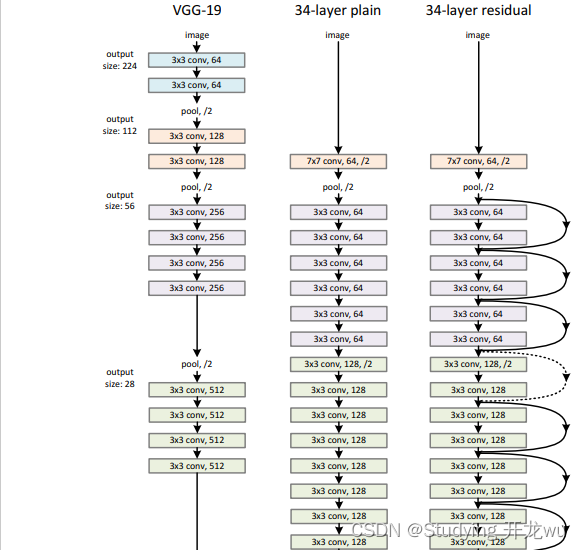
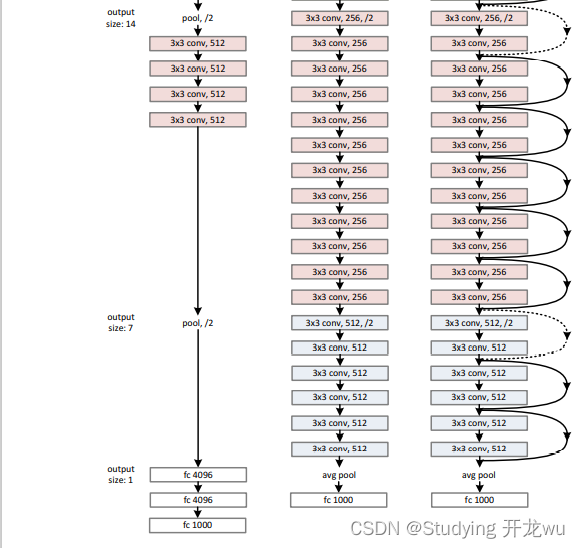

2.其他层网络结构
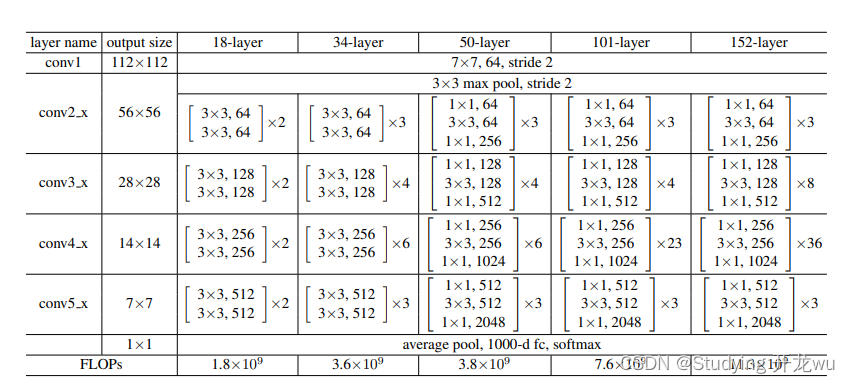
对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1。表中
18-layer
34-layer
50-layer
101-layer
152-layer
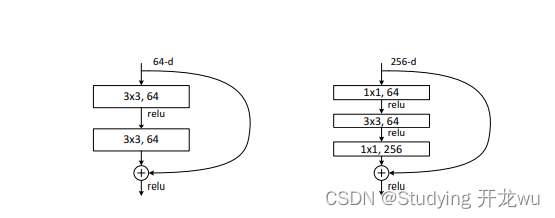
3.residual结构
左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。1*1的卷积核用来降维和升维。
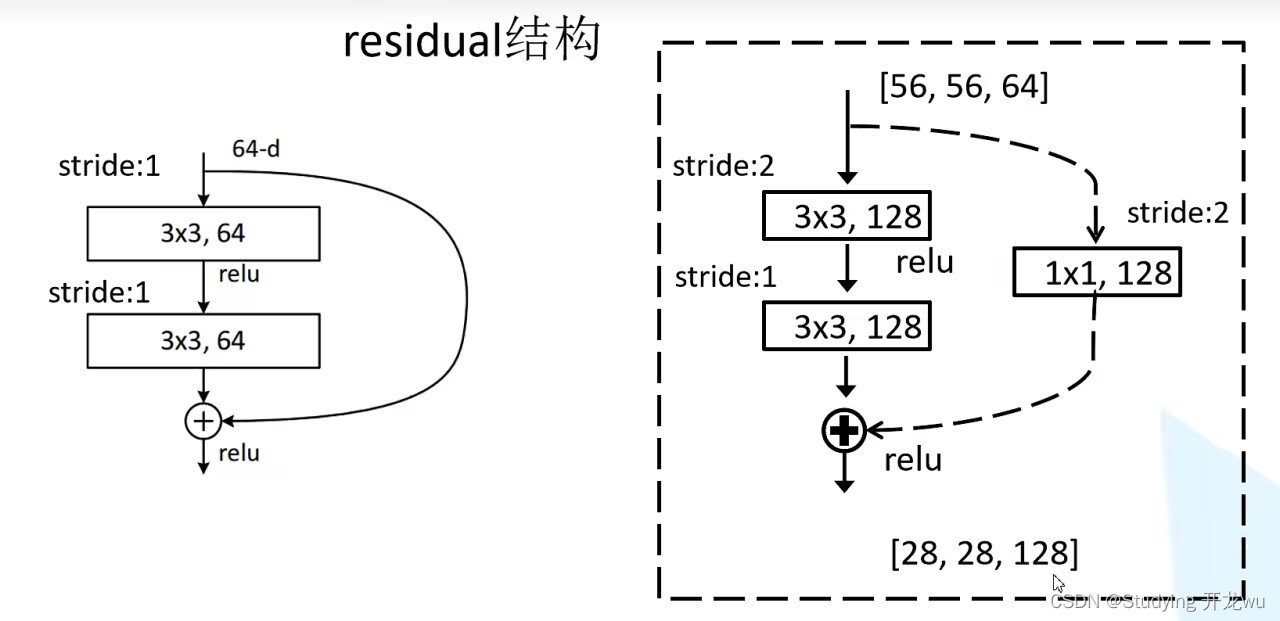
 网络结构中虚线部分:主分支与shortcut的输出特征矩阵shape必须相同
网络结构中虚线部分:主分支与shortcut的输出特征矩阵shape必须相同
因为 在conv3_x层,
输入特征矩阵的shape是【56,56,256】
输出特征矩阵的shape是【28,28,512】
因此在conv3、4、5_x层的第一层都要使用虚线结构,调整特征矩阵的深度、高、宽。其中在conv2_x层就没有!!!
4.Batch Normalization
在ResNet模型中,Batch Normalization(批标准化)被广泛应用于网络的每个残差块(residual block)。Batch Normalization的目的是在网络的每一层中对输入进行归一化处理,从而加速训练过程并提高模型的泛化能力。
在ResNet中,Batch Normalization通常在每个残差块的卷积层之后和非线性激活函数之前应用。具体来说,在每个残差块中,Batch Normalization的操作可以分为以下几个步骤:
(1)对每个小批量(batch)的输入数据进行归一化:对于残差块的输入数据,计算其特征维度上的均值和方差。
(2)应用归一化:将每个特征维度的值减去均值,然后除以方差,从而使特征值分布接近标准正态分布。
(3)伸缩和平移:为了保留网络的表示能力,Batch Normalization引入了可学习的伸缩因子和平移量,以便在归一化后的值上进行适当的缩放和平移。
Batch Normalization的作用是使网络的每一层的输入分布更稳定,有助于加速网络的收敛过程,并降低模型对初始参数的敏感性。它还可以缓解梯度消失问题,使得深层网络更容易训练。此外,Batch Normalization还具有一定的正则化效果,可以在一定程度上减少过拟合。
四、ResNet优缺点
1.优点:
(1)解决梯度消失和模型退化问题:ResNet通过引入残差学习和跳跃连接的概念,有效地解决了深层神经网络中的梯度消失和模型退化问题。这使得ResNet可以构建非常深的网络,具有更好的性能和学习能力。
(2)更容易训练:由于梯度可以通过跳跃连接直接传播,ResNet模型更容易训练。它允许使用更大的学习率,加快了收敛速度,并降低了过拟合的风险。
(3)强大的特征表示能力:ResNet的残差块允许网络学习残差变化,从而能够更好地捕捉和表示输入和输出之间的关系。这使得ResNet在图像分类、目标检测、语义分割等任务中具有强大的特征提取和表示能力。
(4)网络参数共享:ResNet中的跳跃连接使得前一层的特征可以直接传递给后续层,这种参数共享的机制使得网络更加高效。ResNet相对于其他深层网络模型来说,具有相对较少的参数量,可以更容易地部署在计算资源有限的设备上。
(5)可扩展性:ResNet的模型结构非常灵活和可扩展,可以通过增加残差块的深度和宽度来构建更深、更复杂的网络。这种可扩展性使得ResNet适用于各种计算机视觉任务,并且可以根据实际需求进行调整和扩展。
2.缺点:
(1)模型复杂性:由于ResNet模型的深度和复杂性较高,需要较多的计算资源和存储空间。尤其是较深的ResNet模型可能需要更长的训练时间和更高的显存需求,这对于一些资源受限的环境可能不太适用。
(2)训练数据要求:由于ResNet模型的深度,它对大量的训练数据的需求较高。当训练数据集较小或标注有限时,ResNet模型可能容易过拟合,导致性能下降。
(3)参数量较大:相对于一些轻量级的模型,ResNet模型的参数量较大。这导致了在资源受限的环境中,如移动设备或嵌入式系统中的部署变得困难。
(4)特征失真问题:由于ResNet模型中的跳跃连接,残差块中的输入会直接与输出相加。这种操作可能会导致特征的失真,特别是当输入和输出的尺寸不匹配时。为了解决这个问题,需要使用额外的卷积层或池化操作来调整特征的尺寸,增加了网络的复杂性。
(5)对于小规模数据集的泛化能力:ResNet模型在大规模数据集上表现出色,但在小规模数据集上的泛化能力可能会有所下降。这是因为ResNet的深度和复杂性使得模型对训练数据的依赖性增加,从而在小规模数据集上容易过拟合。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









