






摘要
本文提出了一种无监督的视觉跟踪方法。与现有的使用大量注释数据进行监督学习的方法不同,我们的CNN模型是以无监督的方式在大规模的无标记视频上进行训练的。我们的动机是,鲁棒跟踪器在正向和向后预测中都应该是有效的(即,跟踪器可以在连续的帧中向前定位目标对象,并回溯到其在第一帧中的初始位置)。我们在孪生网络相关滤波器网络上建立了我们的框架,它使用未标记的原始视频进行训练。同时,我们提出了一种多帧验证方法和成本敏感的损失,以促进无监督学习。在没有花哨功能的情况下,所提出的无监督跟踪器达到了完全监督跟踪器的基线精度,这在训练过程中需要完整和准确的标签。此外,无监督框架显示出利用未标记或弱标记数据来进一步提高跟踪精度的潜力。
1. Introduction
在本文中,我们提出通过无监督学习从头开始学习一个视觉跟踪模型。我们的直觉在于观察到视觉跟踪可以以向前和向后的方式进行。首先,给定在第一帧上标注的目标对象,我们可以在后续的帧中向前跟踪目标对象。当向后跟踪时,我们使用最后一帧中的预测位置作为初始目标注释,并向后跟踪到第一帧。通过向后跟踪在第一帧中估计的目标位置被期望与初始注释相同。在测量了前向和后向目标轨迹的差异后,我们的网络通过考虑轨迹的一致性1进行训练,如图1所示。通过利用未标记视频中的连续帧,我们的模型通过反复执行前向跟踪和向后验证来学习定位目标。
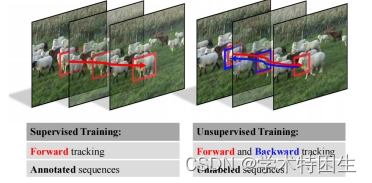
图1.有监督学习和无监督学习之间的比较。通过监督学习的视觉跟踪方法需要对训练视频的每一帧使用地面真实标签。利用前向跟踪和后向验证,我们训练了没有重量级注释的无监督跟踪器。
对于一个视频序列,我们在第一帧中随机初始化一个边界框,它可能不能覆盖整个对象。然后,该模型学习了在以下序列中跟踪边界盒区域。这种跟踪策略与基于部分的[30]或基于边缘的[28]跟踪方法相似,这些方法专注于跟踪目标对象的子区域。由于视觉对象跟踪器并不期望只专注于完整的对象,所以我们在训练过程中使用随机裁剪的边界框来跟踪初始化。
我们将所提出的无监督学习集成到基于孪生网络的相关过滤器框架[54]中。该网络在训练过程中包括两个步骤:前向跟踪和向后验证。我们注意到,反向验证并不总是有效的,因为跟踪器可能会成功地从一个偏转或错误的位置返回到初始目标位置。此外,诸如在未标记视频中的严重遮挡等挑战将进一步降低网络表示能力。为了解决这些问题,我们提出了多帧验证和成本敏感损失,以有利于无监督训练。多帧验证增加了正向和反向轨迹之间的差异,以减少验证失败。同时,成本敏感损失减轻了训练过程中有噪声样本的干扰。
总之,我们的工作的贡献是三方面的:
- 我们提出了一种基于孪生网络相关滤波器主干的无监督跟踪方法,该方法通过正向和向后跟踪学习。
- 我们提出了一种多帧验证方法和代价敏感损失来提高无监督学习性能。
- 在标准基准上进行的大量实验表明,所提出的方法具有良好的性能,并揭示了无监督学习在视觉跟踪中的潜力。
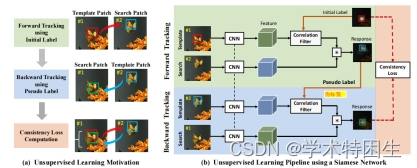
图2.无监督深度跟踪的概述。我们在(a)中展示了我们的动机,即我们通过前后跟踪来计算网络训练的一致性损失。详细的训练过程在(b)中,其中无监督学习集成到孪生网络相关滤波器网络。请注意,在在线跟踪过程中,我们只通过向前跟踪来预测目标位置。
3. Proposed Method
图2(a)显示了蝴蝶序列的一个例子来说明正向和反向跟踪。在实践中,我们在未标记的视频中随机绘制边界框来进行正向和反向跟踪。给定一个随机初始化的边界框标签,我们首先向前跟踪以预测它在后续帧中的位置。然后,我们反转序列,以最后一帧中预测的边界框作为伪标签向后跟踪。通过向后跟踪预测的边界框被期望与第一帧中的原始边界框相同。我们使用网络训练的一致性损失来测量正向轨迹和向后轨迹之间的差异。所提出的无监督孪生网络相关滤波器网络的概述如图2(b).所示在下面,我们首先重新访问基于相关滤波器的跟踪框架,然后说明我们的无监督深度跟踪方法的细节。
3.1. Revisiting Correlation Tracking
滤波器W可以通过求解岭回归问题来学习如下:
![]()
DCF可以通过来计算
![]()
搜索补丁Z相应的响应映射R可以在傅里叶域中计算出来:
![]()
3.2. Unsupervised Learning Prototype
给定两个连续的帧P1和P2,我们分别从它们中裁剪模板T和搜索补丁S。YT是模板补丁T的标签,相应的目标模板WT可以计算为:
![]()
从帧P2开始的搜索补丁S的响应图:

在生成P2帧的响应映射RS后,我们创建一个以其最大值为中心的伪高斯标签,用YS表示。在向后跟踪中,我们在搜索补丁和模板补丁之间切换角色。通过将S作为模板补丁,我们使用伪标签YS生成一个目标模板WS。生成第一帧响应图RT
因此,表示网络ϕθ(·)可以以无监督的方式进行训练,通过最小化重构误差如下:
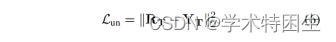
我们对计算出的损失进行反向传播来更新网络参数。在反向传播过程中,我们遵循孪生网络相关滤波方法[54,59]将网络更新为:
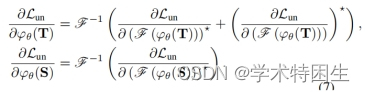
3.3.无监督的学习改进
所提出的无监督学习方法基于RT和YT之间的一致性构造目标函数。在实际应用中,跟踪器在前进跟踪中可能偏离目标,但在后退过程中仍返回到原始位置。然而,由于一致的预测,所提出的损失函数并不惩罚这种偏差。同时,原始视频可能包含无信息,甚至损坏的训练样本,遮挡恶化无监督学习过程。我们提出了多帧验证和成本敏感的损失来解决这些限制。
3.3.1 Multiple Frames Validation 多帧验证

图3.单帧验证和多帧验证。单帧验证中不准确的定位。通过包含更多的帧,如右侧所示,我们可以累积定位误差,以打破正向和反向跟踪过程中的预测一致性。
在实践中,我们使用三个帧来验证,改进的一致性损失被写为:
3.3.2 Cost-sensitive Loss成本敏感性损失

图5从ILSVRC 2015 中随机裁剪的中心补丁的例子。大多数补丁包含有价值的内容,而有些则没有那么有意义(例如,最后一行上的补丁)。
我们在第一帧P1中随机初始化一个边界框区域以进行前向跟踪。这个边界框区域可能包含有噪声的背景环境(例如,被遮挡的目标)。图5显示了这些区域的概述。为了减轻背景干扰,我们提出了一种代价敏感损失来排除噪声样本进行网络训练。在无监督学习过程中,我们从训练序列中构造多个训练对。每个训练对分别由帧P1中的一个初始模板补丁T和后续帧P2和P3中的两个搜索补丁S1和S2组成。这些训练对形成了一个训练批来训练孪生网络网络。在实践中,我们发现很少有极高损失的训练对会了网络训练的收敛。为了减少噪声对的贡献,我们排除了包含高损失值的整个训练对的10%。它们的损失可以用等式来计算 (8).为此,我们为每个训练对分配一个二进值Ai下降,所有的权值元素构成权值向量Adrop。其中10%的元素是0,其他的是1。除了有噪声的训练对外,原始视频还包括许多只包含背景或静止目标的无信息的图像补丁。对于这些补丁,物体(如天空、草或树)很难移动。直观地看,具有大运动的目标对网络训练的贡献更大。因此,我们为所有的训练对分配一个运动权值向量不运动。每个元素的Ai运动都可以通过计算
我们将运动权值和二值权值归一化如下:
其中,n是一个小批处理中的训练对的数量。小批量中的最终无监督损失计算为:

3.4. Unsupervised Training Details
网络结构:我们遵循DCFNet [54],使用一个只有两个卷积层的浅层孪生网络网络。这些卷积层的滤波器大小分别为3×3×3×32和3×3×32×32。此外,在卷积层的末端还采用了局部响应归一化(LRN)层。这种轻量级的结构支持非常高效的在线跟踪。

图4.训练样本生成的说明。该方法简单地对未标记视频中的中心区域进行裁剪并调整为训练补丁。
我们从一个视频中连续的10帧中随机选择3个裁剪补丁。我们将三个补丁中的一个设置为模板,其余的设置为搜索补丁。这是基于位于中心位置的目标对象不太可能在短时间内移出裁剪区域的假设。我们跟踪出现在裁剪区域中心的对象,而不指定它们的类别。图5中显示了一些裁剪区域的例子。
3.5. Online Object Tracking
我们在线更新了DCF参数如下:
其中,αt∈[0,1]为线性插值系数。目标尺度是通过一个具有尺度因子为=1.015,={−1,0,1}}的斑块金字塔来估计的。我们将所提出的无监督深度跟踪器表示为UDT,它只使用了标准的增量模型更新和规模估计。此外,我们使用了一个高级的模型更新,自适应地改变了αt,以及在[7]之后的一个更好的DCF公式。改进后的跟踪器记号为UDT+
4. Experiments
在本节中,我们首先分析了我们的无监督学习框架的有效性。然后,我们在标准基准上,包括OTB-2015 [57]、Temple-Color [29]和VOT-2016 [21],与最先进的跟踪器进行比较。
4.1. Experimental Details
在我们的实验中,我们使用了动量为0.9和权重衰减的随机梯度下降(SGD)用0.005来训练我们的模型。我们的无监督网络训练了50个周期周期,学习速率指数衰减从10−2到10−5,小批量大小为32。所有的实验都是在使用4.00 GHz Intel酷睿I7-4790K和NVIDIA GTX 1080Ti GPU的计算机上执行的。在OTB-2015年的[57]和TempleColor [29]数据集上,我们使用了具有20个像素的距离精度(DP)的一次通过评估(OPE)和重叠成功图的曲线下面积(AUC)。在VOT2016 [21]上,我们使用预期平均重叠(EAO)来衡量性能。
4.2. Ablation Study and Analysis
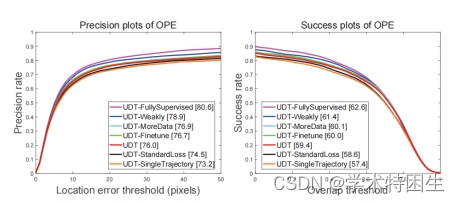
图6.我们在OTB-2015数据集[57]上使用不同配置的UDT跟踪器的精度和成功图。在图例中,我们显示了在20像素阈值下的距离精度和曲线下面积(AUC)评分。
定性评价
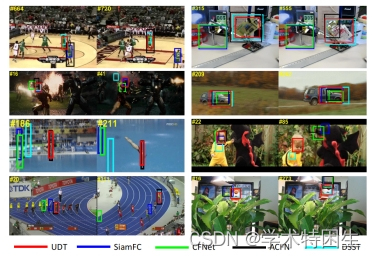
图10。对我们提出的UDT和其他跟踪器,包括SiamFC [1]、CFNet [49]、ACFN [6]和DSST [8],对来自OTB-2015的8个具有挑战性的视频进行了定性评估。从左到右,从上到下分别是篮球、板、铁人、秤、跳水、龙宝宝、螺栓和老虎
缺陷与不足(1)我们的无监督特征表示可能缺乏客观性信息来处理复杂的场景。(2)由于我们的方法同时涉及前向和向后跟踪,计算负载是另一个潜在的缺点。
5. Conclusion
在本文中,我们提出了如何在野外使用未标记的视频序列来训练视觉跟踪器,而这在视觉跟踪中很少被研究。通过设计一个无监督的孪生网络相关滤波器网络,我们验证了我们的基于前向后向的无监督训练管道的可行性和有效性。为了进一步促进无监督培训,我们扩展了我们的框架,以考虑多个框架,并采用了成本敏感的损失。大量的实验表明,所提出的无监督跟踪器,没有花里胡哨,作为一个坚实的基线,并取得了与经典的完全监督跟踪器相当的结果。最后,无监督框架在视觉跟踪方面显示出了有吸引力的潜力,如利用更多的未标记数据或弱标记数据来进一步提高跟踪精度。















 833
833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









