






Unsupervised Learning of Accurate Siamese Tracking
ULAST:准确孪生网络跟踪的无监督学习
摘要
无监督学习在各种计算机视觉任务中都很流行,包括视觉物体跟踪。然而,先前的无监督跟踪方法严重依赖于模板搜索对的空间监督,仍然不能在长时间跨度内跟踪具有强烈变化的对象。由于通过沿着一个时间循环跟踪一个视频可以获得无限的自我监督信号,我们研究了通过反向跟踪视频来演化一个孪生网络跟踪器。我们提出了一种新的无监督跟踪框架,在其中我们可以学习在分类分支和回归分支上的时间对应关系。具体地说,为了在前向传播过程中传播可靠的模板特征,使跟踪器能够在循环中进行训练,我们首先提出了一种一致性传播变换。然后,我们确定了反向传播过程中常规循环训练中的一个不适定惩罚问题。因此,提出了一种可微区域掩模来选择特征,并隐式地惩罚中间帧上的跟踪误差。此外,由于噪声标签可能会降低训练质量,我们提出了一种掩模引导的减重方法。
1. Introduction
视觉跟踪已经成为自动驾驶和视频识别等各种视频应用的重要组成部分。在视觉对象跟踪的主流中,基于深度学习的跟踪器是占主导地位的[28],需要大量的标签视频。由于标记的数据在实际场景中只占相对较小的比例,所以训练过的跟踪器不能可靠地跟踪以前看不见的物体。因此,从无标记的视频中学习成为一种很有前途的方法。先前关于无监督跟踪的工作可以分为两类:利用来自空间或时间维度的视频中的自我监督信号。对于第一类[24,33],重点是如何使用静态框架构建模板-搜索对。由于这些方法受到无法在长时间内学习时间对应关系的限制,训练过的跟踪器不能再跟踪具有强变化的对象。为了应对在线跟踪过程中出现的外观变化,我们将注意力集中在后一类方法上,利用视频中的时间自我监督信号。
在监督跟踪方法中,盒子回归分支已被证明是有效地捕获沿时间维[4,22]具有大尺度变化的对象。然而,在现有的无监督方法中,这个分支总是不存在的[33,34,38]。最近,USOT [47]引入了一个盒子回归头,但跟踪器最初是用单帧的模板搜索对进行训练,然后进行循环记忆训练,以增强分类关联分支的鲁棒性,而盒子回归分支是单独使用空间监督训练。在本文中,我们的目标是通过学习在分类分支和回归分支上的时间对应关系来训练一个更好的跟踪器,然而,我们发现有三个关键的挑战。
首先,尽管通过沿着一个时间周期跟踪视频可以获得无限的自我监督,但现有的方法对如何探索视频时间维度上的自我监督信号来训练具有盒估计分支的跟踪器还没有进行很好的探索。在循环训练中,如图1所示,假设跟踪器能够跟踪到初始位置。跟踪器是通过利用初始帧中开始和结束位置之间的不一致而在循环中演化的。然而,当从头开始训练时,跟踪器很难找到目标对象。在中间帧上生成的模板内核很可能不包含目标对象的任何特征,这意味着跟踪器不能返回到初始位置。训练管道将在几次迭代后崩溃。其次,我们在循环训练中识别偏差:当跟踪结果R2不准确时,生成的模板核T2可能包含许多干扰特征,但施加的损失仍然迫使跟踪器通过使用这样的噪声模板来预测准确的目标盒,从而导致不适定的惩罚。从循环训练的梯度流中,我们可以观察到类似RoI-Align的选择操作,由于坐标是量化的,在盒子坐标上是不可微的。因此,梯度不能反向传播到R2之前的节点。换句话说,中间帧上的跟踪错误不能在这个管道中受到惩罚。
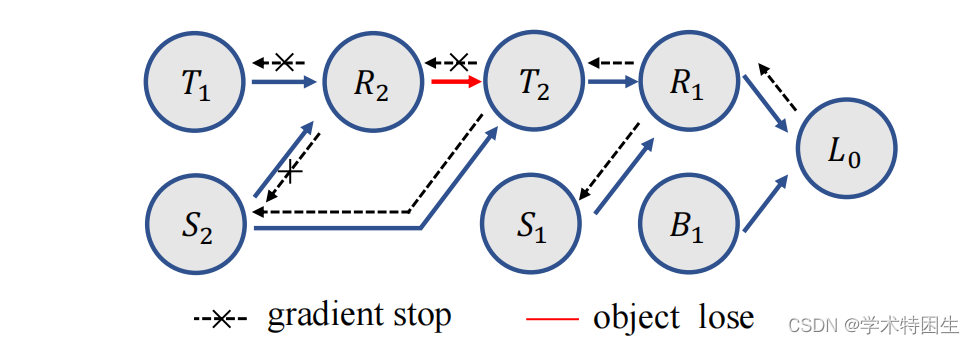
图1.在分类和回归分支上学习具有时间对应关系的更好跟踪器时存在三个挑战。首先,在前向传播过程中,跟踪器经常在中间帧中丢失目标对象,从而破坏了训练管道。其次,在反向传播过程中,由于RoI-Align,梯度不能流过整个框架。第三,伪标签往往是有噪声的,降低了性能。在这个图中,T、S、R、B、L分别表示模板核、搜索区域、候选框、伪标签和丢失值。下标索引了帧的时间顺序。
第三,由于无监督跟踪框架仍然依赖于初始帧中的伪标签,而盒回归分支训练需要具有清晰边缘的对象,因此初始帧中的伪标签是至关重要的。然而,我们观察到这些标签很可能会有噪声,从而降低跟踪性能。
为了解决上述三个挑战,我们提出了一种新的无监督跟踪框架,称为ULAST,它旨在学习分类分支和回归分支上的时间对应关系。它由三个新提出的组件组成:一致性传播转换、区域掩模操作和掩模引导的损失重新加权。具体来说,一致性传播转换的目的是生成可靠的模板核来跟踪下一帧,它使用来自模板核和前一帧搜索区域的长期和短期信息。因此,它使我们的框架能够利用时间的自我监督信号,避免训练管道崩溃。我们的区域掩码操作不使用RoI-Align,而是基于搜索区域特征和预测的边界框来选择R2中所有候选对象的特征,并使回归和分类头可微,从而隐式惩罚中间帧上的跟踪错误。掩模引导的损失重加权策略根据样本的伪标签的质量动态分配赋值,避免了使用有噪声的伪标签。
我们在5个不同的基准数据集上评估了训练过的跟踪器,与最先进的方法相比的良好性能证明了我们提出的框架的有效性。本工作的主要贡献总结如下:
- 我们提出了一种新的无监督学习框架,称为ULAST,它可以在分类和回归分支上精益时间对应。
- 提出了一种一致性传播转换来生成可靠的模板核,避免了ULAST框架的训练过程崩溃。
- 提出了一种可微区域掩模操作,以隐式惩罚反向传播过程中中间帧的跟踪误差。
- 提出了一种掩模引导的损失重加权策略,以减轻噪声对训练的负面影响。
2. Related work
强监督目视跟踪:在过去的几年中,基于深度学习的跟踪器的性能有了显著的提高。我们可以将这些跟踪器大致分为两类:在线优化的跟踪器[2,4-6]和离线跟踪器[3,9,10,21,41,43,46]。在线优化的跟踪器依赖于具有专门设计的在线更新方法。通过使用更新的模板核进行脊回归来确定目标对象的粗略位置。然后应用细化来估计精确的边界盒。另一方面,离线跟踪器学习在度量空间中匹配模板和搜索区域。这一类人主要由基于孪生网络的追踪器所主导。SiamFC [1]的开创性工作提取了具有共享主干网络的模板和搜索补丁的特征。然后利用互相关法生成定位目标的响应图。在这方面已经做出了各种努力,如更好的主干网络[21]、目标感知注意[23,43]、无锚定回归[10,46]和有效的模板搜索融合[13,45]。利用剪枝[11,12]和网络架构搜索[31],探索了基于孪生网络的跟踪器的高效跟踪[29,42]。然而,所有这些方法都需要大量的监督训练,包括大量的注释视频来学习模板和搜索区域之间的对应关系。相比之下,我们的工作是一个无监督的学习框架,用于精确的基于孪生网络的跟踪,这不需要巨大的注释成本。
无监督的视觉跟踪:由于为视频收集注释的成本很高,无监督跟踪[33,35,38,47]成为训练更鲁棒跟踪器的一种很有前途的方法。UDT的开创性工作[34]通过监督一致性损失的前向后跟踪帧训练了一个基于判别相关过滤器(DCF)的跟踪器。这些工作表明,视频的循环一致性可以有效地通过前向后跟踪多帧来训练鲁棒跟踪器。另一方面,s 2 siamfc [33]提出了一种基于孪生网络网络的无监督训练框架,通过在单帧中挖掘自监督,学习对抗性掩蔽,从身份框架中构建模板-搜索对。然而,这些方法的跟踪性能很大程度上依赖于在线更新方案。如果没有在线更新,这些无监督的训练跟踪器就无法处理具有显著变化的挑战性物体。近年来,从时空维度获取自监督信号成为一种很有前途的无监督跟踪方法。Zheng等人[47]提出了一种无监督的训练方法,在第一阶段从单帧开始进行朴素训练,然后采用周期训练在更长的时间跨度上进行学习。PUL [38]提出了一种通过对比学习来初始学习的背景识别模型。然后,该模型继续训练与时间相应的斑块挖掘与噪声鲁棒损失。此外,利用前向跟踪的思想,构建了学习视频视觉表示的各种借口任务[17,27,36]。与这些工作不同,我们的框架主要关注从时间监督同时学习分类和回归能力,获得优越的跟踪性能。
3. Proposed Method
3.1. Preliminary
基于孪生网络的跟踪器:为了处理目标在周期中的尺度变化,我们的ULAST建立在基于暹罗网络的区域建议网络[21]上。假设我们需要使用一个模板补丁来查找在搜索区域中的目标对象。跟踪器首先使用带有共享参数的ResNet50从模板和搜索区域中提取特征,我们将从模板和搜索区域补丁中提取的特征分别表示为T和S。然后,学习一个区域建议网络来生成边界框和相应的类。采用分类损失和回归损失进行优化:

其中L l cls和L l reg分别为焦点损失[25]和L1损失。λ1和λ2是平衡两项的系数,Ll的上标表示孪生配对训练范式[22]中的常规(传统)损失。
循环训练:假设我们用给定的第一帧的伪标签在一个周期中跟踪三个采样帧。在跟踪第二帧时,我们使用从第一帧的patch中提取的模板核来预测搜索区域上的候选框。然后利用这些框通过从搜索区域中选择特性来生成新的模板内核。在跟踪后续帧时,我们使用从最后一个搜索区域生成的模板内核来进行跟踪。一般来说,我们按回文顺序跟踪帧(即帧排序为1、2、3、2、1),以跟踪对象回到第一帧。跟踪器可以通过最终跟踪结果与第一帧伪标签不一致进行优化。形式上,我们称这种训练管道循环训练,而不是单帧的传统训练。循环训练中损失Lc的公式与传统训练相同,由焦点损失[25]和L1损失组成。因此,在循环训练中的总损失被表述为:
![]()
这里的Ll是自我跟踪的损失,从第一帧构建模板搜索对。周期损失Lc是通过跟踪到周期中的第一帧来计算的,λc是一个手动的权重参数。
3.2. Overview
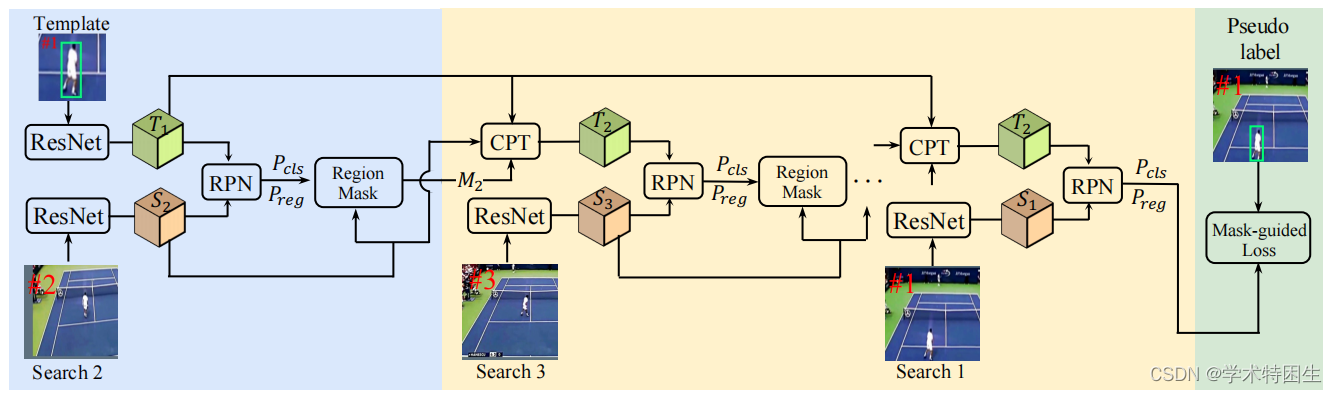
图2.框架概述。在这里演示了以1→2→3→2→1的顺序跟踪3帧的整体框架。
我们的框架的架构如图2所示,其中我们使用了三个稀疏采样的视频帧来进行说明。给定一个回文视频序列,我们首先使用一个共享的ResNet50作为骨干,从第一帧的模板中提取特征,从第二帧中提取搜索补丁,生成模板特征T1和搜索区域特征S2。然后,将提取的特征T1和S2输入区域建议网络(RPN)的回归分支和分类分支,得到盒形回归结果Preg和相应的分类置信度评分Pcls。然后,将Pcls和Preg传递到区域掩码操作,生成区域掩模M2。然后,我们的CPT模块以搜索特征S2和相应的区域掩模M2作为输入,生成第二帧T2的模板特征。同时,从第三帧开始生成搜索区域特征S3。然后将该搜索特征和模板特征T2输入RPN,以预测第三帧的盒子分类和回归结果。重复这个过程,最后在第一帧生成跟踪结果,然后用于计算基于第一帧处的伪标签的掩模引导损耗。
3.3. Training with cycle-consistency
区域掩码:如前所述,传统的循环训练会受到不利的惩罚。由于分类和回归分支的前n个预测结果在初始训练阶段可能不准确。基于这些前n个框生成的新模板特性可能不包含任何目标对象特性。迫使这样的模板跟踪到初始的目标位置会导致不适定的惩罚。而像RoI-Align这样的特征选择操作在盒子坐标上不可微的,导致中间帧跟踪错误不被惩罚。虽然可以使用精确的roi池化[18]使坐标可微,但它不能将梯度传递给所有的候选框。为了解决这些问题,有必要引入一个模块,它可以从涉及所有估计框的最后一个搜索区域中选择目标特征,并在坐标上进行可微分。
因此,我们提出了一种新的区域掩码操作来选择区域级特征,并使分类和回归分支在循环训练中可微。假设我们需要基于搜索区域特征St∈RC×H×W![]() 来计算区域掩模,这里下标t表示采样帧中的第t帧。区域掩码操作的输入是RPN的输出,RPN分别由来自分类和回归分支的输出Pcls和Preg组成。我们首先引入一个大小为H×W的网格,与搜索区域特征St的空间分辨率相同。在图3中,我们说明了当使用4×4大小的网格时的区域掩码操作。让我们假设在回归分支的输出中总共有K个估计框,第k个预测框的网格图记为Gk。表示第k个预测框为(x1、y1、x2、y2),位置(i、j)的网格框为(x ij 1、y ij 1、x ij 2、y2 ij)。网格映射Gk在第i行和第j列的网格值G(i,j)k可以计算如下:
来计算区域掩模,这里下标t表示采样帧中的第t帧。区域掩码操作的输入是RPN的输出,RPN分别由来自分类和回归分支的输出Pcls和Preg组成。我们首先引入一个大小为H×W的网格,与搜索区域特征St的空间分辨率相同。在图3中,我们说明了当使用4×4大小的网格时的区域掩码操作。让我们假设在回归分支的输出中总共有K个估计框,第k个预测框的网格图记为Gk。表示第k个预测框为(x1、y1、x2、y2),位置(i、j)的网格框为(x ij 1、y ij 1、x ij 2、y2 ij)。网格映射Gk在第i行和第j列的网格值G(i,j)k可以计算如下:
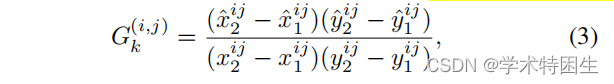
这里,网格值表示固定网格与预测框的重叠比。显然,这个公式在像IoU(联盟的交集)这样的坐标上是自然可微的。因此,这个搜索区域中所有盒子的网格图可以被收集到一个集合{Gk}中,对于k = 1,2,…由于RPN预测的每个边界框都有相应的置信度,因此可以直观地将这些网格图与它们的置信度结合起来。在获得网格映射集{Gk}后,我们将其聚合为一个单个通道的区域掩码。对于具有重复正网格值的相同空间网格,我们只使用置信度得分最高的第k个预测框中的网格值,并将另一个预测框中的网格值设为0。通过这种处理,我们生成了一个新的网格映射{Gk![]() },对于某个空间像素(i,j),在K个网格映射中,最多只有一个网格映射Gk
},对于某个空间像素(i,j),在K个网格映射中,最多只有一个网格映射Gk![]() 的网格值大于0。对于最终的聚合,搜索区域特征St的区域掩码可以计算如下:
的网格值大于0。对于最终的聚合,搜索区域特征St的区域掩码可以计算如下:
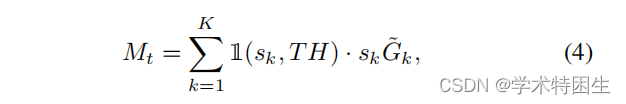
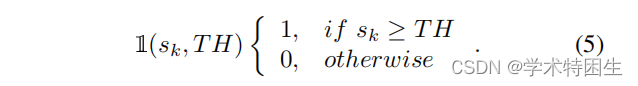
这里,Mt∈RH×W![]() 是生成的区域掩模。TH是一个手动设置的阈值。Sk表示第k个网格图的分类置信度得分。
是生成的区域掩模。TH是一个手动设置的阈值。Sk表示第k个网格图的分类置信度得分。
一致性传播转换(CPT):由于上述管道破坏的问题,确保帧之间的一致性传播至关重要,即跟踪器不应该丢失目标对象。在我们的框架中,我们认为造成这个问题的原因是在引入盒估计分支时缺乏对时间一致性的探索。后续帧的预测框将在很大程度上受到当前帧的影响。即,一旦当前帧中的预测框不准确,就很难在后续帧中生成准确的预测框。因此,我们提出了一个一致性传播变换(CPT)模块来利用时间维度上的自监督信号。具体来说,如图4所示,我们的CPT模块基于第t帧的预测结果,从带有区域掩码Mt的搜索区域特征St中检索一个新的模板核Tt。具体来说,为了压缩搜索区域特征St中的噪声特征,我们引入了一个长短期一致性模块来从中检索特征。由于初始模板特征T1包含了目标最可靠的特征,我们得到了以T1∈RC×W![]() 为条件的长期特征。首先,将区域掩模Mt∈RH×W
为条件的长期特征。首先,将区域掩模Mt∈RH×W![]() 与搜索特征St∈RC×H×W
与搜索特征St∈RC×H×W![]() 相乘,生成一个预先选择的搜索特征,表示为St
相乘,生成一个预先选择的搜索特征,表示为St![]() :
:
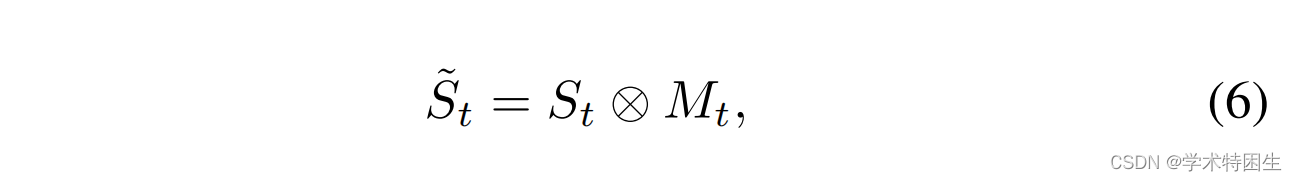
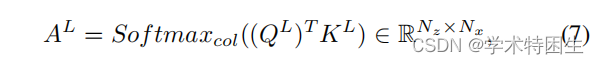
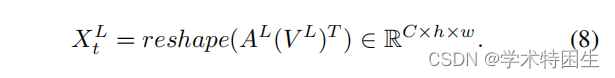
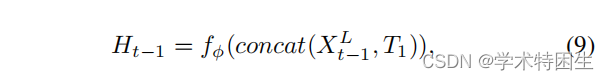
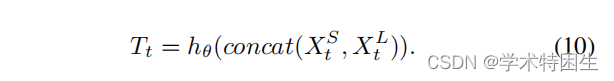
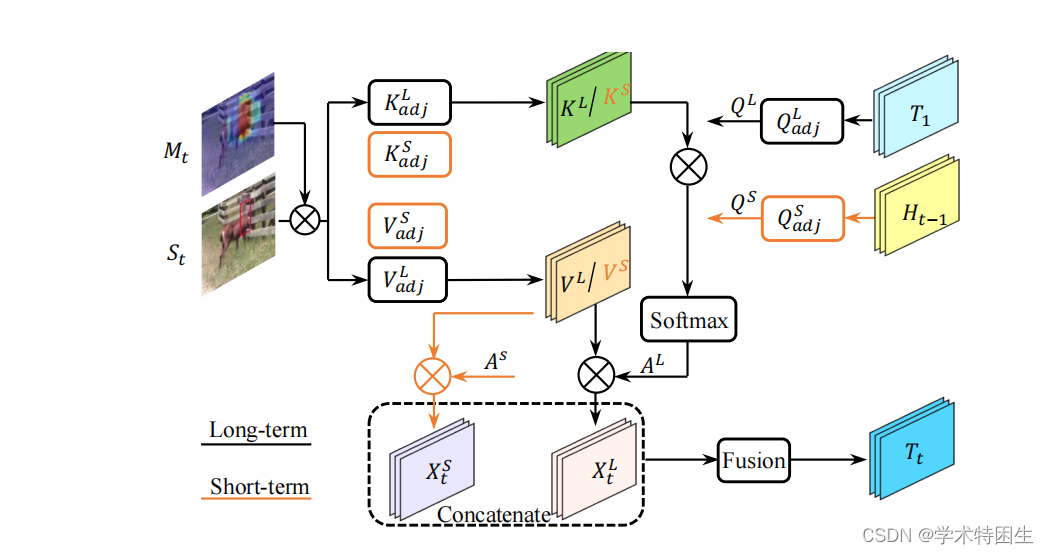
图4.一致性传播转换。在此转换中,我们通过检索长链项特征,从最后一个搜索区域生成可靠的模板核。黑线表示长期目标特征检索,橙色线表示短期目标特征检索。
3.4. Learn from noise label
在我们的ULAST中,我们使用无监督训练的光流模型[26]来生成第一帧的伪标签,这将在训练过程中使用。然而,这些伪标签往往是有噪声的,这阻碍了训练后的跟踪器的性能。现有的方法[33,38]只使用响应图中的分类置信度来过滤掉标签噪声。我们认为,分类结果不足以评估每个样本的重要性。因此,我们也考虑了回归结果。直观地看,由噪声较多的伪标签生成的模板核往往会在搜索区域中产生更大的背景响应区域,这可以从图5中识别出来。为此,我们提出了一种掩模引导的损失重加权策略,从各种质量的伪标签中重新加权损失。具体来说,假设我们有一个batch size 为B的视频。对于该批中的第B个样本,我们首先使用跟踪器从第一帧构建一个模板搜索对来生成分类输出Pcls和回归输出Preg。然后,基于Pcls和Preg,利用等式(3)(4)(5)得到区域掩模Mb![]() 。另一方面,给定伪标记的第一帧,我们也计算了Mb
。另一方面,给定伪标记的第一帧,我们也计算了Mb![]() ,唯一的区别是我们在等式中设置了K = 1和sk = 14,因为在这种情况下,第一帧只有一个真实框。然后,我们根据该配方中相对较高的响应区域,学习一个批次中每个样品的动态权重wb:
,唯一的区别是我们在等式中设置了K = 1和sk = 14,因为在这种情况下,第一帧只有一个真实框。然后,我们根据该配方中相对较高的响应区域,学习一个批次中每个样品的动态权重wb:
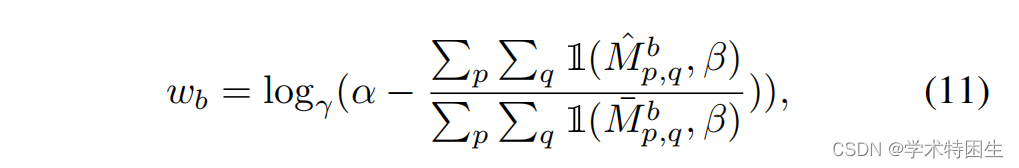
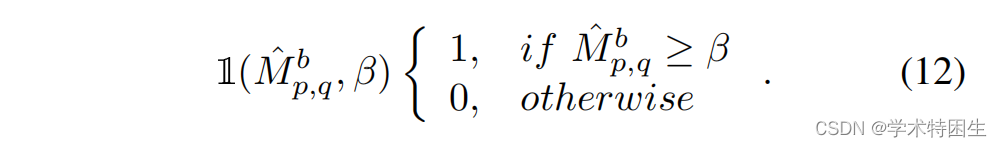
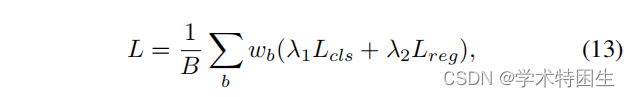
3.5. Online tracking
由于离线训练阶段都采用了传统训练和循环训练,因此RPN中模板核的输入与从补丁中提取出的模板特征或CPT模块从历史检索特征中检索到的特征是兼容的。对于实时跟踪,我们的跟踪器可以像SiamRPN [21]一样执行,以大约80帧/秒的高速运行。对于鲁棒跟踪,循环训练使跟踪器能够使用内存队列进行更新。详细地,保留一个长度为NL的存储队列和历史搜索特征和区域掩码,包括初始帧特征和得分最高的NL−1历史样本。更新内存队列后,内存内核将被更新。此外,隐藏模板Ht每更新一帧,得分最高。速度和准确性之间的权衡,分类地图Rcls传统内核和内存内核结合![]() ,λm表示权重平衡分类分数,而回归映射是由从初始模板补丁中提取的模板内核生成的。这里,R clsL
,λm表示权重平衡分类分数,而回归映射是由从初始模板补丁中提取的模板内核生成的。这里,R clsL![]() 表示应用从初始帧中提取的模板核的分类分支中的响应映射,而R clsM
表示应用从初始帧中提取的模板核的分类分支中的响应映射,而R clsM![]() 是应用从在线内存队列中提取的模板核时的分类响应映射。具体来说,我们在所有的在线更新实验中都设置了NL = 6和Ns = 10。
是应用从在线内存队列中提取的模板核时的分类响应映射。具体来说,我们在所有的在线更新实验中都设置了NL = 6和Ns = 10。
4. Experiments and Results
4.1. Implementation details
Data preparation:我们的训练标签是通过在数据集的Got10k[16]、LaSOT [8]、VID [32]和YoutubeVOS [40]上使用现成的无监督光流模型[26]生成的,数据采样策略类似于USOT [47]。从一个视频中采样一个可靠的模板帧和三个具有较大时间间隔的搜索区域帧进行周期训练。模板补丁被裁剪为大小为127×127,搜索帧被复制为回文,用于跟踪到初始帧。所有输入帧的空间大小被调整为640×480。具体来说,我们的框架只需要对象的初始框和后续的中心位置,从而减少了对伪标签的依赖。由于光流法难以处理目标对象的尺度变化,在循环训练中,根据输入对象中心和最后一帧估计的对象尺度,而不是用伪标签初始化的尺度,将搜索帧裁剪为255×255。
Network architecture: 我们的网络架构遵循了传统的孪生网络跟踪器。我们采用ResNet50作为特征提取器。来自第2、3、4层的特征被用作区域建议网络(RPN)的输入,这些特征被插值到相同的空间分辨率。此外,一个学习到的权重被用来聚合这三个相关图。搜索特征大小的空间分辨率为31×31,区域掩码操作中的网格大小与此相同。RPN的锚定尺度设置为8,锚定比设置为[0.33、0.5、1、2、3],ATSS [44]用于为前15位候选人分配锚定标签。在RPN的预测结果中有K = 3125个候选框。
Training details:损失的超参数设置为λ1 = 10、λ2 = 1.2、λc = 0.5。在区域掩模中,将TH设为0,以传递所有预测结果。在掩模引导的重加权策略中,我们将超参数设置为γ = 5、α = 7和β = 0.8smax,其中smax![]() 表示生成区域掩模时的最大分数。ResNet50的特征提取器通过图像预训练进行初始化。采用5个epoch的传统训练来初始化跟踪器,并能够定位目标对象的粗糙位置。然后采用1个模板帧和3个搜索帧的20个周期训练,使跟踪器在实际情况下跟踪变化较大的对象。在训练过程中,我们将批处理大小设置为8,并使用了一个SGD优化器。初始学习速率设为1e−3,在对数空间中逐渐衰减到5e−5。
表示生成区域掩模时的最大分数。ResNet50的特征提取器通过图像预训练进行初始化。采用5个epoch的传统训练来初始化跟踪器,并能够定位目标对象的粗糙位置。然后采用1个模板帧和3个搜索帧的20个周期训练,使跟踪器在实际情况下跟踪变化较大的对象。在训练过程中,我们将批处理大小设置为8,并使用了一个SGD优化器。初始学习速率设为1e−3,在对数空间中逐渐衰减到5e−5。
4.2. Comparison with SOTA
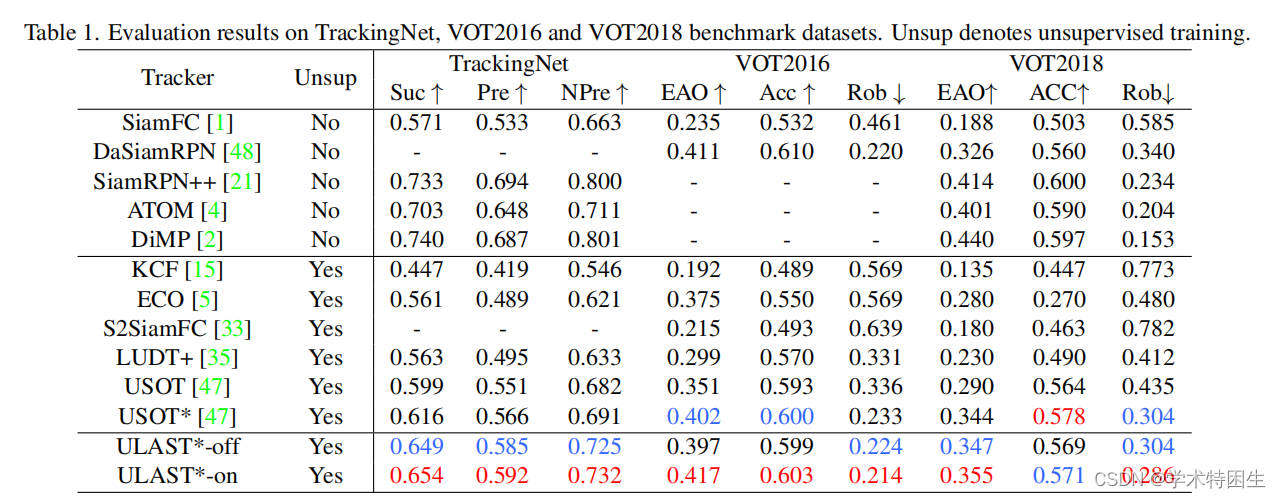
我们在5个具有挑战性的数据集上比较了我们提出的方法与无监督和有监督的方法,包括OTB2015 [39]、VOT2016 [19]、VOT2018 [20]、TrackingNet [30]和LaSOT [8]。离线跟踪模式表示为ULAST*-off,带有内存更新的在线跟踪模式表示为ULAST*-on。

4.3. Ablation Study and Algorithm Analysis
在本节中,我们进行了广泛的实验,并对我们所提出的方法进行了详细的分析。为简单起见,区域掩模、区域掩模(分离头)、精确RoI- pooling、掩模引导损失重加权、剩余连接分别简称为RM、RM (D)、PrPool、ReLoss和Res。此外,模型都是在LaSOT [8]和Got10k [16]数据集上进行训练的,每个epoch的迭代次数是完整版本的一半。
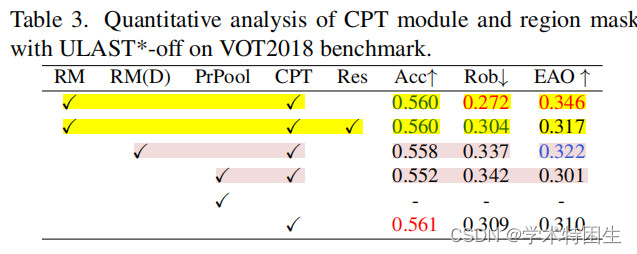
一致性传播转换(CPT):为了评估CPT模块的贡献,我们进行了三个实验。值得注意的是,该模块的输出不包含基于注意的操作中的常见残余连接。该设计的动机是利用目标对象丰富的时间特征,减少对初始模板特征的依赖。为了验证这一点,我们在CPT模块中添加初始模板特征,在输出中进行了一个使用剩余连接训练的实验。结果如表3所示,在此残差连接下,EAO评分从0.346下降到0.317,说明涉及初始模板会导致性能下降。此外,我们单独去除区域掩模来评估CPT模块,EAO评分下降到0.310,但与单帧训练的跟踪器(见表4,EAO=0.296)相比,即仅进行空间自我监督,该模型的性能仍提高了1.4 EAO。此外,我们尝试用PrPool替换CPT模块。如上所述,对于tra的错误预测结果,训练管道容易发生分解(梯度爆炸)。
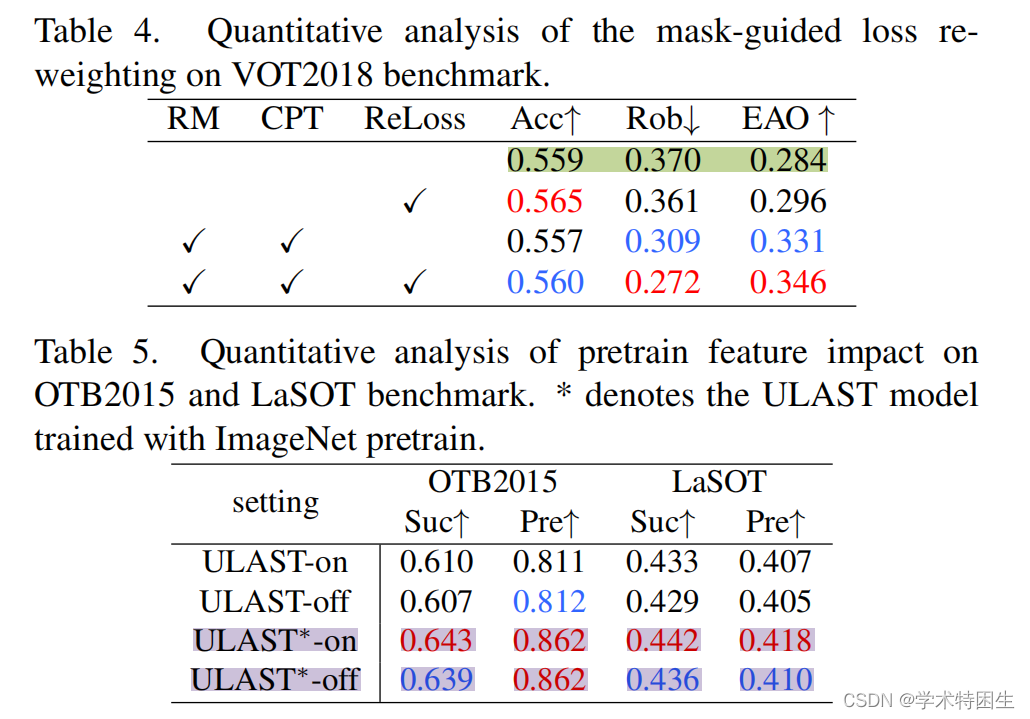
区域掩码:为了更好地理解所提出的区域掩模,在这里我们进行了两个实验。首先,用精确RoI-pooling [18]代替区域掩码操作,从最后一帧中选择特征。在非最大抑制后,我们从前3个得分的预测框中汇集候选特征。然后通过平均融合合并的特征,如表3所示,EAO得分下降到0.301。其次,在生成区域掩码时,我们分离了搜索区域上的候选框的梯度。在这种形式下,区域掩模失去了隐式惩罚中间跟踪错误的能力。如表3所示的RM (D)选项,EAO评分从0.346下降到0.322。
掩膜引导样本重新加权:在这里,我们进行了循环训练和传统训练(通过单帧的模板-搜索对进行训练)的实验,以验证该策略的有效性。如表4所示,在该策略下,EAO的性能都有所提高:循环训练和传统训练分别从0.331到0.346和0.284到0.296。
ImageNet预训练的影响:为了与现有的无监督跟踪工作进行公平的比较,在这里我们从头开始训练我们的跟踪器。详细地说,我们将在ImageNet分类上预训练的ResNet50 [14]作为DenseCL [37]预训练,这是通过对比学习的自我监督训练。然后在OTB2015和LaSOT基准数据集上对训练后的模型进行评估,并进行比较,结果如表5所示。与ULAST*模型相比,ULAST-on和ULAST-off的性能相对略有下降。这表明,一个更好的表示可以有助于无监督的视觉跟踪。
5. Conclusion
在本文中,我们提出了一种新的无监督跟踪框架,称为ULAST。为了在正向传播过程中生成可靠的模板核,从而使我们的框架能够进行周期一致性训练,我们首先提出了一个一致性变换。在反向传播过程中,我们提出了一种区域掩码操作来隐式地惩罚中间帧上的跟踪误差。此外,还提出了一种掩模引导的损失重加权策略,对各种伪标签质量样本的损失分配动态权重。有了这些提出的组件,我们的ULAST可以充分探索无监督跟踪过程中的时间监督,并达到最先进的性能。
6. Discussion and limitations
尽管所提出的框架可以有效地从时间自监督中学习一个更好的跟踪器,但该管道仍然依赖于由无监督光流模型生成的初始帧中的伪标签。由于更好的初始化方法和更好的跟踪器之间的关系是这个公式中的一个难题,因此如何将初始化方法和无监督跟踪链接到端到端可训练的管道中仍然是一个剩余的问题。
7. Quantitative analysis of misalignments
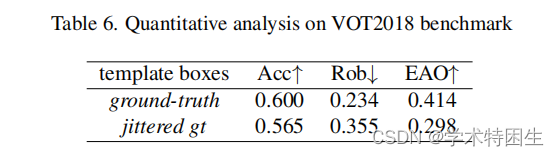
在此,我们对无监督视觉跟踪的常规循环训练中的错位问题进行了定量分析。在我们的手稿中,我们声称在循环训练中的失调严重阻碍了无监督视觉跟踪的表现。具体地说,这种错位的来源是内部模板和搜索区域特征之间的不匹配。为了深入研究这一点,我们对这种错位的影响进行了定量分析。我们选择经典的孪生网络跟踪器,SiamRPN++ [21],作为基线。为了简化,将SiamRPN++ [21]中裁剪模板补丁的噪声模拟为噪声,即可能由前向跟踪误差或初始化偏差产生的中间帧不匹配。具体来说,我们通过以下操作在模板补丁中添加噪声。让我们将模板框架中的地面真实框表示为(cx,cy,w,h),其中(cx,cy)在边界框的中心坐标中,w和h分别为框的宽度和高度。抖动的模板边界框可以表示为(cx+σ1w,cy+σ2h,(1+σ3)w,(1+σ4)h),其中σk表示由均匀分布生成的−0.5和0.5之间的随机数。在训练阶段,用有噪声的模板箱训练的模型在回归分支上难以收敛。我们评估了VOT2018 [20]基准数据集上的跟踪性能,如表6所示,当模板盒抖动时,跟踪器的性能将下降,EAO度量将有很大的差距。
8. More discussion about proposed component
8.1. Threshold in region mask
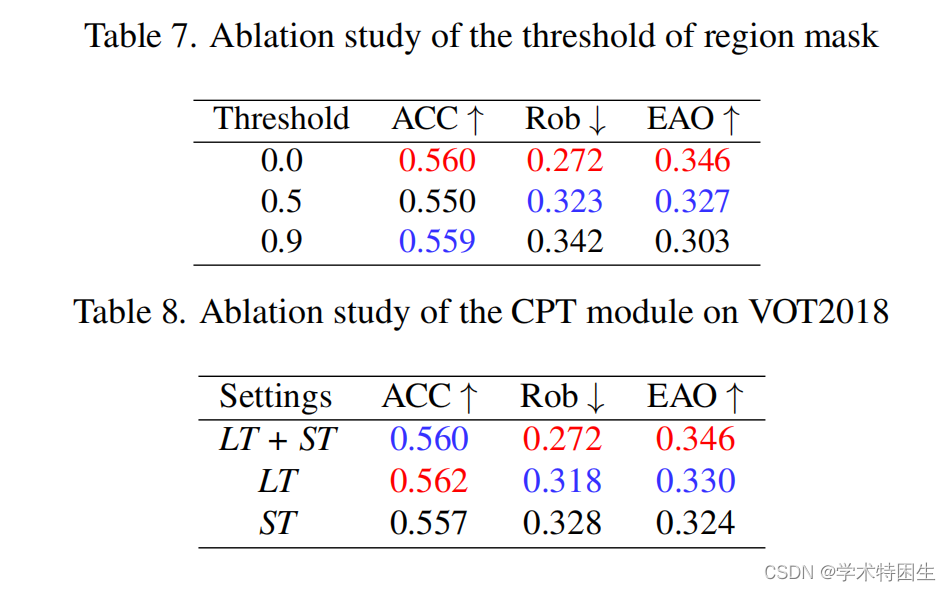
我们提出的区域掩模是一种针对循环训练中的无监督视觉跟踪的定制操作,它通过使坐标可微来惩罚中间帧上的跟踪误差。正如我们在我们的手稿中所声称的那样,与PrPool [18]等传统的特征选择操作相比,该操作基于区域建议网络(RPN)的输出从最后一个搜索区域特征中选择特征,表示为Pcls和Preg。具体来说,我们将盒子号设置为3125(25×25×5),与RPN的预测盒子总数相同。将通过所有预测方框的正阈值(在手稿中表示为TH)设置为0。此外,我们还可视化了具有不同正阈值的训练样本中的区域掩模传播。具有四种不同阈值的搜索区域图像上的区域掩码如图7所示。当这个阈值的值增加时,区域掩模往往会过滤掉更多置信分数较低的预测框,这导致在帧之间传播的信息更少。基于这一观察结果,我们总是在训练阶段设置T H = 0,以便在帧之间传播更多的信息。此外,当置信度得分最高的提案框出现错误时,正阈值较低的区域掩模更有可能选择正确的提案框。
为了更好地理解,我们在训练阶段对这个阈值TH进行了定量分析。如表7所示的其他阈值的消融研究,随着阈值的增加,EAO评分的EAO评分显著下降。在生成区域掩模时,每个区域图都与其信任分数相乘,因此置信度较低的样本基本上具有较小的梯度。然而,考虑到所有的盒子(包括大量的非目标区域)基本上积累了大量的训练样本。另一方面,这种噪声区域掩模强制跟踪器学习更好的辨别能力,即预测前景(目标)区域的置信度得分较高,而背景区域的得分较低。在在线跟踪阶段,我们将高置信度的搜索区域特征和相应的区域掩码隐藏在内存队列中进行更新。当使用CPT模块检索内存内核时,我们设置了一个更高的阈值来过滤类似的干扰物特征。
8.2. Long/short term in CPT module
为了进行具有周期一致性的训练,需要将视频帧作为一个周期进行跟踪。如果这个排名前1位的建议是错误的,特别是在初始阶段,那么生成的模板内核将变得噪声太大,跟踪器无法返回跟踪。利用所提出的CPT模块,可以使用多个可能的匹配区域在帧之间生成可靠的模板特征。这里我们可视化注意力地图在搜索区域长期和短期查询图6,长期(LT)查询有更高的响应不变区域的目标,而短期(ST)查询不同的目标区域有更高的响应,因为他们旨在检索最近的目标特性。此外,我们还对CPT模块的长期/短期查询进行了消融研究,如表8所示。它表明,长期查询和短期查询的组合在EAO分数上比使用单项查询表现得更好。

图6.LT和ST查询的注意图的可视化















 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









