






ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
任务:3D Classification、zero-shot 3D Classification、3D captioning
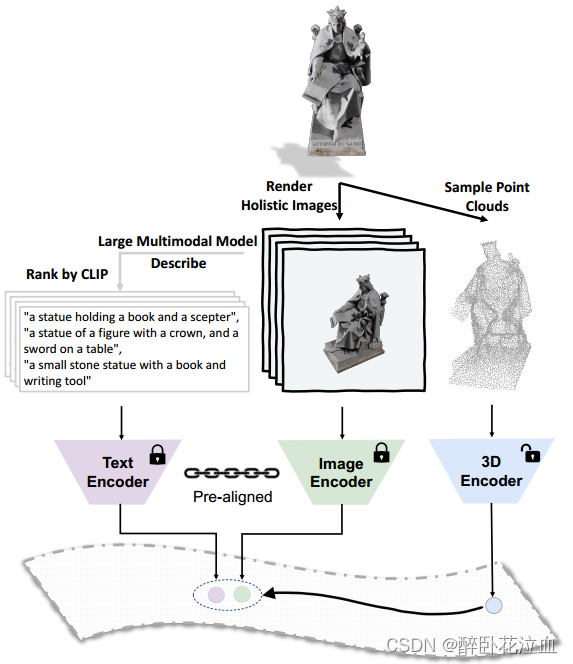
动机:最近的研究表明,通过在3D形状、其对应的2D形状和语言描述之间对齐多模态特征,在3D表示学习中展现出有希望的效果。然而现有的管理多模态数据的方法,特别是对于3D形状的语言描述是非常少的,并且收集的语言描述没有多样性。现有的框架倾向于使用手工标注的类别名称和来自元数据的简短描述。为了解决这个问题,我们引入了ULIP-2,这是一个简单而有效的三模态预训练框架,它利用大型多模态模型自动生成3D形状的整体语言描述(只需要将3D数据作为输入,消除了任何手动注释的需要,因此可以扩展到大型数据集)。
然而,获取和利用三维模态语言数据的最佳途径尚不清楚。尽管训练有素的人类注释者可能会提供3D对象的详细语言描述,但这种方法既昂贵又缺乏可扩展性。此外,为3D形状确定适当的语言对应模态并不是一项简单的任务。为了解决这个问题,我们可以想一想:如果我们可以从任何视点渲染3D形状的2D图像,那么所有这些渲染图像的集合应该近似地包括有关该3D形状的所有信息,从而形成适合3D的图像对应模态。如果我们可以从任何角度对一个三维形状进行语言描述,那么从各个角度对所有这些语言描述的汇编也应该大致包含关于该形状的所有语言可表达的信息,从而形成适合该三维形状的语言形态。在实践中,为了提高效率,我们可以选取有限固定的一组整体视点,而不是“任何视点”。
贡献:具有可扩展性,只要有3D数据就可以进行输入,可以扩展到更大的数据集,甚至是不需要标注的数据集(克服了ULIP需要人工标注的缺点,消除了人工注释的需要)。
编码器以及描述文本生成:在ULIP-2中,我们利用Point-BERT和PointNeXt作为我们的3D编码器。BLIP-2作为文本-图像大模型来生成对图像的描述。文本编码器和图像编码器基于OpenCLIP(ViT-G/14)。
一、方法
ULIP-2吸收了ULIP的预训练框架,并引入了一个可扩展和全面的多模态三元组创建范式,不仅消除了对人工注释的需要,而且显著提高了学习到的多模态3D表示。通过将ULIP高效的多模态预训练与这种可扩展的三元组创建方法相结合,ULIP-2为大规模预训练铺平了道路,这种预训练基本上是以一种伪自我监督的方式进行的。
Scalable Triplet Creation:对于每个角度的图像,都会生成一组详细的描述。我们采用CLIP Score来对这文本进行排序,并选择top-1作为三元组中的语言模态。
Tri-modal Pre-training: 在该阶段,给定一个3D形状𝜪,提取其3D点云P,采样其2D渲染图像I,BLIP-2生成图像I的语言描述T。然后,我们基于OpenCLIP中预对齐和冻结的图像编码器和文本编码器提取图像特征f𝐼和文本特征f𝑇。然后我们训练一个3D点云编码器,使其3D特征与图像和文本特征对齐。
我们使用与CLIP类似的对比损失对齐点云-图像。
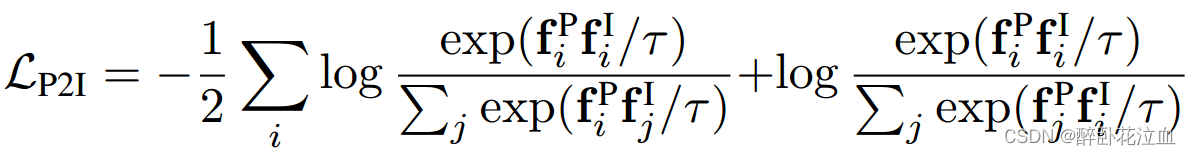
其中,I,j是采样出来的,τ是一个可学习的温度参数。第一项表示来自同一样本的三维特征与图像特征的点积在图像特征来自不同样本的其他产品中要突出。同样,第二项表示同一样本的三维特征与图像特征的点积在3D特征来自不同样本的其他产品中要突出。
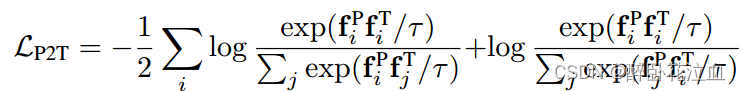
我们的目标是训练3D编码器,使上述两种对比对齐损失的总和最小化。















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









