






ULIP: Learning a Unified Representation of Language,Images,and Point Clouds for 3D Understanding(2022.12)
任务:3D Classification、zero-shot 3D Classification、2D-to-3D retrieval
模型预训练可以潜在地减少下游任务微调期间对标记数据的需求
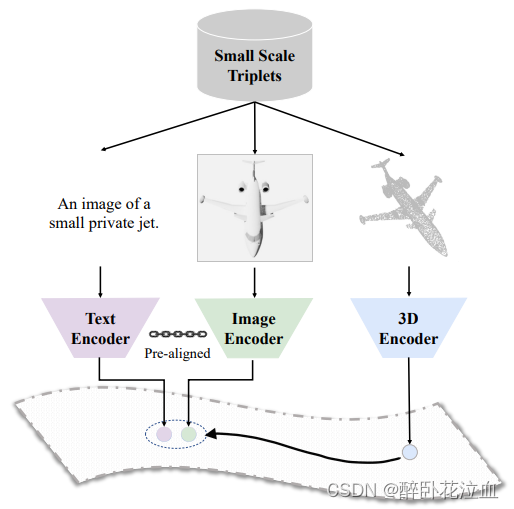
动机:当前3D视觉识别研究任务仍然受到标注数据少和预先确定类别较少的数据集的限制(a small number of annotated data and a pre-defined set of categories)。受到2D领域的启发,通过语言或其他形式的模态信息可以显著缓解类似的问题。因此,利用多模态的信息,可以有效的帮助并提高对3D的理解。因此,我们引入ULIP来学习图像、文本和3D点云的统一表征,方法是通过使用来自三种模态的对象三元组(object triplets)进行预训练。为了克服三元组的缺少/少量,ULIP利用一个预先训练好的视觉-语言模型(由于三元组数据的缺乏,我们利用了大量图像文本对上预训练的视觉语言模型--CLIP),该模型已经通过大量图像-文本对的训练学习了一个公共的视觉、语言空间。然后ULIP利用少量的自动合成的三元组数据(ShapeNet55,无需手动注释)来实现三者在空间上的对齐。在预训练期间,我们将CLIP模型冻结,并通过对比学习将对象的3D特征与其相应的文本-视觉特征进行对齐,以此来训练3D编码器。预训练的3D backbone可以进一步微调不同的下游任务。
ULIP is agnostic to 3D backbone networks and caneasily be integrated into any 3D architecture.
现在的方法:CLIP通过对大规模图像-文本对进行预训练,开创了视觉和文本特征对齐的先路。它提高了最先进的视觉概念识别,并实现了对看不见的物体的零射击分类。然而,涉及到3D模态的多模态学习,以及它是否能够帮助3D识别任务,目前还没有得到很好的研究。
缺点:可扩展性不足,仍然需要人工标注,所以后续提出了ULIP2。
一、三元组的组成与获取
ShapeNet55是ShapeNet的公开子集,它包含大约52.5K个CAD模型,每个模型都与元数据相关联,元数据在文本上描述了CAD模型的语义信息。对于数据集中的每个CAD模型i,我们创建了一个三元组𝑻𝒊:𝑰𝒊,𝑺𝒊,𝑷𝒊,其中𝑰𝒊表示图像,𝑺𝒊表示文本,𝑷𝒊表示点云。
点云生成:直接使用ShapeNet55中每个CAD模型生成的点云。然后进行下采样以及一系列数据增强得到𝑃𝑖。然后将𝑷𝒊输入进点云编码器中,输出其3D特征h𝑖𝑃。
多视角图像渲染:ShapeNet55 CAD模型不附带图像。为了获得与每个CAD模型语义一致的图像,我们在每个对象周围放置虚拟摄像机,并从每个视点绘制相应的RGB图像和深度图,从而合成每个CAD模型的多视图图像。每12度渲染一个RGB图像和深度图,总共获得30个RGB图像和深度图,总共60个图像候选(image candidate)。在预训练中,每次从CAD模型的60个图像候选中随机选择一张图像作为𝑰𝒊,并将𝑰𝒊作为图像编码器的输入,提取图像特征h𝑖𝐼。
文本生成:我们利用每个CAD模型附带的元数据作为相应的文本描述。对于元数据中的每个单词,我们采用简单的prompts来构建有意义的句子,这些句子将在预训练中使用。我们遵循先前的工作,在图像-文本预训练任务中使用63个提示,如“a picture of [WOED]”,并额外添加一个专用提示“a point cloud model of [WORD]”以适应3D模态(63+1)。在每次训练迭代中,我们从元数据中随机选择一个单词,并对该单词利用64个模板来构建一组文本描述,𝑺𝒊。然后将𝑆𝑖输入到文本编码器中,分别得到一组文本表示(输出集)。最后,我们对输出集进行平均池化,作为对象i 的文本特征h𝑖𝑆。
二、三种模态的对齐
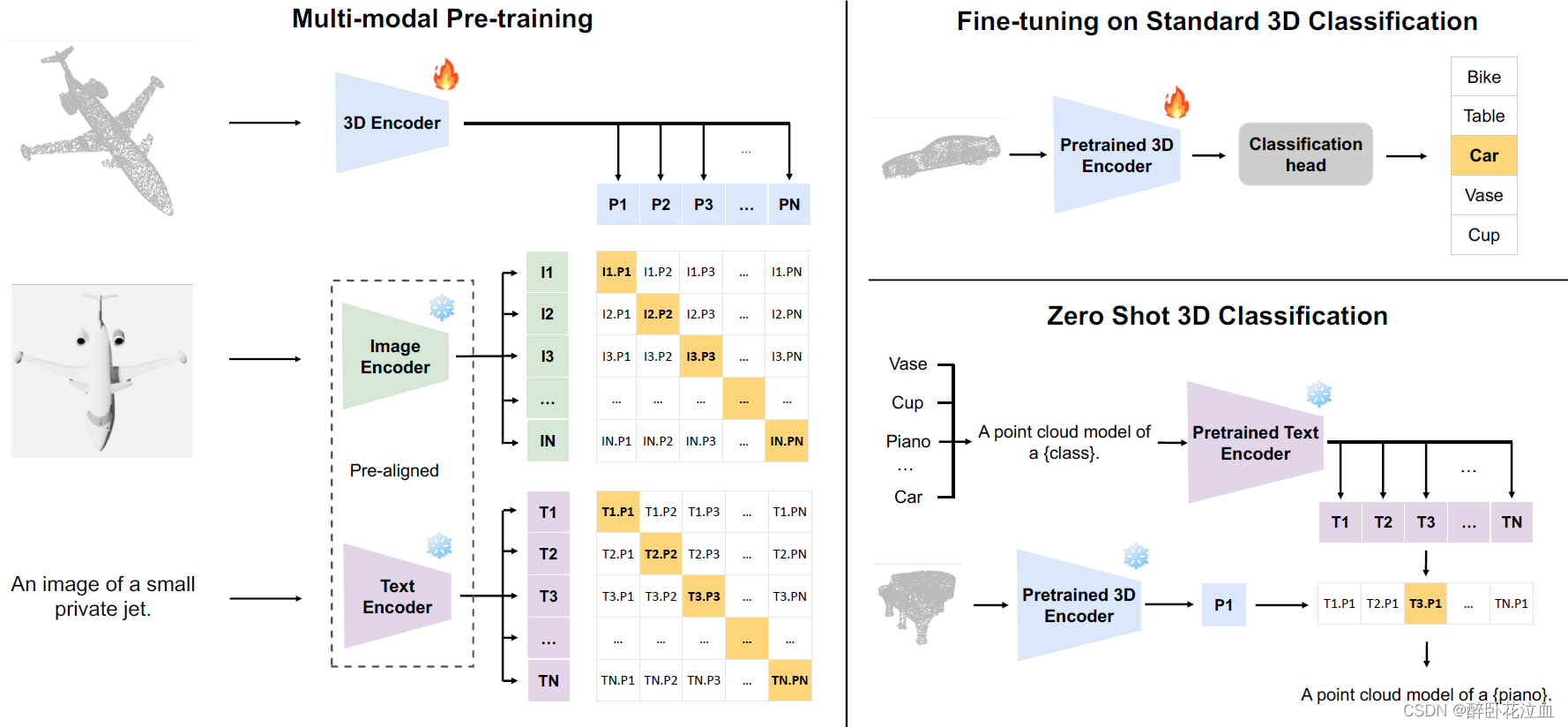
跨模态对比学习:分别从图像、文本、3D点云编码器提取到的特征为h𝑖𝐼、h𝑖𝑆、h𝑖𝑃。每种模态的对比损失计算如下:
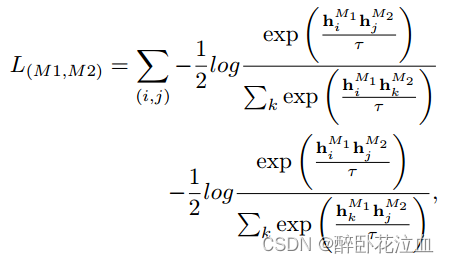
其中,M1和M2表示两种模态。(i,j)表示正样本对。同时也使用了一个可学习得参数τ,类似于CLIP。
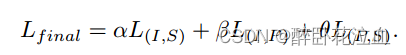
默认情况下,α设为常数0,其他两个参数设为1:因为在预训练期间,我们发现如果我们更新CLIP的图像和文本编码器,由于我们有限的数据大小,会出现灾难性的遗忘。当将ULIP应用于下游任务时,这将导致显著的性能下降。因此,在整个预训练的过程中,我们冻结了文本编码器和图像编码器的权重,仅更新3D点云编码器。

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









