









23年10月来自厦门大学的论文“JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues“。
3D表示学习在计算机视觉、自动驾驶和机器人技术中起着至关重要的作用,其重要性日益凸显。然而,一种直接将2D对齐策略转移到3D领域的主流趋势,遇到了三个不同的挑战:(1)信息退化:这是由于3D数据与单视图的2D图像和通用文本对齐,忽略了多视图图像和详细子类文本的需要。(2) 协同不足:这些策略将3D表示与图像和文本特征单独对齐,阻碍了3D模型的整体优化。(3) 利用不足:学习到的表示,其固有的细粒度信息往往没有得到充分利用,这表明细节可能会丢失。
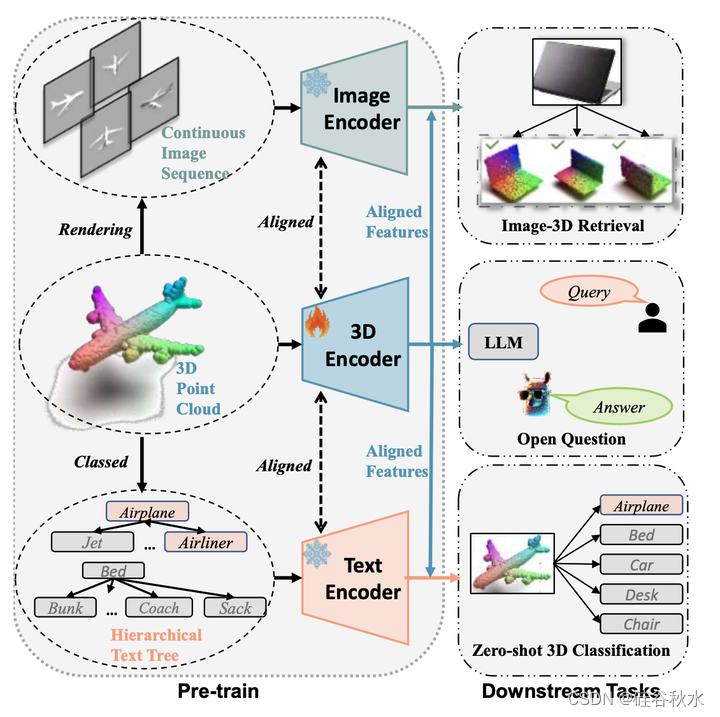
为了解决这些问题,提出JM3D,一种集成点云、文本和图像的综合方法。主要贡献包括结构化多模态组织器(SMO,Structured Multimodal Organizer),它用多个视图和分层文本丰富视觉语言表示,以及联合的多模态对齐(JMA),将语言理解与视觉表示相结合。高级模型JM3D-LLM通过有效的微调将3D表示与大语言模型相结合。在数据集ModelNet40和ScanObjectNN做评估,确立JM3D的优越性。
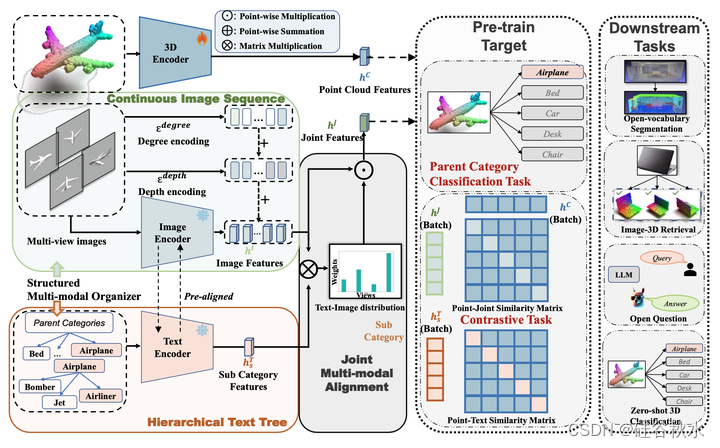
如图所示,JM3D以两个主要模块为中心:结构化多模态组织器(SMO)和联合的多模态对齐(JMA)。首先提出SMO来解决信息退化问题,它独立地增强每种模态。对于视觉增强,3D模型应该与跨越不同角度的连续图像阵列相关联。因此,引入连续图像序列(CIS,Continuous Image Sequence )同时对多个视点进行建模。为了捕捉复杂的细节,将角度、颜色和深度等属性编码到这些图像中。从语言学的角度来看,分层文本树(HTT,Hierarchical Text Tree)增强文本表示。合并特定的子类,如“喷气式飞机”、“客机”或“轰炸机”,系统可以获得理解上的细粒度。同时,像“飞机”这样的粗略分类合并语义相关的子类,增强了模型的稳健性。然后,设计JMA来解决协同作用不足的问题。JMA协同地协调视觉和语言模态,在优化过程中同时使用。这种协同作用确保了3D模型有效地利用了这两个域的见解。此外,提供了一个理论框架,强调方法的有效性。在M3D框架完成的特征对齐基础上,3D表示与文本描述无缝同步,从而为潜在集成到大语言模型(LLM)立下基础。受指令调整技术的启发,参数有效微调(PEF)将3D语义嵌入LLM中。这种融合在JM3D-LLM中使LLM能够解析更细粒度的线索,从而解决了利用不足的问题。为了锁定这种集成,作者策划了一个来自Cap3D的会话数据集,专门用于训练。
尽管ULIP【14】采用对比学习来有效地学习三模态的联合分布,但它侧重于将3D特征与语言和视觉特征分别对齐。具体来说,联合概率分布P可以通过部署预训练的视觉语言模型来获得,例如CLIP[16]。该预训练模型是预对齐特征的宝贵资源,而各种主干[26]、[31]、[70]负责提取3D特征。
结构化多模态组织器(SMO)是一个数据细化模块,用于填补3D模型与图像-文本之间的信息空白。例如,从视觉角度来看,可以考虑汽车的3D模型。汽车的单个正面渲染图像可能无法捕捉到有关车辆后端的关键信息。同样,在语言方面,使用“瓶子”一词并不能准确地表示“罐子”、“啤酒”或“烧瓶”等特定型号。为了减少这种信息损失,采用多视图方法来组织三元组样本中的数据,构建一个更新形式的三元组。
为了确保三模态之间更公平和全面的对齐,SMO合并连续图像序列(CIS)的图像和分层文本树(HTT)的结构化文本。利用这些传统的视觉和文本线索,可以捕捉3D模型、视觉表示和附加文本描述之间更准确、更详细的关联。
如图所示:连续图像序列(CIS)和分层文本树(HTT)分别组织连续的多视图图像和分层文本,并将其输入预训练模型(冻结)提取左侧的特征。然后,联合的多模态对齐(JMA)结合两种模态的特征来生成联合建模特征。最后,应用对比学习将3D特征(训练)与联合特征和子类文本对齐,同时在父类的帮助下聚合3D特征。
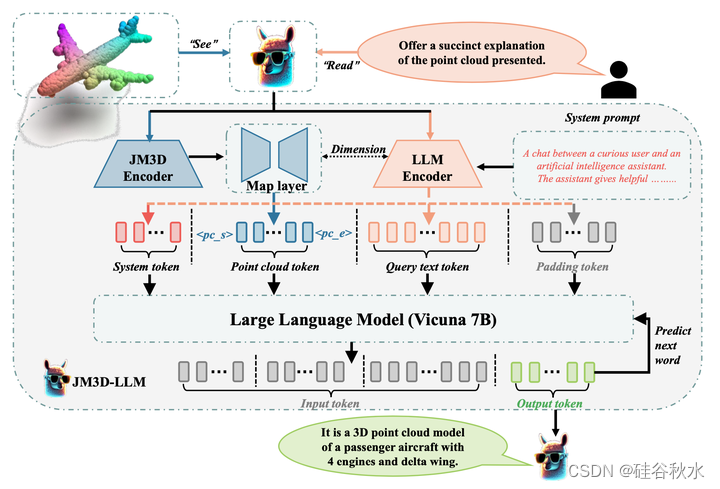
在JM3D-LLM架构中,部署了多层感知器(MLP),将点云特征与语言token的特征对齐。随后,这些点云特征作为专用tokens无缝集成到LLM的输入流中。如图是JM3D-LLM的框架:以LLM为基石,支持进一步的语义理解任务,如细粒度的3D模型加字幕。

















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









